
Fine-tune Anthropic’s Claude 3 Haiku in Amazon Bedrock to boost model accuracy and quality
Frontier large language models (LLMs) like Anthropic Claude on Amazon Bedrock are trained on vast amounts of data, allowing Anthropic Claude to understand and generate human-like text. Fine-tuning Anthropic Claude 3 Haiku on proprietary datasets can provide optimal performance on specific domains or tasks. The fine-tuning as a deep level of customization represents a key differentiating factor by using your own unique data.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) along with a broad set of capabilities to build generative artificial intelligence (AI) applications, simplifying development with security, privacy, and responsible AI. With Amazon Bedrock custom models, you can customize FMs securely with your data. According to Anthropic, Claude 3 Haiku is the fastest and most cost-effective model on the market for its intelligence category. You can now fine-tune Anthropic Claude 3 Haiku in Amazon Bedrock in a preview capacity in the US West (Oregon) AWS Region. Amazon Bedrock is the only fully managed service that provides you with the ability to fine-tune Anthropic Claude models.
This post introduces the workflow of fine-tuning Anthropic Claude 3 Haiku in Amazon Bedrock. We first introduce the general concept of fine-tuning and then focus on the important steps in fining-tuning the model, including setting up permissions, preparing for data, commencing the fine-tuning jobs, and conducting evaluation and deployment of the fine-tuned models.
Solution overview
Fine-tuning is a technique in natural language processing (NLP) where a pre-trained language model is customized for a specific task. During fine-tuning, the weights of the pre-trained Anthropic Claude 3 Haiku model will get updated to enhance its performance on a specific target task. Fine-tuning allows the model to adapt its knowledge to the task-specific data distribution and vocabulary. Hyperparameters like learning rate and batch size need to be tuned for optimal fine-tuning.
Fine-tuning Anthropic Claude 3 Haiku in Amazon Bedrock offers significant advantages for enterprises. This process enhances task-specific model performance, allowing the model to handle custom use cases with task-specific performance metrics that meet or surpass more powerful models like Anthropic Claude 3 Sonnet or Anthropic Claude 3 Opus. As a result, businesses can achieve improved performance with reduced costs and latency. Essentially, fine-tuning Anthropic Claude 3 Haiku provides you with a versatile tool to customize Anthropic Claude, enabling you to meet specific performance and latency goals efficiently.
You can benefit from fine-tuning Anthropic Claude 3 Haiku in different use cases, using your own data. The following use cases are well-suited for fine-tuning the Anthropic Claude 3 Haiku model:
- Classification – For example, when you have 10,000 labeled examples and want Anthropic Claude to do really well at this task
- Structured outputs – For example, when you need Anthropic Claude’s response to always conform to a given structure
- Industry knowledge – For example, when you need to teach Anthropic Claude how to answer questions about your company or industry
- Tools and APIs – For example, when you need to teach Anthropic Claude how to use your APIs really well
In the following sections, we go through the steps of fine-tuning and deploying Anthropic Claude 3 Haiku in Amazon Bedrock using the Amazon Bedrock console and the Amazon Bedrock API.
Prerequisites
To use this feature, make sure you have satisfied the following requirements:
- An active AWS account.
- Anthropic Claude 3 Haiku enabled in Amazon Bedrock. You can confirm it’s enabled on the Model access page of the Amazon Bedrock console.
- Access to the preview of Anthropic Claude 3 Haiku fine-tuning in Amazon Bedrock. To request access, contact your AWS account team or submit a support ticket using the AWS Management Console. When creating the support ticket, choose Bedrock for Service and Models for Category.
- The required training dataset (and optional validation dataset) prepared and stored in Amazon Simple Storage Service (Amazon S3).
To create a model customization job using Amazon Bedrock, you need to create an AWS Identity and Access Management (IAM) role with the following permissions (for more details, see Create a service role for model customization):
- A trust relationship, which allows Amazon Bedrock to assume the role
- Permissions to access training and validation data in Amazon S3
- Permissions to write output data to Amazon S3
- Optionally, permissions to decrypt an AWS Key Management Service (AWS KMS) key if you have encrypted resources with a KMS key
The following code is the trust relationship, which allows Amazon Bedrock to assume the IAM role:
Prepare the data
To fine-tune the Anthropic Claude 3 Haiku model, the training data must be in JSON Lines (JSONL) format, where each line represents a single training record. Specifically, the training data format aligns with the MessageAPI:
The following is an example from a text summarization use case used as one-line input for fine-tuning Anthropic Claude 3 Haiku in Amazon Bedrock. In JSONL format, each record is one text line.
You can invoke the fine-tuned model using the same MessageAPI format, providing consistency. In each line, the "system" message is optional information, which is a way of providing context and instructions to the model, such as specifying a particular goal or role, often known as a system prompt. The "user" content corresponds to the user’s instruction, and the "assistant" content is the desired response that the fine-tuned model should provide. Fine-tuning Anthropic Claude 3 Haiku in Amazon Bedrock supports both single-turn and multi-turn conversations. If you want to use multi-turn conversations, the data format for each line is as follows:
The last line’s "assistant" role represents the desired output from the fine-tuned model, and the previous chat history serves as the prompt input. For both single-turn and multi-turn conversation data, the total length of each record (including system, user, and assistant content) should not exceed 32,000 tokens.
In addition to your training data, you can prepare validation and test datasets. Although it’s optional, a validation dataset is recommended because it allows you to monitor the model’s performance during training. This dataset enables features like early stopping and helps improve model performance and convergence. Separately, a test dataset is used to evaluate the final model’s performance after training is complete. Both additional datasets follow a similar format to your training data, but serve distinct purposes in the fine-tuning process.
If you’re already using Amazon Bedrock to fine-tune Amazon Titan, Meta Llama, or Cohere models, the training data should follow this format:
For data in this format, you can use the following Python code to convert to the required format for fine-tuning:
To optimize the fine-tuning performance, the quality of training data is more important than the size of the dataset. We recommend starting with a small but high-quality training dataset (50–100 rows of data is a reasonable start) to fine-tune the model and evaluate its performance. Based on the evaluation results, you can then iterate and refine the training data. Generally, as the size of the high-quality training data increases, you can expect to achieve better performance from the fine-tuned model. However, it’s essential to maintain a focus on data quality, because a large but low-quality dataset may not yield the desired improvements in the fine-tuned model performance.
Currently, the requirements for the number of records in training and validation data for fine-tuning Anthropic Claude 3 Haiku align with the customization limits set by Amazon Bedrock for fine-tuning other models. Specifically, the training data should not exceed 10,000 records, and the validation data should not exceed 1,000 records. These limits provide efficient resource utilization while allowing for model optimization and evaluation within a reasonable data scale.
