
Visier’s data science team boosts their model output 10 times by migrating to Amazon SageMaker
This post is co-written with Ike Bennion from Visier.
Visier’s mission is rooted in the belief that people are the most valuable asset of every organization and that optimizing their potential requires a nuanced understanding of workforce dynamics.
Paycor is an example of the many world-leading enterprise people analytics companies that trust and use the Visier platform to process large volumes of data to generate informative analytics and actionable predictive insights.
Visier’s predictive analytics has helped organizations such as Providence Healthcare retain critical employees within their workforce and saved an estimated $6 million by identifying and preventing employee attrition by using a framework built on top of Visier’s risk-of-exit predictions.
Trusted sources like Sapient Insights Group, Gartner, G2, Trust Radius, and RedThread Research have recognized Visier for its inventiveness, great user experience, and vendor and customer satisfaction. Today, over 50,000 organizations in 75 countries use the Visier platform as the driver to shape business strategies and drive better business results.
Unlocking growth potential by overcoming the tech stack barrier
Visier’s analytics and predictive power is what makes its people analytics solution so valuable. Users without data science or analytics experience can generate rigorous data-backed predictions to answer big questions like time-to-fill for important positions, or resignation risk for crucial employees.
It was an executive priority at Visier to continue innovating in their analytics and predictive capabilities because those make up one of the cornerstones of what their users love about their product.
The challenge for Visier was that their data science tech stack was holding them back from innovating at the rate they wanted to. It was costly and time consuming to experiment and implement new analytic and predictive capabilities because:
- The data science tech stack was tightly coupled with the entire platform development. The data science team couldn’t roll out changes independently to production. This limited the team to fewer and slower iteration cycles.
- The data science tech stack was a collection of solutions from multiple vendors, which led to additional management and support overhead for the data science team.
Steamlining model management and deployment with SageMaker
Amazon SageMaker is a managed machine learning platform that provides data scientists and data engineers familiar concepts and tools to build, train, deploy, govern, and manage the infrastructure needed to have highly available and scalable model inference endpoints. Amazon SageMaker Inference Recommender is an example of a tool that can help data scientists and data engineers be more autonomous and less reliant on outside teams by providing guidance on right-sizing inference instances.
The existing data science tech stack was one of the many services comprising Visier’s application platform. Using the SageMaker platform, Visier built an API-based microservices architecture for the analytics and predictive services that was decoupled from the application platform. This gave the data science team the desired autonomy to deploy changes independently and release new updates more frequently.
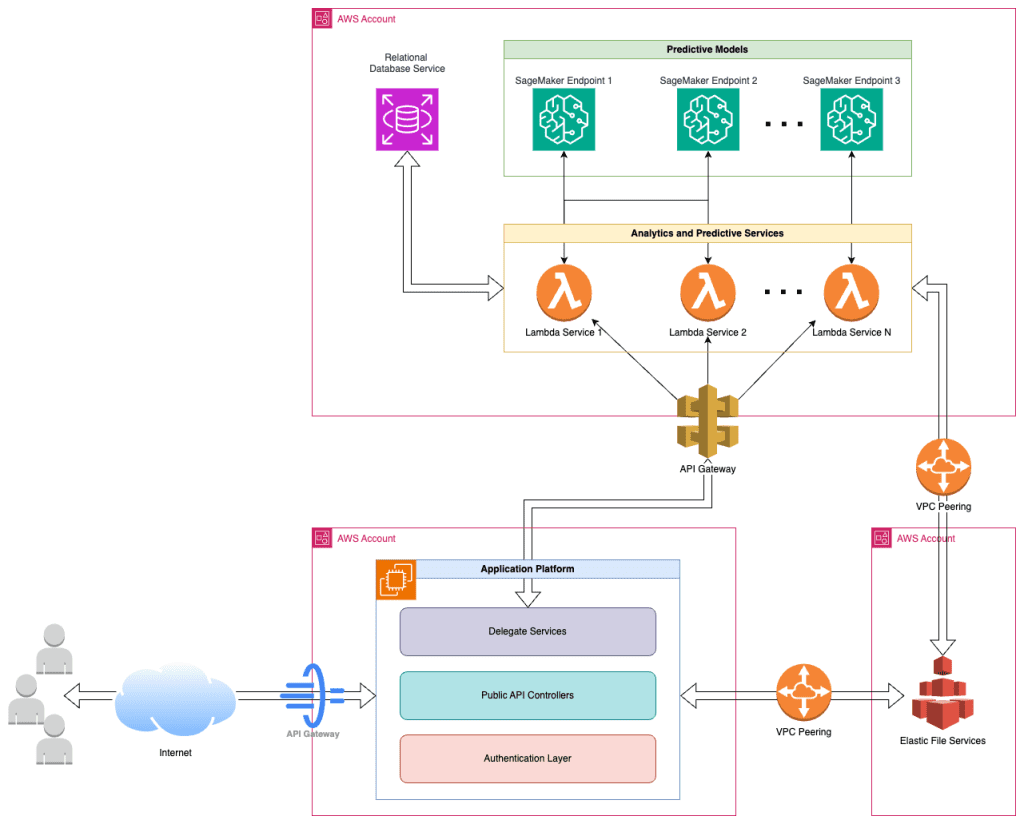
The results
The first improvement Visier saw after migrating the analytics and predictive services to SageMaker was that it allowed the data science team to spend more time on innovations—such as the build-up of a prediction model validation pipeline—rather than having to spend time on deployment details and vendor tooling integration.
