
How Cisco accelerated the use of generative AI with Amazon SageMaker Inference
This post is co-authored with Travis Mehlinger and Karthik Raghunathan from Cisco.
Webex by Cisco is a leading provider of cloud-based collaboration solutions, including video meetings, calling, messaging, events, polling, asynchronous video, and customer experience solutions like contact center and purpose-built collaboration devices. Webex’s focus on delivering inclusive collaboration experiences fuels their innovation, which uses artificial intelligence (AI) and machine learning (ML), to remove the barriers of geography, language, personality, and familiarity with technology. Its solutions are underpinned with security and privacy by design. Webex works with the world’s leading business and productivity apps—including AWS.
Cisco’s Webex AI (WxAI) team plays a crucial role in enhancing these products with AI-driven features and functionalities, using large language models (LLMs) to improve user productivity and experiences. In the past year, the team has increasingly focused on building AI capabilities powered by LLMs to improve productivity and experience for users. Notably, the team’s work extends to Webex Contact Center, a cloud-based omni-channel contact center solution that empowers organizations to deliver exceptional customer experiences. By integrating LLMs, the WxAI team enables advanced capabilities such as intelligent virtual assistants, natural language processing (NLP), and sentiment analysis, allowing Webex Contact Center to provide more personalized and efficient customer support. However, as these LLM models grew to contain hundreds of gigabytes of data, the WxAI team faced challenges in efficiently allocating resources and starting applications with the embedded models. To optimize its AI/ML infrastructure, Cisco migrated its LLMs to Amazon SageMaker Inference, improving speed, scalability, and price-performance.
This post highlights how Cisco implemented new functionalities and migrated existing workloads to Amazon SageMaker inference components for their industry-specific contact center use cases. By integrating generative AI, they can now analyze call transcripts to better understand customer pain points and improve agent productivity. Cisco has also implemented conversational AI experiences, including chatbots and virtual agents that can generate human-like responses, to automate personalized communications based on customer context. Additionally, they are using generative AI to extract key call drivers, optimize agent workflows, and gain deeper insights into customer sentiment. Cisco’s adoption of SageMaker Inference has enabled them to streamline their contact center operations and provide more satisfying, personalized interactions that address customer needs.
In this post, we discuss the following:
- Cisco’s business use cases and outcomes
- How Cisco accelerated the use of generative AI powered by LLMs for their contact center use cases with the help of SageMaker Inference
- Cisco’s generative AI inference architecture, which is built as a robust and secure foundation, using various services and features such as SageMaker Inference, Amazon Bedrock, Kubernetes, Prometheus, Grafana, and more
- How Cisco uses an LLM router and auto scaling to route requests to appropriate LLMs for different tasks while simultaneously scaling their models for resiliency and performance efficiency.
- How the solutions in this post impacted Cisco’s business roadmap and strategic partnership with AWS
- How Cisco helped SageMaker Inference build new capabilities to deploy generative AI applications at scale
Enhancing collaboration and customer engagement with generative AI: Webex’s AI-powered solutions
In this section, we discuss Cisco’s AI-powered use cases.
