
Catalog, query, and search audio programs with Amazon Transcribe and Knowledge Bases for Amazon Bedrock
Information retrieval systems have powered the information age through their ability to crawl and sift through massive amounts of data and quickly return accurate and relevant results. These systems, such as search engines and databases, typically work by indexing on keywords and fields contained in data files.
However, much of our data in the digital age also comes in non-text format, such as audio and video files. Finding relevant content usually requires searching through text-based metadata such as timestamps, which need to be manually added to these files. This can be hard to scale as the volume of unstructured audio and video files continues to grow.
Fortunately, the rise of artificial intelligence (AI) solutions that can transcribe audio and provide semantic search capabilities now offer more efficient solutions for querying content from audio files at scale. Amazon Transcribe is an AWS AI service that makes it straightforward to convert speech to text. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
In this post, we show how Amazon Transcribe and Amazon Bedrock can streamline the process to catalog, query, and search through audio programs, using an example from the AWS re:Think podcast series.
Solution overview
The following diagram illustrates how you can use AWS services to deploy a solution for cataloging, querying, and searching through content stored in audio files.
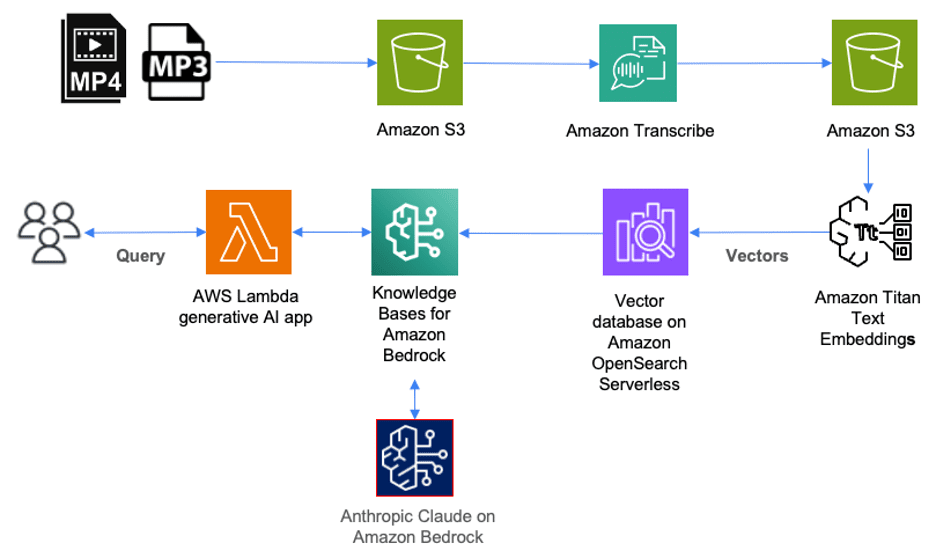
In this solution, audio files stored in mp3 format are first uploaded to Amazon Simple Storage Service (Amazon S3) storage. Video files (such as mp4) that contain audio in supported languages can also be uploaded to Amazon S3 as part of this solution. Amazon Transcribe will then transcribe these files and store the entire transcript in JSON format as an object in Amazon S3.
To catalog these files, each JSON file in Amazon S3 should be tagged with the corresponding episode title. This allows us to later retrieve the episode title for each query result.
Next, we use Amazon Bedrock to create numerical representations of the content inside each file. These numerical representations are also called embeddings, and they’re stored as vectors inside a vector database that we can later query.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API. Included with Amazon Bedrock is Knowledge Bases for Amazon Bedrock. As a fully managed service, Knowledge Bases for Amazon Bedrock makes it straightforward to set up a Retrieval Augmented Generation (RAG) workflow.
With Knowledge Bases for Amazon Bedrock, we first set up a vector database on AWS. Knowledge Bases for Amazon Bedrock can then automatically split the data files stored in Amazon S3 into chunks and then create embeddings of each chunk using Amazon Titan on Amazon Bedrock. Amazon Titan is a family of high-performing FMs from Amazon. Included with Amazon Titan is Amazon Titan Text Embeddings, which we use to create the numerical representation of the text inside each chunk and store them in a vector database.
