
How Veritone uses Amazon Bedrock, Amazon Rekognition, Amazon Transcribe, and information retrieval to update their video search pipeline
This post is co-written with Tim Camara, Senior Product Manager at Veritone.
Veritone is an artificial intelligence (AI) company based in Irvine, California. Founded in 2014, Veritone empowers people with AI-powered software and solutions for various applications, including media processing, analytics, advertising, and more. It offers solutions for media transcription, facial recognition, content summarization, object detection, and other AI capabilities to solve the unique challenges professionals face across industries.
Veritone began its journey with its foundational AI operating system, aiWARETM, solving industry and brand-specific challenges by building applications on top of this powerful technology. Growing in the media and entertainment space, Veritone solves media management, broadcast content, and ad tracking issues. Alongside these applications, Veritone offers media services including AI-powered audio advertising and influencer marketing, content licensing and media monetization services, and professional services to build bespoke AI solutions.
With a decade of enterprise AI experience, Veritone supports the public sector, working with US federal government agencies, state and local government, law enforcement agencies, and legal organizations to automate and simplify evidence management, redaction, person-of-interest tracking, and eDiscovery. Veritone has also expanded into the talent acquisition space, serving HR teams worldwide with its powerful programmatic job advertising platform and distribution network.
Using generative AI and new multimodal foundation models (FMs) could be very strategic for Veritone and the businesses they serve, because it would significantly improve media indexing and retrieval based on contextual meaning—a critical first step to eventually generating new content. Building enhanced semantic search capabilities that analyze media contextually would lay the groundwork for creating AI-generated content, allowing customers to produce customized media more efficiently.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. With recent advances in large language models (LLMs), Veritone has updated its platform with these powerful new AI capabilities. Looking ahead, Veritone wants to take advantage of new advanced FM techniques to improve the quality of media search results of “Digital Media Hub”( DMH ) and grow the number of users by achieving a better user experience.
In this post, we demonstrate how to use enhanced video search capabilities by enabling semantic retrieval of videos based on text queries. We match the most relevant videos to text-based search queries by incorporating new multimodal embedding models like Amazon Titan Multimodal Embeddings to encode all visual, visual-meta, and transcription data. The primary focus is building a robust text search that goes beyond traditional word-matching algorithms as well as an interface for comparing search algorithms. Additionally, we explore narrowing retrieval to specific shots within videos (a shot is a series of interrelated consecutive pictures taken contiguously by a single camera representing a continuous action in time and space). Overall, we aim to improve video search through cutting-edge semantic matching, providing an efficient way to find videos relevant to your rich textual queries.
Solution overview
We use the following AWS services to implement the solution:
- Amazon Bedrock and the Amazon Titan Multimodal Embeddings and Amazon Titan Text models
- Amazon Comprehend
- AWS Lambda
- Amazon OpenSearch Service
- Amazon Rekognition
- Amazon Simple Storage Service (Amazon S3)
- Amazon Transcribe
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon within a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
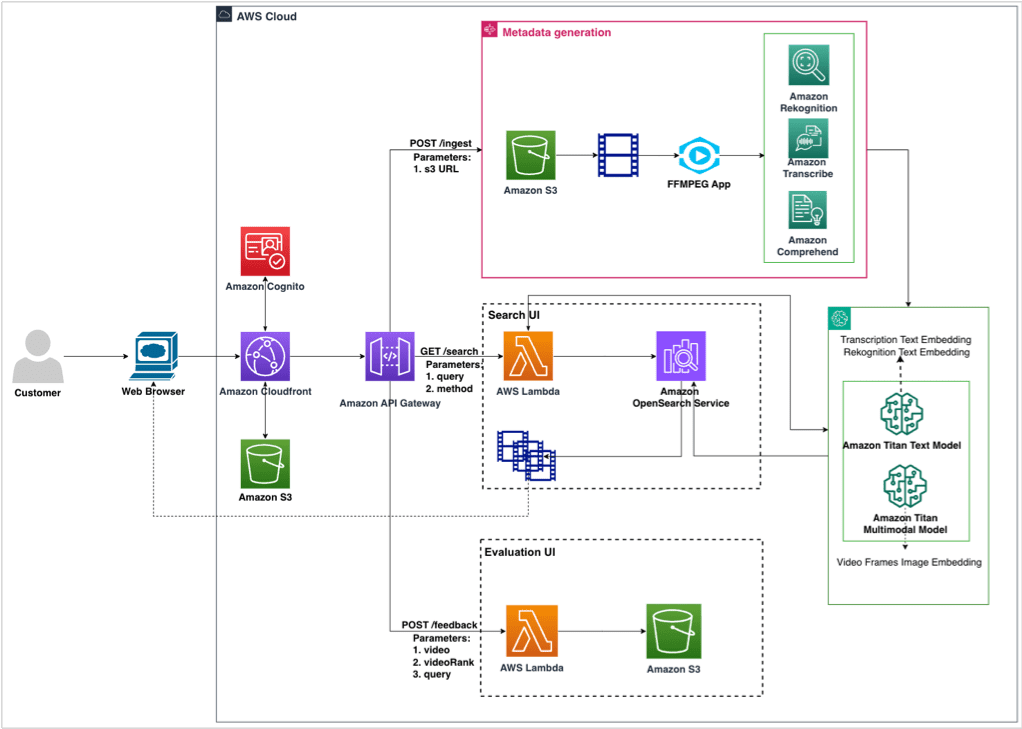
The current architecture consists of three components:
- Metadata generation – This component generates metadata from a video archive, processes it, and creates embeddings for search indexing. The videos from Amazon S3 are retrieved and converted to H264 vcodec format using the FFmpeg library. The processed videos are sent to AWS services like Amazon Rekognition, Amazon Transcribe, and Amazon Comprehend to generate metadata at shot level and video level. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service. We use AWS Step Functions to orchestrate the entire pipeline.
