
How BigBasket improved AI-enabled checkout at their physical stores using Amazon SageMaker
This post is co-written with Santosh Waddi and Nanda Kishore Thatikonda from BigBasket.
BigBasket is India’s largest online food and grocery store. They operate in multiple ecommerce channels such as quick commerce, slotted delivery, and daily subscriptions. You can also buy from their physical stores and vending machines. They offer a large assortment of over 50,000 products across 1,000 brands, and are operating in more than 500 cities and towns. BigBasket serves over 10 million customers.
In this post, we discuss how BigBasket used Amazon SageMaker to train their computer vision model for Fast-Moving Consumer Goods (FMCG) product identification, which helped them reduce training time by approximately 50% and save costs by 20%.
Customer challenges
Today, most supermarkets and physical stores in India provide manual checkout at the checkout counter. This has two issues:
- It requires additional manpower, weight stickers, and repeated training for the in-store operational team as they scale.
- In most stores, the checkout counter is different from the weighing counters, which adds to the friction in the customer purchase journey. Customers often lose the weight sticker and have to go back to the weighing counters to collect one again before proceeding with the checkout process.
Self-checkout process
BigBasket introduced an AI-powered checkout system in their physical stores that uses cameras to distinguish items uniquely. The following figure provides an overview of the checkout process.
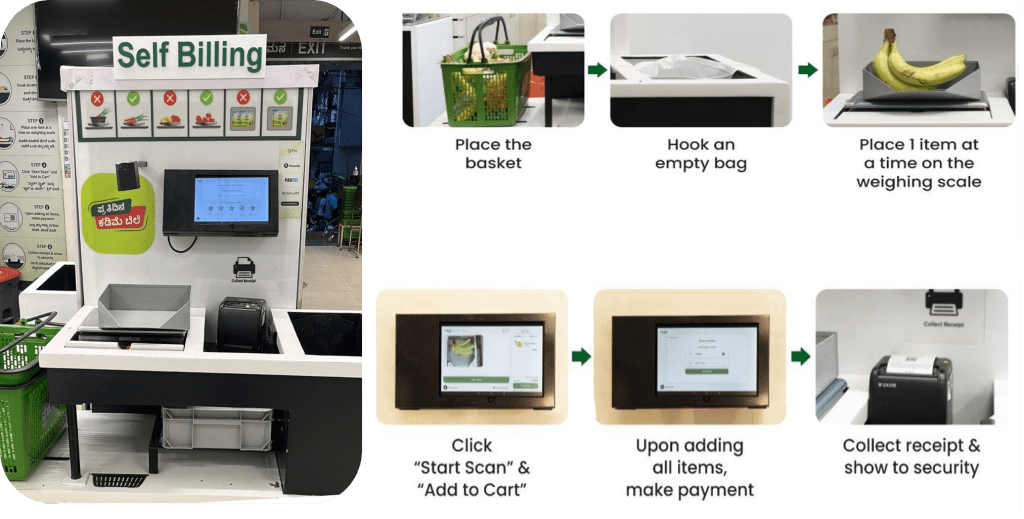
The BigBasket team was running open source, in-house ML algorithms for computer vision object recognition to power AI-enabled checkout at their Fresho (physical) stores. We were facing the following challenges to operate their existing setup:
- With the continuous introduction of new products, the computer vision model needed to continuously incorporate new product information. The system needed to handle a large catalog of over 12,000 Stock Keeping Units (SKUs), with new SKUs being continually added at a rate of over 600 per month.
- To keep pace with new products, a new model was produced each month using the latest training data. It was costly and time consuming to train the models frequently to adapt to new products.
- BigBasket also wanted to reduce the training cycle time to improve the time to market. Due to increases in SKUs, the time taken by the model was increasing linearly, which impacted their time to market because the training frequency was very high and took a long time.
- Data augmentation for model training and manually managing the complete end-to-end training cycle was adding significant overhead. BigBasket was running this on a third-party platform, which incurred significant costs.
Solution overview
We recommended that BigBasket rearchitect their existing FMCG product detection and classification solution using SageMaker to address these challenges. Before moving to full-scale production, BigBasket tried a pilot on SageMaker to evaluate performance, cost, and convenience metrics.
Their objective was to fine-tune an existing computer vision machine learning (ML) model for SKU detection. We used a convolutional neural network (CNN) architecture with ResNet152 for image classification. A sizable dataset of around 300 images per SKU was estimated for model training, resulting in over 4 million total training images. For certain SKUs, we augmented data to encompass a broader range of environmental conditions.
The following diagram illustrates the solution architecture.
