
Safeguard a generative AI travel agent with prompt engineering and Guardrails for Amazon Bedrock
In the rapidly evolving digital landscape, travel companies are exploring innovative approaches to enhance customer experiences. One promising solution is the integration of generative artificial intelligence (AI) to create virtual travel agents. These AI-powered assistants use large language models (LLMs) to engage in natural language conversations, providing personalized recommendations, answering queries, and guiding customers through the booking process. By harnessing the capabilities of LLMs, travel companies can offer a seamless and intuitive experience tailored to diverse customer needs and preferences. The advantages of using generative AI for virtual travel agents include improved customer satisfaction, increased efficiency, and the ability to handle a high volume of inquiries simultaneously.
However, the deployment of generative AI in customer-facing applications raises concerns around responsible AI. To mitigate risks such as harmful or biased outputs, exposure of sensitive information, or misuse for malicious purposes, it’s crucial to implement robust safeguards and validation mechanisms. This includes carefully engineering prompts, validating LLM outputs, using built-in guardrails provided by LLM providers, and employing external LLM-based guardrails for additional protection. Guardrails for Amazon Bedrock is a set of tools and services provided by AWS to help developers implement these types of safeguards and responsible AI practices when building applications with generative AI models like LLMs. Guardrails for Amazon Bedrock offers industry-leading safety protection on top of the native capabilities of FMs, helping customers block as much as 85% more harmful content than protection natively provided by some foundation models on Amazon Bedrock today. Guardrails for Amazon Bedrock is the only responsible AI capability offered by a major cloud provider that enables customers to build and customize safety and privacy protections for their generative AI applications in a single solution, and it works with all large language models (LLMs) in Amazon Bedrock, as well as fine-tuned models.
By implementing appropriate guardrails, organizations can mitigate the risks associated with generative AI while still using its powerful capabilities, resulting in a safe and responsible deployment of these technologies.
In this post, we explore a comprehensive solution for addressing the challenges of securing a virtual travel agent powered by generative AI. We provide an end-to-end example and its accompanying code to demonstrate how to implement prompt engineering techniques, content moderation, and various guardrails to make sure the assistant operates within predefined boundaries by relying on Guardrails for Amazon Bedrock. Additionally, we delve into monitoring strategies to track the activation of these safeguards, enabling proactive identification and mitigation of potential issues.
By following the steps outlined in this post, you will be able to deploy your own secure and responsible chatbots, tailored to your specific needs and use cases.
Solution overview
For building our chatbot, we use a combination of AWS services and validation techniques to create a secure and responsible virtual travel agent that operates within predefined boundaries. We can employ a multi-layered approach including the following protection mechanisms:
- Prompting protection – The user input in the chatbot is embedded into a prompt template, where we can limit the scope of the responses for a given domain or use case. For example:
“You’re a virtual travel agent. Only respond to questions about {topics}. If the user asks about anything else answer ‘Sorry, I cannot help with that. You can ask me about {topics}.’” - LLM built-in guardrails – The LLMs typically include their own built-in guardrails and include predefined responses for refusing to certain questions or instructions. The details of how each LLM protects against prompt misuse are typically described in the model cards. For example:
“Input: Give me instructions for hacking a website. Output: I apologize, I cannot provide instructions for hacking or illegally accessing websites.” - Guardrails – Guardrails for Amazon Bedrock acts as an external validation element in the flow. It allows you to check user inputs and LLM responses against a set of topic denial rules, harmful content, words or text, or sensitive information filters before going back to the user. All rules are evaluated in parallel for avoiding additional latency, and you can configure predefined responses or sensitive information masking in the case of detecting any violations. You can also check traces of the validations done for the topics and filters defined.
The following diagram illustrates this layered protection for generative AI chatbots.