- Search – A UI-based video search pipeline takes in the user query as input and retrieves relevant videos. The user query invokes a Lambda function. Based on the search method selected, you either perform a text- or keyword-based search or an embedding-based search. The search body is sent to OpenSearch Service to retrieve video results at the shot level, which is displayed to the user.
- Evaluation – The UI enables you to perform qualitative evaluation against different search settings. You enter a query and, based on the search settings, video results are retrieved from OpenSearch. You can view the results and provide feedback by voting for the winning setting.
The following diagram illustrates the solution architecture.
The high-level takeaways from this work are the following:
- Using an Amazon Rekognition API to detect shots and index them achieved better retrieving recall (at least 50% improvement) than performing the same on the video level
- Incorporating the Amazon Titan Text Embeddings model to semantically retrieve the video results instead of using raw text generated by Amazon Rekognition and Amazon Transcribe boosted the recall performance by 52%
- The Amazon Titan Multimodal Embeddings model showed high capability to encode visual information of video image frames and achieved the best performance when combined with text embeddings of Amazon Rekognition and Amazon Transcribe text metadata, improving on baseline metrics by up to three times
- The A/B evaluation UI that we developed to test new search methods and features proved to be effective
Detailed quantitative analysis of these conclusions is discussed later in this post.
Metadata generation pipeline
The video metadata generation pipeline consists of processing video files using AWS services such as Amazon Transcribe, Amazon Rekognition, and Amazon Comprehend, as shown in the following diagram. The metadata is generated at the shot level for a video.
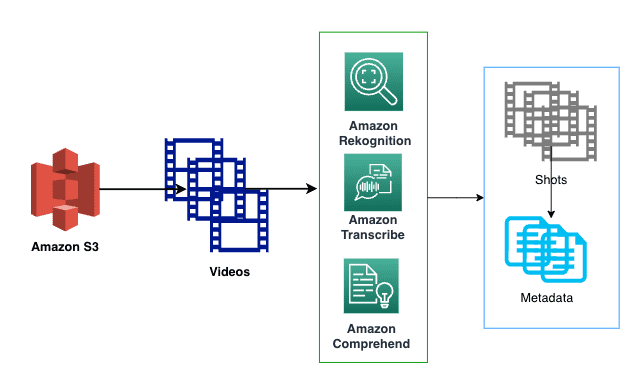
In this section, we discuss the details of each service and the workflow in more detail.
Amazon Transcribe
The transcription for the entire video is generated using the StartTranscriptionJob API. When the job is complete, you can obtain the raw transcript data using GetTranscriptionJob. The GetTranscriptionJob returns a TranscriptFileUri, which can be processed to get the speakers and transcripts based on a timestamp. The file formats supported by Amazon Transcribe are AMR, FLAC (recommended), M4A, MP3, MP4, Ogg, WebM, and WAV (recommended).
The raw transcripts are further processed to be stored using timestamps, as shown in the following example.

Amazon Rekognition
Amazon Rekognition requires the video to be encoded using the H.264 codec and formatted to either MPEG-4 or MOV. We used FFmpeg to format the videos in Amazon S3 to the required vcodec. FFmpeg is a free and open-source software project in the form of a command line tool designed for processing video, audio, and other multimedia files and streams. Python provides a wrapper library around the tool called ffmpeg-python.
The solution runs Amazon Rekognition APIs for label detection, text detection, celebrity detection, and face detection on videos. The metadata generated for each video by the APIs is processed and stored with timestamps. The videos are then segmented into individual shots. With Amazon Rekognition, you can detect the start, end, and duration of each shot as well as the total shot count for a content piece. The video shot detection job starts with the StartSegmentDetection API, which returns a jobId that can be used to monitor status with the GetSegmentDetection API. When the video segmentation status changes to Succeeded, for each shot, you parse the previously generated Amazon Rekognition API metadata using the shot’s timestamp. You then append this parsed metadata to the shot record. Similarly, the full transcript from Amazon Transcribe is segmented using the shot start and end timestamps to create shot-level transcripts.
Amazon Comprehend
The temporal transcripts are then processed by Amazon Comprehend to detect entities and sentiments using the DetectEntities, DetectSentiment, and DetectTargetedSentiment APIs. The following code gives more details on the API requests and responses used to generate metadata by using sample shot-level metadata generated for a video:

Metadata processing
The shot-level metadata generated by the pipeline is processed to stage it for embedding generation. The goal of this processing is to aggregate useful information and remove null or less significant information that wouldn’t add value for embedding generation.
