
Introducing Fast Model Loader in SageMaker Inference: Accelerate autoscaling for your Large Language Models (LLMs) – part 1
The generative AI landscape has been rapidly evolving, with large language models (LLMs) at the forefront of this transformation. These models have grown exponentially in size and complexity, with some now containing hundreds of billions of parameters and requiring hundreds of gigabytes of memory. As LLMs continue to expand, AI engineers face increasing challenges in deploying and scaling these models efficiently for inference. One of the primary bottlenecks in the inference deployment process has been the time required to load these massive models onto accelerators. With LLMs now reaching hundreds of gigabytes in size, it has become increasingly difficult for many users to address bursty traffic patterns and scale quickly. For LLMs that often require high throughput and low-latency inference requests, this loading process can add significant overhead to the total deployment and scaling time, potentially impacting application performance during traffic spikes. SageMaker Large Model Inference (LMI) is deep learning container to help customers quickly get started with LLM deployments on SageMaker Inference.
Today at AWS re:Invent 2024, we are excited to announce a new capability in Amazon SageMaker Inference that significantly reduces the time required to deploy and scale LLMs for inference using LMI: Fast Model Loader. This innovation allows you to scale your models faster, observing up to 19% reduction in latency when scaling a new model copy on a new instance for inference. It represents a substantial leap forward in loading large models efficiently. Fast Model Loader introduces a novel approach by streaming model weights directly from Amazon Simple Storage Service (Amazon S3) to the accelerator, enabling faster model loading.
In our internal testing, we observed that Fast Model Loader can load large models up to 15 times faster compared to the traditional loading methods. This dramatic improvement in loading speed opens up new possibilities for responsive AI systems, potentially enabling faster scaling and more dynamic applications that can adapt quickly to changing demands. During our performance testing we were able to load the llama-3.1-70B model on an ml.p4d.24xlarge instance in just 1 minute. This model, with its 70 billion parameters, typically requires over 140 GB of memory in full precision, underscoring the magnitude of the loading challenge that Fast Model Loader addresses.
Fast Model Loader is designed to tackle scaling challenges, potentially leading to improved resource utilization on GPU instances and more efficient scaling during autoscaling events. This feature aims to provide you with a powerful new option for managing the deployment and scaling of your LLMs on SageMaker inference, whether you’re dealing with bursty traffic patterns or need to rapidly scale your LLM-based services.
This post is Part 1 of a series exploring Fast Model Loader. In this post, we delve into the technical details of Fast Model Loader, explore its integration with existing SageMaker workflows, discuss how you can get started with this powerful new feature, and share customer success stories. In Part 2, we provide a detailed, hands-on guide to implementing Fast Model Loader in your LLM deployments.
Challenges in deploying LLMs for inference
As LLMs and their respective hosting containers continue to grow in size and complexity, AI and ML engineers face increasing challenges in deploying and scaling these models efficiently for inference. The rapid evolution of LLMs, with some models now using hundreds of billions of parameters, has led to a significant increase in the computational resources and sophisticated infrastructure required to run them effectively.
One of the primary bottlenecks in the deployment process is the time required to download and load containers when scaling up endpoints or launching new instances. This challenge is particularly acute in dynamic environments where rapid scaling is crucial to maintain service quality. The sheer size of these containers, often ranging from several gigabytes to tens of gigabytes, can lead to substantial delays in the scaling process.
When a scale-up event occurs, several actions take place, each contributing to the total time between triggering a scale-up event and serving traffic from the newly added instances. These actions typically include:
- Provisioning new compute instances
- Downloading the container image
- Loading the container image
- Downloading the model artifacts from Amazon S3 to disk
- Loading the model artifacts on the host (using CPU and memory)
- Preparing the model to be loaded on GPU (quantization, model sharding, and so on)
- Loading the final model artifacts on the GPU
The cumulative time for these steps can take up to tens of minutes, depending on the model size, runtime used by the model, and infrastructure capabilities. This delay can lead to suboptimal user experiences and potential service degradation during scaling activities, making it a critical area for optimization in the field of AI inference infrastructure.
To reduce the time it takes to download and load the container image, SageMaker now supports container caching. To learn more about this new feature, refer to Supercharge your auto scaling for generative AI inference- Introducing Container Caching in SageMaker Inference
For model loading, a typical deployment follows the steps described in this section, which can lead non-ideal deployment latency. This can lead to requests sitting in the queue waiting to be processed while the deployment concludes, or can result in dropped requests when timeouts are exceeded, as shown in the following diagrams.