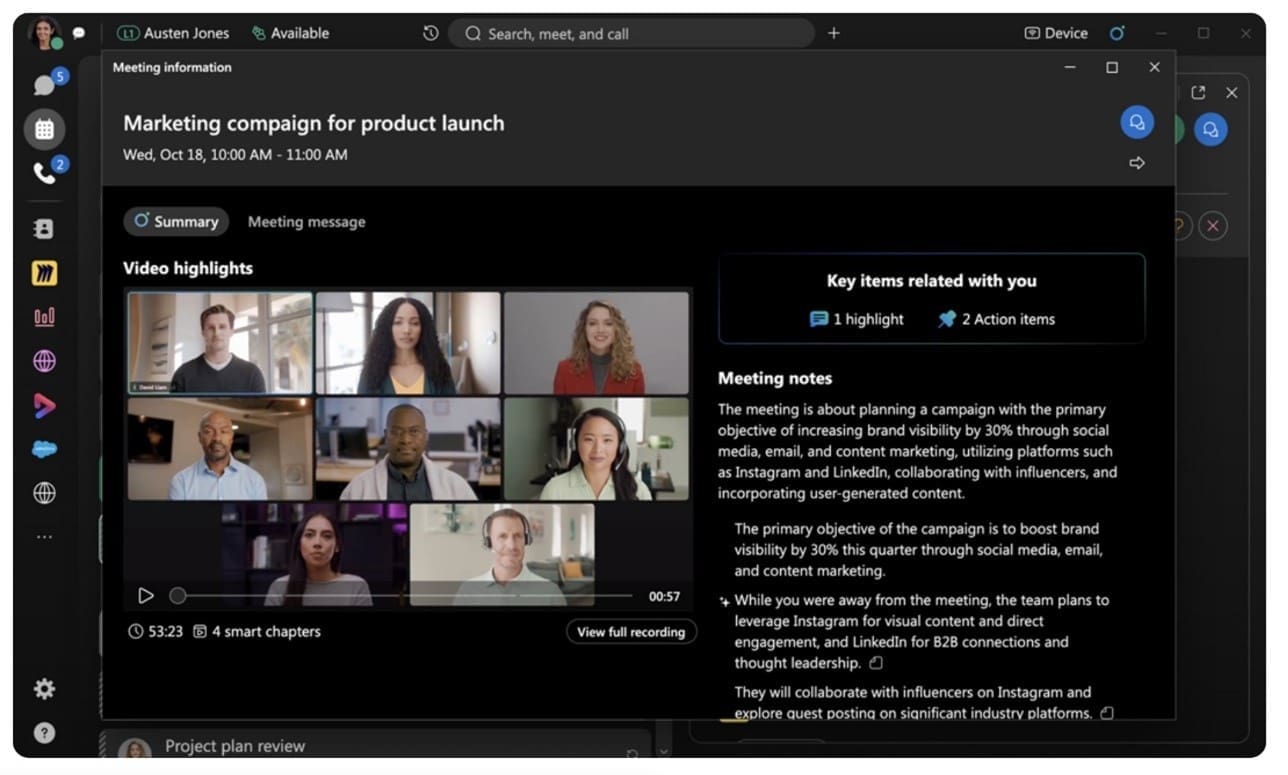
Meeting summaries and insights
For Webex Meetings, the platform uses generative AI to automatically summarize meeting recordings and transcripts. This extracts the key takeaways and action items, helping distributed teams stay informed even if they missed a live session. The AI-generated summaries provide a concise overview of important discussions and decisions, allowing employees to quickly get up to speed. Beyond summaries, Webex’s generative AI capabilities also surface intelligent insights from meeting content. This includes identifying action items, highlighting critical decisions, and generating personalized meeting notes and to-do lists for each participant. These insights help make meetings more productive and hold attendees accountable.