Fine-tune the model
Fine-tuning Anthropic Claude 3 Haiku in Amazon Bedrock allows you to configure various hyperparameters that can significantly impact the fine-tuning process and the resulting model’s performance. The following table summarizes the supported hyperparameters.
| Name | Description | Type | Default | Value Range |
epochCount |
The maximum number of iterations through the entire training dataset. Epochcount is equivalent to epoch. |
integer | 2 | 1–10 |
batchSize |
The number of samples processed before updating model parameters. | integer | 32 | 4–256 |
learningRateMultiplier |
The multiplier that influences the learning rate at which model parameters are updated after each batch. | float | 1 | 0.1–2 |
earlyStoppingThreshold |
The minimum improvement in validation loss required to prevent premature stopping of the training process. | float | 0.001 | 0–0.1 |
earlyStoppingPatience |
The tolerance for stagnation in the validation loss metric before stopping the training process. | int | 2 | 1–10 |
The learningRateMultiplier parameter is a factor that adjusts the base learning rate set by the model itself, which determines the actual learning rate applied during the training process by scaling the model’s base learning rate with this multiplier factor. Typically, you should increase the batchSize when the training dataset size increases, and you may need to perform hyperparameter optimization (HPO) to find the optimal settings. Early stopping is a technique used to prevent overfitting and stop the training process when the validation loss stops improving. The validation loss is computed at the end of each epoch. If the validation loss has not decreased enough (determined by earlyStoppingThreshold) for earlyStoppingPatience times, the training process will be stopped.
For example, the following table shows example validation losses for each epoch during a training process.
| Epoch | Validation Loss |
| 1 | 0.9 |
| 2 | 0.8 |
| 3 | 0.7 |
| 4 | 0.66 |
| 5 | 0.64 |
| 6 | 0.65 |
| 7 | 0.65 |
The following table illustrates the behavior of early stopping during the training, based on different configurations of earlyStoppingThreshold and earlyStoppingPatience.
| Scenario | earlyStopping Threshold | earlyStopping Patience | Training Stopped | Best Checkpoint |
| 1 | 0 | 2 | Epoch 7 | Epoch 5 (val loss 0.64) |
| 2 | 0.05 | 1 | Epoch 4 | Epoch 4 (val loss 0.66) |
Choosing the right hyperparameter values is crucial for achieving optimal fine-tuning performance. You may need to experiment with different settings or use techniques like HPO to find the best configuration for your specific use case and dataset.
Run the fine-tuning job on the Amazon Bedrock console
Make sure you have access to the preview of Anthropic Claude 3 Haiku fine-tuning in Amazon Bedrock, as discussed in the prerequisites. After you’re granted access, complete the following steps:
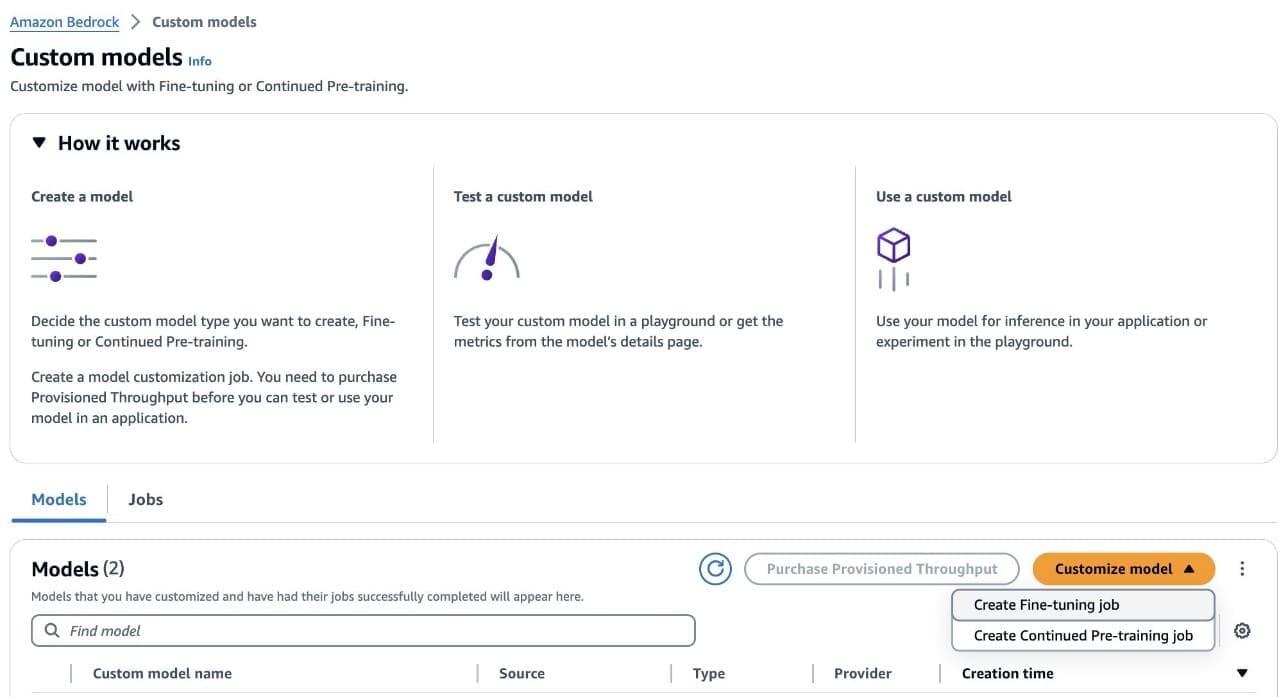
- On the Amazon Bedrock console, choose Foundation models in the navigation pane.
- Choose Custom models.
- In the Models section, on the Customize model menu, choose Create Fine-tuning job.

