
Easily deploy and manage hundreds of LoRA adapters with SageMaker efficient multi-adapter inference
The new efficient multi-adapter inference feature of Amazon SageMaker unlocks exciting possibilities for customers using fine-tuned models. This capability integrates with SageMaker inference components to allow you to deploy and manage hundreds of fine-tuned Low-Rank Adaptation (LoRA) adapters through SageMaker APIs. Multi-adapter inference handles the registration of fine-tuned adapters with a base model and dynamically loads them from GPU memory, CPU memory, or local disk in milliseconds, based on the request. This feature provides atomic operations for adding, deleting, or updating individual adapters across a SageMaker endpoint’s running instances without affecting performance or requiring a redeployment of the endpoint.
The efficiency of LoRA adapters allows for a wide range of hyper-personalization and task-based customization which had previously been too resource-intensive and costly to be feasible. For example, marketing and software as a service (SaaS) companies can personalize artificial intelligence and machine learning (AI/ML) applications using each of their customer’s images, art style, communication style, and documents to create campaigns and artifacts that represent them. Similarly, enterprises in industries like healthcare or financial services can reuse a common base model with task-based adapters to efficiently tackle a variety of specialized AI tasks. Whether it’s diagnosing medical conditions, assessing loan applications, understanding complex documents, or detecting financial fraud, you can simply swap in the appropriate fine-tuned LoRA adapter for each use case at runtime. This flexibility and efficiency unlocks new opportunities to deploy powerful, customized AI across your organization. With this new efficient multi-adapter inference capability, SageMaker reduces the complexity of deploying and managing the adapters that power these applications.
In this post, we show how to use the new efficient multi-adapter inference feature in SageMaker.
Problem statement
You can use powerful pre-trained foundation models (FMs) without needing to build your own complex models from scratch. However, these general-purpose models might not always align with your specific needs or your unique data. To make these models work for you, you can use Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA.
The benefit of PEFT and LoRA is that it lets you fine-tune models quickly and cost-effectively. These methods are based on the idea that only a small part of a large FM needs updating to adapt it to new tasks or domains. By freezing the base model and just updating a few extra adapter layers, you can fine-tune models much faster and cheaper, while still maintaining high performance. This flexibility means you can quickly customize pre-trained models at low cost to meet different requirements. When inferencing, the LoRA adapters can be loaded dynamically at runtime to augment the results from the base model for best performance. You can create a library of task-specific, customer-specific, or domain-specific adapters that can be swapped in as needed for maximum efficiency. This allows you to build AI tailored exactly to your business.
Although fine-tuned LoRA adapters can effectively address targeted use cases, managing these adapters can be challenging at scale. You can use open-source libraries, or the AWS managed Large Model Inference (LMI) deep learning container (DLC) to dynamically load and unload adapter weights. Current deployment methods use fixed adapters or Amazon Simple Storage Service (Amazon S3) locations, making post-deployment changes impossible without updating the model endpoint and adding unnecessary complexity. This deployment method also makes it impossible to collect per-adapter metrics, making the evaluation of their health and performance a challenge.
Solution overview
In this solution, we show how to use efficient multi-adapter inference in SageMaker to host and manage multiple LoRA adapters with a common base model. The approach is based on an existing SageMaker capability, inference components, where you can have multiple containers or models on the same endpoint and allocate a certain amount of compute to each container. With inference components, you can create and scale multiple copies of the model, each of which retains the compute that you have allocated. With inference components, deploying multiple models that have specific hardware requirements becomes a much simpler process, allowing for the scaling and hosting of multiple FMs. An example deployment would look like the following figure.
