
Anthropic Claude 3.5 Sonnet ranks number 1 for business and finance in S&P AI Benchmarks by Kensho
Anthropic Claude 3.5 Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho, which assesses large language models (LLMs) for finance and business. Kensho is the AI Innovation Hub for S&P Global. Using Amazon Bedrock, Kensho was able to quickly run Anthropic Claude 3.5 Sonnet through a challenging suite of business and financial tasks. We discuss these tasks and the capabilities of Anthropic Claude 3.5 Sonnet in this post.
Limitations of LLM evaluations
It is a common practice to use standardized tests, such as Massive Multitask Language Understanding (MMLU, a test consisting of multiple-choice questions that cover 57 disciplines like math, philosophy, and medicine) and HumanEval (testing code generation), to evaluate LLMs. Although these evaluations are useful in giving LLM users a sense of an LLM’s relative performance, they have limitations. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Additionally, today’s LLMs work well for general tasks, such as question answering tasks and code generation. However, these capabilities don’t always translate to domain-specific tasks. In the financial services industry, we hear customers ask which model to choose for their financial domain generative artificial intelligence (AI) applications. These applications require the LLMs to have requisite domain knowledge and be able to reason about numeric data to calculate metrics and extract insights. We have also heard from customers that highly ranked general benchmark LLMs don’t necessarily provide them with the best performance for their given finance and business applications.
Our customers often ask us if we have a benchmark of LLMs just for the financial industry that could help them pick the right LLMs faster.
S&P AI Benchmarks by Kensho
When Kensho’s R&D lab began to research and develop useful, challenging datasets for finance and business, it quickly became clear that within the finance industry, there was a scarcity of such realistic evaluations. To address this challenge, the lab created S&P AI Benchmarks, which aims to serve as the industry standard for benchmarking models for finance and business.
“By offering a robust and independent benchmarking solution, we want to help the financial services industry make smart decisions about which models to implement for which use cases.”
– Bhavesh Dayalji, Chief AI Officer of S&P Global and CEO of Kensho.
S&P AI Benchmarks focuses on measuring models’ ability to perform tasks that center around three categories of capabilities and knowledge: domain knowledge, quantity extraction, and quantitative reasoning (more details can be found in this paper). This publicly available resource includes a corresponding leaderboard, which allows everyone to see the performance of every state-of-the-art language model that has been evaluated on these rigorous tasks. Anthropic Claude 3.5 Sonnet is currently ranked number one (as of July 2024), demonstrating Anthropic’s strengths in the business and finance domain.
Kensho chose to test their benchmark with Amazon Bedrock because of its ease of use and enterprise-ready security and privacy controls.
The evaluation tasks
S&P AI Benchmarks evaluates LLMs using a wide range of questions concerning finance and business. The evaluation comprises 600 questions spanning three categories: domain knowledge, quantity extraction, and quantitative reasoning. Each question has been verified by domain experts and finance professionals with over 5 years of experience.
Quantitative reasoning
This task determines if, given a question and lengthy documents, the model can perform complex calculations and correctly reason to produce an accurate answer. The questions are written by financial professionals using real-world data and financial knowledge. As such, they are closer to the kinds of questions that business and financial professionals would ask in a generative AI application. The following is an example:
Question: The market price of K-T-Lew Corporation’s common stock is $60 per share, and each share gives its owner one subscription right. Four rights are required to purchase an additional share of common stock at the subscription price of $54 per share. If the common stock is currently selling rights-on, what is the theoretical value of a right? Answer to the nearest cent.
To answer the question, LLMs must resolve complex quantity references and use implicit financial background knowledge. For example, “subscription right,” “selling rights-on,” and “subscription price” in the preceding question require financial background knowledge to understand the terms. To generate the answer, LLMs need to have the financial knowledge of calculating the “theoretical value of a right.”
Quantity extraction
Given financial reports, an LLM can extract the pertinent numerical information. Many business and finance workflows require high-precision quantity extraction. In the following example, for an LLM to answer the question correctly, it needs to understand the table row represents location and the column represents year, and then extract the correct quantity (total amount) from the table based on the asked location and year:
Question: What was the Total Americas amount in 2019? (thousand)
| Years Ended December 31, | |||
| 2019 | 2018 | 2017 | |
| Americas: | . | . | . |
| United States | $614,493 | $668,580 | $644,870 |
| The Philippines | 250,888 | 231,966 | 241,211 |
| Costa Rica | 127,078 | 127,963 | 132,542 |
| Canada | 99,037 | 102,353 | 112,367 |
| El Salvador | 81,195 | 81,156 | 75,800 |
| Other | 123,969 | 118,620 | 118,853 |
| Total Americas | 1,296,660 | 1,330,638 | 1,325,643 |
| EMEA: | . | . | . |
| Germany | 94,166 | 91,703 | 81,634 |
| Other | 223,847 | 203,251 | 178,649 |
| Total EMEA | 318,013 | 294,954 | 260,283 |
| Total Other | 89 | 95 | 82 |
| . | $1,614,762 | $1,625,687 | $1,586,008 |
Domain knowledge
Models must demonstrate an understanding of business and financial terms, practices, and formulae. The task is to answer multiple-choice questions collected from CFA practice exams and the business ethics, microeconomics, and professional accounting exams from the MMLU dataset. In the following example question, the LLM needs to understand what a fixed-rate system is:
Question: A fixed-rate system is characterized by:
A: Explicit legislative commitment to maintain a specified parity.