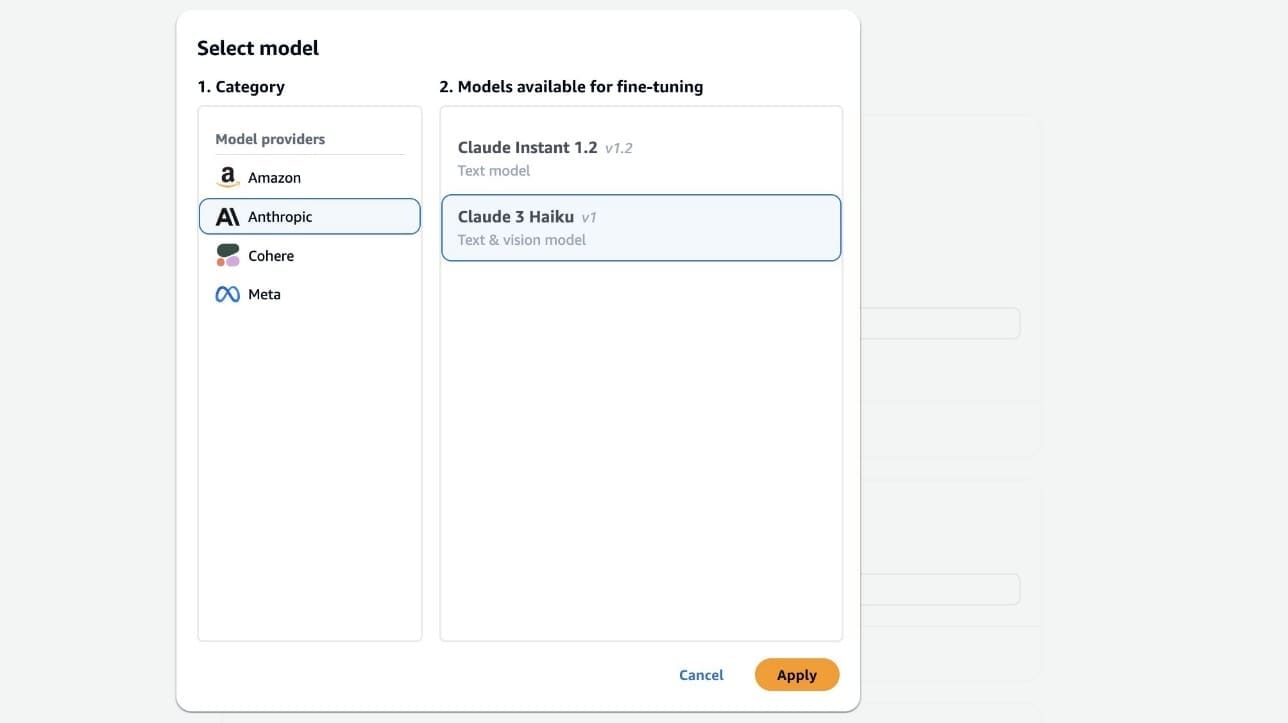
- For Category, choose Anthropic.
- For Models available for fine-tuning, choose Claude 3 Haiku.
- Choose Apply.
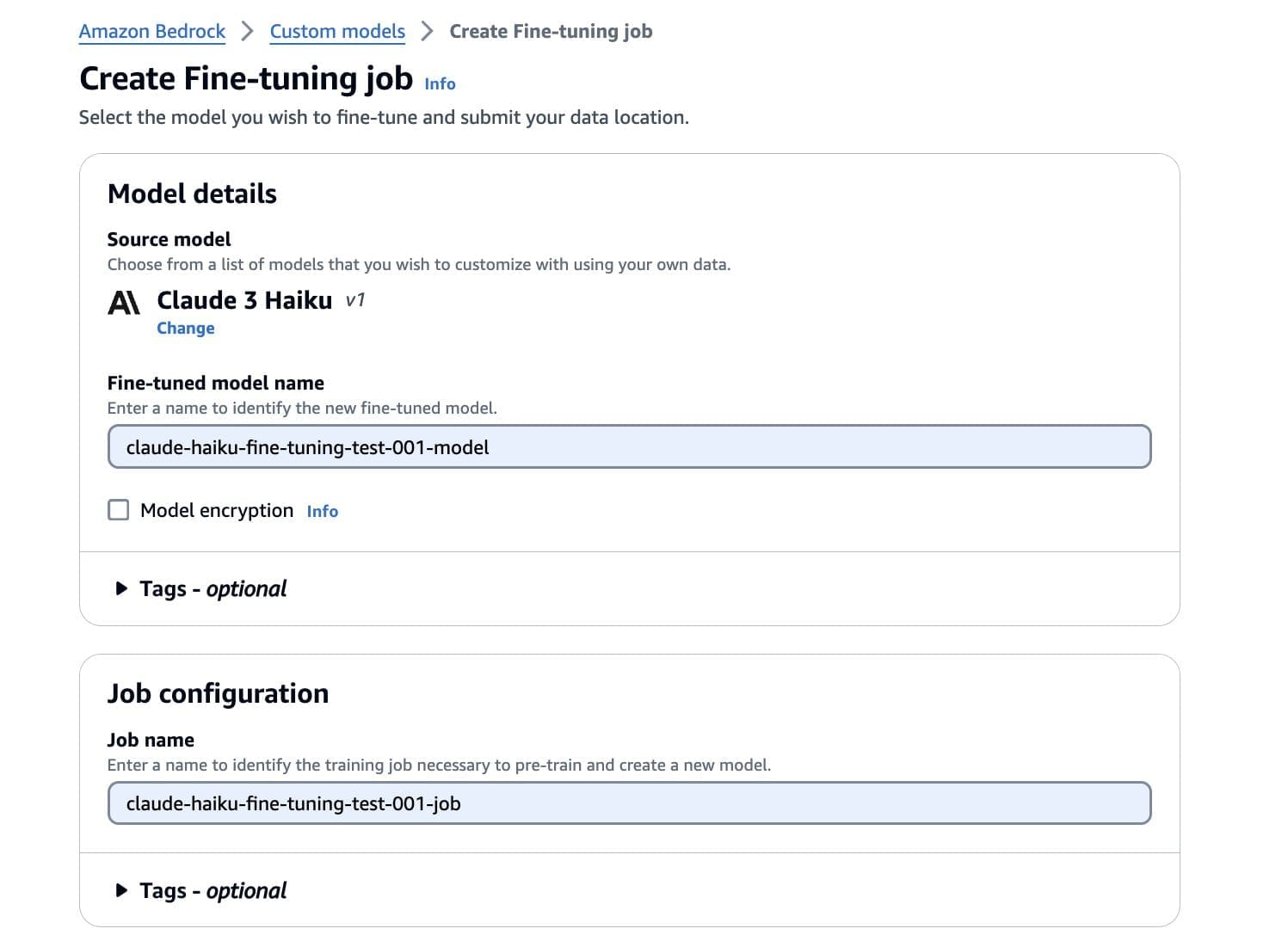
- For Fine-tuned model name, enter a name for the model.
- Select Model encryption to add a KMS key.
- Optionally, expand the Tags section to add tags for tracking.
- For Job name, enter a name for the training job.
