
Simplify automotive damage processing with Amazon Bedrock and vector databases
In the automotive industry, the ability to efficiently assess and address vehicle damage is crucial for efficient operations, customer satisfaction, and cost management. However, manual inspection and damage detection can be a time-consuming and error-prone process, especially when dealing with large volumes of vehicle data, the complexity of assessing vehicle damage, and the potential for human error in the assessment.
This post explores a solution that uses the power of AWS generative AI capabilities like Amazon Bedrock and OpenSearch vector search to perform damage appraisals for insurers, repair shops, and fleet managers.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon OpenSearch Service is a powerful, highly flexible search engine that allows you to retrieve data based on a variety of lexical and semantic retrieval approaches.
By combining these powerful tools, we have developed a comprehensive solution that streamlines the process of identifying and categorizing automotive damage. This approach not only enhances efficiency, but also provides valuable insights that can help automotive businesses make more informed decisions.
The traditional way to solve these problems is to use computer vision machine learning (ML) models to classify the damage and its severity and complement with regression models that predict numerical outcomes based on input features like the make and model of the car, damage severity, damaged part, and more.
This approach creates challenges to maintain multiple models for classifying damage severity and creating estimates. Although these models can provide precise estimates based on historical data, they can’t be generalized to provide a quick range of estimates and any changes to the damage dataset (which includes updated makes and models) or varying repair estimates based on parts, labor, and facility. Any generalization to provide such estimates using traditional models will lead to feature engineering complexity.
This is where large language models (LLMs) come into play to look at the features both visually and based on text descriptions and find the closest match semantically.
Solution overview
Automotive companies have large datasets that include damages that have happened to their vehicle assets, which include images of the vehicles, the damage, and detailed information about that damage. This metadata includes details such as make, model, year, area of the damage, severity of the damage, parts replacement cost, and labor required to repair.
The information contained in these datasets—the images and the corresponding metadata—is converted to numerical vectors using a process called multimodal embedding. These embedding vectors contain the necessary information of the image and the text metadata encoded in numerical representation. We query against these embedding vectors to find the closest match to the incoming damaged vehicle image. This technique is called semantic search. In this solution, we use OpenSearch Service, a powerful, highly flexible search engine that allows you to retrieve data based on a variety of lexical and semantic retrieval approaches, including vector search. We generate the embeddings using the Amazon Titan Multimodal Embeddings model, available on Amazon Bedrock.
This solution is available in our GitHub repo, including detailed instructions about its deployment and testing.
The following architecture diagram illustrates the proposed solution. It contains two flows:
- Data ingestion – The data ingestion flow converts the damage datasets (images and metadata) into vector embeddings and stores them in the OpenSearch vector store. We need to initially invoke this flow to load all the historic data into OpenSearch. We can also schedule it to load the updated dataset on a regular basis, or invoke it in near real time whenever new data flows in.
- Damage assessment inference – The inference processing flow runs every time there is a new damage image to find the closest match from the current dataset stored in OpenSearch.
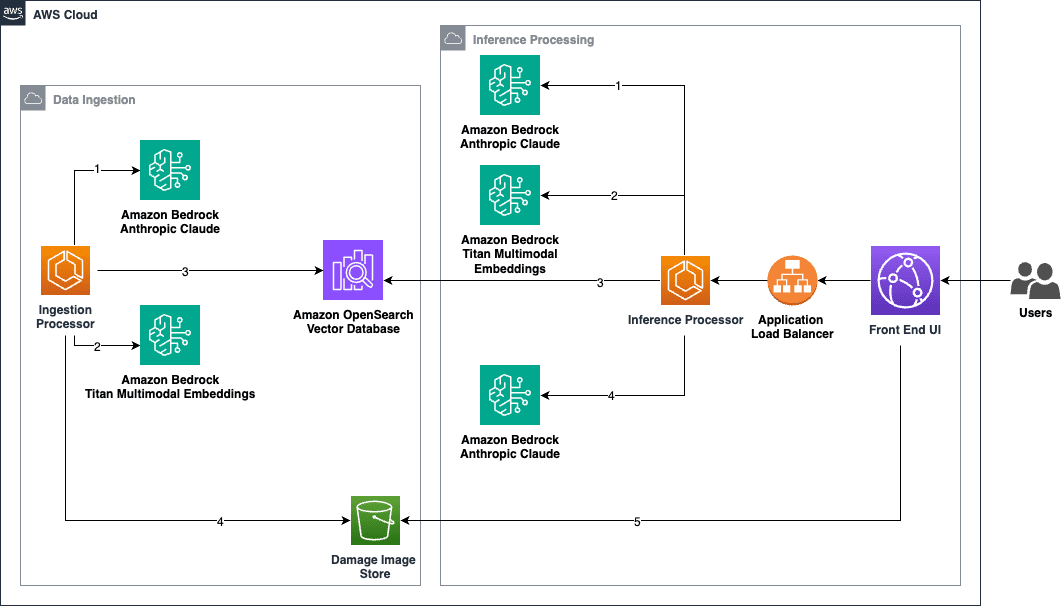
The data ingestion flow consists of the following steps:
- The ingestion process starts with the ingestion processor taking each damaged image from the existing damage repair cost dataset and passing it to Anthropic’s Claude 3 on Amazon Bedrock. The invoice details of the repair costs could be in various formats, like PDF, images, tables, and so on. These images are passed to Anthropic’s Claude 3 Haiku to be analyzed and output into a standardized JSON format. The step of creating the metadata during the ingestion process is optional if the repair invoices are already present in a standardized format.