B: Monetary independence being subject to the maintenance of an exchange rate peg.
C: Target foreign exchange reserves bearing a direct relationship to domestic monetary aggregates.
Anthropic Claude 3.5 Sonnet on Amazon Bedrock
In addition to ranking at the top on S&P AI Benchmarks, Anthropic Claude 3.5 Sonnet yields state-of-the-art performance on a wide range of other tasks, including undergraduate-level expert knowledge (MMLU), graduate-level expert reasoning (GPQA), code (HumanEval), and more. As pointed out in Anthropic’s Claude 3.5 Sonnet model now available in Amazon Bedrock: Even more intelligence than Claude 3 Opus at one-fifth the cost, Anthropic Claude 3.5 Sonnet made key improvements in visual processing and understanding, writing and content generation, natural language processing, coding, and generating insights.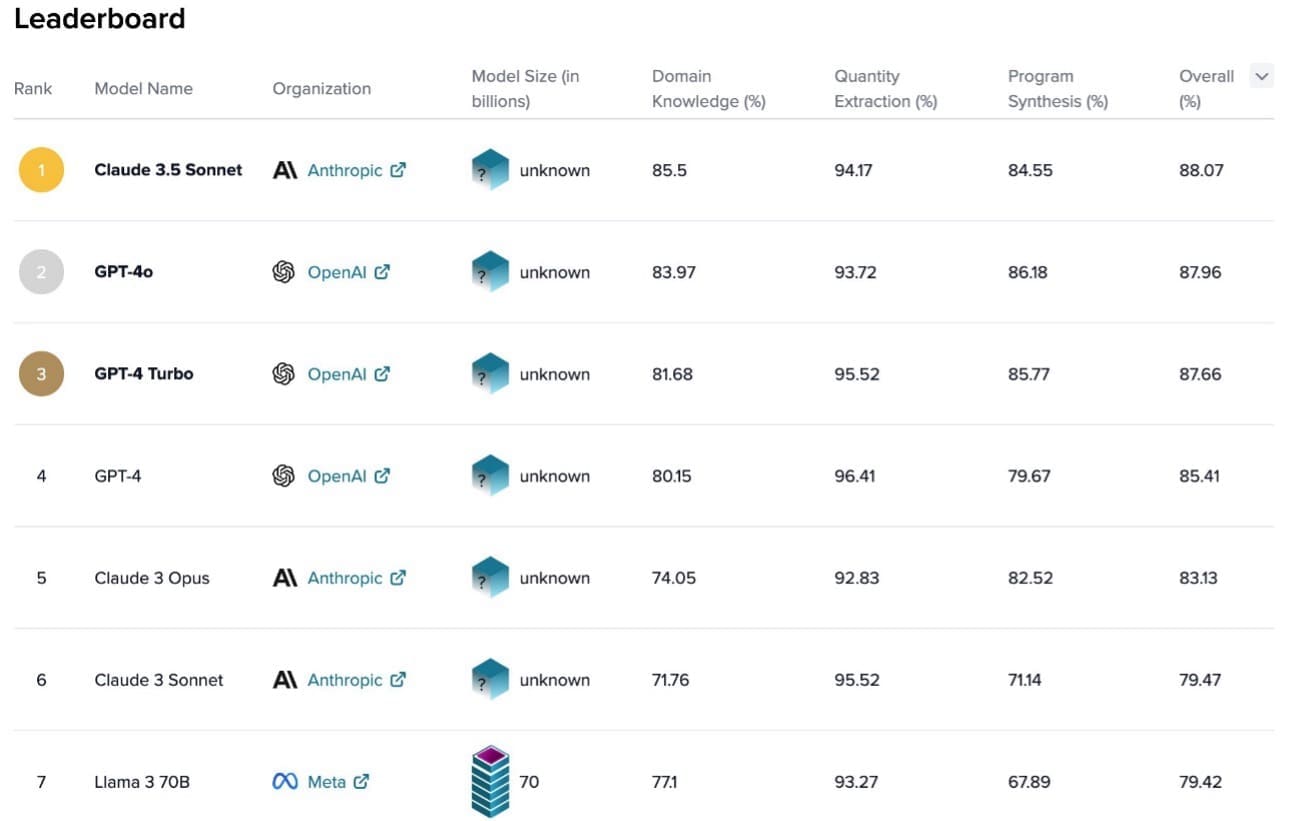
Get started with Anthropic Claude 3.5 Sonnet on Amazon Bedrock
Anthropic Claude 3.5 Sonnet is generally available in Amazon Bedrock as part of the Anthropic Claude family of AI models. Amazon Bedrock is a fully managed service that offers quick access to a choice of industry-leading LLMs and other foundation models from AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon. It also offers a broad set of capabilities to build generative AI applications, simplifying development while supporting privacy and security. Tens of thousands of customers have already selected Amazon Bedrock as the foundation for their generative AI strategy. Customers from the financial industry such as Nasdaq, NYSE, Broadridge, Jefferies, NatWest, and more use Amazon Bedrock to build their generative AI applications.