When a user queries the contents of the audio files through a generative AI application or AWS Lambda function, it makes an API call to Knowledge Bases for Amazon Bedrock. Knowledge Bases for Amazon Bedrock will then orchestrate a call to the vector database to perform a semantic search, which returns the most relevant results. Next, Knowledge Bases for Amazon Bedrock augments the user’s original query with these results to a prompt, which is sent to the large language model (LLM). The LLM will return results that are more accurate and relevant to the user query.
Let’s walk through an example of how you can catalog, query, and search through a library of audio files using these AWS AI services. For this post, we use episodes of the re:Think podcast series, which has over 20 episodes. Each episode is an audio program recorded in mp3 format. As we continue to add new episodes, we will want to use AI services to make the task of querying and searching for specific content more scalable without the need to manually add metadata for each episode.
Prerequisites
In addition to having access to AWS services through the AWS Management Console, you need a few other resources to deploy this solution.
First, you need a library of audio files to catalog, query, and search. For this post, we use episodes of the AWS re:Think podcast series.
To make API calls to Amazon Bedrock from our generative AI application, we use Python version 3.11.4 and the AWS SDK for Python (Boto3).
Transcribe audio files
The first task is to transcribe each mp3 file using Amazon Transcribe. For instructions on transcribing with the AWS Management Console or AWS CLI, refer to the Amazon Transcribe Developer guide. Amazon Transcribe can create a transcript for each episode and store it as an S3 object in JSON format.
Catalog audio files using tagging
To catalog each episode, we tag the S3 object for each episode with the corresponding episode title. For instructions on tagging objects in S3, refer to the Amazon Simple Storage Service User Guide. For example, for the S3 object AI-Accelerators.json, we tag it with key = “title” and value = “Episode 20: AI Accelerators in the Cloud.”
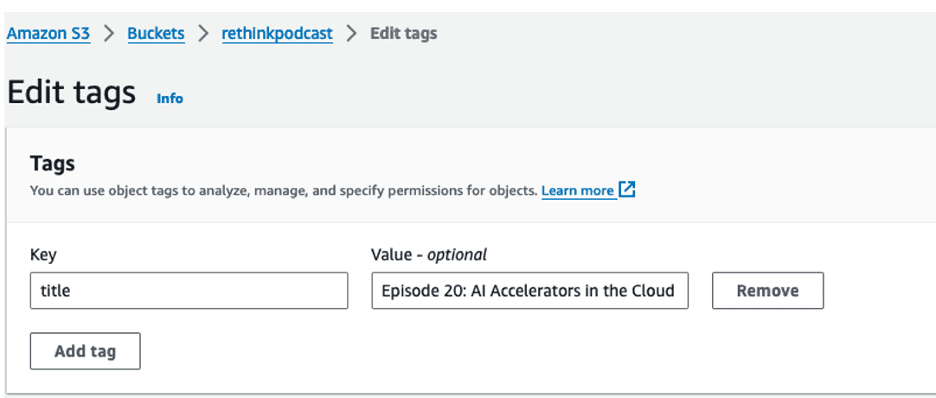
The title is the only metadata we need to manually add for each audio file. There is no need to manually add timestamps for each chapter or section in order to later search for specific content.
Set up a vector database using Knowledge Bases for Amazon Bedrock
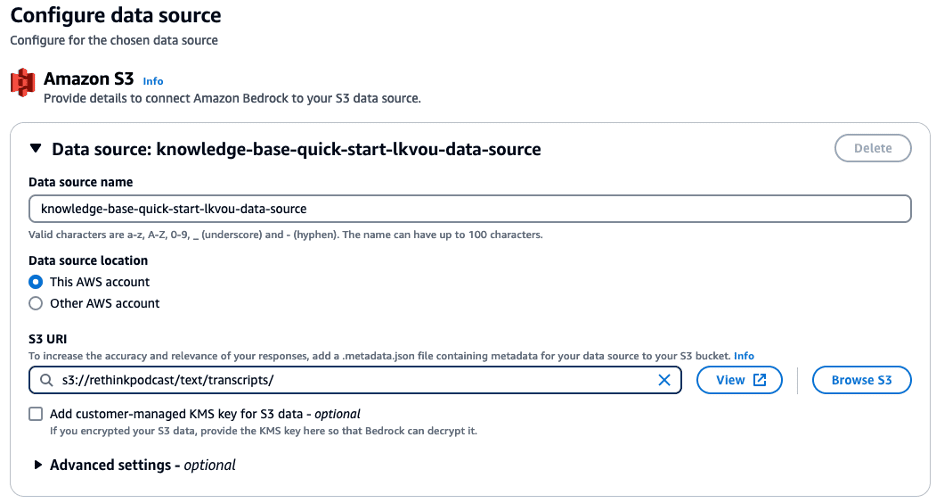
Next, we set up our fully managed RAG workflow using Knowledge Bases for Amazon Bedrock. For instructions on creating a knowledge base, refer to the Amazon Bedrock User Guide. We begin by specifying a data source. In our case, we choose the S3 bucket location where our transcripts in JSON format are stored.