Prediction model validation
The following figure shows the prediction model validation pipeline.
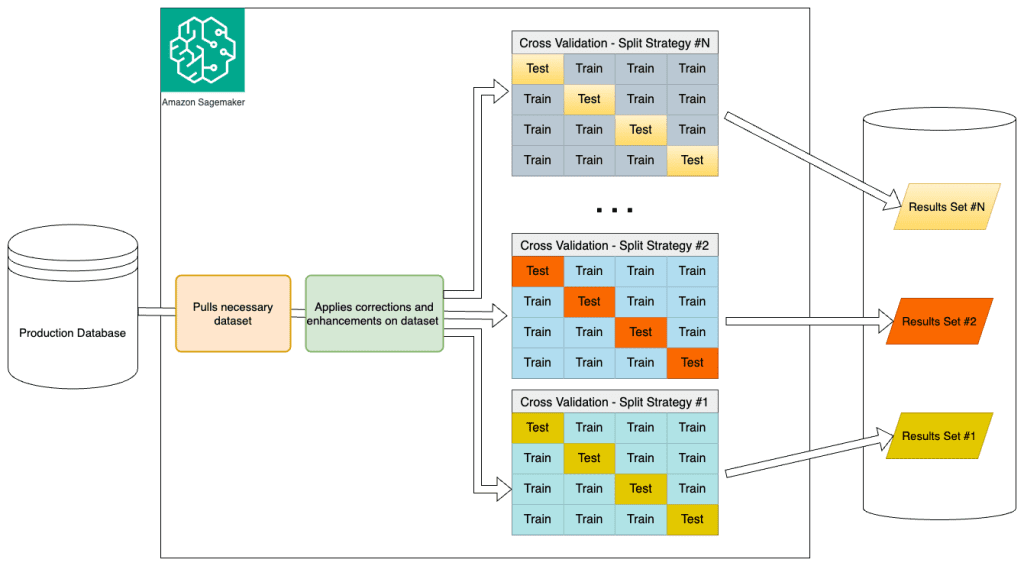
Using SageMaker, Visier built a prediction model validation pipeline that:
- Pulls the training dataset from the production databases
- Gathers additional validation measures that describe the dataset and specific corrections and enhancements on the dataset
- Performs multiple cross-validation measurements using different split strategies
- Stores the validation results along with metadata about the run in a permanent datastore
The validation pipeline allowed the team to deliver a stream of advancements in the models that improved prediction performance by 30% across their whole customer base.
Train customer-specific predictive models at scale
Visier develops and manages thousands of customer-specific predictive models for their enterprise customers. The second workflow improvement the data science team made was to develop a highly scalable method to generate all of the customer-specific predictive models. This allowed the team to deliver ten times as many models with the same number of resources.
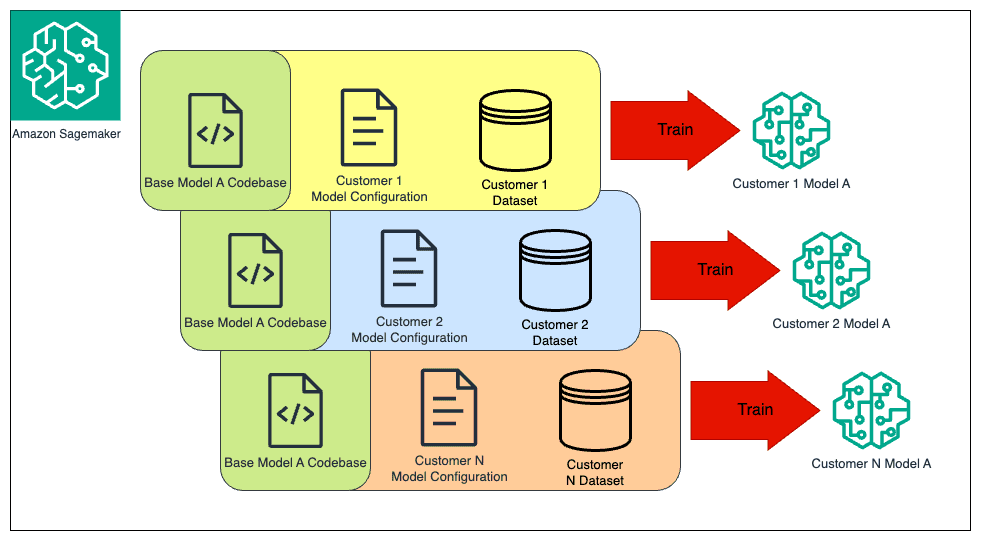 As shown in the preceding figure, the team developed a model-training pipeline where model changes are made in a central prediction codebase. This codebase is executed separately for each Visier customer to train a sequence of custom models (for different points in time) that are sensitive to the specialized configuration of each customer and their data. Visier uses this pattern to scalably push innovation in a single model design to thousands of custom models across their customer base. To ensure state-of-art training efficiency for large models, SageMaker provides libraries that support parallel (SageMaker Model Parallel Library) and distributed (SageMaker Distributed Data Parallelism Library) model training. To learn more about how effective these libraries are, see Distributed training and efficient scaling with the Amazon SageMaker Model Parallel and Data Parallel Libraries.
