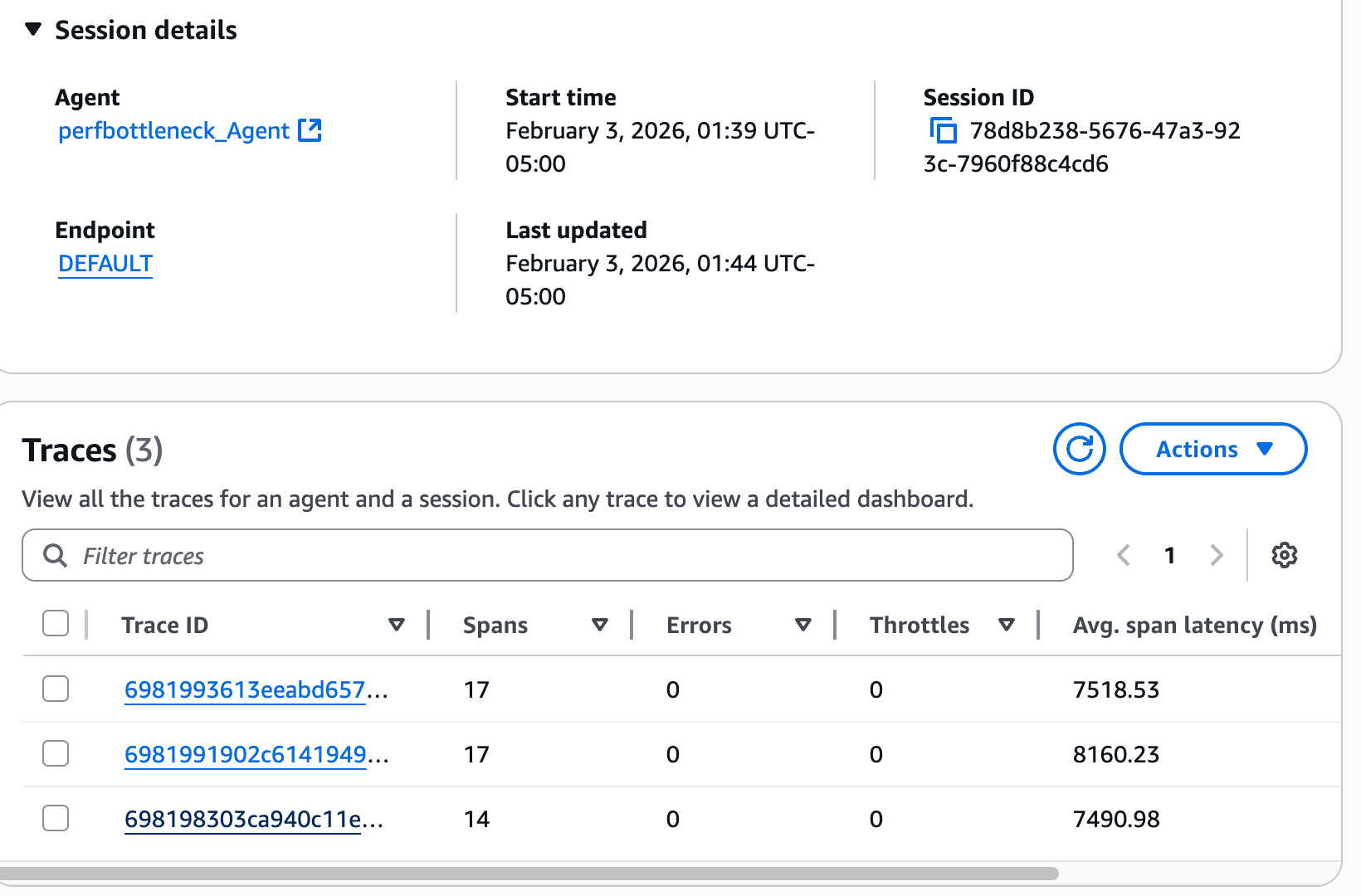
Favorite As your AI agents move from prototype to production, the challenges shift from getting them to work to keeping them fast and efficient. In Part 1 of this series, we walked through debugging two common agent failures: infinite loops and tool invocation errors. Those scenarios dealt with agents that
Read More
 Shared by AWS Machine Learning August 1, 2026
Shared by AWS Machine Learning August 1, 2026
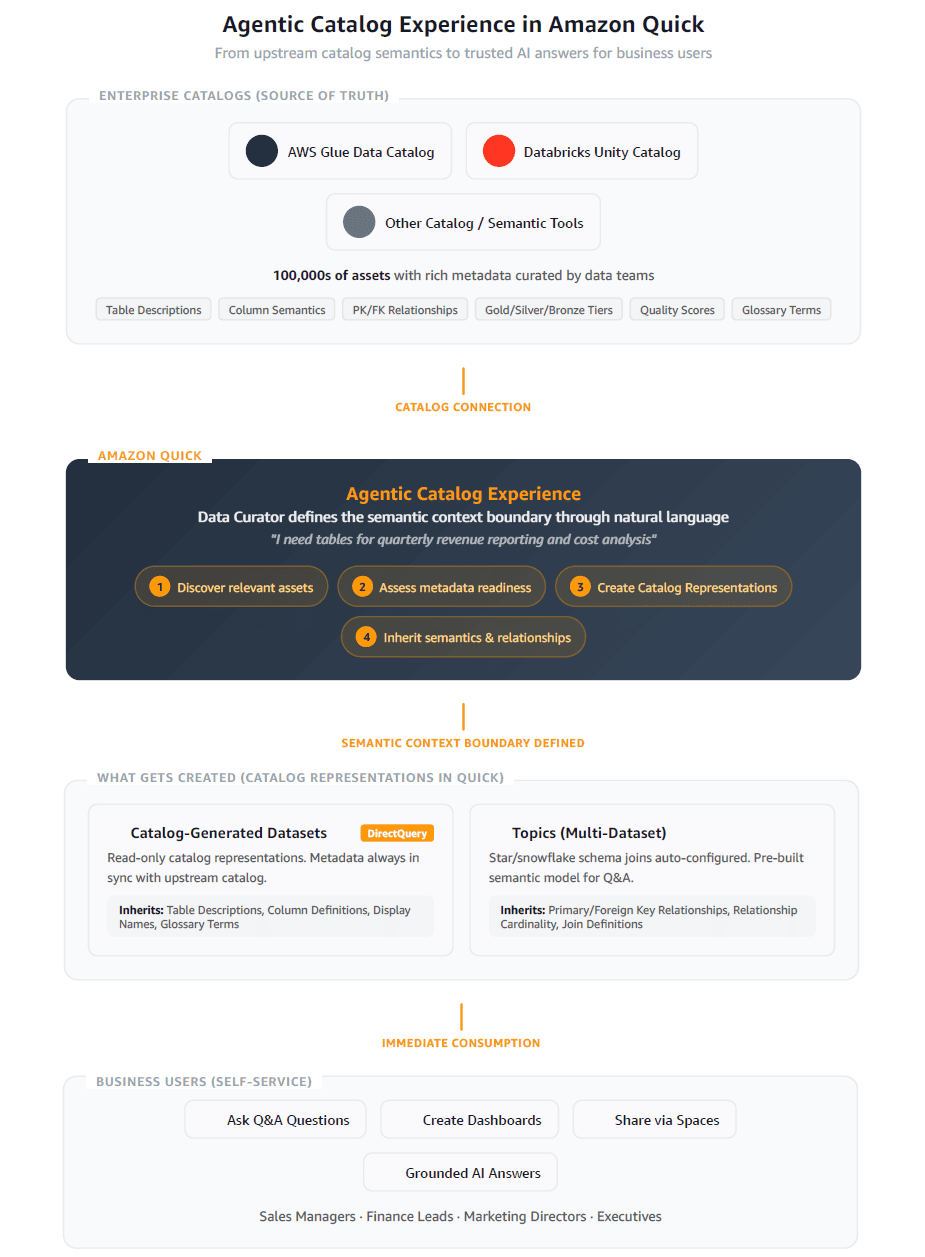
Favorite As organizations embrace AI-powered analytics, the value of a natural language (Text2SQL) answer is only as good as the business context behind it. We’re entering a phase where semantic richness (table and column descriptions, and relationships) must flow directly from where it’s authored in upstream data catalogs and semantic
Read More
Shared by AWS Machine Learning August 1, 2026
Favorite The problem: Prompt engineering at scale is still painful Migrating prompts to new models on Amazon Bedrock, or optimizing them for your current model, is still one of the most manual parts of building a generative AI application. Say you have built a deployed generative AI application. It works.