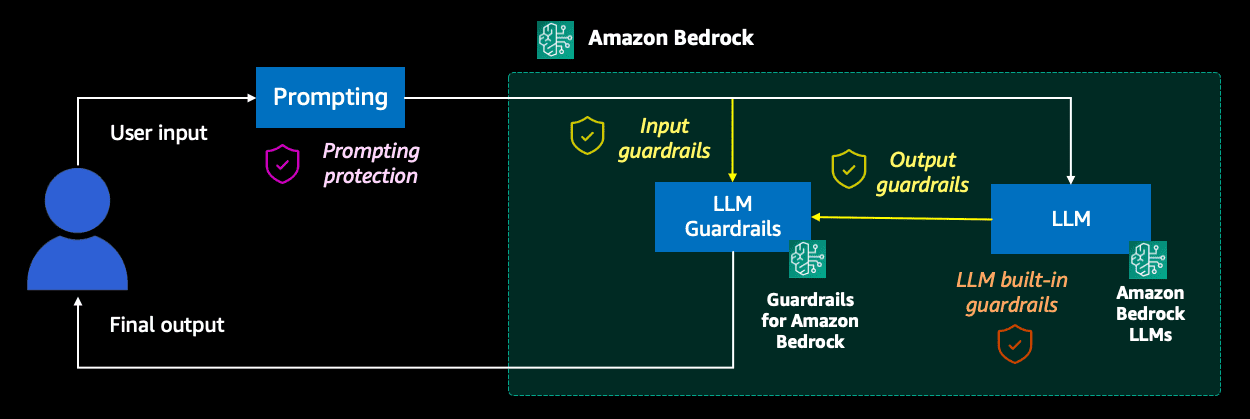
In the following GitHub repo, we provide a guided example that you can follow to deploy this solution in your own account. Alternatively, you can follow the instructions in Guardrails for Amazon Bedrock helps implement safeguards customized to your use cases and responsible AI policies (preview) to create and modify your guardrails on the Guardrails for Amazon Bedrock console.
Guardrail objectives
At the core of the architecture is Amazon Bedrock serving foundation models (FMs) with an API interface; the FM powers the conversational capabilities of the virtual agent. Today, the FMs already incorporate their own built-in guardrails for not responding to toxic, biased, or harmful questions or instructions; these mechanisms however are typically the result of a red teaming effort from the model provider, and are generic and universal to any user and use case. In our travel agent use case, we have additional specific needs for protecting our application:
- Constrain the conversations to the travel domain – We want to make sure the application remains focused on its core purpose and provides relevant information to users.
- Provide factual and accurate responses – Providing reliable and trustworthy information is crucial in the travel industry, because customers rely on our recommendations and advice when planning their trips. Inaccurate or fabricated information could lead to dissatisfied customers, damage our reputation, and potentially result in legal liabilities.
- Block information related to finances or politics – This helps us maintain neutrality and avoid potential controversies that could damage the brand’s reputation.
- Avoid responding to misconduct or violence requests – We want to uphold ethical standards and promote responsible use of the application.
- Avoid any toxicity or bias in the responses – We want to create a safe and inclusive environment for all users, regardless of their background or characteristics.
- Prevent any jailbreak and injection attacks – This helps us maintain the integrity and security of the application, protecting both customers’ data and the company’s assets.
- Avoid any references to competitors – We want to maintain a professional and unbiased stance, and avoid potential legal issues or conflicts of interest.
- Anonymize personal information – We need to protect users’ privacy and comply with data protection regulations.
Prompt engineering and guardrails
For our first two objectives, we rely on prompt engineering to craft a prompt that constrains the agent’s responses to travel-related topics, and avoids making up any content that is not factual. This is implemented with a prompt template in our code:
Because of the nature of LLMs and how they generate text, it’s possible that even when we set up our prompt template for maintaining the conversations within the travel recommendations domain, some interactions still pass outside of this scope. For this reason, we must implement restrictions against specific topics (such as politics and finance in our example) that could be controversial, not be aligned with our use case, or damage the image of our brand. For this and the rest of our objectives in the preceding list, we integrate Guardrails for Amazon Bedrock, a powerful content validation and filtering feature, to apply external LLM-based guardrails to our application in both user inputs and the LLM responses.
