
Build generative AI chatbots using prompt engineering with Amazon Redshift and Amazon Bedrock
With the advent of generative AI solutions, organizations are finding different ways to apply these technologies to gain edge over their competitors. Intelligent applications, powered by advanced foundation models (FMs) trained on huge datasets, can now understand natural language, interpret meaning and intent, and generate contextually relevant and human-like responses. This is fueling innovation across industries, with generative AI demonstrating immense potential to enhance countless business processes, including the following:
- Accelerate research and development through automated hypothesis generation and experiment design
- Uncover hidden insights by identifying subtle trends and patterns in data
- Automate time-consuming documentation processes
- Provide better customer experience with personalization
- Summarize data from various knowledge sources
- Boost employee productivity by providing software code recommendations
Amazon Bedrock is a fully managed service that makes it straightforward to build and scale generative AI applications. Amazon Bedrock offers a choice of high-performing foundation models from leading AI companies, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon, via a single API. It enables you to privately customize the FMs with your data using techniques such as fine-tuning, prompt engineering, and Retrieval Augmented Generation (RAG), and build agents that run tasks using your enterprise systems and data sources while complying with security and privacy requirements.
In this post, we discuss how to use the comprehensive capabilities of Amazon Bedrock to perform complex business tasks and improve the customer experience by providing personalization using the data stored in a database like Amazon Redshift. We use prompt engineering techniques to develop and optimize the prompts with the data that is stored in a Redshift database to efficiently use the foundation models. We build a personalized generative AI travel itinerary planner as part of this example and demonstrate how we can personalize a travel itinerary for a user based on their booking and user profile data stored in Amazon Redshift.
Prompt engineering
Prompt engineering is the process where you can create and design user inputs that can guide generative AI solutions to generate desired outputs. You can choose the most appropriate phrases, formats, words, and symbols that guide the foundation models and in turn the generative AI applications to interact with the users more meaningfully. You can use creativity and trial-and-error methods to create a collection on input prompts, so the application works as expected. Prompt engineering makes generative AI applications more efficient and effective. You can encapsulate open-ended user input inside a prompt before passing it to the FMs. For example, a user may enter an incomplete problem statement like, “Where to purchase a shirt.” Internally, the application’s code uses an engineered prompt that says, “You are a sales assistant for a clothing company. A user, based in Alabama, United States, is asking you where to purchase a shirt. Respond with the three nearest store locations that currently stock a shirt.” The foundation model then generates more relevant and accurate information.
The prompt engineering field is evolving constantly and needs creative expression and natural language skills to tune the prompts and obtain the desired output from FMs. A prompt can contain any of the following elements:
- Instruction – A specific task or instruction you want the model to perform
- Context – External information or additional context that can steer the model to better responses
- Input data – The input or question that you want to find a response for
- Output indicator – The type or format of the output
You can use prompt engineering for various enterprise use cases across different industry segments, such as the following:
- Banking and finance – Prompt engineering empowers language models to generate forecasts, conduct sentiment analysis, assess risks, formulate investment strategies, generate financial reports, and ensure regulatory compliance. For example, you can use large language models (LLMs) for a financial forecast by providing data and market indicators as prompts.
- Healthcare and life sciences – Prompt engineering can help medical professionals optimize AI systems to aid in decision-making processes, such as diagnosis, treatment selection, or risk assessment. You can also engineer prompts to facilitate administrative tasks, such as patient scheduling, record keeping, or billing, thereby increasing efficiency.
- Retail – Prompt engineering can help retailers implement chatbots to address common customer requests like queries about order status, returns, payments, and more, using natural language interactions. This can increase customer satisfaction and also allow human customer service teams to dedicate their expertise to intricate and sensitive customer issues.
In the following example, we implement a use case from the travel and hospitality industry to implement a personalized travel itinerary planner for customers who have upcoming travel plans. We demonstrate how we can build a generative AI chatbot that interacts with users by enriching the prompts from the user profile data that is stored in the Redshift database. We then send this enriched prompt to an LLM, specifically, Anthropic’s Claude on Amazon Bedrock, to obtain a customized travel plan.
Amazon Redshift has announced a feature called Amazon Redshift ML that makes it straightforward for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Redshift data warehouses. However, this post uses LLMs hosted on Amazon Bedrock to demonstrate general prompt engineering techniques and its benefits.