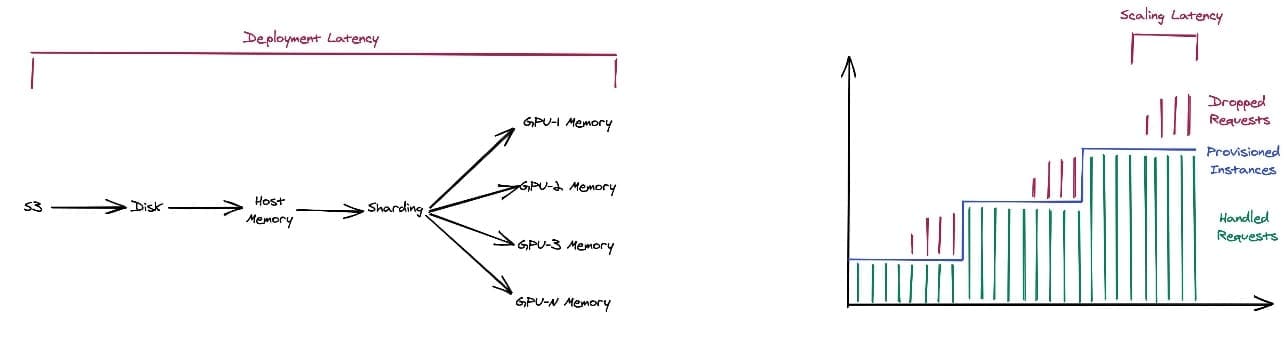
You can take a step to optimize deployment with ahead of time (AoT) compilation of your model. This requires you to create or use existing pre-sharded models to avoid the step needed to process the model during runtime deployment. By taking on the cost of pre-creating these artifacts and referencing them as persisted objects, you can take that latency ahead of time. This can significantly reduce the time it takes to scale up a model especially if it’s larger in size.
The benefits of this approach are particularly noticeable for larger models:
- Reduced scaling time – Pre-sharded models can be loaded more quickly, decreasing the time required to bring new instances online during scaling events
- Improved resource utilization – By offloading the compilation and sharding process, more computational resources are available for inference tasks during runtime
- Consistency – Pre-compiled artifacts provide consistent performance across deployments
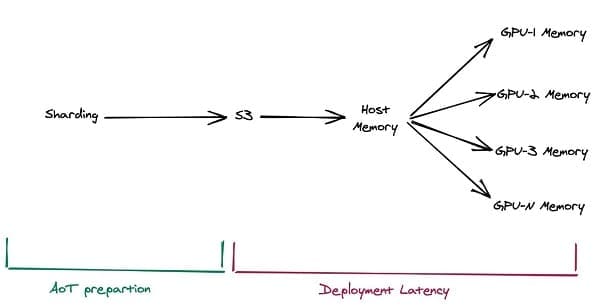
Although there is an upfront cost in creating these artifacts, the long-term savings in reduced scaling times and improved resource utilization can be substantial, especially for models that are frequently deployed or require rapid scaling. This approach can significantly reduce the time it takes to scale up a model, particularly for larger models, leading to more responsive and efficient AI systems. The following figures illustrate the proposed way to load models.

Additionally, disk becomes a bottleneck during model loading due to its limited I/O bandwidth. Traditional storage systems struggle with the high throughput required for large-scale model loading, like Meta Llama 3.1 70B. Disk read/write speeds are often much slower than network or GPU memory bandwidths, creating delays in transferring model weights. This issue can be alleviated by streaming data directly from Amazon S3 to GPU memory, bypassing disk entirely.
We can now take a significant step forward and also address the steps it takes using host resources and the sequential steps it takes between downloading the model artifacts to loading it onto the GPU using Fast Model Loader.
Weight streaming
Fast Model Loader streams weights directly from Amazon S3 to GPUs. This is accomplished by cutting out the intermediary steps—the bytes representing model weights are downloaded to the CPU memory and immediately copied over to the GPU using Direct Memory Access (DMA). This simplifies the model loading workflow and makes it straightforward to maximize the model loading throughput. It presents the following key advantages:
- No waiting – In the traditional approach, each step in the loading process (download, load to host’s CPU, GPU copy) needs to complete for a tensor or a layer before the next step could begin. This creates synchronous bottlenecks, where components are idle while waiting for the previous step to finish. Fast Model Loader’s direct streaming approach eliminates these synchronous blocking operations, allowing all components to operate at their maximum potential concurrently.
- No accumulation – Instead of downloading the entire model to disk or CPU memory before processing, Fast Model Loader streams the model weights in small chunks directly to the GPU. This avoids the need to accumulate the full model in system storage or memory, reducing the overall resource requirements and footprint.