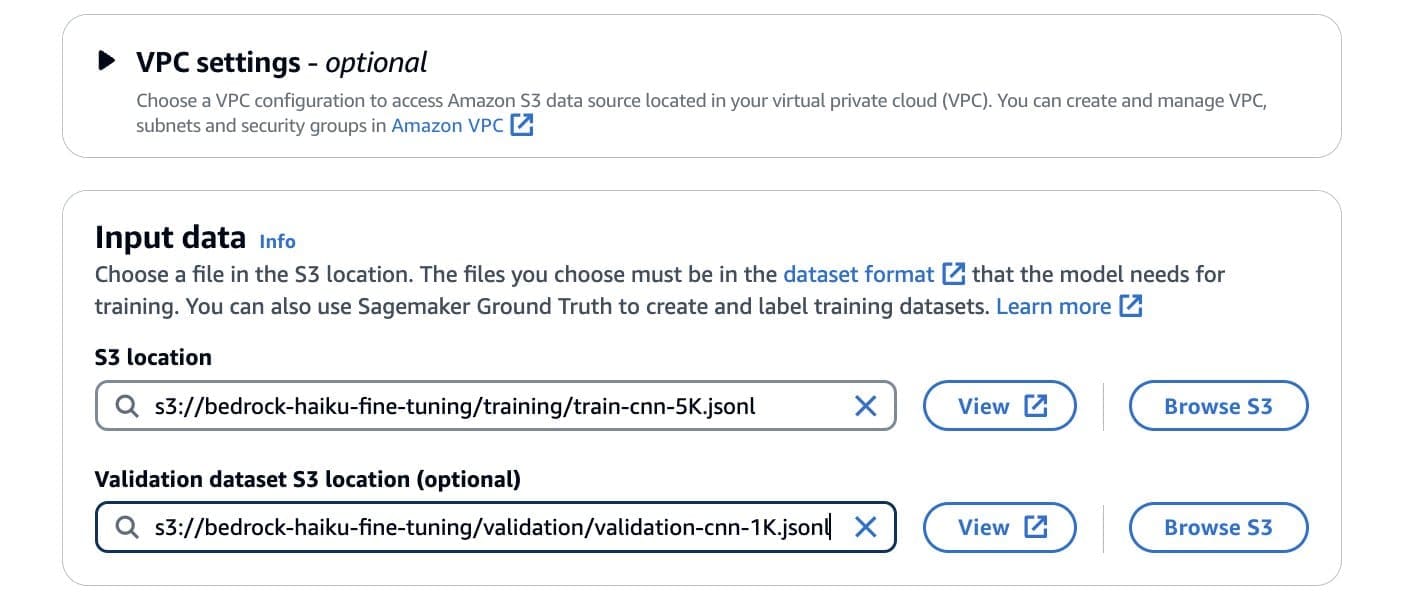
Before you start a fine-tuning job, create an S3 bucket in the same Region as your Amazon Bedrock service (for example, us-west-2), as mentioned in the prerequisites. At the time of writing, fine-tuning for Anthropic Claude 3 Haiku in Amazon Bedrock is available in preview in the US West (Oregon) Region. Within this S3 bucket, set up separate folders for your training data, validation data, and fine-tuning artifacts. Upload your training and validation datasets to their respective folders.
- Under Input data, specify the S3 locations for both your training and validation datasets.
This setup enforces proper data access and Regional compatibility for your fine-tuning process.
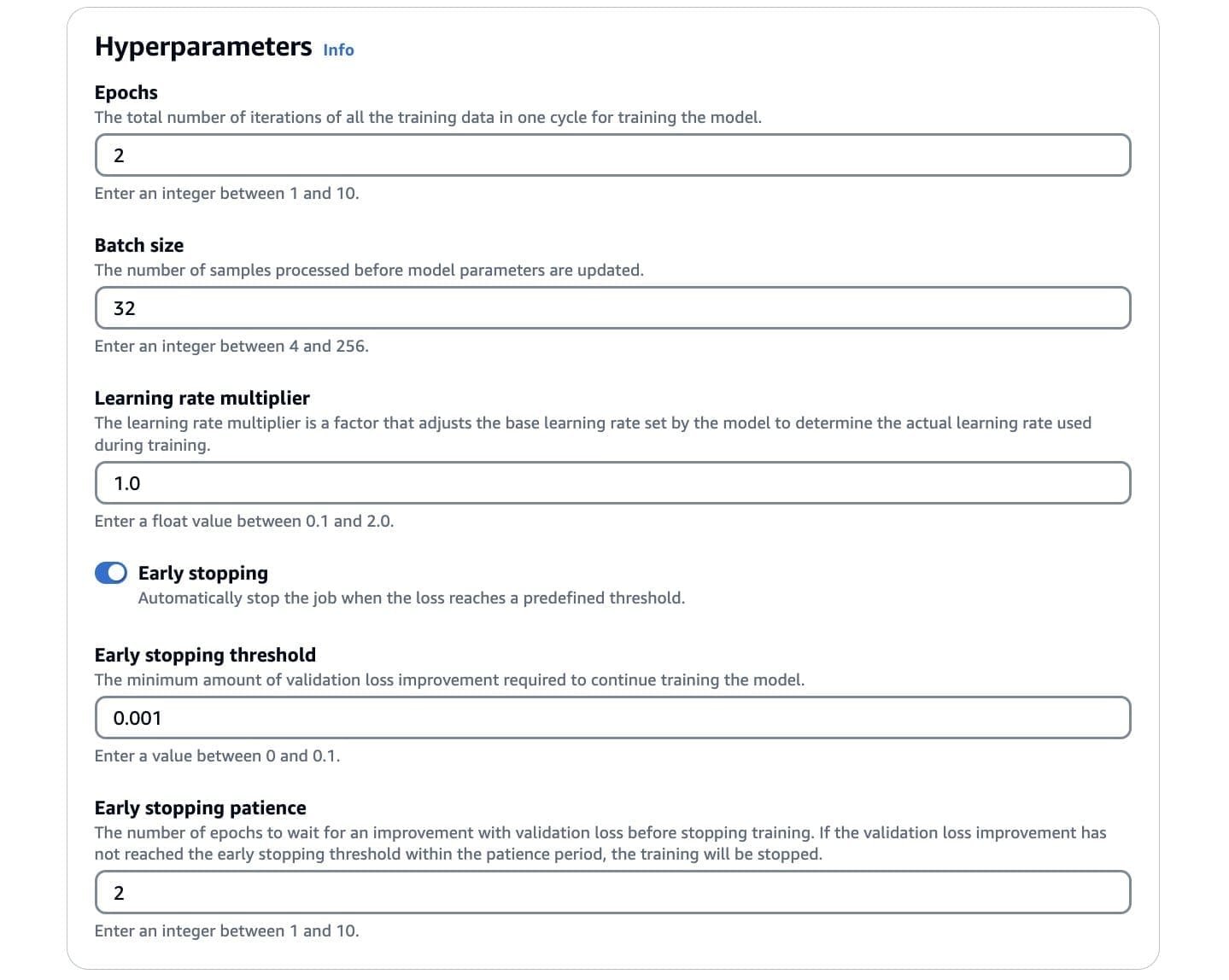
Next, you configure the hyperparameters for your fine-tuning job.