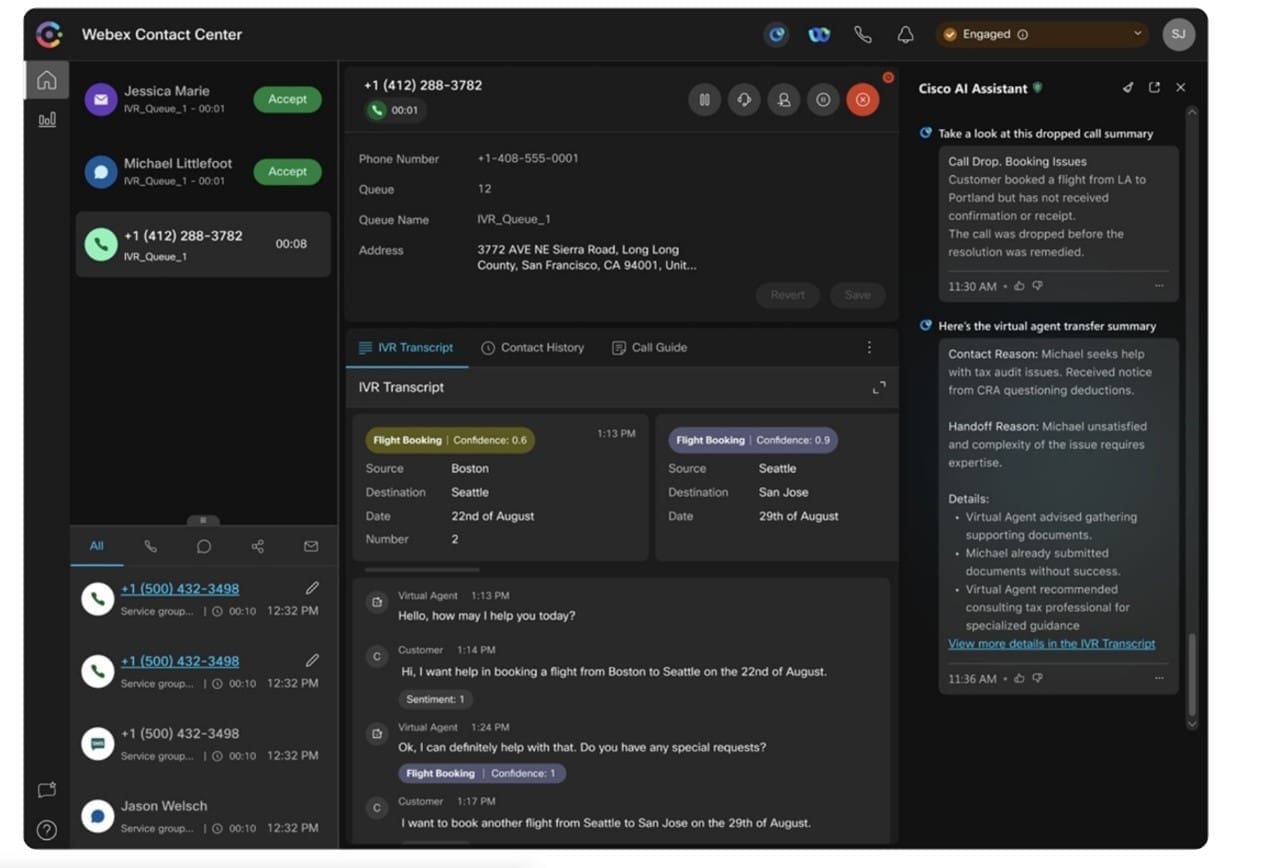
Enhancing contact center experiences
Webex is also applying generative AI to its contact center solutions, enabling more natural, human-like conversations between customers and agents. The AI can generate contextual, empathetic responses to customer inquiries, as well as automatically draft personalized emails and chat messages. This helps contact center agents work more efficiently while maintaining a high level of customer service.
Webex customers realize positive outcomes with generative AI
Webex’s adoption of generative AI is driving tangible benefits for customers. Clients using the platform’s AI-powered meeting summaries and insights have reported productivity gains. Webex customers using the platform’s generative AI for contact centers have handled hundreds of thousands of calls with improved customer satisfaction and reduced handle times, enabling more natural, empathetic conversations between agents and clients. Webex’s strategic integration of generative AI is empowering users to work smarter and deliver exceptional experiences.
For more details on how Webex is harnessing generative AI to enhance collaboration and customer engagement, see Webex | Exceptional Experiences for Every Interaction on the Webex blog.