Read More
Shared by AWS Machine Learning July 31, 2026
Favorite This post is co-written with Chris Dickens from OpenAI. OpenAI GPT-5.6 Sol, Terra, and Luna are now generally available on Amazon Bedrock. With GPT-5.6 on Amazon Bedrock, you get the newest generation of OpenAI frontier models with pay-per-token pricing, AWS security and governance controls, and usage that counts toward
Read More
Shared by AWS Machine Learning July 31, 2026
Favorite Without the ability to track machine learning (ML) model prediction quality, organizations only realize they have issues when their customers complain or when they conduct spot checks, which jeopardizes customer trust. This post introduces inference meta-monitoring for Amazon SageMaker AI endpoints. It provides a governance layer that sits above
Read More
Shared by AWS Machine Learning July 31, 2026
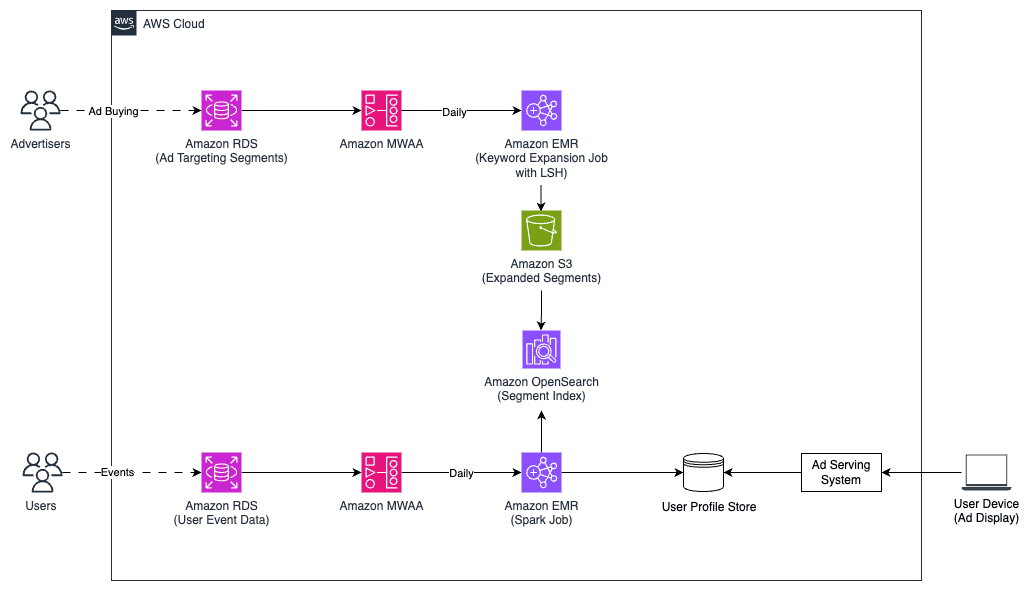