- Set the number of epochs, batch size, and learning rate multiplier.
- If you’ve included a validation dataset, you can enable early stopping.
This feature allows you to set an early stopping threshold and patience value. Early stopping helps prevent overfitting by halting the training process when the model’s performance on the validation set stops improving.
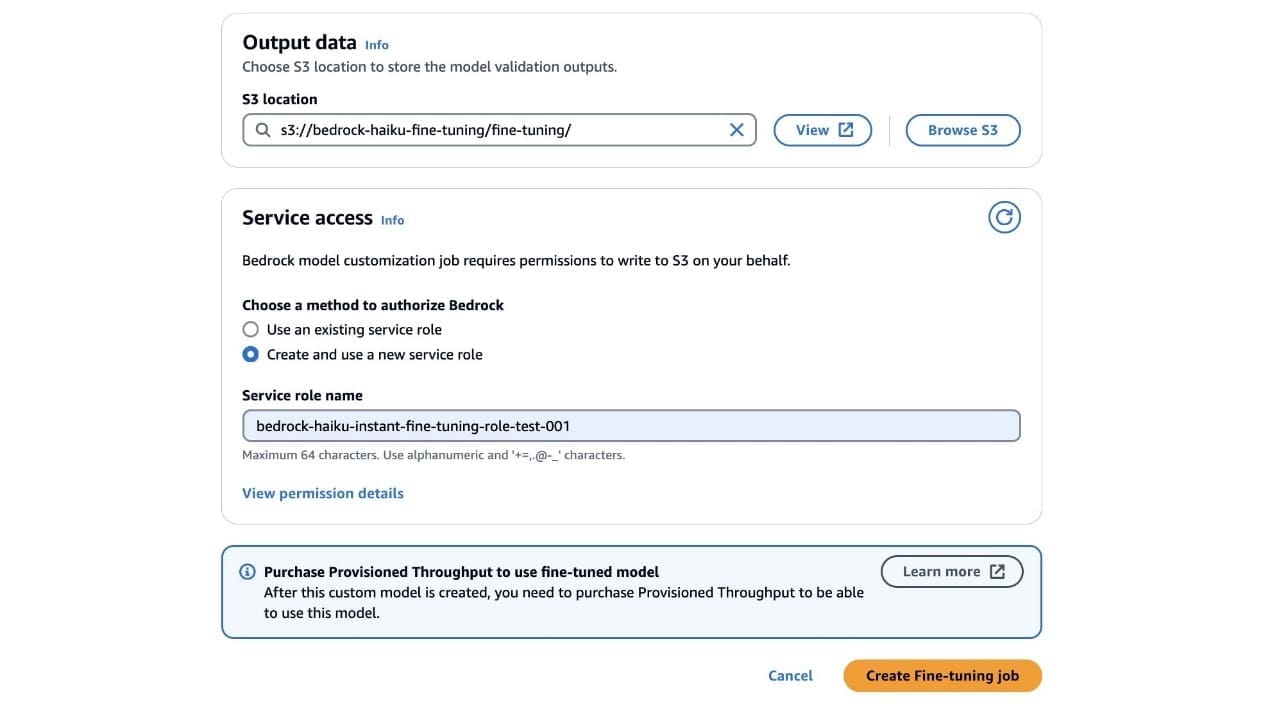
- Under Output data, for S3 location, enter the S3 path for the bucket storing fine-tuning metrics.
- Under Service access, select a method to authorize Amazon Bedrock. You can select Use an existing service role if you have an access role with fine-grained IAM policies or select Create and use a new service role.
- After you have added all the required configurations for fine-tuning Anthropic Claude 3 Haiku, choose Create Fine- tuning job.
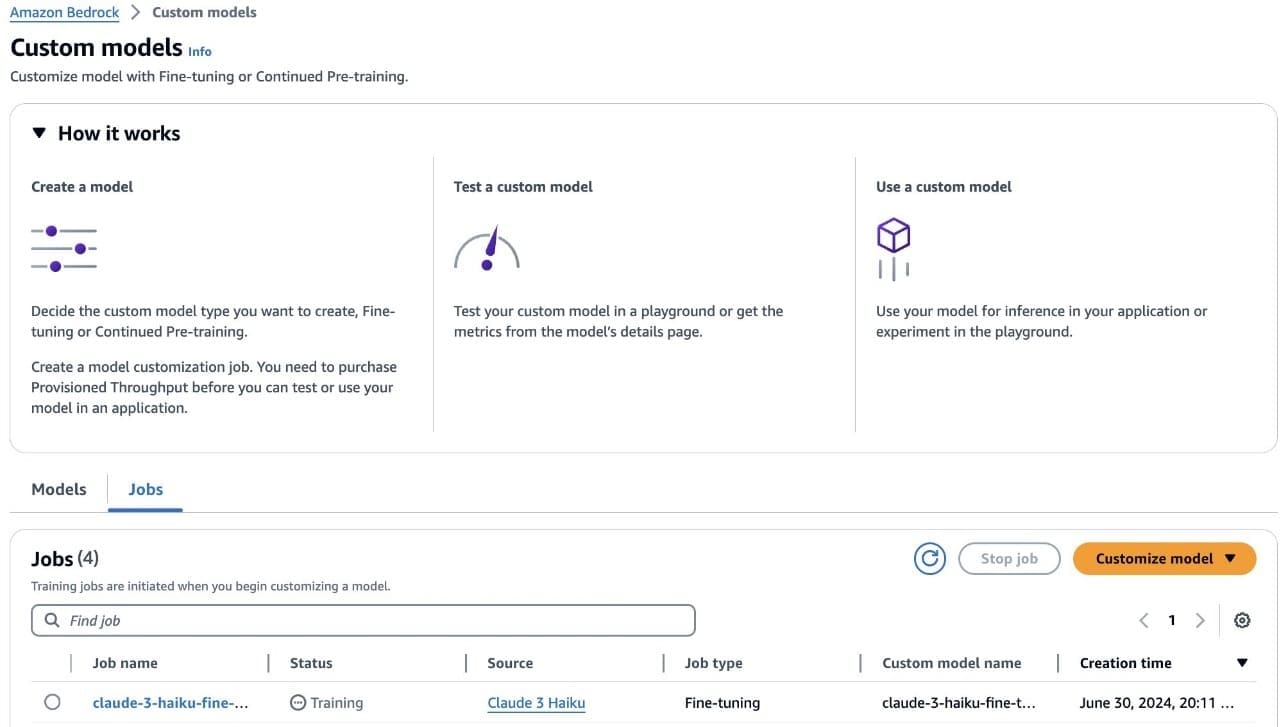
When the fine-tuning job starts, you can see the status of the training job (Training or Complete) under Jobs.