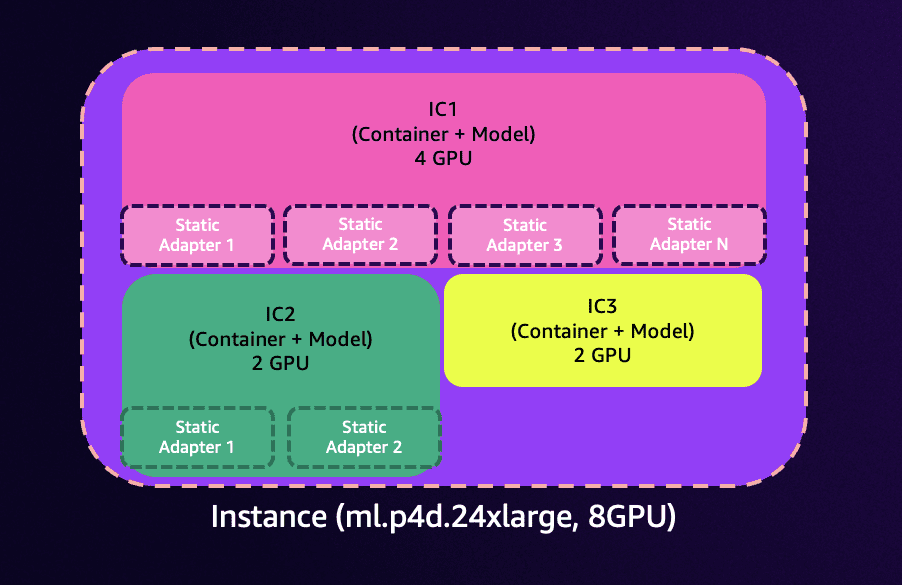
This feature extends inference components to a new type of component, inference component adapters, which you can use to allow SageMaker to manage your individual LoRA adapters at scale while having a common inference component for the base model that you’re deploying. In this post, we show how to create, update, and delete inference component adapters and how to call them for inference. You can envision this architecture as the following figure.

Prerequisites
To run the example notebooks, you need an AWS account with an AWS Identity and Access Management (IAM) role with permissions to manage resources created. For details, refer to Create an AWS account.
If this is your first time working with Amazon SageMaker Studio, you first need to create a SageMaker domain. Additionally, you may need to request a service quota increase for the corresponding SageMaker hosting instances. In this example, you host the base model and multiple adapters on the same SageMaker endpoint, so you will use an ml.g5.12xlarge SageMaker hosting instance.
In this example, you learn how to deploy a base model (Meta Llama 3.1 8B Instruct) and LoRA adapters on an SageMaker real-time endpoint using inference components. You can find the example notebook in the GitHub repository.
Download the base model from the Hugging Face model hub. Because Meta Llama 3.1 8B Instruct is a gated model, you will need a Hugging Face access token and to submit a request for model access on the model page. For more details, see Accessing Private/Gated Models.
Copy your model artifact to Amazon S3 to improve model load time during deployment:
!aws s3 cp —recursive {local_model_path} {s3_model_path}
Select one of the available LMI container images for hosting. Efficient adapter inference capability is available in 0.31.0-lmi13.0.0 and higher.
inference_image_uri = "763104351884.dkr.ecr.us-west-2.amazonaws.com/djl-inference:0.31.0-lmi13.0.0-cu124"
Create a container environment for the hosting container. LMI container parameters can be found in the LMI Backend User Guides.
The parameters OPTION_MAX_LORAS and OPTION_MAX_CPU_LORAS control how adapters move between GPU, CPU, and disk. OPTION_MAX_LORAS sets a limit on the number of adapters concurrently stored in GPU memory, with excess adapters offloaded to CPU memory. OPTION_MAX_CPU_LORAS determines how many adapters are staged in CPU memory, offloading excess adapters to local SSD storage.
In the following example, 30 adapters can live in GPU memory and 70 adapters in CPU memory before going to local storage.
With your container image and environment defined, you can create a SageMaker model object that you will use to create an inference component later:
Set up a SageMaker endpoint
To create a SageMaker endpoint, you need an endpoint configuration. When using inference components, you don’t specify a model in the endpoint configuration. You load the model as a component later on.
Create the SageMaker endpoint with the following code:
With your endpoint created, you can now create the inference component for the base model. This will be the base component that the adapter components you create later will depend on.
Notable parameters here are ComputeResourceRequirements. These are a component-level configuration that determine the amount of resources that the component needs (memory, vCPUs, accelerators). The adapters will share these resources with the base component.
In this example, you create a single adapter, but you could host up to hundreds of them per endpoint. They will need to be compressed and uploaded to Amazon S3.
The adapter package has the following files at the root of the archive with no sub-folders.

For this example, an adapter was fine-tuned using QLoRA and Fully Sharded Data Parallel (FSDP) on the training split of the ECTSum dataset. Training took 21 minutes on an ml.p4d.24xlarge and cost approximately $13 using current on-demand pricing.