Favorite Connecting user search intent with relevant ad experiences across channels is a longstanding challenge in digital advertising. Advertisers need sophisticated ways to reach audiences based on their demonstrated interests and behaviors, particularly their search activity, which is one of the strongest signals of user intent. Traditional keyword expansion approaches
Read More
Shared by AWS Machine Learning July 31, 2026
Favorite Open weight models have become powerful enough to handle complex tasks such as multi-step agentic workflows, advanced reasoning, and long-horizon coding. However, as these models grow in capability, they also grow in size and hosting multi-trillion parameter architectures requires purpose-built infrastructure, high-end GPU compute, and optimized serving frameworks. On
Read More
Shared by AWS Machine Learning July 31, 2026
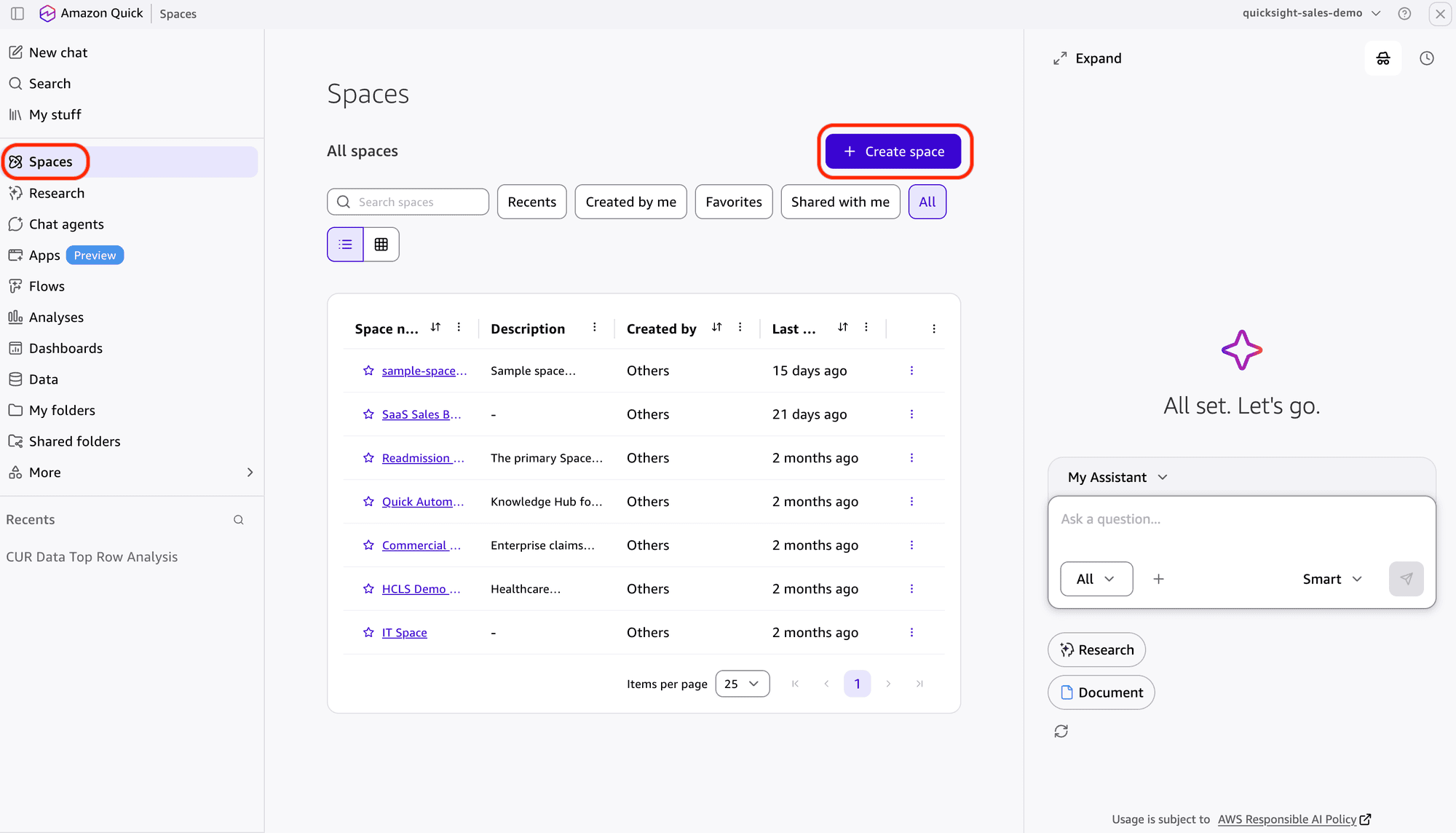
Favorite Automating customer retention workflows in Amazon Quick can turn a five-day churn-response cycle into one that takes minutes. Last quarter, a mid-size SaaS company lost 12% of its at-risk accounts because the retention team took five days to identify and contact dissatisfied customers. By the time someone manually reviewed