- Maximum throughput – By simplifying the model loading workflow and eliminating intermediate steps, Fast Model Loader can more effectively take advantage of the high-throughput capabilities of Amazon S3 and the generous network bandwidth available on the large instances typically used for hosting LLMs. This allows the model loading process to achieve maximum throughput and minimize latency.
The following figure compares model load times for sequential vs. parallel processes.

Model sharding for streaming
The weight streaming paradigm described in the previous section requires that the model weights be prepared appropriately prior to streaming. In order to stream the model weights a few bytes at a time, we need to store the model in a format consistent with our expectation.
The traditional approach to storing and distributing LLM weights often relies on the SafeTensors format. Although SafeTensors provides a standardized way to package and distribute model weights, it presents some challenges when it comes to the weight streaming paradigm used by Fast Model Loader. In the SafeTensors format, the fundamental unit of storage is the tensor. Tensors are multi-dimensional arrays that represent the various weights and parameters of a machine learning model. However, the size of these tensors can vary significantly, ranging from a few megabytes to several gigabytes, depending on the complexity and scale of the model. This non-uniform distribution of tensor sizes poses a problem for Fast Model Loader’s weight streaming approach. The variable tensor sizes in the SafeTensors format make it difficult to achieve consistent throughput. Larger tensors require more time and resources to load, whereas smaller tensors are underutilized, leading to inefficiencies in the overall loading process.
The following figure illustrates loading SafeTensors weights of various sizes.

Fast Model Loader introduces a new model format with the following key advantages:
- Pre-sharding – The explosion in model sizes has seen them outgrow GPUs. The largest models available today are over 1 TB large, whereas the largest GPUs fall short of 200 GB. This has led to us embracing distributed inference strategies like tensor parallelism. It involves splitting a model into portions (shards) and distributing them to multiple GPUs. However, this involves quite a few computations in deciding how to split the model at every layer and calculating offsets based on tensor size and available GPU memory. Fast Model Loader performs this optimization pre-deployment, which avoids the overhead during scaling activities. The preparation only happens one time, and the model can be deployed to any number of instances with the same distributed inference strategy. The following figure provides an overview of pre-sharding.

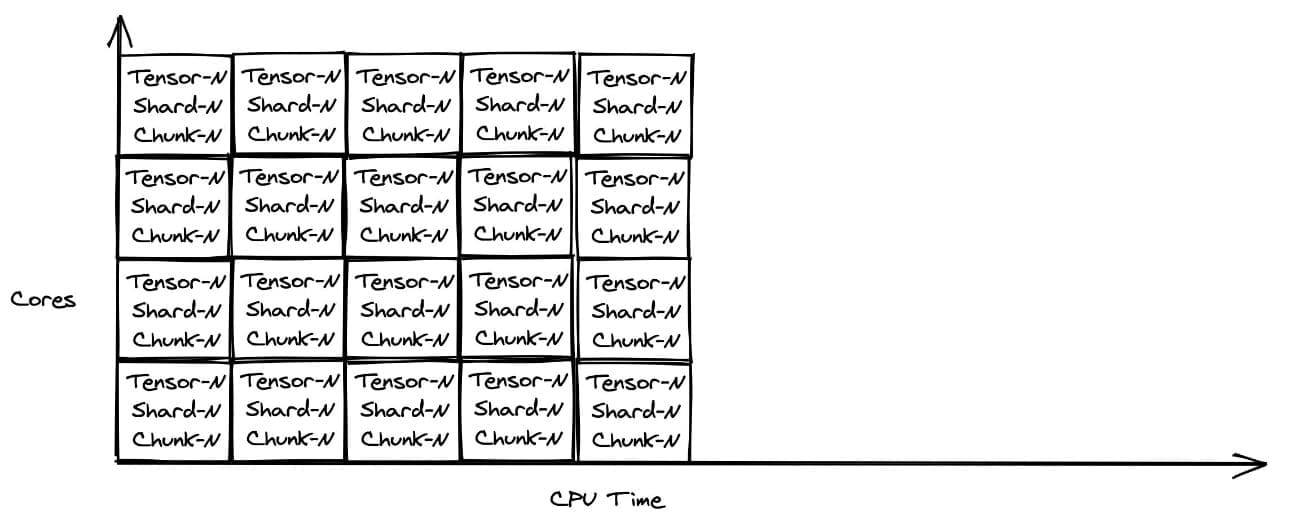
- Uniform size distribution – The model weights are stored in uniform 8 MB chunks, which are less complicated to parallelize for concurrent processing. The following figure illustrates uniform chunks being parallelized across cores.