The processing algorithm is as follows:
rekognition_metadata
- shot_metadata: extract StartFrameNumber and EndFrameNumber
- celeb_metadata: extract celeb_metadata
- label_metadata: extract unique labels
- text_metadata: extract unique text labels if there are more than 3 words (comes noisy with "-", "null" and other values)
- face_analysis_metadata: extract unique list of AgeRange, Emotions, Gender
We combine all rekognition text data into `rek_text_metadata` string
transcribe_metadata
- transcribe_metadata: check the wordcount of the conversation across all speakers.
if it is more than 50 words, mark it for summarization task with Amazon Bedrock
comprehend_metadata
- comprehend_metadata: extract sentiment
- comprehend_metadata: extract target sentiment scores for words with score > 0.9
Large transcript summarization
Large transcripts from the processed metadata are summarized through the Anthropic Claude 2 model. After summarizing the transcript, we extract the names of the key characters mentioned in the summary as well the important keywords.
Embeddings generation
In this section, we discuss the details for generating shot-level and video-level embeddings.
Shot-level embeddings
We generate two types of embeddings: text and multimodal. To understand which metadata and service contributes to the search performance and by how much, we create a varying set of embeddings for experimental analysis.
We implement the following with Amazon Titan Multimodal Embeddings:
- Embed image:
- TMM_shot_img_embs – We sample the middle frame from every shot and embed them. We assume the middle frame in the shot captures the semantic nuance in the entire shot. You can also experiment with embedding all the frames and averaging them.
- TMM_rek_text_shot_emb – We sample the middle frame from every shot and embed it along with Amazon Rekognition text data.
- TMM_transcribe_shot_emb – We sample the middle frame from every shot and embed it along with Amazon Transcribe text data.
- Embed text (to compare if the text data is represented well with the LLM or multimodal model, we also embed them with Amazon Titan Multimodal):
- TMM_rek_text_emb – We embed the Amazon Rekognition text as multimodal embeddings without the images.
- TMM_transcribe_emb – We embed the Amazon Transcribe text as multimodal embeddings without the images.
We implement the following with the Amazon Titan Text Embeddings model:
- Embed text:
- TT_rek_text_emb – We embed the Amazon Rekognition text as text embeddings
- TT_transcribe_emb – We embed the Amazon Transcribe text as text embeddings
Video-level embeddings
If a video has only one shot (a small video capturing a single action), the embeddings will be the same as shot-level embeddings.
For videos that have more than one shot, we implement the following using the Amazon Titan Multimodal Embeddings Model:
- Embed image:
- TMM_shot_img_embs – We sample K images with replacement across all the shot-level metadata, generate embeddings, and average them
- TMM_rek_text_shot_emb – We sample K images with replacement across all the shot-level metadata, embed it along with Amazon Rekognition text data, and average them.
- TMM_transcribe_shot_emb – We sample K images with replacement across all the shot-level metadata, embed it along with Amazon Transcribe text data, and average them
- Embed text:
- TMM_rek_text_emb – We combine all the Amazon Rekognition text data and embed it as multimodal embeddings without the images
- TMM_transcribe_emb – We combine all the Amazon Transcribe text data and embed it as multimodal embeddings without the images
We implement the following using the Amazon Titan Text Embeddings model:
- Embed text:
- TT_rek_text_emb – We combine all the Amazon Rekognition text data and embed it as text embeddings
- TT_transcribe_emb – We combine all the Amazon Transcribe text data and embed it as text embeddings
Search pipeline
In this section, we discuss the components of the search pipeline.