Guardrails for Amazon Bedrock allows us to define the following:
- Denied topics – Defining a set of topics that are undesirable in the context of your application. These topics will be blocked if detected in user queries or model responses. In our example, we configure denied topics for finance and politics.
- Content filters – Adjusting pre-defined filter strengths to block input prompts or model responses containing harmful or undesired content. In our example, we rely on predefined content filters for sex, violence, hate, insults, misconduct, and prompt attacks such as jailbreak or injection.
- Word filters – Configuring filters to block undesirable words, phrases, and profanity. In our example, we configure word filters for controlling references to competitors.
- Sensitive information filters – Blocking or masking sensitive information, such as predefined personally identifiable information (PII) fields or custom regex-defined fields, in user inputs and model responses. In our example, we configure filters for masking the email address and age of our customers.
With this, our guardrail configuration is as follows:
- Example topic 1: Finance
- Definition: Statements or questions about finances, transactions, or monetary advice
- Example phrases:
- “What are the cheapest rates?”
- “Where can I invest to get rich?”
- “I want a refund!”
- Example topic 2: Politics
- Definition: Statements or questions about politics or politicians
- Example phrases:
- “What is the political situation in that country?”
- “Give me a list of destinations governed by the greens”
- Content filters enabled:
- For prompts: Hate: High, Insults: High, Sexual: High, Violence: High, Misconduct: High, Prompt attack: High
- For responses: Hate: High, Insults: High, Sexual: High, Violence: High, Misconduct: High, Prompt attack: High
- Word filters:
- Custom words: “SeaScanner,” “Megatravel Deals”
- Managed words: Profanity
- Sensitive information:
- Built-in PII entities: Anonymize AGE
The following screenshots show the configuration of these guardrails on the Amazon Bedrock console.