Read More
Shared by AWS Machine Learning July 30, 2026
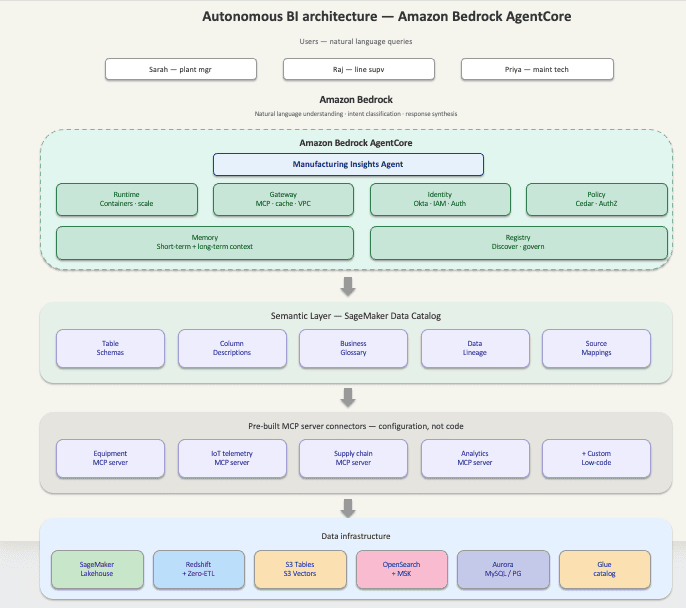
Favorite A Monday morning problem Sarah Chen manages 12 assembly lines and 2,000 machines. Before her 10 AM production review, she needs one answer: Which lines need attention this week? Simple question. Painful journey. She starts in the IoT dashboard. Line 4’s motor temperature is running 12°C above baseline —
Read More
Shared by AWS Machine Learning July 30, 2026
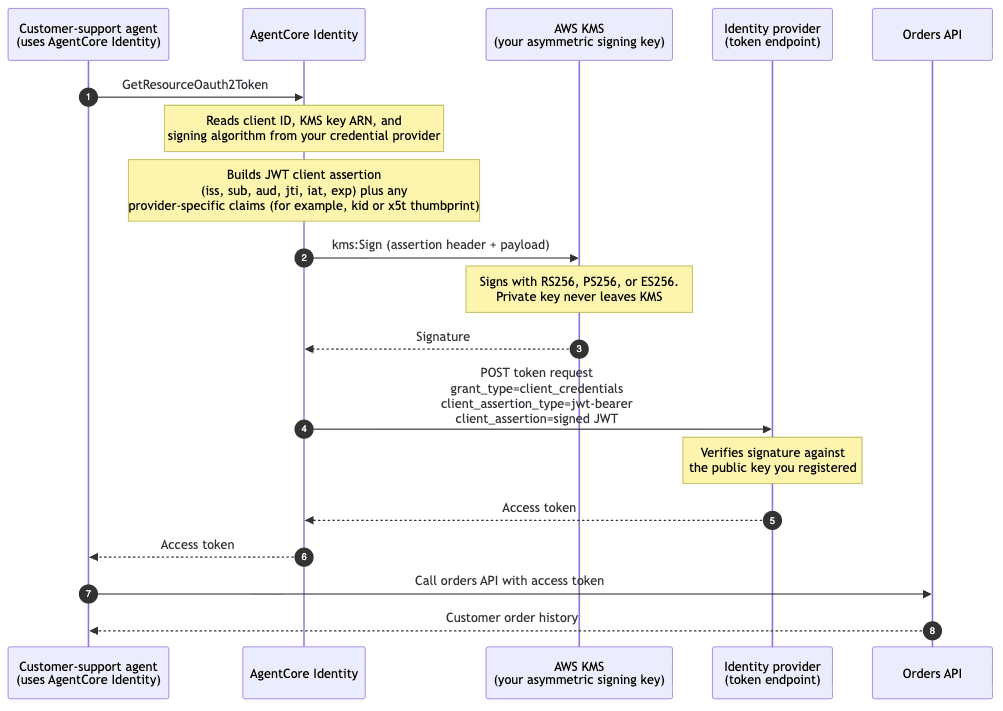
Favorite Amazon Bedrock AgentCore Identity now supports Private Key JWT client authentication for agents. With Private Key JWT client authentication, your agents can authenticate to a downstream identity provider’s token endpoint using a signed JSON Web Token (JWT) client assertion instead of a shared OAuth 2.0 client secret. You can
Read More
Shared by AWS Machine Learning July 30, 2026