In this solution, Anthropic’s Claude 3 creates the JSON metadata for each image. The dataset provided in this example only contains images. In a production scenario, the metadata would ideally contain relevant data from existing invoices, where Amazon Bedrock could be used to extract the relevant information and create the standardized metadata, if it doesn’t exist yet.
The following is an example image.

The following code shows an example of the ingested metadata:
- The JSON output from the previous step along with the actual damage image are sent to the Amazon Titan Multimodal Embeddings model to generate embedding vectors. Each vector is of 1,024 dimensions, and it encodes both the image and the repair cost JSON data.
- The outputs generated in the previous steps (the text representation and vector embeddings of the damage data) are stored in an Amazon OpenSearch Serverless vector search collection. By storing both the text representation and vector embeddings, you can use the power of hybrid search (text search and semantic search) to optimize the search results.
- Finally, the ingestion processor stores the raw images in Amazon Simple Storage Service (Amazon S3), which we use later in the inference flow to show the closest matches to the user.
The user performing the damage assessment interacts with the UI by providing the image of the damaged vehicle and some basic information needed for the assessment. The inference processing flow includes the following steps:
Inference Flow Steps:
- The inference processor takes each damaged image provided by the user and passes it to Anthropic’s Claude 3 to be analyzed and output into a standardized JSON format.
- The JSON output from the previous step along with the damage image are sent to the Amazon Titan Multimodal Embeddings model to generate embedding vectors.
- The embeddings are queried against all the embeddings of the existing damage data inside the OpenSearch Serverless collection to find the closest matches. For the top k (k=3 in our sample application) closest matches, it returns the JSON data that contains the repair costs and other damage expenses. With that information, several stats like median expenses and repair costs upper and lower bounds are calculated.
- In our scenario, the solution takes the metadata from each of the matches and sends that metadata to Anthropic’s Claude 3 Haiku hosted on Amazon Bedrock. The prompt is engineered to get the LLM to consider the total repair cost of each match and calculate an average. Production implementations of this solution could have variations of how this final step is done. Calculation of the repair costs could be done on different ways, in this case using generative AI, or by retrieving further information from other datasets, such as current parts and labor costs, to calculate a new repair cost average.
- The UI displays the repair expenses estimates along with the accuracy. The front end also pulls the images from Amazon S3 that are closest in match to the queried image.
Prompts and datasets
Our solution consists of automotive damage images, which are provided as part of our repository, and the code provided handles the ingestion of images and the UI that users can interact with. Our sample dataset contains images from different vehicles (for this post, we use three fictitious car brands and models). We use the following prompt to create the JSON metadata that is ingested with the image:
This prompt instructs the model to create the metadata as JSON output, and an example of that JSON metadata is provided within the
For each fictitious vehicle make and model, we have a dataset with 200 images. These images are stored within the /containers/ingestion/data_set path of the repository.