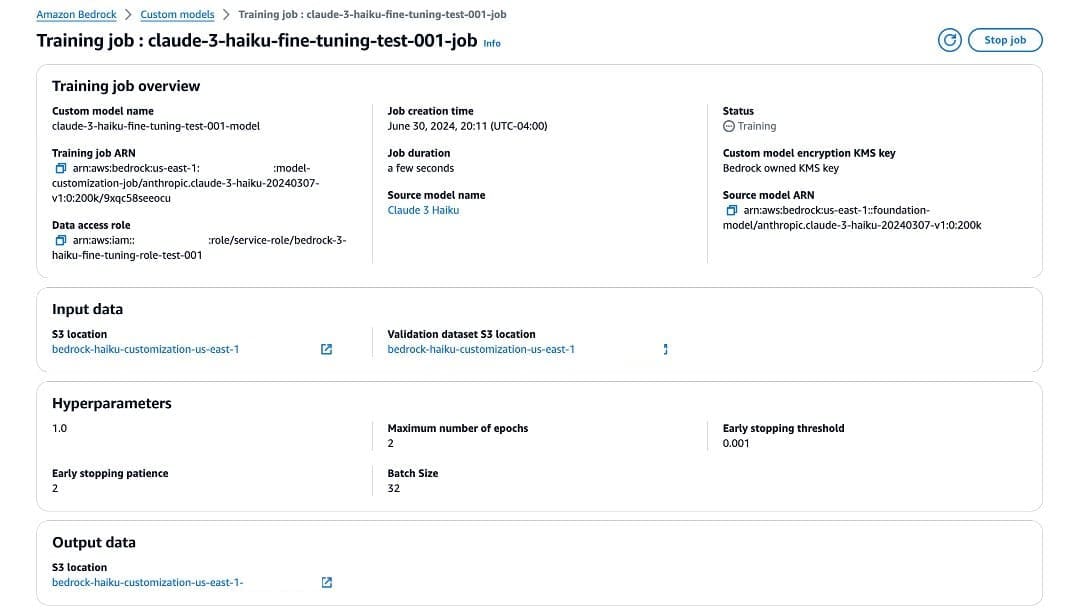
As the fine-tuning job progresses, you can find more information about the training job, including job creation time, job duration, input data, and hyperparameters used for the fine-tuning job. Under Output data, you can navigate to the fine-tuning folder in the S3 bucket, where you can find the training and validation metrics that were computed as part of the fine-tuning job.
Run the fine-tuning job using the Amazon Bedrock API
Make sure to request access to the preview of Anthropic Claude 3 Haiku fine-tuning in Amazon Bedrock, as discussed in the prerequisites.
To start a fine-tuning job for Anthropic Claude 3 Haiku using the Amazon Bedrock API, complete the following steps:
- Create an Amazon Bedrock client and set the base model ID for the Anthropic Claude 3 Haiku model:
- Generate a unique job name and custom model name, typically using a timestamp:
- Specify the IAM role ARN that has the necessary permissions to access the required resources for the fine-tuning job, as discussed in the prerequisites:
- Set the customization type to
FINE_TUNINGand define the hyperparameters for fine-tuning the model, as discussed in the previous session: - Configure the S3 bucket and prefix where the fine-tuned model and output data will be stored, and provide the S3 data paths for your training and validation datasets (the validation dataset is optional):
- With these configurations in place, you can create the fine-tuning job using the
create_model_customization_jobmethod from the Amazon Bedrock client, passing in the required parameters:
The create_model_customization method will return a response containing information about the created fine-tuning job. You can monitor the job’s progress and retrieve the fine-tuned model when the job is complete, either through the Amazon Bedrock API or Amazon Bedrock console.
Deploy and evaluate the fine-tuned model
After successfully fine-tuning the model, you can evaluate the fine-tuning metrics recorded during the process. These metrics are stored in the specified S3 bucket for evaluation purposes. For the training data, step-wise training metrics are recorded with columns, including step_number, epoch_number, and training_loss.
If you provided a validation dataset, additional validation metrics are stored in a separate file, including step_number, epoch_number, and corresponding validation_loss.
When you’re satisfied with the fine-tuning metrics, you can purchase Provisioned Throughput to deploy your fine-tuned model, which allows you to take advantage of the improved performance and specialized capabilities of the fine-tuned model in your applications. Provisioned Throughput refers to the number and rate of inputs and outputs that a model processes and returns. To use a fine-tuned model, you must purchase Provisioned Throughput, which is billed hourly. The pricing for Provisioned Throughput depends on the following factors:
- The base model the fine-tuned model was customized from.
- The number of Model Units (MUs) specified for the Provisioned Throughput. MU is a unit that specifies the throughput capacity for a given model; each MU defines the number of input tokens it can process and output tokens it can generate across all requests within 1 minute.
- The commitment duration, which can be no commitment, 1 month, or 6 months. Longer commitments offer more discounted hourly rates.
After Provisioned Throughput is set up, you can use the MessageAPI to invoke the fine-tuned model, similar to how the base model is invoked. This provides a seamless transition and maintains compatibility with existing applications or workflows.
It’s crucial to evaluate the performance of the fine-tuned model to make sure it meets the desired criteria and outperforms in specific tasks. You can conduct various evaluations, including comparing the fine-tuned model with the base model, or even evaluating performance against more advanced models, like Anthropic Claude 3 Sonnet.
Deploy the fine-tuned model using the Amazon Bedrock console
To deploy the fine-tuned model using the Amazon Bedrock console, complete the following steps:
- On the Amazon Bedrock console, choose Custom models in the navigation pane.
- Select the fine-tuned model and choose Purchase Provisioned Throughput.