Solution overview
We all have searched the internet for things to do in a certain place during or before we go on a vacation. In this solution, we demonstrate how we can generate a custom, personalized travel itinerary that users can reference, which will be generated based on their hobbies, interests, favorite foods, and more. The solution uses their booking data to look up the cities they are going to, along with the travel dates, and comes up with a precise, personalized list of things to do. This solution can be used by the travel and hospitality industry to embed a personalized travel itinerary planner within their travel booking portal.
This solution contains two major components. First, we extract the user’s information like name, location, hobbies, interests, and favorite food, along with their upcoming travel booking details. With this information, we stitch a user prompt together and pass it to Anthropic’s Claude on Amazon Bedrock to obtain a personalized travel itinerary. The following diagram provides a high-level overview of the workflow and the components involved in this architecture.
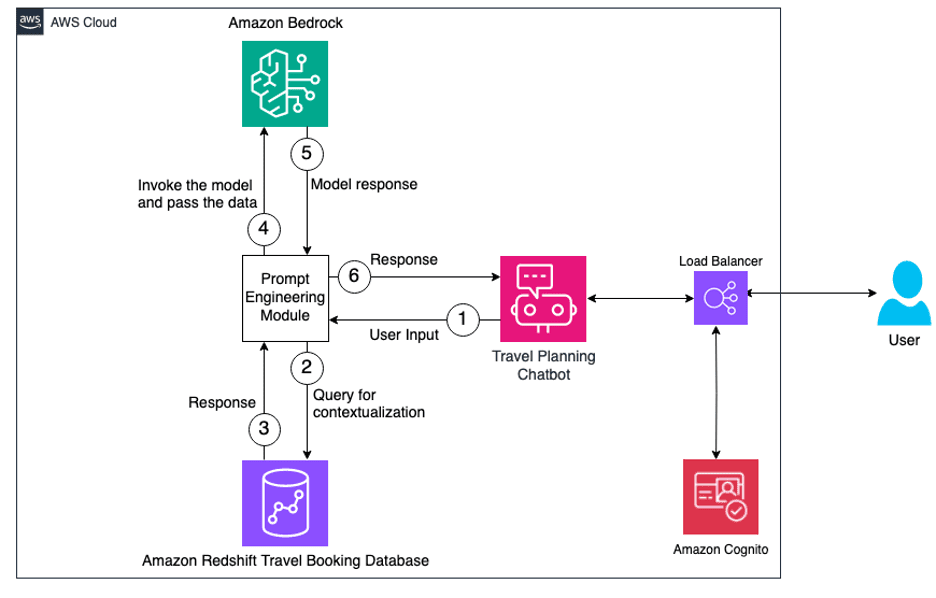
First, the user logs in to the chatbot application, which is hosted behind an Application Load Balancer and authenticated using Amazon Cognito. We obtain the user ID from the user using the chatbot interface, which is sent to the prompt engineering module. The user’s information like name, location, hobbies, interests, and favorite food is extracted from the Redshift database along with their upcoming travel booking details like travel city, check-in date, and check-out date.
Prerequisites
Before you deploy this solution, make sure you have the following prerequisites set up:
- A valid AWS account.
- An AWS Identity and Access Management (IAM) role in the account that has sufficient permissions to create the necessary resources. If you have administrator access to the account, no action is necessary.
- An SSL certificate created and imported into AWS Certificate Manager (ACM). For more details, refer to Importing a certificate.
Deploy this solution
Use the following steps to deploy this solution in your environment. The code used in this solution is available in the GitHub repo.