As shown in the preceding figure, the team developed a model-training pipeline where model changes are made in a central prediction codebase. This codebase is executed separately for each Visier customer to train a sequence of custom models (for different points in time) that are sensitive to the specialized configuration of each customer and their data. Visier uses this pattern to scalably push innovation in a single model design to thousands of custom models across their customer base. To ensure state-of-art training efficiency for large models, SageMaker provides libraries that support parallel (SageMaker Model Parallel Library) and distributed (SageMaker Distributed Data Parallelism Library) model training. To learn more about how effective these libraries are, see Distributed training and efficient scaling with the Amazon SageMaker Model Parallel and Data Parallel Libraries.
Using the model validation workload shown earlier, changes made to a predictive model can be validated in as little as three hours.
Process unstructured data
Iterative improvements, a scalable deployment, and consolidation of data science technology were an excellent start, but when Visier adopted SageMaker, the goal was to enable innovation that was entirely out of reach by the previous tech stack.
A unique advantage that Visier has is the ability to learn from the collective employee behaviors across all their customer base. Tedious data engineering tasks like pulling data into the environment and database infrastructure costs were eliminated by securely storing their vast amount of customer-related datasets within Amazon Simple Storage Service (Amazon S3) and using Amazon Athena to directly query the data using SQL. Visier used these AWS services to combine relevant datasets and feed them directly into SageMaker, resulting in the creation and release of a new prediction product called Community Predictions. Visier’s Community Predictions give smaller organizations the power to create predictions based on the entire community’s data, rather than just their own. That gives a 100-person organization access to the kind of predictions that otherwise would be reserved for enterprises with thousands of employees.
For information about how you can manage and process your own unstructured data, see Unstructured data management and governance using AWS AI/ML and analytics services.
Use Visier Data in Amazon SageMaker
With the transformative success Visier had internally, they wanted ensure their end-customers could also benefit from the Amazon SageMaker platform to develop their own AI and machine learning (AI/ML) models.
Visier has written a full tutorial about how to use Visier Data in Amazon SageMaker and have also built a Python connector available on their GitHub repo. The Python connector allows customers to pipe Visier data to their own AI/ML projects to better understand the impact of their people on financials, operations, customers and partners. These results are often then imported back into the Visier platform to distribute these insights and drive derivative analytics to further improve outcomes across the employee lifecycle.
Conclusion
Visier’s success with Amazon SageMaker demonstrates the power and flexibility of this managed machine learning platform. By using the capabilities of SageMaker, Visier increased their model output by 10 times, accelerated innovation cycles, and unlocked new opportunities such as processing unstructured data for their Community Predictions product.
If you’re looking to streamline your machine learning workflows, scale your model deployments, and unlock insights from your data, explore the possibilities with SageMaker and built-in capabilities such as Amazon SageMaker Pipelines.
Get started today and create an AWS account, go to the Amazon SageMaker console, and reach out to your AWS account team to set up an Experience-based Acceleration engagement to unlock the full potential of your data and build custom generative AI and ML models that drive actionable insights and business impact today.
About the authors
 Kinman Lam is a Solution Architect at AWS. He is accountable for the health and growth of some of the largest ISV/DNB companies in Western Canada. He is also a member of the AWS Canada Generative AI vTeam and has helped a growing number of Canadian companies successful launch advanced Generative AI use-cases.
Kinman Lam is a Solution Architect at AWS. He is accountable for the health and growth of some of the largest ISV/DNB companies in Western Canada. He is also a member of the AWS Canada Generative AI vTeam and has helped a growing number of Canadian companies successful launch advanced Generative AI use-cases.
 Ike Bennion is the Vice President of Platform & Platform Marketing at Visier and a recognized thought leader in the intersection between people, work and technology. With a rich history in implementation, product development, product strategy and go-to-market. He specializes in market intelligence, business strategy, and innovative technologies, including AI and blockchain. Ike is passionate about using data to drive equitable and intelligent decision-making. Outside of work, he enjoys dogs, hip hop, and weightlifting.
Ike Bennion is the Vice President of Platform & Platform Marketing at Visier and a recognized thought leader in the intersection between people, work and technology. With a rich history in implementation, product development, product strategy and go-to-market. He specializes in market intelligence, business strategy, and innovative technologies, including AI and blockchain. Ike is passionate about using data to drive equitable and intelligent decision-making. Outside of work, he enjoys dogs, hip hop, and weightlifting.
Leave a Reply