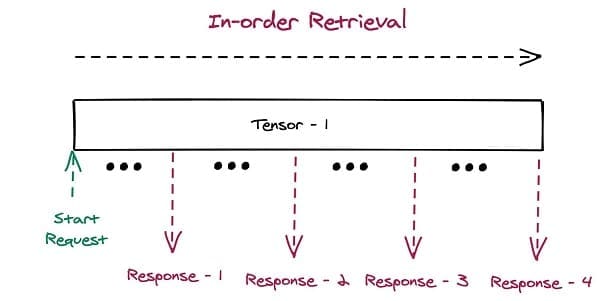
- Out of order processing – Objects in Amazon S3 typically have to be downloaded in-order. To read the middle of the object, Amazon S3 starts by reading objects from the start, until it gets to the middle. This requires model weights to be downloaded synchronously, which runs contrary to our fast model loading paradigm. Storing model weights in uniform chunks of 8 MB each allows you to access any piece of the model at any time without synchronization. The following figures illustrate how breaking tensors into chunks allows for asynchronous, out of order retrieval.
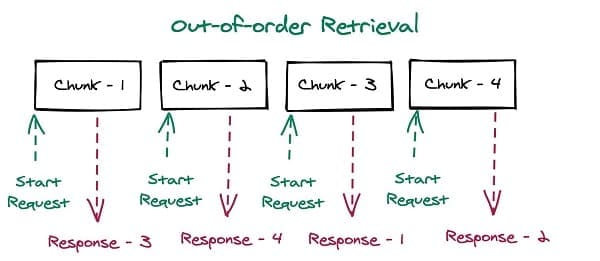
Performance Testing:
The implementation of the Fast Model Loader demonstrates significant in End-to-End (E2E) scaling time for large language models. Across five simulations that were performed with Llama3.1 70B, we observed remarkably consistent results, reinforcing the reliability of our findings. For this feature we use container wherein caching was enabled here. When using CUDA Graphs, the average scaling time was reduced from 407 seconds (6.78 minutes) to 334.6 seconds (5.58 minutes), marking a substantial 21.64% improvement. Similarly, without CUDA Graphs, the average scaling time decreased from 379 seconds (6.32 minutes) to 306 seconds (5.10 minutes), resulting in a 19.26% reduction. By cutting scaling times by approximately one-fifth in all observed cases, this feature enables more responsive scaling and better handling of dynamic workloads, ultimately leading to improved performance and resource utilization in AI inference.
To run this benchmark, we use sub-minute metrics to detect the need for scaling. For more details, see Amazon SageMaker inference launches faster auto scaling for generative AI models and Container Caching.
The following table summarizes our setup.
| Region | CMH |
| Instance Type | p4d.24xlarge |
| Container | LMI |
| Container Image | 763104351884.dkr.ecr.us-east-2.amazonaws.com/djl-inference:0.31.0-lmi13.0.0-cu124 |
| Model | Meta Llama3.1 70B |
For this scenario, we illustrate scaling the model by adding a new instance.
The following table summarizes the results when the models are not sharded.
** All numbers presented here are in seconds.
| Meta Llama 3.1 70B | ||||||
|---|---|---|---|---|---|---|
| Trial | Time to Detect Need for Scaling | Time to Spin Up an Instance | Time to Instantiate a New Model Copy | CUDA Graphs Capture Overhead | E2E Scaling Latency | |
| . | . | . | . | . | With CUDA Graphs | Without CUDA Graphs |
| 1 | 40 | 185 | 173 | 28 | 398 | 370 |
| 2 | 40 | 175 | 188 | 29 | 403 | 374 |
| 3 | 40 | 164 | 208 | 29 | 412 | 383 |
| 4 | 40 | 185 | 187 | 30 | 412 | 382 |
| 5 | 40 | 185 | 187 | 28 | 412 | 384 |
| Average | . | 179 | 189 | 29 | 407 | 379 |
The following table summarizes the results after the models are sharded.
** All numbers presented here are in seconds.
| Meta Llama 3.1 70B | ||||||
|---|---|---|---|---|---|---|
| Trial | Time to Detect Need for Scaling | Time to Spin Up an Instance | Time to Instantiate a New Model Copy | CUDA Graphs Capture Overhead | E2E Scaling Latency | |
| . | . | . | . | . | With CUDA Graphs | Without CUDA Graphs |
| 1 | 40 | 185 | 119 | 28 | 344 | 316 |
| 2 | 40 | 175 | 119 | 30 | 334 | 304 |
| 3 | 40 | 169 | 119 | 28 | 328 | 300 |
| 4 | 40 | 169 | 120 | 28 | 329 | 301 |
| 5 | 40 | 179 | 119 | 29 | 338 | 309 |
| Average | . | 175.4 | 119.2 | 28.6 | 334.6 | 306 |
The following diagram summarizes the impact on E2E scaling time.