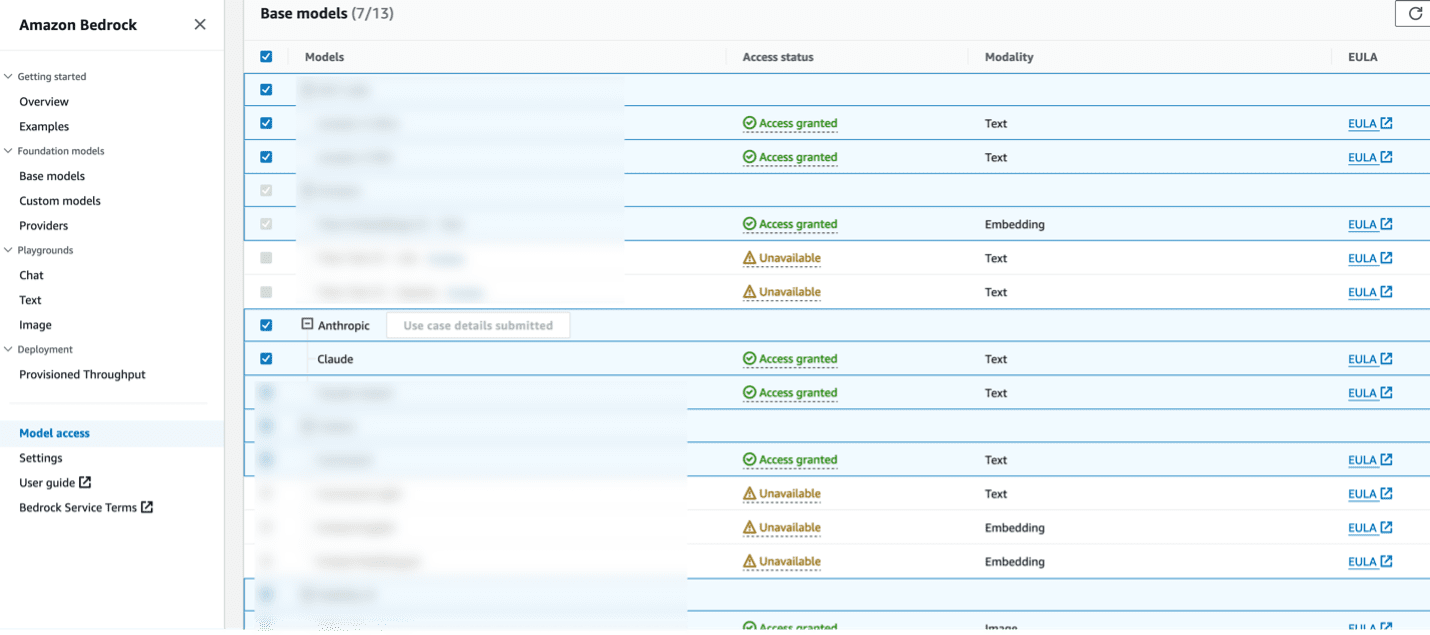
The first step is to make sure the account and the AWS Region where the solution is being deployed have access to Amazon Bedrock base models.
- On the Amazon Bedrock console, choose Model access in the navigation pane.
- Choose Manage model access.
- Select the Anthropic Claude model, then choose Save changes.
It may take a few minutes for the access status to change to Access granted.
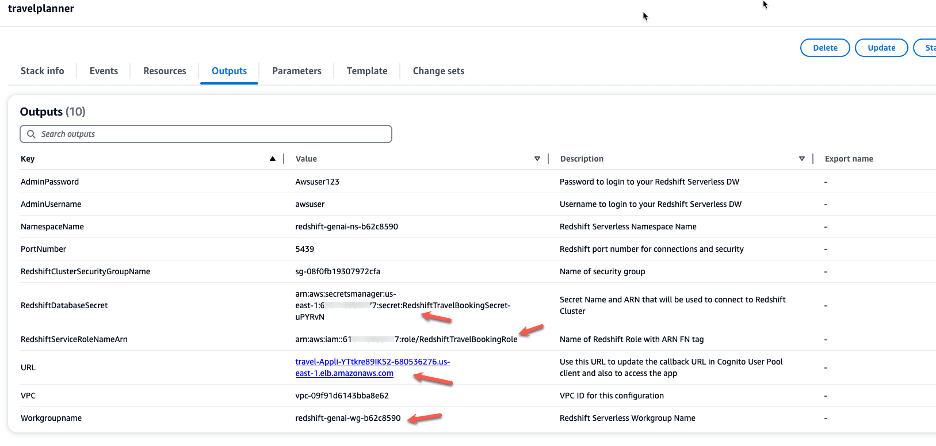
Next, we use the following AWS CloudFormation template to deploy an Amazon Redshift Serverless cluster along with all the related components, including the Amazon Elastic Compute Cloud (Amazon EC2) instance to host the webapp.