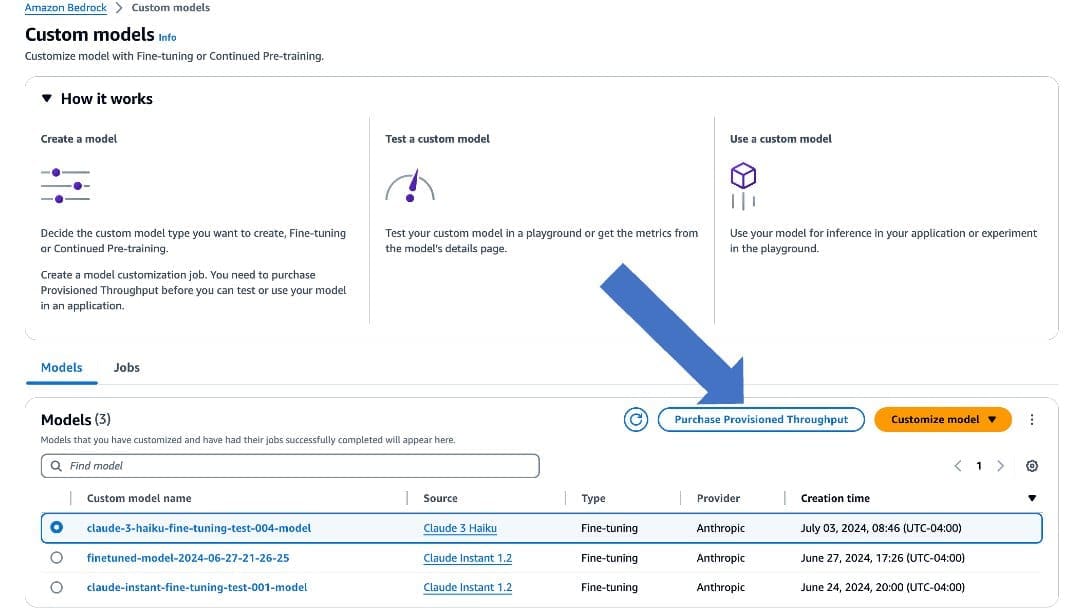
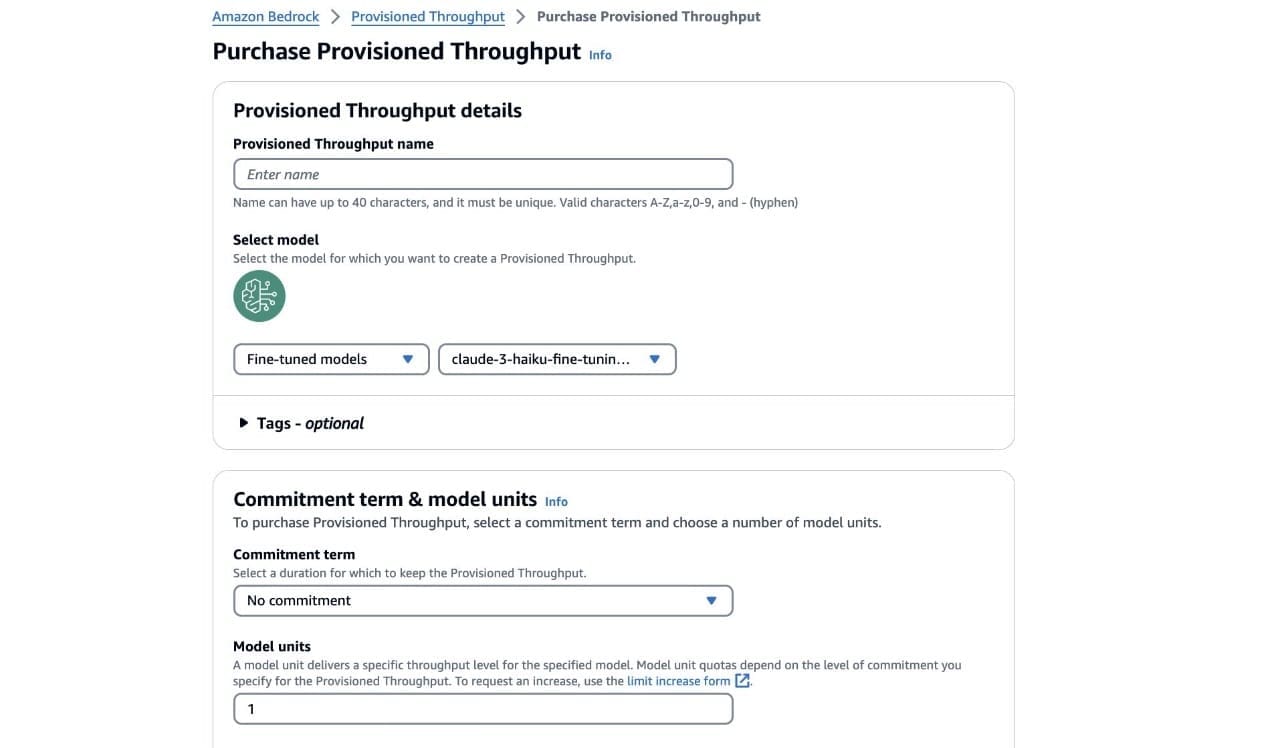
- For Provisioned Throughput name¸ enter a name.
- Choose the model you want to deploy.
- For Commitment term, choose your level of commitment (for this post, we choose No commitment).
- Choose Purchase Provisioned Throughput.
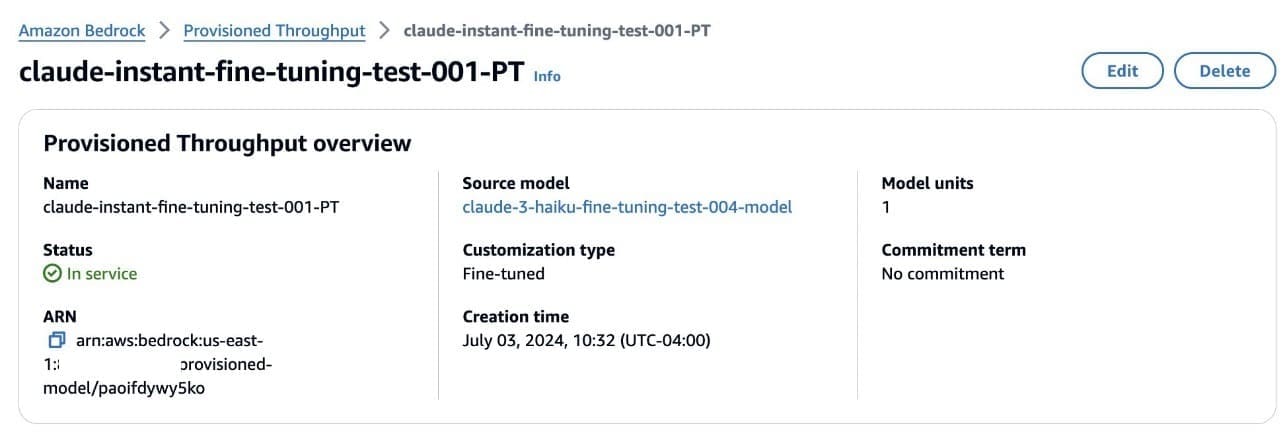
After the fine-tuned model has been deployed using Provisioned Throughput, you can see the model status as In service when you go to the Provisioned Throughput page on the Amazon Bedrock console.