During the inference flow, the first steps that are run by the UI are capturing the image from the user and creating new metadata based on this new image and some basic information that the user provides. The following prompt is part of the inference code, which is used to create the initial metadata:
These prompts are examples provided with the solution to create basic metadata, which is then used to increase the accuracy of the vector search. There might be different use cases where more detailed prompts are required, and for that, this solution can serve as a base.
Prerequisites
To deploy the proposed sample solution, some prerequisites are needed:
- Model access in Amazon Bedrock. For instructions to request model access, see Access Amazon Bedrock foundation models. Enable the following models at a minimum:
- Amazon Titan Multimodal Embeddings
- Anthropic’s Claude 3 Haiku
- An AWS Identity and Access Management (IAM) user or role that can run AWS CloudFormation templates and has access to create resources for the following:
- Application Load Balancers
- Amazon CloudFront
- Amazon Elastic Container Service (Amazon ECS)
- Amazon Elastic Container Registry (Amazon ECR)
- IAM
- OpenSearch Serverless
- Amazon S3
- AWS Systems Manager
Deploy the solution
Complete the following steps to deploy this solution:
- Run the provided CloudFormation template.
- Download the dataset from the public dataset repository. Specific instructions can be found on the AWS Samples repository.
- Upload the dataset to the S3 source bucket. Specific instructions can be found on the AWS Samples repository.
- Run the ECS task, which runs the image ingestion process following the steps mentioned on the GitHub repo.
- To access the inference code, open the AWS CloudFormation console, navigate to the stack’s Outputs tab, and choose the CloudFront distribution link for the
InferenceUIURLkey to go to the inference UI.

- Test the solution by following the testing procedures in our GitHub repo.
Clean up
To clean up the resources you created, complete the following steps:
- On the AWS CloudFormation console, navigate to the Outputs tab of the stack you deployed.
- Note the name of your ECR repository and S3 bucket.
- On the Amazon S3 console, delete the contents of the bucket.
- On the Amazon ECR console, delete the images in the repository.
- On the AWS CloudFormation console, delete the stack.
Deleting the stack removes all other related resources from your AWS account. The bucket and repository must be empty in order to delete them.
Conclusion
The integration of Amazon Bedrock and vector databases like OpenSearch presents a powerful solution for simplifying automotive damage processing. This innovative approach offers several key benefits:
- Efficiency – By using generative AI and semantic search capabilities, the system can quickly process and analyze damage reports, significantly reducing the time required for assessments
- Accuracy – The use of multimodal embeddings and vector search makes sure damage assessments are based on comprehensive data, including both visual and textual information, leading to more accurate results
- Scalability – As the dataset grows, the system’s performance improves, allowing it to handle increasing volumes of data without compromising speed or accuracy
- Adaptability – The system can be updated with new data, so it remains current with the latest repair costs and damage types without the need to fully train using a traditional ML model
As the automotive industry continues to evolve, solutions like this will play a crucial role in streamlining operations, improving customer satisfaction, and optimizing resource allocation. By embracing AI-driven technologies, automotive businesses can stay ahead of the curve and deliver more efficient, accurate, and cost-effective damage assessment services. The combination of powerful AI models available in Amazon Bedrock and vector search capabilities of OpenSearch Service demonstrates the potential for transformative solutions in the automotive industry. As these technologies continue to advance, we can expect even more innovative applications that will reshape how we approach vehicle damage assessment and repair.
For detailed instructions and deployment steps, refer to our GitHub repo. Let us know in the comments section your thoughts about this solution and potential improvements we can add.
About the Authors
 Vinicius Pedroni is a Senior Solutions Architect at AWS for the Travel and Hospitality Industry, with focus on Edge Services and Generative AI. Vinicius is also passionate about assisting customers on their Cloud Journey, allowing them to adopt the right strategies at the right moment.
Vinicius Pedroni is a Senior Solutions Architect at AWS for the Travel and Hospitality Industry, with focus on Edge Services and Generative AI. Vinicius is also passionate about assisting customers on their Cloud Journey, allowing them to adopt the right strategies at the right moment.
 Manikanth Pasumarti is a Solutions Architect based out of New York City. He works with enterprise customers to architect and design solutions for their business needs. He is passionate about math and loves to teach kids in his free time.
Manikanth Pasumarti is a Solutions Architect based out of New York City. He works with enterprise customers to architect and design solutions for their business needs. He is passionate about math and loves to teach kids in his free time.
Leave a Reply