- Choose Launch Stack to launch the CloudFormation stack:
- Provide a stack name and SSH keypair, then create the stack.
- On the stack’s Outputs tab, save the values for the Redshift database workgroup name, secret ARN, URL, and Amazon Redshift service role ARN.

Now you’re ready to connect to the EC2 instance using SSH.
- Open an SSH client.
- Locate your private key file that was entered while launching the CloudFormation stack.
- Change the permissions of the private key file to 400 (
chmod 400 id_rsa). - Connect to the instance using its public DNS or IP address. For example:
- Update the configuration file
personalized-travel-itinerary-planner/core/data_feed_config.iniwith the Region, workgroup name, and secret ARN that you saved earlier.
- Run the following command to create the database objects that contain the user information and travel booking data:

This command creates the travel schema along with the tables named user_profile and hotel_booking.
- Run the following command to launch the web service:
In the next steps, you create a user account to log in to the app.
- On the Amazon Cognito console, choose User pools in the navigation pane.
- Select the user pool that was created as part of the CloudFormation stack (travelplanner-user-pool).
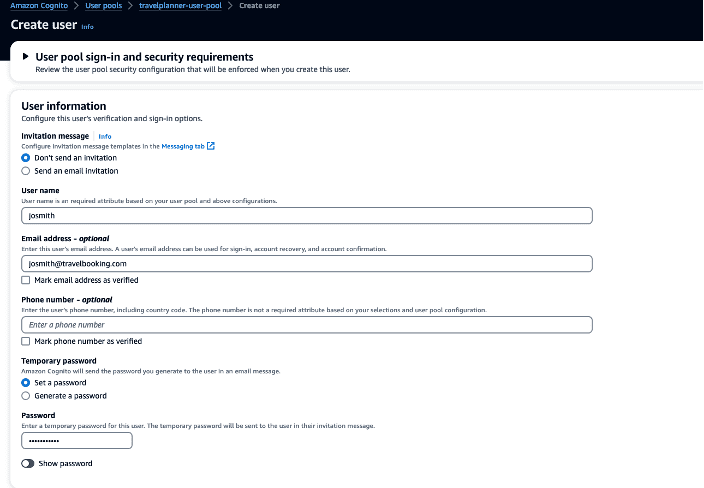
- Choose Create user.
- Enter a user name, email, and password, then choose Create user.
Now you can update the callback URL in Amazon Cognito.
- On the
travelplanner-user-pooluser pool details page, navigate to the App integration tab. - In the App client list section, choose the client that you created (
travelplanner-client). - In the Hosted UI section, choose Edit.
- For URL, enter the URL that you copied from the CloudFormation stack output (make sure to use lowercase).
- Choose Save changes.

Test the solution
Now we can test the bot by asking it questions.
- In a new browser window, enter the URL you copied from the CloudFormation stack output and log in using the user name and password that you created. Change the password if prompted.
- Enter the user ID whose information you want to use (for this post, we use user ID 1028169).
- Ask any question to the bot.
The following are some example questions:
- Can you plan a detailed itinerary for my July trip?
- Should I carry a jacket for my upcoming trip?
- Can you recommend some places to travel in March?
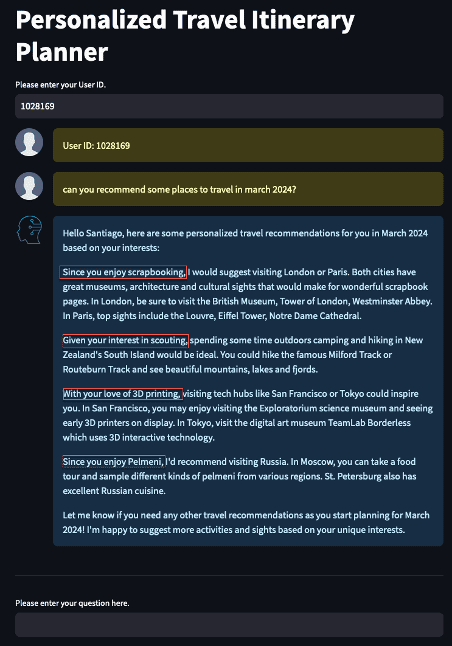
Using the user ID you provided, the prompt engineering module will extract the user details and design a prompt, along with the question asked by the user, as shown in the following screenshot.