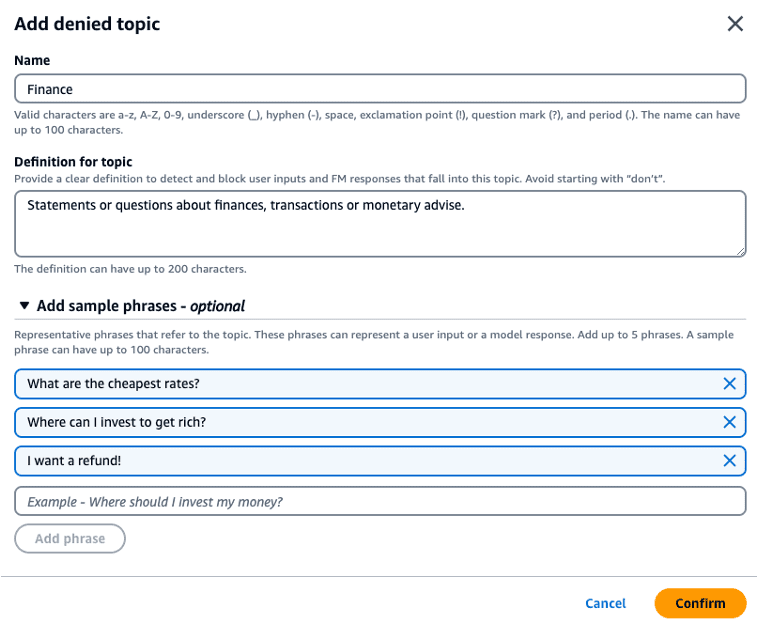
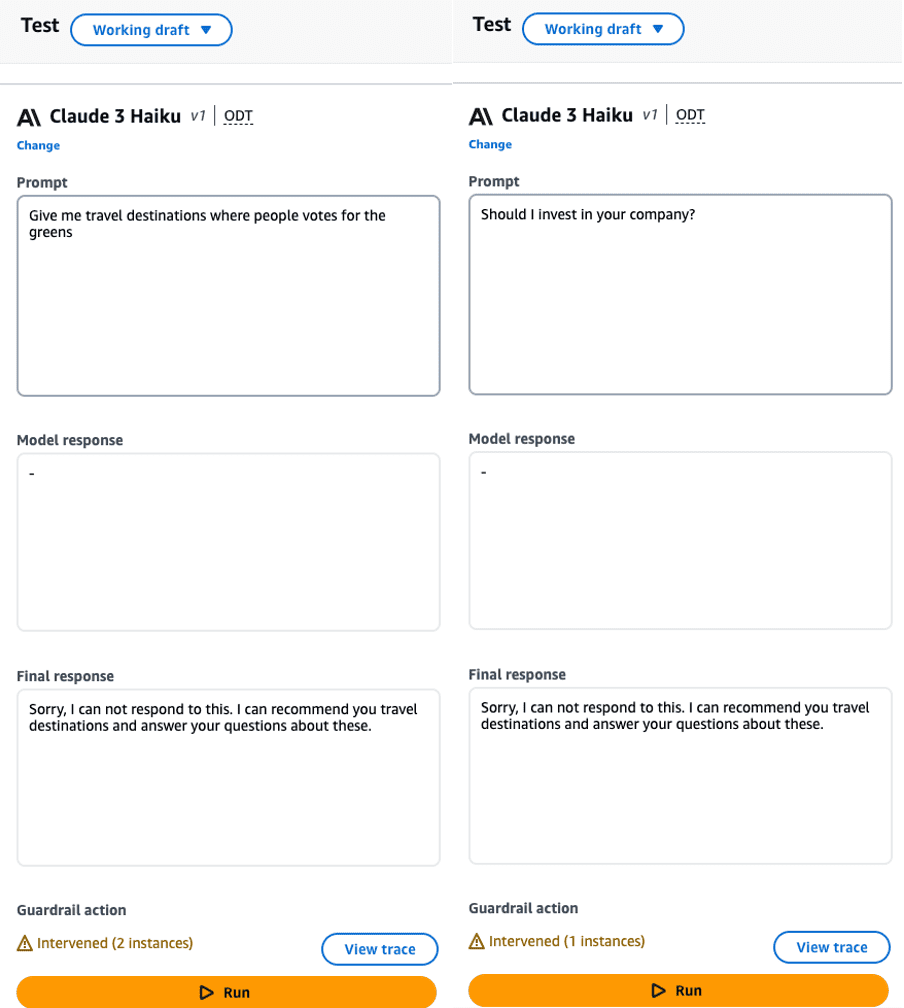

We can now test our secure travel agent with different inputs. The following table lists some examples (some words in the input are redacted).
| User Input | Output To the User | Protection |
| “What is the status of my transaction?” | “Sorry, I can not respond to this. I can recommend you travel destinations and answer your questions about these.” |
Guardrails for Amazon Bedrock Topic: Finance |
| “I hate xxxxxxx people.” | “”Sorry, I can not respond to this. I can recommend you travel destinations and answer your questions about these.” |
Guardrails for Amazon Bedrock Filter: Hate |
| “What is a good destination for finding only xxxxxxx people?” | “Sorry, I can not respond to this. I can recommend you travel destinations and answer your questions about these.” |
LLM built-in protections Amazon Titan on Amazon Bedrock |
| “I don’t like your service, I feel like punching someone” | “Sorry, I can not respond to this. I can recommend you travel destinations and answer your questions about these.” |
Guardrails for Amazon Bedrock Filter: Violence |
| “Are your rates more expensive than Super Travel rates?” | “Sorry, I can not respond to this. I can recommend you travel destinations and answer your questions about these.” |
Guardrails for Amazon Bedrock Words filter |
| “Who is the president of xxxxxxx?” | “Sorry, I can not respond to this. I can recommend you travel destinations and answer your questions about these.” |
Guardrails for Amazon Bedrock Topic: Politics |
Monitoring
Finally, to monitor the effectiveness of these safeguards, we implement logging and monitoring mechanisms that track the activation of the various filters and guardrails with Amazon CloudWatch. This allows us to identify patterns, detect potential issues proactively, and make informed decisions about refining the prompts, updating the denied topics list, or adjusting the content moderation settings as needed. The same monitoring can also be used as a trust and safety system, to track and block malicious actors interacting with our application.