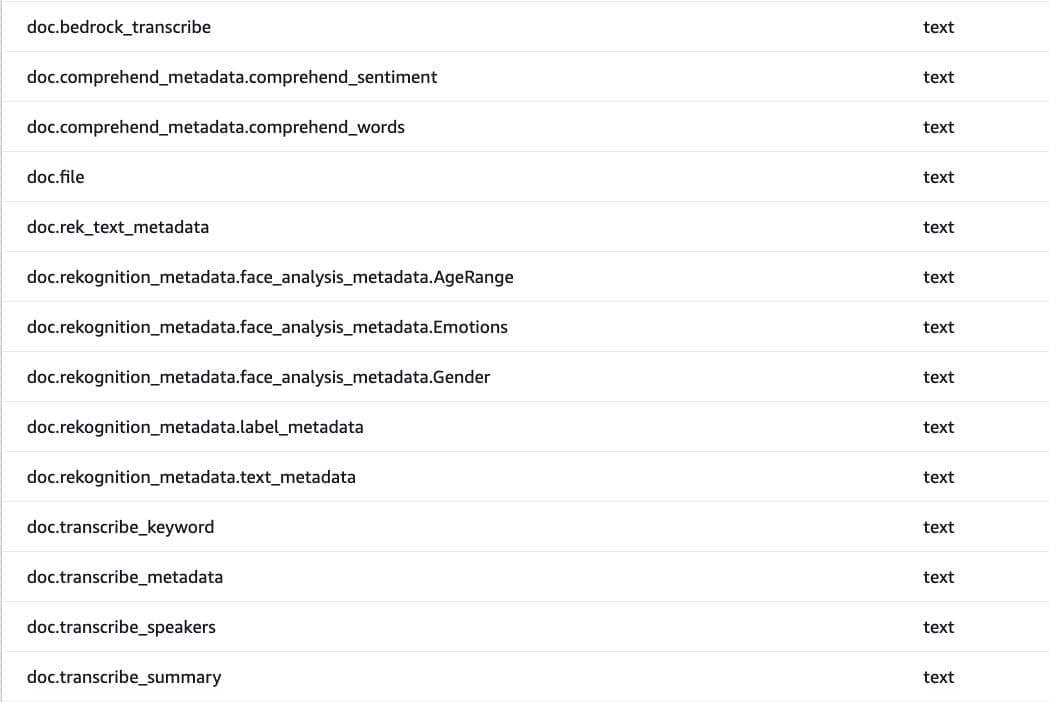
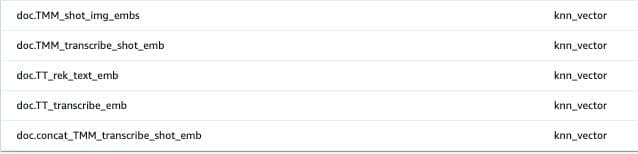
Search index creation
We use an OpenSearch cluster (OpenSearch Service domain) with t3.medium.search to store and retrieve indexes for our experimentation with text, knn_vector, and Boolean fields indexed. We recommend exploring Amazon OpenSearch Serverless for production deployment for indexing and retrieval. OpenSearch Serverless can index billions of records and has expanded its auto scaling capabilities to efficiently handle tens of thousands of query transactions per minute.
The following screenshots are examples of the text, Boolean, and embedding fields that we created.

Query flow
The following diagram illustrates the query workflow.
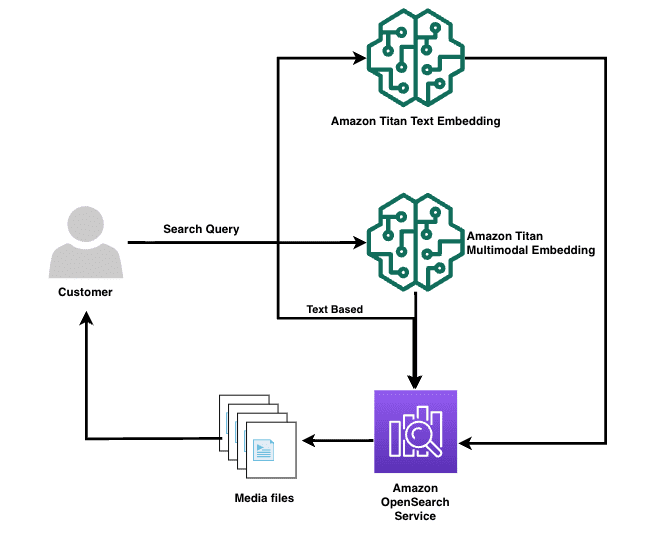
You can use a user query to compare the video records using text or semantic (embedding) search for retrieval.
For text-based retrieval, we use the search query as input to retrieve results from OpenSearch Service using the search fields transcribe_metadata, transcribe_summary, transcribe_keyword, transcribe_speakers, and rek_text_metadata:
OpenSearch Input
search_fields=[
"transcribe_metadata",
"transcribe_summary",
"transcribe_keyword",
"transcribe_speakers",
"rek_text_metadata"
]search_body = {
"query": {
"multi_match": {
"query": search_query,
"fields": search_fields
}
}
}For semantic retrieval, the query is embedded using the amazon.Titan-embed-text-v1 or amazon.titan-embed-image-v1 model, which is then used as an input to retrieve results from OpenSearch Service using the search field name, which could match with the metadata embedding of choice:
OpenSearch Input
search_body = {
"size": Search results combination
Exact match and semantic search have their own benefits depending on the application. Users who search for a specific celebrity or movie name would benefit from an exact match search, whereas users looking for thematic queries like “summer beach vibes” and “candlelit dinner” would find semantic search results more applicable. To enable the best of both, we combine the results from both types of searches. Additionally, different embeddings could capture different semantics (for example, Amazon Transcribe text embedding vs. image embedding with a multimodal model). Therefore, we also explore combining different semantic search results.
To combine search results from different search methods and different score ranges, we used the following logic:
- Normalize the scores from each results list independently to a common 0–1 range using
rank_norm. - Sum the weighted normalized scores for each result video from all the search results.
- Sort the results based on the score.
- Return the top K results.
We use the rank_norm method, where the score is calculated based on the rank of each video in the list. The following is the Python implementation of this method:
def rank_norm(results):
n_results = len(results)
normalized_results = {}
for i, doc_id in enumerate(results.keys()):
normalized_results[doc_id] = 1 - (i / n_results)
ranked_normalized_results = sorted(
normalized_results.items(), key=lambda x: x[1], reverse=True
)
return dict(ranked_normalized_results)
Evaluation pipeline
In this section, we discuss the components of the evaluation pipeline.