Next, we select an embedding model. The embedding model will convert each chunk of our transcript into embeddings. Embeddings are numbers, and the meaning of each embedding depends on the model. In our example, we select Titan Text Embeddings v2 with a dimension size of 1024.
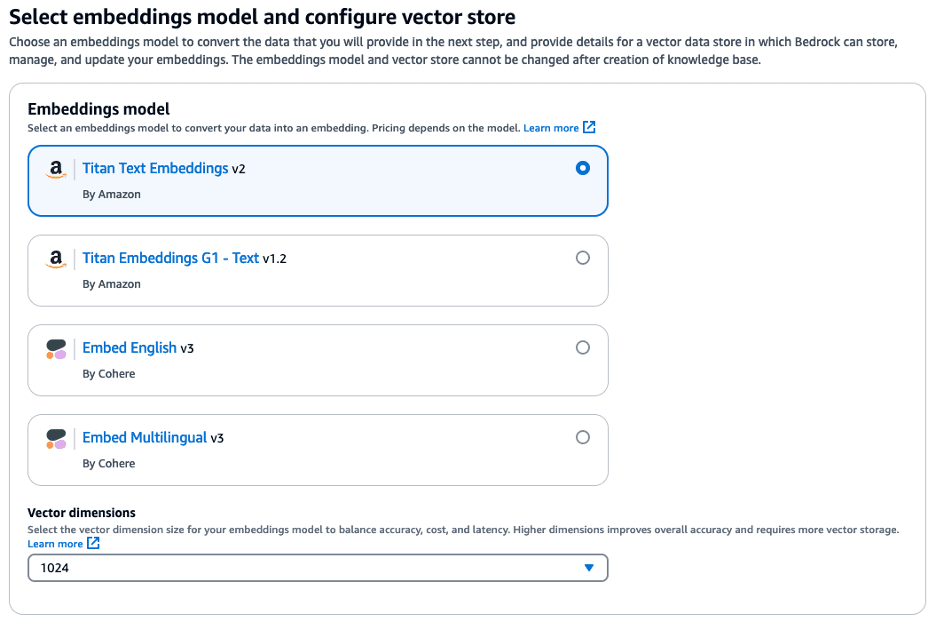
The embeddings are stored as vectors in a vector database. You can either specify an existing vector database you have already created or have Knowledge Bases for Amazon Bedrock create one for you. For our example, we have Knowledge Bases for Amazon Bedrock create a vector database using Amazon OpenSearch Serverless.

Before you can query the vector database, you must first sync it with the data source. During each sync operation, Knowledge Bases for Amazon Bedrock will split the data source into chunks and then use the selected embedding model to embed each chunk as a vector. Knowledge Bases for Amazon Bedrock will then store these vectors in the vector database.
The sync operation as well as other Amazon Bedrock operations described so far can be performed either using the console or API calls.
Query the audio files
Now we’re ready to query and search for specific content from our library of podcast episodes. In episode 20, titled “AI Accelerators in the Cloud,” our guest Matthew McClean, a senior manager from AWS’s Annapurna team, shared why AWS decided to buy Annapurna Labs in 2015. For our first query, we ask, “Why did AWS acquire Annapurna Labs?”
We entered this query into Knowledge Bases for Amazon Bedrock using Anthropic Claude and got the following response:
“AWS acquired Annapurna Labs in 2015 because Annapurna was providing AWS with nitro cards that offloaded virtualization, security, networking and storage from EC2 instances to free up CPU resources.”
This is an exact quote from Matthew McClean in the podcast episode. You wouldn’t get this quote if you had entered the same prompt into other publicly available generative AI chatbots because they don’t have the vector database with embeddings of the podcast transcript to provide more relevant context.