The highlighted text in the preceding screenshot is the user-specific information that was extracted from the Redshift database and stitched together with some additional instructions. The elements of a good prompt such as instruction, context, input data, and output indicator are also called out.
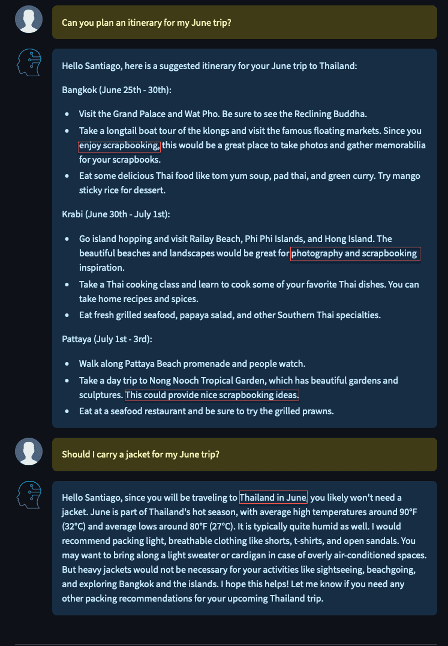
After you pass this prompt to the LLM, we get the following output. In this example, the LLM created a custom travel itinerary for the specific dates of the user’s upcoming booking. It also took into account the user’s hobbies, interests, and favorite food while planning this itinerary.
 |
 |
Clean up
To avoid incurring ongoing charges, clean up your infrastructure.
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Select the stack that you created and choose Delete.
Conclusion
In this post, we demonstrated how we can engineer prompts using data that is stored in Amazon Redshift and can be passed on to Amazon Bedrock to obtain an optimized response. This solution provides a simplified approach for building a generative AI application using proprietary data residing in your own database. By engineering tailored prompts based on the data in Amazon Redshift and having Amazon Bedrock generate responses, you can take advantage of generative AI in a customized way using your own datasets. This allows for more specific, relevant, and optimized output than would be possible with more generalized prompts. The post shows how you can integrate AWS services to create a generative AI solution that unleashes the full potential of these technologies with your data.
Stay up to date with the latest advancements in generative AI and start building on AWS. If you’re seeking assistance on how to begin, check out the Generative AI Innovation Center.
About the Authors
 Ravikiran Rao is a Data Architect at AWS and is passionate about solving complex data challenges for various customers. Outside of work, he is a theatre enthusiast and an amateur tennis player.
Ravikiran Rao is a Data Architect at AWS and is passionate about solving complex data challenges for various customers. Outside of work, he is a theatre enthusiast and an amateur tennis player.
 Jigna Gandhi is a Sr. Solutions Architect at Amazon Web Services, based in the Greater New York City area. She has over 15 years of strong experience in leading several complex, highly robust, and massively scalable software solutions for large-scale enterprise applications.
Jigna Gandhi is a Sr. Solutions Architect at Amazon Web Services, based in the Greater New York City area. She has over 15 years of strong experience in leading several complex, highly robust, and massively scalable software solutions for large-scale enterprise applications.
 Jason Pedreza is a Senior Redshift Specialist Solutions Architect at AWS with data warehousing experience handling petabytes of data. Prior to AWS, he built data warehouse solutions at Amazon.com and Amazon Devices. He specializes in Amazon Redshift and helps customers build scalable analytic solutions.
Jason Pedreza is a Senior Redshift Specialist Solutions Architect at AWS with data warehousing experience handling petabytes of data. Prior to AWS, he built data warehouse solutions at Amazon.com and Amazon Devices. He specializes in Amazon Redshift and helps customers build scalable analytic solutions.
 Roopali Mahajan is a Senior Solutions Architect with AWS based out of New York. She thrives on serving as a trusted advisor for her customers, helping them navigate their journey on cloud. Her day is spent solving complex business problems by designing effective solutions using AWS services. During off-hours, she loves to spend time with her family and travel.
Roopali Mahajan is a Senior Solutions Architect with AWS based out of New York. She thrives on serving as a trusted advisor for her customers, helping them navigate their journey on cloud. Her day is spent solving complex business problems by designing effective solutions using AWS services. During off-hours, she loves to spend time with her family and travel.
Leave a Reply