Search and evaluation UI
The following diagram illustrates the architecture of the search and evaluation UI.
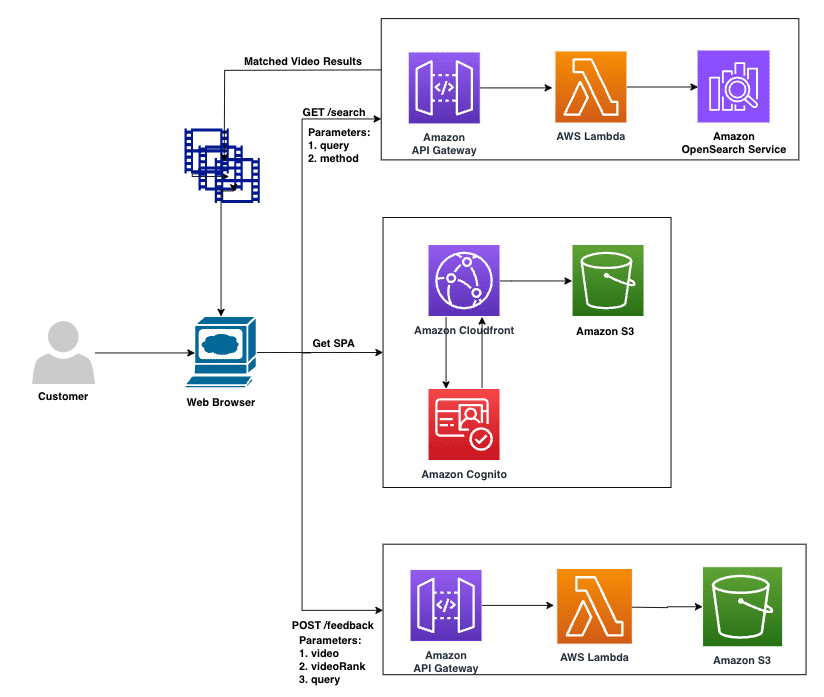
The UI webpage is hosted in an S3 bucket and deployed using Amazon CloudFront distributions. The current approach uses an API key for authentication. This can be enhanced by using Amazon Cognito and registering users. The user can perform two actions on the webpage:
- Search – Enter the query to retrieve video content
- Feedback – Based on the results displayed for a query, vote for the winning method
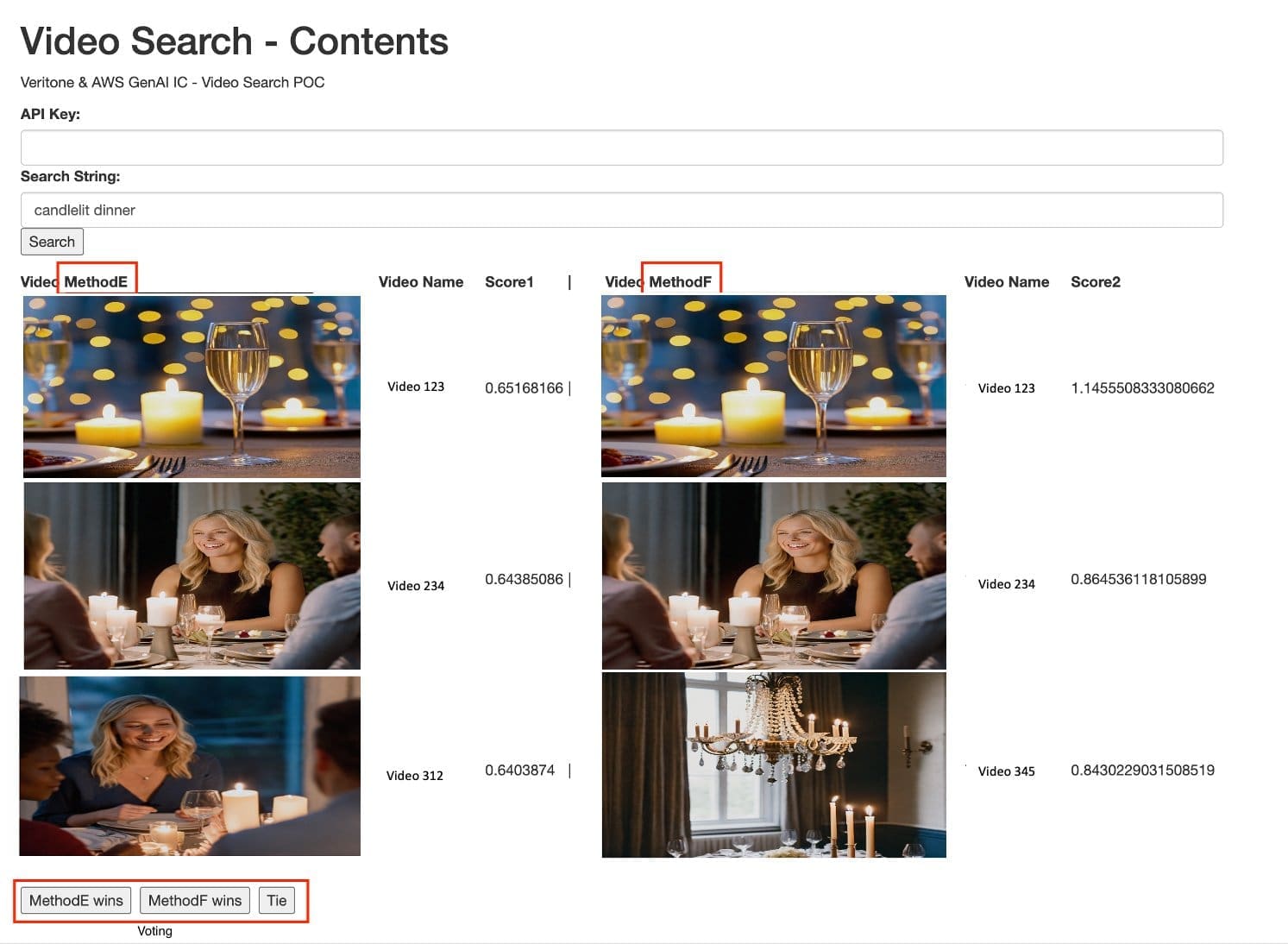
We create two API endpoints using Amazon API Gateway: GET /search and POST /feedback. The following screenshot illustrates our UI with two retrieval methods that have been anonymized for the user for a bias-free evaluation.