Using SageMaker Inference to optimize resources for Cisco
Cisco’s WxAI team is dedicated to delivering advanced collaboration experiences powered by cutting-edge ML. The team develops a comprehensive suite of AI and ML features for the Webex ecosystem, including audio intelligence capabilities like noise removal and optimizing speaker voices, language intelligence for transcription and translation, and video intelligence features like virtual backgrounds. At the forefront of WxAI’s innovations is the AI-powered Webex Assistant, a virtual assistant that provides voice-activated control and seamless meeting support in multiple languages. To build these sophisticated capabilities, WxAI uses LLMs, which can contain up to hundreds of gigabytes of training data.
Initially, WxAI embedded LLM models directly into the application container images running on Amazon Elastic Kubernetes Service (Amazon EKS). However, as the models grew larger and more complex, this approach faced significant scalability and resource utilization challenges. Operating the resource-intensive LLMs through the applications required provisioning substantial compute resources, which slowed down processes like allocating resources and starting applications. This inefficiency hampered WxAI’s ability to rapidly develop, test, and deploy new AI-powered features for the Webex portfolio. To address these challenges, the WxAI team turned to SageMaker Inference—a fully managed AI inference service that allows seamless deployment and scaling of models independently from the applications that use them. By decoupling the LLM hosting from the Webex applications, WxAI could provision the necessary compute resources for the models without impacting the core collaboration and communication capabilities.
“The applications and the models work and scale fundamentally differently, with entirely different cost considerations; by separating them rather than lumping them together, it’s much simpler to solve issues independently.”
– Travis Mehlinger, Principal Engineer at Cisco.
This architectural shift has enabled Webex to harness the power of generative AI across its suite of collaboration and customer engagement solutions.
Solution overview: Improving efficiency and reducing costs by migrating to SageMaker Inference
To address the scalability and resource utilization challenges faced with embedding LLMs directly into their applications, the WxAI team migrated to SageMaker Inference. By taking advantage of this fully managed service for deploying LLMs, Cisco unlocked significant performance and cost-optimization opportunities. Key benefits include the ability to deploy multiple LLMs behind a single endpoint for faster scaling and improved response latencies, as well as cost savings. Additionally, the WxAI team implemented an LLM proxy to simplify access to LLMs for Webex teams, enable centralized data collection, and reduce operational overhead. With SageMaker Inference, Cisco can efficiently manage and scale their LLM deployments, harnessing the power of generative AI across the Webex portfolio while maintaining optimal performance, scalability, and cost-effectiveness.
The following diagram illustrates the WxAI architecture on AWS.
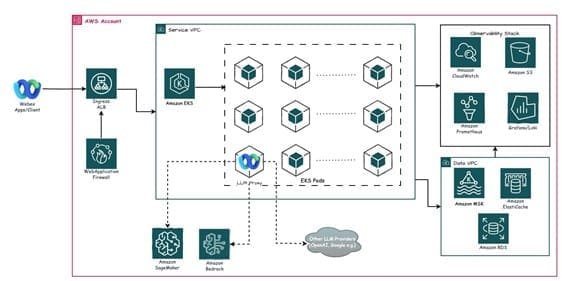
The architecture is built on a robust and secure AWS foundation:
- The architecture uses AWS services like Application Load Balancer, AWS WAF, and EKS clusters for seamless ingress, threat mitigation, and containerized workload management.
- The LLM proxy (a microservice deployed on an EKS pod as part of the Service VPC) simplifies the integration of LLMs for Webex teams, providing a streamlined interface and reducing operational overhead. The LLM proxy supports LLM deployments on SageMaker Inference, Amazon Bedrock, or other LLM providers for Webex teams.
- The architecture uses SageMaker Inference for optimized model deployment, auto scaling, and routing mechanisms.
- The system integrates Loki for logging, Amazon Managed Service for Prometheus for metrics, and Grafana for unified visualization, seamlessly integrated with Cisco SSO.
- The Data VPC houses the data layer components, including Amazon ElastiCache for caching and Amazon Relational Database Service (Amazon RDS) for database services, providing efficient data access and management.