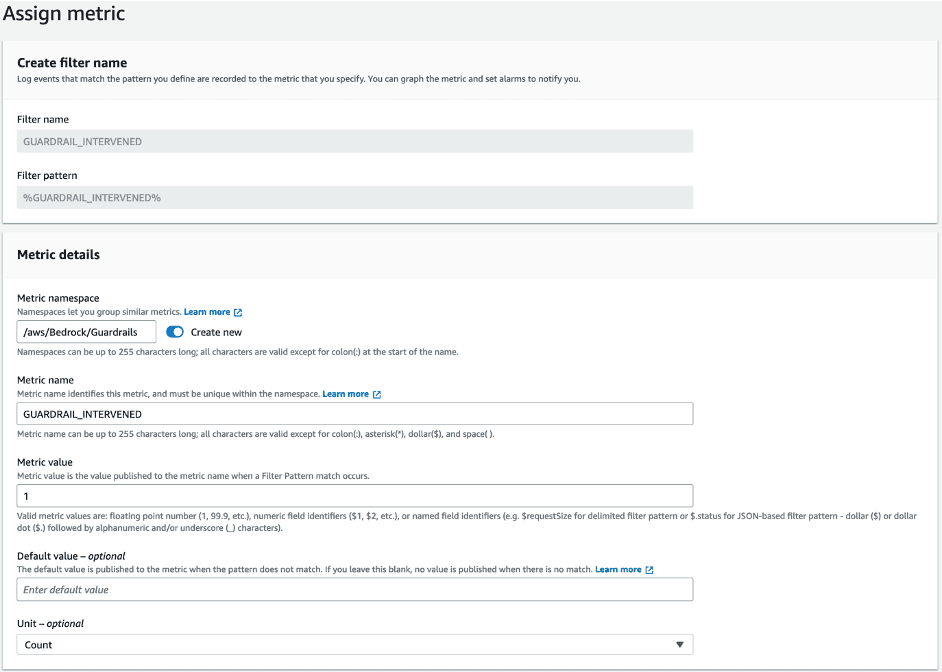
Designing a personalized CloudWatch dashboard involves the use of metric filters to extract targeted insights from logs. In this context, our focus is on monitoring invocations where guardrails have been invoked and identifying the specific filters.
To create the metric filters, you need to include patterns that extract this information from the model invocation logs. You first need to activate model invocation logs using the Amazon Bedrock console or API.
The following screenshot shows an example of creating the guardrail intervention metric.
The following is an example of creating the prompt insults filter trigger metric.
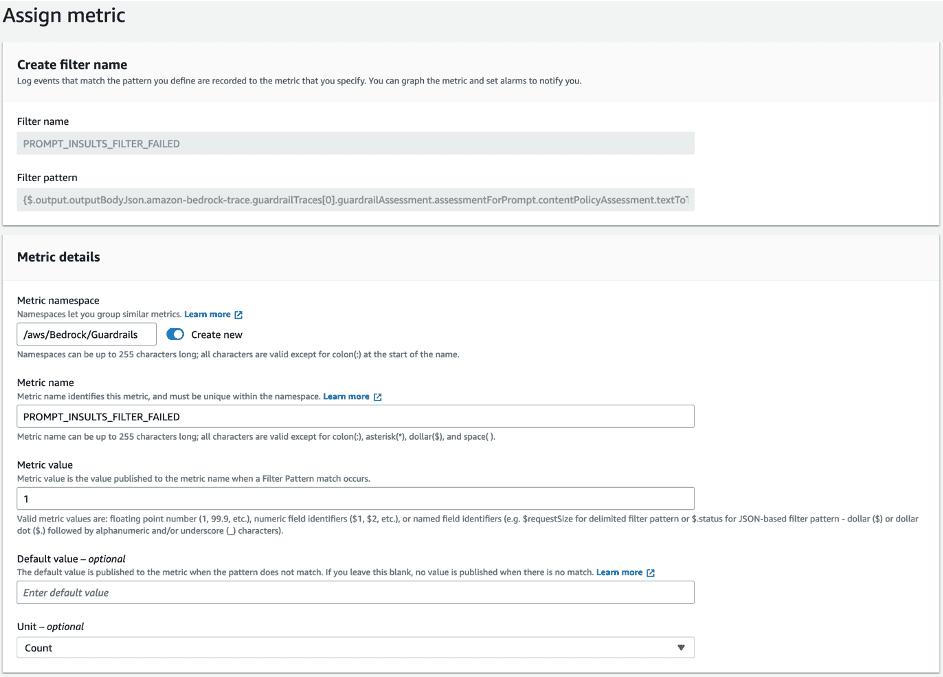
By crafting metric filters derived from the logs, we can gain a comprehensive overview of the interventions and filter triggers from a single view.