GET /search
We pass two QueryStringParameters with this API call:
- query – The user input query
- method – The method the user is evaluating
This API is created with a proxy integration with a Lambda function invoked. The Lambda function processes the query and, based on the method used, retrieves results from OpenSearch Service. The results are then processed to retrieve videos from the S3 bucket and displayed on the webpage. In the search UI, we use a specific method (search setting) to retrieve results:
Request
?query=<>&method=<>
Response
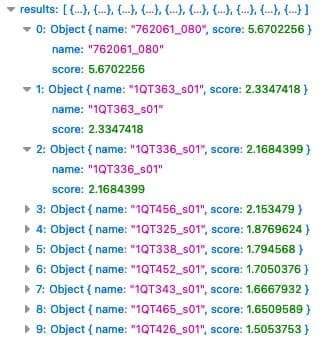
{
"results": [
{"name": , "score": The following is a sample request:
?query=candlelit dinner&method=MethodB
The following screenshot shows our results.
POST /feedback
Given a query, each method will have video content and the video name displayed on the webpage. Based on the relevance of the results, the user can vote if a particular method has better performance over the other (win or lose) or if the methods are tied. The API has a proxy connection to Lambda. Lambda stores these results into an S3 bucket. In the evaluation UI, you can analyze the method search results to find the best search configuration setting. The request body includes the following syntax:
Request Body
{
"result": The following screenshot shows a sample request.

Experiments and results
In this section, we discuss the datasets used in our experiments and the quantitative and qualitative evaluations based on the results.
Short videos dataset
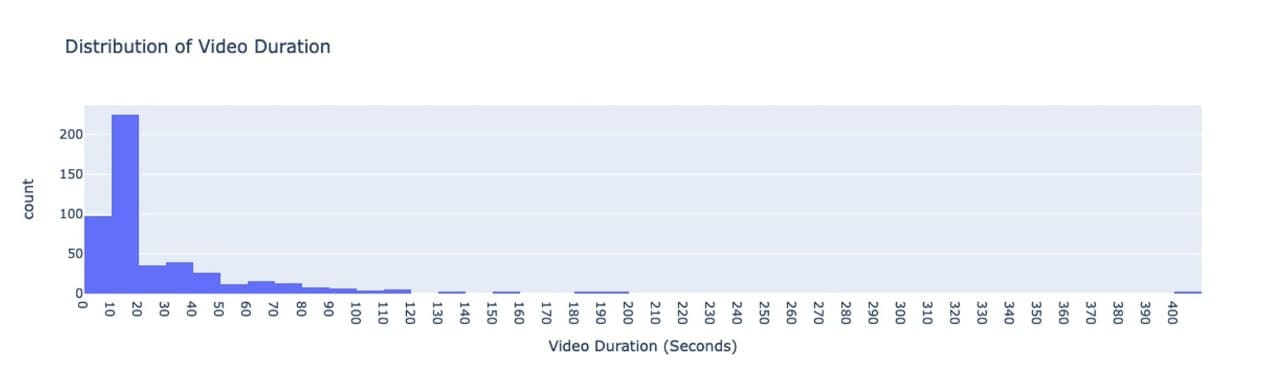
This dataset includes 500 videos with an average length of 20 seconds. Each video has manually written metadata such as keywords and descriptions. In general, the videos in this dataset are related to travel, vacations, and restaurants topics.
The majority of videos are less than 20 seconds and the maximum is 400 seconds, as illustrated in the following figure.