Retrieve an episode title
Now let’s suppose that in addition to getting more relevant responses, we also want to retrieve the correct podcast episode title that was relevant to this query from our catalog of podcast episodes.
To retrieve the episode title, we first use the most relevant data chunk from the query. Whenever Knowledge Bases for Amazon Bedrock responds to a query, it also provides one or more chunks of data that it retrieved from the vector database that were most relevant to the query in order of relevance. We can take the first chunk that was returned. These chunks are returned as JSON documents. Nested inside the JSON is the S3 location of the transcript object. In our example, the S3 location is s3://rethinkpodcast/text/transcripts/AI-Accelerators.json.
The first words in the chunk text are: “Yeah, sure. So maybe I can start with the history of Annapurna…”
Because we have already tagged this transcript object in Amazon S3 with the episode title, we can retrieve the title by retrieving the value of the tag where key = “title”. In this case, the title is “Episode 20: AI Accelerators in the Cloud.”
Search the start time
What if we also want to search and find the start time inside the episode where the relevant content begins? We want to do so without having to manually read through the transcript or listen to the episode from the beginning, and without manually adding timestamps for every chapter.
We can find the start time much faster by having our generative AI application make a few more API calls. We start by treating the chunk text as a substring of the entire transcript. We then search for the start time of the first word in the chunk text.
In our example, the first words returned were “Yeah, sure. So maybe I can start with the history of Annapurna…” We now need to search the entire transcript for the start time of the word “Yeah.”
Amazon Transcribe outputs the start time of every word in the transcript. However, any word can appear more than once. The word “Yeah” occurs 28 times in the transcript, and each occurrence has its own start time. So how do we determine the correct start time for “Yeah” in our example?
There are multiple approaches an application developer can use to find the correct start time. For our example, we use the Python string find() method to find the position of the chunk text within the entire transcript.
For the chunk text that begins with “Yeah, sure. So maybe I can start with the history of Annapurna…” the find() method returned the position as 2047. If we treat the transcript as one long text string, the chunk “Yeah, sure. So maybe…” starts at character position 2047.
Finding the start time now becomes a matter of counting the character position of each word in the transcript and using it to look up the correct start time from the transcript file generated by Amazon Transcribe. This may be tedious for a person to do manually, but trivial for a computer.
In our example Python code, we loop through an array that contains the start time for each token while counting the number of the character position that each token starts at. Because we’re looping through the tokens, we can build a new array that stores the start time for each character position.
In this example query, the start time for the word “Yeah” at position 2047 is 160 seconds, or 2 minutes and 40 seconds into the podcast. You can check the recording starting at 2 minutes 40 seconds.
Clean up
This solution incurs charges based on the services you use:
- Amazon Transcribe operates under a pay-as-you-go pricing model. For more details, see Amazon Transcribe Pricing.
- Amazon Bedrock uses an on-demand quota, so you only pay for what you use. For more information, refer to Amazon Bedrock pricing.
- With OpenSearch Serverless, you only pay for the resources consumed by your workload.
- If you’re using Knowledge Bases for Amazon Bedrock with other vector databases besides OpenSearch Serverless, you may continue to incur charges even when not running any queries. It is recommended you delete your knowledge base and its associated vector store along with audio files stored in Amazon S3 to avoid unnecessary costs when you’re done testing this solution.
Conclusion
Cataloging, querying, and searching through large volumes of audio files can be difficult to scale. In this post, we showed how Amazon Transcribe and Knowledge Bases for Amazon Bedrock can help automate and make the process of retrieving relevant information from audio files more scalable.
You can begin transcribing your own library of audio files with Amazon Transcribe. To learn more on how Knowledge Bases for Amazon Bedrock can then orchestrate a RAG workflow for your transcripts with vector stores, refer to Knowledge Bases now delivers fully managed RAG experience in Amazon Bedrock.
With the help of these AI services, we can now expand the frontiers of our knowledge bases.
About the Author

Nolan Chen is a Partner Solutions Architect at AWS, where he helps startup companies build innovative solutions using the cloud. Prior to AWS, Nolan specialized in data security and helping customers deploy high-performing wide area networks. Nolan holds a bachelor’s degree in Mechanical Engineering from Princeton University.
Leave a Reply