Use case overview: Contact center topic analytics
A key focus area for the WxAI team is to enhance the capabilities of the Webex Contact Center platform. A typical Webex Contact Center installation has hundreds of agents handling many interactions through various channels like phone calls and digital channels. Webex’s AI-powered Topic Analytics feature extracts the key reasons customers are calling about by analyzing aggregated historical interactions and clustering them into meaningful topic categories, as shown in the following screenshot. The contact center administrator can then use these insights to optimize operations, enhance agent performance, and ultimately deliver a more satisfactory customer experience.
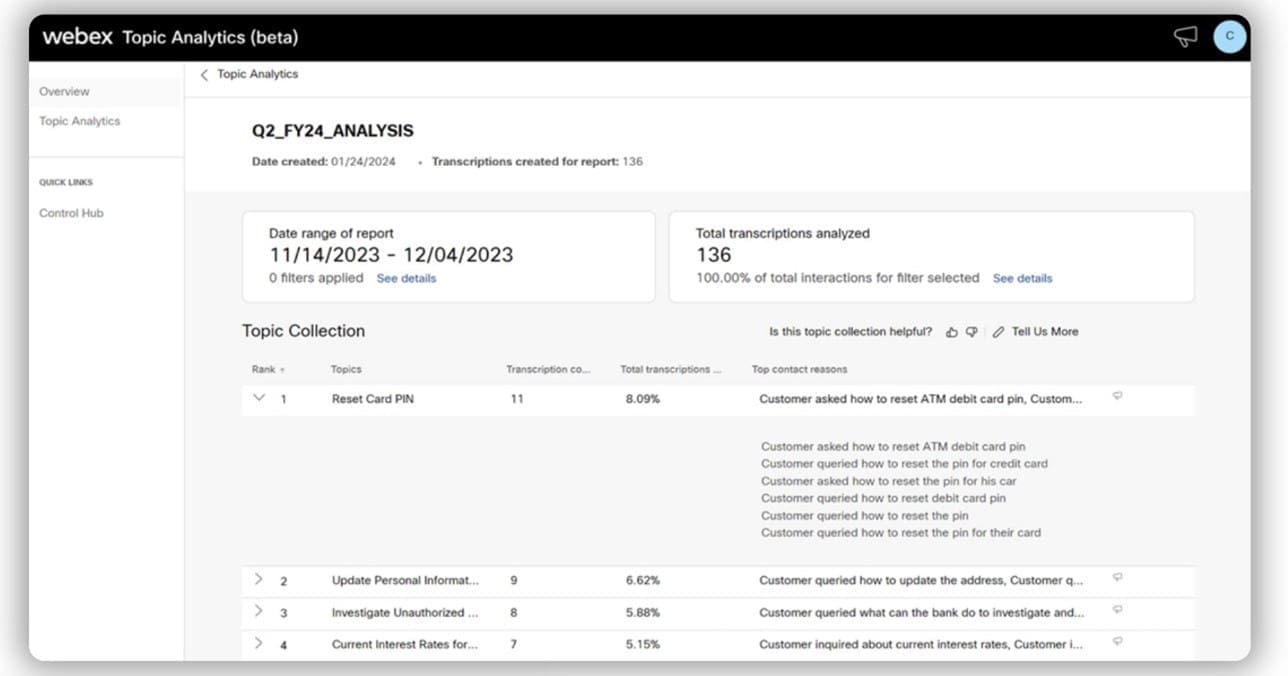
The Topic Analytics feature is powered by a pipeline of three models: a call driver extraction model, a topic clustering model, and a topic labeling model, as illustrated in the following diagram.