For each adapter you are going to deploy, you need to specify an InferenceComponentName, an ArtifactUrl with the S3 location of the adapter archive, and a BaseInferenceComponentName to create the connection between the base model inference component and the new adapter inference components. You repeat this process for each additional adapter.
Use the deployed adapter
First, you build a prompt to invoke the model for earnings summarization, filling in the source text with a random item from the ECTSum dataset. Then you store the ground truth summary from the item for comparison later.
To test the base model, specify the EndpointName for the endpoint you created earlier and the name of the base inference component as InferenceComponentName, along with your prompt and other inference parameters in the Body parameter:
To invoke the adapter, use the adapter inference component name in your invoke_endpoint call:
Compare outputs
Compare the outputs of the base model and adapter to ground truth. While the base model might appear subjectively better in this test, the adapter’s response is actually much closer to the ground truth response. This will be proven with metrics in the next section.
To validate the true adapter performance, you can use a tool like fmeval to run an evaluation of summarization accuracy. This will calculate the METEOR, ROUGE, and BertScore metrics for the adapter vs. the base model. Doing so against the test split of ECTSum yields the following results.

The fine-tuned adapter shows a 59% increase in METEOR score, 159% increase in ROUGE score, and 8.6% increase in BertScore.
The following diagram shows the frequency distribution of scores for the different metrics, with the adapter consistently scoring better more often in all metrics.

We observed an end-to-end latency difference of up to 10% between base model invocation and the adapter in our tests. If the adapter is loaded from CPU memory or disk, it will incur an additional cold start delay for the first load to GPU. But depending on your container configurations and instance type chosen, these values may vary.
Update an existing adapter
Because adapters are managed as inference components, you can update them on a running endpoint. SageMaker handles the unloading and deregistering of the old adapter and loading and registering of the new adapter onto every base inference component on all the instances that it is running on for this endpoint. To update an adapter inference component, use the update_inference_component API and supply the existing inference component name and the Amazon S3 path to the new compressed adapter archive.
You can train a new adapter, or re-upload the existing adapter artifact to test this functionality.
Remove adapters
If you need to delete an adapter, call the delete_inference_component API with the inference component name to remove it:
Deleting the base model inference component will automatically delete the base inference component and any associated adapter inference components:
Pricing
SageMaker multi-adapter inference is generally available in AWS Regions US East (N. Virginia, Ohio), US West (Oregon), Asia Pacific (Jakarta, Mumbai, Seoul, Singapore, Sydney, Tokyo), Canada (Central), Europe (Frankfurt, Ireland, London, Stockholm), Middle East (UAE), and South America (São Paulo), and is available at no extra cost.
Conclusion
The new efficient multi-adapter inference feature in SageMaker opens up exciting possibilities for customers with fine-tuning use cases. By allowing the dynamic loading of fine-tuned LoRA adapters, you can quickly and cost-effectively customize AI models to your specific needs. This flexibility unlocks new opportunities to deploy powerful, customized AI across organizations in industries like marketing, healthcare, and finance. The ability to manage these adapters at scale through SageMaker inference components makes it effortless to build tailored generative AI solutions.
About the Authors
 Dmitry Soldatkin is a Senior Machine Learning Solutions Architect at AWS, helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. He has a passion for continuous innovation and using data to drive business outcomes. Prior to joining AWS, Dmitry was an architect, developer, and technology leader in data analytics and machine learning fields in the financial services industry.
Dmitry Soldatkin is a Senior Machine Learning Solutions Architect at AWS, helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. He has a passion for continuous innovation and using data to drive business outcomes. Prior to joining AWS, Dmitry was an architect, developer, and technology leader in data analytics and machine learning fields in the financial services industry.
 Giuseppe Zappia is a Principal AI/ML Specialist Solutions Architect at AWS, focused on helping large enterprises design and deploy ML solutions on AWS. He has over 20 years of experience as a full stack software engineer, and has spent the past 5 years at AWS focused on the field of machine learning.
Giuseppe Zappia is a Principal AI/ML Specialist Solutions Architect at AWS, focused on helping large enterprises design and deploy ML solutions on AWS. He has over 20 years of experience as a full stack software engineer, and has spent the past 5 years at AWS focused on the field of machine learning.
 Ram Vegiraju is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Leave a Reply