** All numbers presented here are in seconds.
| .. | Before | After | % Improvements |
|---|---|---|---|
| Scaling with CUDA Graphs | 407 | 334.6 | 21.64% |
| Scaling without CUDA Graphs | 379 | 306 | 19.26% |
Note: For customers using ODCRs for GPUs may experience lower time to spin up new instances as compared to on demand depending on instance type.
Impact on Read-to-Serve Time:
The benchmarks below show that the SageMaker Fast Model Loader can load large models significantly faster compared to traditional counterparts. For the LLaMa 3.1 70B model on the ml.p4d.24xlarge instance, we compared the download and load times against 2 traditional methods – downloading the model from HuggingFace Hub using transformers and downloading the model from S3 using vLLM’s default downloader. In both cases we used vLLM’s default loader to load the model after the download.
** All numbers presented here are in seconds.
| . | Download | Load | % Improvement with Fast Model Loader | Speedup with Fast Model Loader |
|---|---|---|---|---|
| Transformers Downloader + vLLM Model Loader | 602 | 138 | 93.24% | 15x |
| vLLM Downloader + vLLM Model Loader | 127 | 138 | 81.13% | 5x |
| Fast Model Loader | 50 | . | . | |
The load time here indicates the time taken to get the model fully ready to serve, including time taken to initialize the KV cache.
How to get started
You can start using Fast Model Loader now through the Amazon SageMaker Studio console using Amazon SageMaker JumpStart or programmatically using the SageMaker Python SDK.
From the SageMaker Studio JumpStart hub, you can pick a model and choose Optimize to run the inference optimization job and then deploy the optimized model to a SageMaker endpoint. For more detailed instructions, refer to the Part 2 of this post.
Though SageMaker Studio provides a user-friendly interface for model optimization through SageMaker JumpStart, you can also achieve the same functionality programmatically using the SageMaker Python SDK. The ModelBuilder class offers a streamlined way to optimize and deploy large models, requiring just a few lines of code to prepare your model for fast loading and inference. The following code snippet shows the core implementation to use ModelBuilder to prepare and optimize the model for Fast Model Loader. You can find an end-to-end example notebook in the following GitHub repo.
Customer testimonials
The introduction of Fast Model Loader in SageMaker has generated significant excitement among our customers, particularly those working with LLMs. We’ve collected early feedback from customers that have had the opportunity to preview this new capability. Their responses underscore the potential of Fast Model Loader to transform the deployment and scaling of AI models, especially in scenarios requiring rapid response to changing demands.
Atomicwork is a modern ITSM and ESM solution that revolutionizes internal support for organizations through AI-powered chat interfaces, replacing traditional ticketing portals.
“Amazon SageMaker Fast Model Loader is a game changer for our AI-driven enterprise workflows. It significantly accelerates the deployment and scaling of the large language models, which are critical for providing responsive, chat-based IT support, HR processes, and customer service operations. We look forward to adopting this feature that allows us to optimize our computational resources while maintaining the agility our enterprise customers expect, helping us deliver a truly intelligent service management platform.”
– Kiran Darisi, Co-founder and CTO of Atomicwork.
Conclusion
In this post, we discussed how loading large model artifacts can be the bottleneck in loading and scaling FMs. SageMaker has launched a new feature called Fast Model Loader to address challenges in deploying and scaling FMs for inference. Fast Model Loader can load large models up to 15 times faster by streaming model weights directly from Amazon S3 to the accelerator, reducing scaling and deployment times significantly.
In Part 2 of this post, we demonstrate how you can try out this new feature through either the SageMaker Python SDK or SageMaker Studio console.
About the Authors
 Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
 Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of Generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of Generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on LinkedIn.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on LinkedIn.
 Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
 Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Anisha Kolla is a Software Development Engineer with SageMaker Inference team with over 10+ years of industry experience. She is passionate about building scalable and efficient solutions that empower customers to deploy and manage machine learning applications seamlessly. Anisha thrives on tackling complex technical challenges and contributing to innovative AI capabilities. Outside of work, she enjoys exploring fusion cuisines, traveling, and spending time with family and friends.
Anisha Kolla is a Software Development Engineer with SageMaker Inference team with over 10+ years of industry experience. She is passionate about building scalable and efficient solutions that empower customers to deploy and manage machine learning applications seamlessly. Anisha thrives on tackling complex technical challenges and contributing to innovative AI capabilities. Outside of work, she enjoys exploring fusion cuisines, traveling, and spending time with family and friends.
Leave a Reply