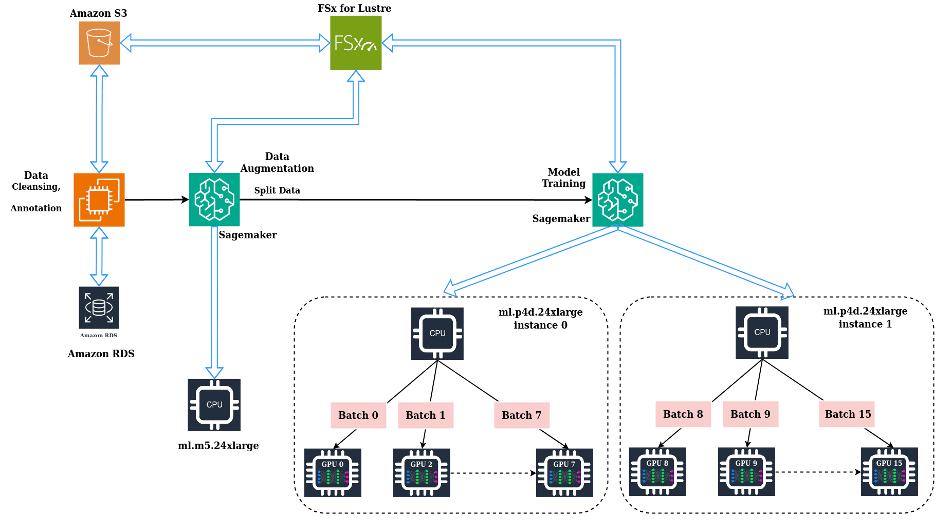
The complete process can be summarized into the following high-level steps:
- Perform data cleansing, annotation, and augmentation.
- Store data in an Amazon Simple Storage Service (Amazon S3) bucket.
- Use SageMaker and Amazon FSx for Lustre for efficient data augmentation.
- Split data into train, validation, and test sets. We used FSx for Lustre and Amazon Relational Database Service (Amazon RDS) for fast parallel data access.
- Use a custom PyTorch Docker container including other open source libraries.
- Use SageMaker Distributed Data Parallelism (SMDDP) for accelerated distributed training.
- Log model training metrics.
- Copy the final model to an S3 bucket.
BigBasket used SageMaker notebooks to train their ML models and were able to easily port their existing open source PyTorch and other open source dependencies to a SageMaker PyTorch container and run the pipeline seamlessly. This was the first benefit seen by the BigBasket team, because there were hardly any changes needed to the code to make it compatible to run on a SageMaker environment.
The model network consists of a ResNet 152 architecture followed by fully connected layers. We froze the low-level feature layers and retained the weights acquired through transfer learning from the ImageNet model. The total model parameters were 66 million, consisting of 23 million trainable parameters. This transfer learning-based approach helped them use fewer images at the time of training, and also enabled faster convergence and reduced the total training time.
Building and training the model within Amazon SageMaker Studio provided an integrated development environment (IDE) with everything needed to prepare, build, train, and tune models. Augmenting the training data using techniques like cropping, rotating, and flipping images helped improve the model training data and model accuracy.
Model training was accelerated by 50% through the use of the SMDDP library, which includes optimized communication algorithms designed specifically for AWS infrastructure. To improve data read/write performance during model training and data augmentation, we used FSx for Lustre for high-performance throughput.
Their starting training data size was over 1.5 TB. We used two Amazon Elastic Compute Cloud (Amazon EC2) p4d.24 large instances with 8 GPU and 40 GB GPU memory. For SageMaker distributed training, the instances need to be in the same AWS Region and Availability Zone. Also, training data stored in an S3 bucket needs to be in the same Availability Zone. This architecture also allows BigBasket to change to other instance types or add more instances to the current architecture to cater to any significant data growth or achieve further reduction in training time.
How the SMDDP library helped reduce training time, cost, and complexity
In traditional distributed data training, the training framework assigns ranks to GPUs (workers) and creates a replica of your model on each GPU. During each training iteration, the global data batch is divided into pieces (batch shards) and a piece is distributed to each worker. Each worker then proceeds with the forward and backward pass defined in your training script on each GPU. Finally, model weights and gradients from the different model replicas are synced at the end of the iteration through a collective communication operation called AllReduce. After each worker and GPU has a synced replica of the model, the next iteration begins.
The SMDDP library is a collective communication library that improves the performance of this distributed data parallel training process. The SMDDP library reduces the communication overhead of the key collective communication operations such as AllReduce. Its implementation of AllReduce is designed for AWS infrastructure and can speed up training by overlapping the AllReduce operation with the backward pass. This approach achieves near-linear scaling efficiency and faster training speed by optimizing kernel operations between CPUs and GPUs.
Note the following calculations:
- The size of the global batch is (number of nodes in a cluster) * (number of GPUs per node) * (per batch shard)
- A batch shard (small batch) is a subset of the dataset assigned to each GPU (worker) per iteration
BigBasket used the SMDDP library to reduce their overall training time. With FSx for Lustre, we reduced the data read/write throughput during model training and data augmentation. With data parallelism, BigBasket was able to achieve almost 50% faster and 20% cheaper training compared to other alternatives, delivering the best performance on AWS. SageMaker automatically shuts down the training pipeline post-completion. The project completed successfully with 50% faster training time in AWS (4.5 days in AWS vs. 9 days on their legacy platform).