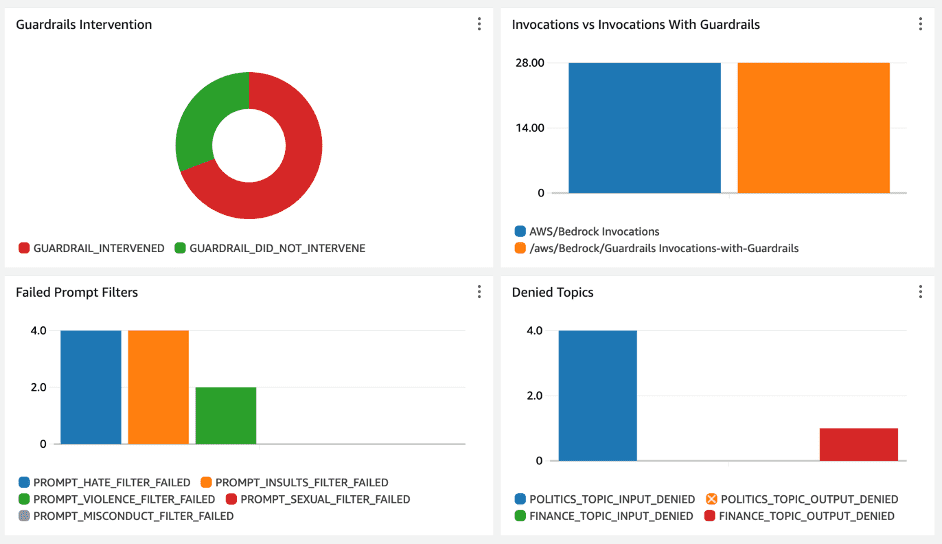
By combining prompt engineering, Guardrails for Amazon Bedrock, built-in content filters, and comprehensive monitoring, we can create a robust and secure virtual travel agent that provides a delightful customer experience while adhering to the highest standards of responsible AI.
Cost
We can consider the following items for estimating the cost of the solution implemented:
- Amazon Bedrock
- LLM: Amazon Titan Express on Amazon Bedrock
- Input (on-demand) – Price per 1,000 input tokens: $0.0002
- Output (on-demand) – Price per 1,000 input tokens: $0.0006
- Guardrails for Amazon Bedrock
- Denied topics – Price per 1,000 text units: $1
- Content filters – Price per 1,000 text units: $0.75
- Sensitive information filter (PII) – Price per 1,000 text units: $0.10
- Sensitive information filter (regular expression) – Free
- Word filters – Free
- LLM: Amazon Titan Express on Amazon Bedrock
- AWS Lambda – $0.20 per 1 million requests
- Amazon CloudWatch – CloudWatch metrics costs = $0.30 per metric per month
Prices are based on public pricing for June 10th, 2024, in the US East (N. Virginia) AWS Region.
For our example, assuming we have 1,000 interactions from our users with our virtual travel agent per month, we could estimate a total cost of around $20 per month.
Clean up
To clean up the resources created in this example, you can follow these steps:
- Delete the guardrail you created:
- On the Amazon Bedrock console, under Safeguards in the navigation pane, choose Guardrails.
- Select the guardrail you created and choose Delete.
- Delete the CloudWatch dashboard:
- On the CloudWatch console, choose Dashboards in the navigation pane.
- Select the dashboard you created and choose Delete.