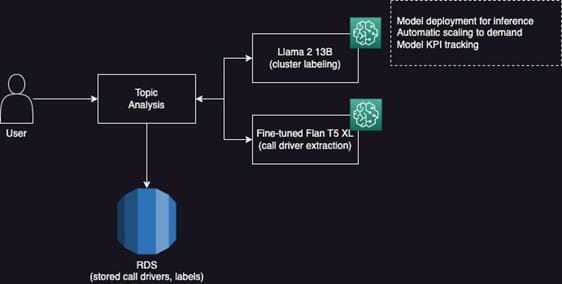
The model details are as follows:
- Call driver extraction – This generative model summarizes the primary reason or intent (referred to as the call driver) behind a customer’s call. Accurate automatic tagging of calls with call drivers helps contact center supervisors and administrators quickly understand the primary reason for any historical call. One of the key considerations when solving this problem was selecting the right model to balance quality and operational costs. The WxAI team chose the FLAN T5 model on SageMaker Inference and instruction fine-tuned it for extracting call drivers from call transcripts. FLAN-T5 is a powerful text-to-text transfer transformer model that performs various natural language understanding and generation tasks. This workload had a global footprint deployed in
us-east-2,eu-west-2,eu-central-1,ap-southeast-1,ap-southeast-2,ap-northeast-1, andca-central-1AWS - Topic clustering – Although automatically tagging every contact center interaction with its call driver is a useful feature in itself, analyzing these call drivers in an aggregated fashion over a large batch of calls can uncover even more interesting trends and insights. The topic clustering model achieves this by clustering all the individually extracted call drivers from a large batch of calls into different topic clusters. It does this by creating a semantic embedding for each call driver and employing an unsupervised hierarchical clustering technique that operates on the vector embeddings. This results in distinct and coherent topic clusters where semantically similar call drivers are grouped together.
- Topic labeling – The topic labeling model is a generative model that creates a descriptive name to serve as the label for each topic cluster. Several LLMs were prompt-tuned and evaluated in a few-shot setting to choose the ideal model for the label generation task. Finally, Llama2-13b-chat, with its ability to better capture contextual nuances and semantics of natural language conversation, was used for its accuracy, performance, and cost-effectiveness. Additionally, Llama2-13b-chat was deployed and used on SageMaker inference components, while maintaining relatively low operating costs compared to other LLMs, by using specific hardware like g4dn and g5
This solution also used the auto scaling capabilities of SageMaker to dynamically adjust the number of instances based on a desired minimum of 1 endpoint and maximum of 30. This approach provides efficient resource utilization while maintaining high throughput, allowing the WxAI platform to handle batch jobs overnight and scale to hundreds of inferences per minute during peak hours. By deploying the model on SageMaker Inference with auto scaling, WxAI team was able to deliver reliable and accurate responses to customer interactions for their Topic Analytics use case.
By accurately pinpointing the call driver, the system can suggest appropriate actions, resources, and next steps to the agent, streamlining the customer support process, further leading to personalized and accurate responses to customer questions.
To handle fluctuating demand and optimize resource utilization, the WxAI team implemented auto scaling for their SageMaker Inference endpoints. They configured the endpoints to scale from a minimum to a maximum instance count based on GPU utilization. Additionally, the LLM proxy routed requests between the different LLMs deployed on SageMaker Inference. This proxy abstracts the complexities of communicating with various LLM providers and enables centralized data collection and analysis. This led to enhanced generative AI workflows, optimized latency, and personalized use case implementations.
Benefits
Through the strategic adoption of AWS AI services, Cisco’s WxAI team has realized significant benefits, enabling them to build cutting-edge, AI-powered collaboration capabilities more rapidly and cost-effectively:
- Improved development and deployment cycle time – By decoupling models from applications, the team has streamlined processes like bug fixes, integration testing, and feature rollouts across environments, accelerating their overall development velocity.
- Simplified engineering and delivery – The clear separation of concerns between the lean application layer and resource-intensive model layer has simplified engineering efforts and delivery, allowing the team to focus on innovation rather than infrastructure complexities.
- Reduced costs – By using fully managed services like SageMaker Inference, the team has offloaded infrastructure management overhead. Additionally, capabilities like asynchronous inference and multi-model endpoints have enabled significant cost optimization without compromising performance or availability.