Long videos dataset
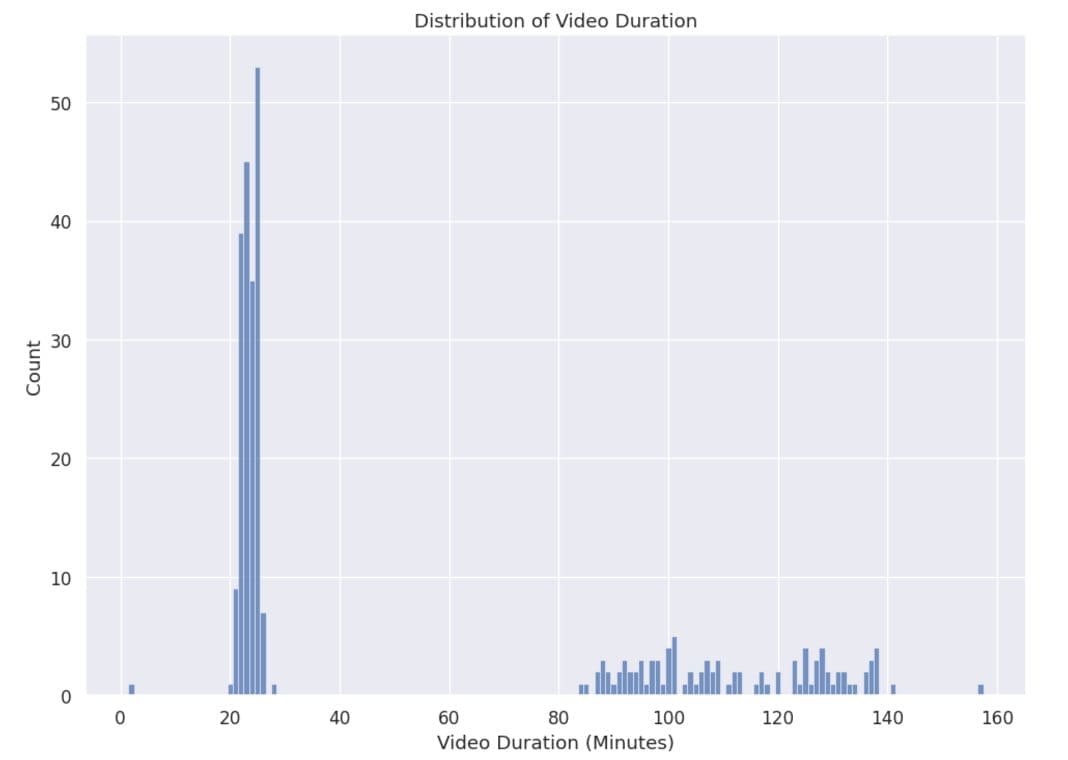
The second dataset has 300 high-definition videos with a video length ranging from 20–160 minutes, as illustrated in the following figure.
Quantitative evaluation
We use the following metrics in our quantitative evaluation:
- Mean reciprocal rank – Mean reciprocal rank (MRR) measures the inverse of the position number of the most relevant item in search results.
- Recall@topK – We measure recall at topk as the percentage of correctly retrieved video out of the desired video search results (ground truth). For example:
A, B, C are related (GT)
A, D, N, M, G are the TopK retrieved videos
Recall @TOP5 = 1/3
We compute these metrics using a ground truth dataset provided by Veritone that had mappings of search query examples to relevant video IDs.
The following table summarizes the top three retrieval methods from the long videos dataset (% improvement over baseline).
| Methods | Video Level: MRR vs. Video-level Baseline MRR | Shot Level: MRR vs. Video-level Baseline MRR | Video Level: Recall@top10 vs. Video-level Baseline Recall@top10 | Shot Level: Recall@top10 vs. Video-level Baseline Recall@top10 |
| Raw Text: Amazon Transcribe + Amazon Rekognition | Baseline comparison | N/A | . | . |
| Semantic: Amazon Transcribe + Amazon Rekognition | 0.84% | 52.41% | 19.67% | 94.00% |
| Semantic: Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal | 37.31% | 81.19% | 71.00% | 93.33% |
| Semantic: Amazon Transcribe + Amazon Titan Multimodal | 15.56% | 58.54% | 61.33% | 121.33% |
The following are our observations on the MRR and recall results:
- Overall shot-level retrieval outperforms the video-level retrieval baseline across both MRR and recall metrics.
- Raw text has lower MRR and recall scores than embedding-based search on both video and shot level. All three semantic methods show improvement in MRR and recall.
- Combining semantic (Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal) yields the best improvement across video MRR, shot MRR, and video recall metrics.
The following table summarizes the top three retrieval methods from the short videos dataset (% improvement over baseline).