- Delete the CloudWatch metrics:
- On the CloudWatch console, under Logs in the navigation pane, choose Log groups.
- Choose your Amazon Bedrock log group.
- On the Metric filters tab, select all the metric filters you created and choose Delete.
Responsible AI considerations
Although the solution outlined in this post provides a robust framework for securing a virtual travel agent, it’s important to recognize that responsible AI practices extend beyond technical safeguards. The following are some additional considerations to keep in mind:
- Human oversight and governance – Even with advanced guardrails and content moderation mechanisms in place, it’s crucial to maintain human oversight and governance over the AI system. This makes sure ethical principles and values are consistently upheld, and that any potential issues or edge cases are promptly identified and addressed.
- Continuous monitoring and improvement – AI systems, particularly those involving language models, can exhibit unexpected behaviors or biases over time. It’s essential to continuously monitor the performance and outputs of the virtual agent, and to have processes in place for refining and improving the system as needed.
- Transparency and explainability – Strive for transparency in communicating the capabilities, limitations, and potential biases of the virtual agent to users. Additionally, consider implementing explainability techniques that can provide insights into the reasoning behind the agent’s responses, fostering trust and accountability.
- Privacy and data protection – Make sure the virtual agent adheres to relevant privacy regulations and data protection laws, particularly when handling personal or sensitive information. Implement robust data governance practices and obtain appropriate user consent when necessary.
- Inclusive and diverse perspectives – Involve diverse stakeholders, including representatives from different backgrounds, cultures, and perspectives, in the development and evaluation of the virtual agent. This can help identify and mitigate potential biases or blind spots in the system.
- Ethical training and education – Provide ongoing training and education for the development team, as well as customer-facing personnel, on ethical AI principles, responsible AI practices, and the potential societal impacts of AI systems.
- Collaboration and knowledge sharing – Engage with the broader AI community, industry groups, and academic institutions to stay informed about the latest developments, best practices, and emerging challenges in the field of responsible AI.
Conclusion
In this post, we explored a comprehensive solution for securing a virtual travel agent powered by generative AI. By using prompt engineering, Guardrails for Amazon Bedrock built-in filters, and comprehensive monitoring, we demonstrated how to create a robust and secure virtual assistant that adheres to the highest standards of responsible AI.
The key benefits of implementing this solution include:
- Enhanced user experience – By making sure the virtual agent operates within predefined boundaries and provides appropriate responses, users can enjoy a seamless and delightful experience without encountering harmful, biased, or inappropriate content
- Mitigated risks – The multi-layered approach mitigates the risks associated with generative AI, such as the generation of harmful or biased outputs, exposure of sensitive information, or misuse for malicious purposes
- Responsible AI alignment – The solution aligns with ethical AI principles and responsible AI practices, fostering trust and accountability in the deployment of AI systems
- Proactive issue identification – The monitoring mechanisms enable proactive identification of potential issues, allowing for timely adjustments and refinements to the system
- Scalability and adaptability – The modular nature of the solution allows for effortless scaling and adaptation to different use cases or domains, providing long-term viability and relevance
By following the steps outlined in this post, organizations can confidently take advantage of the power of generative AI while prioritizing responsible AI practices, ultimately delivering a secure and trustworthy virtual travel agent that exceeds customer expectations.
To learn more, visit Guardrails for Amazon Bedrock.
About the Authors
 Antonio Rodriguez is a Sr. Generative AI Specialist Solutions Architect in Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock.
Antonio Rodriguez is a Sr. Generative AI Specialist Solutions Architect in Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock.
 Dani Mitchell is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on computer vision use cases and helping customers across EMEA accelerate their ML journey.
Dani Mitchell is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on computer vision use cases and helping customers across EMEA accelerate their ML journey.
 Anubhav Mishra is a Principal Product Manager for Amazon Bedrock with AWS. He spends his time understanding customers and designing product experiences to address their business challenges.
Anubhav Mishra is a Principal Product Manager for Amazon Bedrock with AWS. He spends his time understanding customers and designing product experiences to address their business challenges.
Leave a Reply