“The Kensho team uses Amazon Bedrock to quickly evaluate models from several different providers. In fact, access to Amazon Bedrock allowed the team to benchmark Anthropic Claude 3.5 Sonnet within 24 hours.”
– Diana Mingels, Head of Machine Learning at Kensho.
Conclusion
In this post, we walked through the S&P AI Benchmarks task details for business and finance. The benchmark shows that Anthropic Claude 3.5 Sonnet is the leading performer in these tasks. To start using this new model, see Anthropic Claude models. With Amazon Bedrock, you get a fully managed service offering access to leading AI models from companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications. Learn more and get started today at Amazon Bedrock.
About the authors
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Joe Dunn is an AWS Principal Solutions Architect in Financial Services with over 20 years of experience in infrastructure architecture and migration of business-critical loads to AWS. He helps financial services customers to innovate on the AWS Cloud by providing solutions using AWS products and services.
Joe Dunn is an AWS Principal Solutions Architect in Financial Services with over 20 years of experience in infrastructure architecture and migration of business-critical loads to AWS. He helps financial services customers to innovate on the AWS Cloud by providing solutions using AWS products and services.
 Raghvender Arni (Arni) is a part of the AWS Generative AI GTM team and leads the Cross-Portfolio team which is a multidisciplinary group of AI specialists dedicated to accelerating and optimizing generative AI adoption across industries.
Raghvender Arni (Arni) is a part of the AWS Generative AI GTM team and leads the Cross-Portfolio team which is a multidisciplinary group of AI specialists dedicated to accelerating and optimizing generative AI adoption across industries.
 Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. In his spare time, Simon enjoys spending time with family, reading sci-fi, and working on various DIY house projects.
 Scott Mullins is Managing Director and General Manger of AWS’ Worldwide Financial Services organization. In this role, Scott is responsible for AWS’ relationships with systemically important financial institutions, and for leading the development and execution of AWS’ strategic initiatives across Banking, Payments, Capital Markets, and Insurance around the world. Prior to joining AWS in 2014, Scott’s 28-year career in financial services included roles at JPMorgan Chase, Nasdaq, Merrill Lynch, and Penson Worldwide. At Nasdaq, Scott was the Product Manager responsible for building the exchange’s first cloud-based solution, FinQloud. Before joining NASDAQ, Scott ran Surveillance and Trading Compliance for one of the nation’s largest clearing broker-dealers, with responsibility for regulatory response, emerging regulatory initiatives, and compliance matters related to the firm’s trading and execution services divisions. Prior to his roles in regulatory compliance, Scott spent 10 years as an equity trader. A graduate of Texas A&M University, Scott is a subject matter expert quoted in industry media, and a recognized speaker at industry events..
Scott Mullins is Managing Director and General Manger of AWS’ Worldwide Financial Services organization. In this role, Scott is responsible for AWS’ relationships with systemically important financial institutions, and for leading the development and execution of AWS’ strategic initiatives across Banking, Payments, Capital Markets, and Insurance around the world. Prior to joining AWS in 2014, Scott’s 28-year career in financial services included roles at JPMorgan Chase, Nasdaq, Merrill Lynch, and Penson Worldwide. At Nasdaq, Scott was the Product Manager responsible for building the exchange’s first cloud-based solution, FinQloud. Before joining NASDAQ, Scott ran Surveillance and Trading Compliance for one of the nation’s largest clearing broker-dealers, with responsibility for regulatory response, emerging regulatory initiatives, and compliance matters related to the firm’s trading and execution services divisions. Prior to his roles in regulatory compliance, Scott spent 10 years as an equity trader. A graduate of Texas A&M University, Scott is a subject matter expert quoted in industry media, and a recognized speaker at industry events..
Leave a Reply