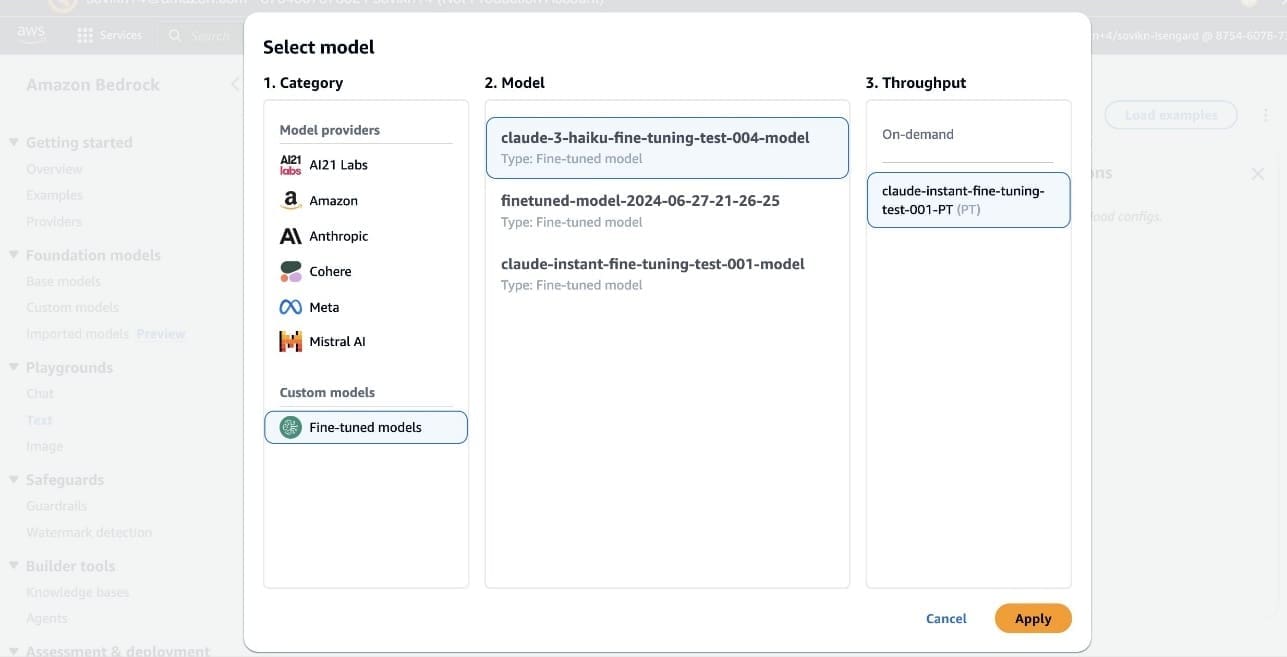
You can use the fine-tuned model deployed using Provisioned Throughput for task-specific use cases. In the Amazon Bedrock playground, you can find the fine-tuned model under Custom models and use it for inference.
Deploy the fine-tuned model using the Amazon Bedrock API
To deploy the fine-tuned model using the Amazon Bedrock API, complete the following steps:
- Retrieve the fine-tuned model ID from the job’s output, and create a Provisioned Throughput model instance with the desired model units:
- When the Provisioned Throughput model is ready, you can call the
invoke_modelfunction from the Amazon Bedrock runtime client to generate text using the fine-tuned model:
By following these steps, you can deploy and use your fine-tuned Anthropic Claude 3 Haiku model through the Amazon Bedrock API, allowing you to generate customized Anthropic Claude 3 Haiku models tailored to your specific requirements.
Conclusion
Fine-tuning Anthropic Claude 3 Haiku in Amazon Bedrock empowers enterprises to optimize this LLM for your specific needs. By combining Amazon Bedrock with Anthropic Claude 3 Haiku’s speed and cost-effectiveness, you can efficiently customize the model while maintaining robust security. This process enhances the model’s accuracy and tailors its outputs to unique business requirements, driving significant improvements in efficiency and effectiveness.
Fine-tuning Anthropic Claude 3 Haiku in Amazon Bedrock is now available in preview in the US West (Oregon) Region. To request access to the preview, contact your AWS account team or submit a support ticket.
About the Authors
 Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
 Sovik Kumar Nath is an AI/ML and Generative AI Senior Solutions Architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double master’s degrees from the University of South Florida and University of Fribourg, Switzerland, and a bachelor’s degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and going on adventures.
Sovik Kumar Nath is an AI/ML and Generative AI Senior Solutions Architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double master’s degrees from the University of South Florida and University of Fribourg, Switzerland, and a bachelor’s degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and going on adventures.
 Carrie Wu is an Applied Scientist at Amazon Web Services, working on fine-tuning large language models for alignment to custom tasks and responsible AI. She graduated from Stanford University with a PhD in Management Science and Engineering. Outside of work, she loves reading, traveling, aerial yoga, ice skating, and spending time with her dog.
Carrie Wu is an Applied Scientist at Amazon Web Services, working on fine-tuning large language models for alignment to custom tasks and responsible AI. She graduated from Stanford University with a PhD in Management Science and Engineering. Outside of work, she loves reading, traveling, aerial yoga, ice skating, and spending time with her dog.
 Fang Liu is a principal machine learning engineer at Amazon Web Services, where he has extensive experience in building AI/ML products using cutting-edge technologies. He has worked on notable projects such as Amazon Transcribe and Amazon Bedrock. Fang Liu holds a master’s degree in computer science from Tsinghua University.
Fang Liu is a principal machine learning engineer at Amazon Web Services, where he has extensive experience in building AI/ML products using cutting-edge technologies. He has worked on notable projects such as Amazon Transcribe and Amazon Bedrock. Fang Liu holds a master’s degree in computer science from Tsinghua University.
Leave a Reply