At the time of writing this post, BigBasket has been running the complete solution in production for more than 6 months and scaling the system by catering to new cities, and we’re adding new stores every month.
“Our partnership with AWS on migration to distributed training using their SMDDP offering has been a great win. Not only did it cut down our training times by 50%, it was also 20% cheaper. In our entire partnership, AWS has set the bar on customer obsession and delivering results—working with us the whole way to realize promised benefits.”
– Keshav Kumar, Head of Engineering at BigBasket.
Conclusion
In this post, we discussed how BigBasket used SageMaker to train their computer vision model for FMCG product identification. The implementation of an AI-powered automated self-checkout system delivers an improved retail customer experience through innovation, while eliminating human errors in the checkout process. Accelerating new product onboarding by using SageMaker distributed training reduces SKU onboarding time and cost. Integrating FSx for Lustre enables fast parallel data access for efficient model retraining with hundreds of new SKUs monthly. Overall, this AI-based self-checkout solution provides an enhanced shopping experience devoid of frontend checkout errors. The automation and innovation have transformed their retail checkout and onboarding operations.
SageMaker provides end-to-end ML development, deployment, and monitoring capabilities such as a SageMaker Studio notebook environment for writing code, data acquisition, data tagging, model training, model tuning, deployment, monitoring, and much more. If your business is facing any of the challenges described in this post and wants to save time to market and improve cost, reach out to the AWS account team in your Region and get started with SageMaker.
About the Authors
 Santosh Waddi is a Principal Engineer at BigBasket, brings over a decade of expertise in solving AI challenges. With a strong background in computer vision, data science, and deep learning, he holds a postgraduate degree from IIT Bombay. Santosh has authored notable IEEE publications and, as a seasoned tech blog author, he has also made significant contributions to the development of computer vision solutions during his tenure at Samsung.
Santosh Waddi is a Principal Engineer at BigBasket, brings over a decade of expertise in solving AI challenges. With a strong background in computer vision, data science, and deep learning, he holds a postgraduate degree from IIT Bombay. Santosh has authored notable IEEE publications and, as a seasoned tech blog author, he has also made significant contributions to the development of computer vision solutions during his tenure at Samsung.
 Nanda Kishore Thatikonda is an Engineering Manager leading the Data Engineering and Analytics at BigBasket. Nanda has built multiple applications for anomaly detection and has a patent filed in a similar space. He has worked on building enterprise-grade applications, building data platforms in multiple organizations and reporting platforms to streamline decisions backed by data. Nanda has over 18 years of experience working in Java/J2EE, Spring technologies, and big data frameworks using Hadoop and Apache Spark.
Nanda Kishore Thatikonda is an Engineering Manager leading the Data Engineering and Analytics at BigBasket. Nanda has built multiple applications for anomaly detection and has a patent filed in a similar space. He has worked on building enterprise-grade applications, building data platforms in multiple organizations and reporting platforms to streamline decisions backed by data. Nanda has over 18 years of experience working in Java/J2EE, Spring technologies, and big data frameworks using Hadoop and Apache Spark.
 Sudhanshu Hate is a Principal AI & ML Specialist with AWS and works with clients to advise them on their MLOps and generative AI journey. In his previous role, he conceptualized, created, and led teams to build a ground-up, open source-based AI and gamification platform, and successfully commercialized it with over 100 clients. Sudhanshu has to his credit a couple of patents; has written 2 books, several papers, and blogs; and has presented his point of view in various forums. He has been a thought leader and speaker, and has been in the industry for nearly 25 years. He has worked with Fortune 1000 clients across the globe and most recently is working with digital native clients in India.
Sudhanshu Hate is a Principal AI & ML Specialist with AWS and works with clients to advise them on their MLOps and generative AI journey. In his previous role, he conceptualized, created, and led teams to build a ground-up, open source-based AI and gamification platform, and successfully commercialized it with over 100 clients. Sudhanshu has to his credit a couple of patents; has written 2 books, several papers, and blogs; and has presented his point of view in various forums. He has been a thought leader and speaker, and has been in the industry for nearly 25 years. He has worked with Fortune 1000 clients across the globe and most recently is working with digital native clients in India.
 Ayush Kumar is Solutions Architect at AWS. He is working with a wide variety of AWS customers, helping them adopt the latest modern applications and innovate faster with cloud-native technologies. You’ll find him experimenting in the kitchen in his spare time.
Ayush Kumar is Solutions Architect at AWS. He is working with a wide variety of AWS customers, helping them adopt the latest modern applications and innovate faster with cloud-native technologies. You’ll find him experimenting in the kitchen in his spare time.
Leave a Reply