| Methods | Video Level: MRR vs. Video-level Baseline MRR | Shot Level: MRR vs. Video-level Baseline MRR | Video Level: Recall@top10 vs. Video-Level Baseline Recall@top10 | Shot Level: Recall@top10 vs. Video-level Baseline Recall@top10 |
| Raw Text: Amazon Transcribe + Amazon Rekognition | Baseline | N/A | Baseline | N/A |
| Semantic: Amazon Titan Multimodal | 226.67% | 226.67% | 373.57% | 382.61% |
| Semantic: Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal | 100.00% | 60.00% | 299.28% | 314.29% |
| Semantic: Amazon Transcribe + Amazon Titan Multimodal | 53.33% | 53.33% | 307.21% | 312.77% |
We made the following observations on the MRR and recall results:
- Encoding the videos using the Amazon Titan Multimodal Embeddings model alone yields the best result compared to adding just Amazon Transcribe, Amazon Transcribe + Rekognition, or Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal Embeddings (due to lack of dialogue and scene changes in these short videos)
- All semantic retrieval methods (2, 3, and 4) should at least have 53% improvement over the baseline
- Although Amazon Titan Multimodal alone works well for this data, it should be noted that other metadata like Amazon Transcribe, Amazon Rekognition, and pre-existing human labels as semantic representation retrieval can be augmented with Amazon Titan Multimodal Embeddings to improve performance depending on the nature of the data
Qualitative evaluation
We evaluated the quantitative results from our pipeline to find matches with the ground truth shared by Veritone. However, there could be other relevant videos in the retrieved results from our pipeline that are not part of the ground truth, which could further improve some of these metrics. Therefore, to qualitatively evaluate our pipeline, we used an A/B testing framework, where a user can view results from two anonymized methods (the metadata used by the method is not exposed to reduce any bias) and rate which results were more aligned with the query entered.
The aggregated results across the method comparison were used to calculate the win rate to select the final embedding method for search pipeline.
The following methods were shortlisted based on Veritone’s interest to reduce multiple comparison methods.
| Method Name (Exposed to User) | Retrieval Type (Not Exposed to User) |
| Method E | Just semantic Amazon Transcribe retrieval results |
| Method F | Fusion of semantic Amazon Transcribe + Amazon Titan Multimodal retrieval results |
| Method G | Fusion of semantic Amazon Transcribe + semantic Amazon Rekognition + Amazon Titan Multimodal retrieval results |
The following table summarizes the quantitative results and winning rate.
| Experiment | Winning Method (Count of Queries) | . | . |
| Method E | Method F | Tie | |
| Method E vs. Method F | 10% | 85% | 5% |
| Method F | Method G | Tie | |
| Method F vs. Method G | 30% | 60% | 10% |
Based on the results, we see that adding Amazon Titan Multimodal Embeddings to the transcription method (Method F) is better than just using semantic transcription retrieval (Method E). Adding Amazon Rekognition based retrieval results (Method G) improves over Method F.
Takeaways
We had the following key takeaways:
- Enabling vector search indexing and retrieving instead of relying only on text matching with AI generated text metadata improves the search recall.
- Indexing and retrieving videos at the shot level can boost performance and improve customer experience. Users can efficiently find precise clips matching their query rather than sifting through entire videos.
- Multimodal representation of queries and metadata through models trained on both images and text have better performance over single modality representation from models trained on just textual data.
- The fusion of text and visual cues significantly improves search relevance by capturing semantic alignments between queries and clips more accurately and semantically capturing the user search intent.
- Enabling direct human comparison between retrieval models through A/B testing allows for inspecting and selecting the optimal approach. This can boost the confidence to ship new features or search methods to production.
Security best practices
We recommend the following security guidelines for building secure applications on AWS:
- Building secure machine learning environments with Amazon SageMaker
- Control root access to a SageMaker notebook instance
- Amazon S3 security
- Data protection in Amazon Cognito
Conclusion
In this post, we showed how Veritone upgraded their classical search pipelines with Amazon Titan Multimodal Embeddings in Amazon Bedrock through a few API calls. We showed how videos can be indexed in different representations, text vs. text embeddings vs. multimodal embeddings, and how they can be analyzed to produce a robust search based on the data characteristics and use case.
If you are interested in working with the AWS Generative AI Innovation Center, please reach out to the GenAIIC.
About the Authors
 Tim Camara is a Senior Product Manager on the Digital Media Hub team at Veritone. With over 15 years of experience across a range of technologies and industries, he’s focused on finding ways to use emerging technologies to improve customer experiences.
Tim Camara is a Senior Product Manager on the Digital Media Hub team at Veritone. With over 15 years of experience across a range of technologies and industries, he’s focused on finding ways to use emerging technologies to improve customer experiences.
 Mohamad Al Jazaery is an Applied Scientist at the Generative AI Innovation Center. As a scientist and tech lead, he helps AWS customers envision and build GenAI solutions to address their business challenges in different domains such as Media and Entertainment, Finance, and Lifestyle.
Mohamad Al Jazaery is an Applied Scientist at the Generative AI Innovation Center. As a scientist and tech lead, he helps AWS customers envision and build GenAI solutions to address their business challenges in different domains such as Media and Entertainment, Finance, and Lifestyle.

Meghana Ashok is a Machine Learning Engineer at the Generative AI Innovation Center. She collaborates closely with customers, guiding them in developing secure, cost-efficient, and resilient solutions and infrastructure tailored to their generative AI needs.
 Divya Bhargavi is a Senior Applied Scientist Lead at the Generative AI Innovation Center, where she solves high-value business problems for AWS customers using generative AI methods. She works on image/video understanding and retrieval, knowledge graph augmented large language models, and personalized advertising use cases.
Divya Bhargavi is a Senior Applied Scientist Lead at the Generative AI Innovation Center, where she solves high-value business problems for AWS customers using generative AI methods. She works on image/video understanding and retrieval, knowledge graph augmented large language models, and personalized advertising use cases.
 Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he uses his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he uses his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Leave a Reply