- Scalability and performance – Services like SageMaker Inference and Amazon Bedrock, combined with technologies like NVIDIA Triton Inference Server on SageMaker, have empowered the WxAI team to scale their AI/ML workloads reliably and deliver high-performance inference for demanding use cases.
- Accelerated innovation – The partnership with AWS has given the WxAI team access to cutting-edge AI services and expertise, enabling them to rapidly prototype and deploy innovative capabilities like the AI-powered Webex Assistant and advanced contact center AI features.
Cisco’s contributions to SageMaker Inference: Enhancing generative AI inference capabilities
Building upon the success of their strategic migration to SageMaker Inference, Cisco has been instrumental in partnering with the SageMaker Inference team to build and enhance key generative AI capabilities within the SageMaker platform. Since the early days of generative AI, Cisco has provided the SageMaker Inference team with valuable inputs and expertise, enabling the introduction of several new features and optimizations:
- Cost and performance optimizations for generative AI inference – Cisco helped the SageMaker Inference team develop innovative techniques to optimize the use of accelerators, enabling SageMaker Inference to reduce foundation model (ML) deployment costs by 50% on average and latency by 20% on average with inference components. This breakthrough delivers significant cost savings and performance improvements for customers running generative AI workloads on SageMaker.
- Scaling improvements for generative AI inference – Cisco’s expertise in distributed systems and auto scaling has also helped the SageMaker team develop advanced capabilities to better handle the scaling requirements of generative AI models. These improvements reduce auto scaling times by up to 40% and auto scaling detection by 6 times, so customers can rapidly scale their generative AI workloads on SageMaker to meet spikes in demand without compromising performance.
- Streamlined generative AI model deployment for inference – Recognizing the need for simplified generative AI model deployment, Cisco collaborated with AWS to introduce the ability to deploy open source LLMs and FMs with just a few clicks. This user-friendly functionality removes the complexity traditionally associated with deploying these advanced models, empowering more customers to harness the power of generative AI.
- Simplified inference deployment for Kubernetes customers – Cisco’s deep expertise in Kubernetes and container technologies helped the SageMaker team develop new Kubernetes Operator-based inference capabilities. These innovations make it straightforward for customers running applications on Kubernetes to deploy and manage generative AI models, reducing LLM deployment costs by 50% on average.
- Using NVIDIA Triton Inference Server for generative AI – Cisco worked with AWS to integrate the NVIDIA Triton Inference Server, a high-performance model serving container managed by SageMaker, to power generative AI inference on SageMaker Inference. This enabled the WxAI team to scale their AI/ML workloads reliably and deliver high-performance inference for demanding generative AI use cases.
- Packaging generative AI models more efficiently – To further simplify the generative AI model lifecycle, Cisco worked with AWS to enhance the capabilities in SageMaker for packaging LLMs and FMs for deployment. These improvements make it straightforward to prepare and deploy these generative AI models, accelerating their adoption and integration.
- Improved documentation for generative AI – Recognizing the importance of comprehensive documentation to support the growing generative AI ecosystem, Cisco collaborated with the AWS team to enhance the SageMaker documentation. This includes detailed guides, best practices, and reference materials tailored specifically for generative AI use cases, helping customers quickly ramp up their generative AI initiatives on the SageMaker platform.
By closely partnering with the SageMaker Inference team, Cisco has played a pivotal role in driving the rapid evolution of generative AI Inference capabilities in SageMaker. The features and optimizations introduced through this collaboration are empowering AWS customers to unlock the transformative potential of generative AI with greater ease, cost-effectiveness, and performance.
“Our partnership with the SageMaker Inference product team goes back to the early days of generative AI, and we believe the features we have built in collaboration, from cost optimizations to high-performance model deployment, will broadly help other enterprises rapidly adopt and scale generative AI workloads on SageMaker, unlocking new frontiers of innovation and business transformation.”
– Travis Mehlinger, Principal Engineer at Cisco.
Conclusion
By using AWS services like SageMaker Inference and Amazon Bedrock for generative AI, Cisco’s WxAI team has been able to optimize their AI/ML infrastructure, enabling them to build and deploy AI-powered features more efficiently, reliably, and cost-effectively. This strategic approach has unlocked significant benefits for Cisco in deploying and scaling its generative AI capabilities for the Webex platform. Cisco’s own journey with generative AI, as showcased in this post, offers valuable lessons and insights for other uses of SageMaker Inference.
Recognizing the impact of generative AI, Cisco has played a crucial role in shaping the future of these capabilities within SageMaker Inference. By providing valuable insights and hands-on collaboration, Cisco has helped AWS develop a range of powerful features that are making generative AI more accessible and scalable for organizations. From optimizing infrastructure costs and performance to streamlining model deployment and scaling, Cisco’s contributions have been instrumental in enhancing the SageMaker Inference service.
Moving forward, the Cisco-AWS partnership aims to drive further advancements in areas like conversational and generative AI inference. As generative AI adoption accelerates across industries, Cisco’s Webex platform is designed to scale and streamline user experiences through various use cases discussed in this post and beyond. You can expect to see ongoing innovation from this collaboration in SageMaker Inference capabilities, as Cisco and SageMaker Inference continue to push the boundaries of what’s possible in the world of AI.
For more information on Webex Contact Center’s Topic Analytics feature and related AI capabilities, refer to The Webex Advantage: Navigating Customer Experience in the Age of AI on the Webex blog.
About the Authors
 Travis Mehlinger is a Principal Software Engineer in the Webex Collaboration AI group, where he helps teams develop and operate cloud-centered AI and ML capabilities to support Webex AI features for customers around the world. In his spare time, Travis enjoys cooking barbecue, playing video games, and traveling around the US and UK to race go-karts.
Travis Mehlinger is a Principal Software Engineer in the Webex Collaboration AI group, where he helps teams develop and operate cloud-centered AI and ML capabilities to support Webex AI features for customers around the world. In his spare time, Travis enjoys cooking barbecue, playing video games, and traveling around the US and UK to race go-karts.
 Karthik Raghunathan is the Senior Director for Speech, Language, and Video AI in the Webex Collaboration AI Group. He leads a multidisciplinary team of software engineers, machine learning engineers, data scientists, computational linguists, and designers who develop advanced AI-driven features for the Webex collaboration portfolio. Prior to Cisco, Karthik held research positions at MindMeld (acquired by Cisco), Microsoft, and Stanford University.
Karthik Raghunathan is the Senior Director for Speech, Language, and Video AI in the Webex Collaboration AI Group. He leads a multidisciplinary team of software engineers, machine learning engineers, data scientists, computational linguists, and designers who develop advanced AI-driven features for the Webex collaboration portfolio. Prior to Cisco, Karthik held research positions at MindMeld (acquired by Cisco), Microsoft, and Stanford University.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
 Ravi Thakur is a Senior Solutions Architect at AWS, based in Charlotte, NC. He specializes in solving complex business challenges using distributed, cloud-centered, and well-architected patterns. Ravi’s expertise includes microservices, containerization, AI/ML, and generative AI. He empowers AWS strategic customers on digital transformation journeys, delivering bottom-line benefits. In his spare time, Ravi enjoys motorcycle rides, family time, reading, movies, and traveling.
Ravi Thakur is a Senior Solutions Architect at AWS, based in Charlotte, NC. He specializes in solving complex business challenges using distributed, cloud-centered, and well-architected patterns. Ravi’s expertise includes microservices, containerization, AI/ML, and generative AI. He empowers AWS strategic customers on digital transformation journeys, delivering bottom-line benefits. In his spare time, Ravi enjoys motorcycle rides, family time, reading, movies, and traveling.
 Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
 Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
Leave a Reply