
Announcing the ICDAR 2023 Competition on Hierarchical Text Detection and Recognition
The last few decades have witnessed the rapid development of Optical Character Recognition (OCR) technology, which has evolved from an academic benchmark task used in early breakthroughs of deep learning research to tangible products available in consumer devices and to third party developers for daily use. These OCR products digitize and democratize the valuable information that is stored in paper or image-based sources (e.g., books, magazines, newspapers, forms, street signs, restaurant menus) so that they can be indexed, searched, translated, and further processed by state-of-the-art natural language processing techniques.
Research in scene text detection and recognition (or scene text spotting) has been the major driver of this rapid development through adapting OCR to natural images that have more complex backgrounds than document images. These research efforts, however, focus on the detection and recognition of each individual word in images, without understanding how these words compose sentences and articles.
Layout analysis is another relevant line of research that takes a document image and extracts its structure, i.e., title, paragraphs, headings, figures, tables and captions. These layout analysis efforts are parallel to OCR and have been largely developed as independent techniques that are typically evaluated only on document images. As such, the synergy between OCR and layout analysis remains largely under-explored. We believe that OCR and layout analysis are mutually complementary tasks that enable machine learning to interpret text in images and, when combined, could improve the accuracy and efficiency of both tasks.
With this in mind, we announce the Competition on Hierarchical Text Detection and Recognition (the HierText Challenge), hosted as part of the 17th annual International Conference on Document Analysis and Recognition (ICDAR 2023). The competition is hosted on the Robust Reading Competition website, and represents the first major effort to unify OCR and layout analysis. In this competition, we invite researchers from around the world to build systems that can produce hierarchical annotations of text in images using words clustered into lines and paragraphs. We hope this competition will have a significant and long-term impact on image-based text understanding with the goal to consolidate the research efforts across OCR and layout analysis, and create new signals for downstream information processing tasks.
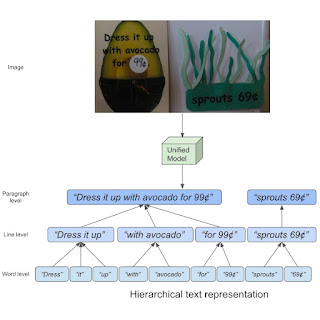
 |
| The concept of hierarchical text representation. |
Constructing a hierarchical text dataset
In this competition, we use the HierText dataset that we published at CVPR 2022 with our paper “Towards End-to-End Unified Scene Text Detection and Layout Analysis”. It’s the first real-image dataset that provides hierarchical annotations of text, containing word, line, and paragraph level annotations. Here, “words” are defined as sequences of textual characters not interrupted by spaces. “Lines” are then interpreted as “space“-separated clusters of “words” that are logically connected in one direction, and aligned in spatial proximity. Finally, “paragraphs” are composed of “lines” that share the same semantic topic and are geometrically coherent.
To build this dataset, we first annotated images from the Open Images dataset using the Google Cloud Platform (GCP) Text Detection API. We filtered through these annotated images, keeping only images rich in text content and layout structure. Then, we worked with our third-party partners to manually correct all transcriptions and to label words, lines and paragraph composition. As a result, we obtained 11,639 transcribed images, split into three subsets: (1) a train set with 8,281 images, (2) a validation set with 1,724 images, and (3) a test set with 1,634 images. As detailed in the paper, we also checked the overlap between our dataset, TextOCR, and Intel OCR (both of which also extracted annotated images from Open Images), making sure that the test images in the HierText dataset were not also included in the TextOCR or Intel OCR training and validation splits and vice versa. Below, we visualize examples using the HierText dataset and demonstrate the concept of hierarchical text by shading each text entity with different colors. We can see that HierText has a diversity of image domain, text layout, and high text density.
 |
| Samples from the HierText dataset. Left: Illustration of each word entity. Middle: Illustration of line clustering. Right: Illustration paragraph clustering. |
Dataset with highest density of text
In addition to the novel hierarchical representation, HierText represents a new domain of text images. We note that HierText is currently the most dense publicly available OCR dataset. Below we summarize the characteristics of HierText in comparison with other OCR datasets. HierText identifies 103.8 words per image on average, which is more than 3x the density of TextOCR and 25x more dense than ICDAR-2015. This high density poses unique challenges for detection and recognition, and as a consequence HierText is used as one of the primary datasets for OCR research at Google.
| Dataset | Training split | Validation split | Testing split | Words per image | ||||||||||
| ICDAR-2015 | 1,000 | 0 | 500 | 4.4 | ||||||||||
| TextOCR | 21,778 | 3,124 | 3,232 | 32.1 | ||||||||||
| Intel OCR | 19,1059 | 16,731 | 0 | 10.0 | ||||||||||
| HierText | 8,281 | 1,724 | 1,634 | 103.8 |
| Comparing several OCR datasets to the HierText dataset. |
Spatial distribution
We also find that text in the HierText dataset has a much more even spatial distribution than other OCR datasets, including TextOCR, Intel OCR, IC19 MLT, COCO-Text and IC19 LSVT. These previous datasets tend to have well-composed images, where text is placed in the middle of the images, and are thus easier to identify. On the contrary, text entities in HierText are broadly distributed across the images. It’s proof that our images are from more diverse domains. This characteristic makes HierText uniquely challenging among public OCR datasets.
 |
| Spatial distribution of text instances in different datasets. |
The HierText challenge
The HierText Challenge represents a novel task and with unique challenges for OCR models. We invite researchers to participate in this challenge and join us in ICDAR 2023 this year in San Jose, CA. We hope this competition will spark research community interest in OCR models with rich information representations that are useful for novel down-stream tasks.
Acknowledgements
The core contributors to this project are Shangbang Long, Siyang Qin, Dmitry Panteleev, Alessandro Bissacco, Yasuhisa Fujii and Michalis Raptis. Ashok Popat and Jake Walker provided valuable advice. We also thank Dimosthenis Karatzas and Sergi Robles from Autonomous University of Barcelona for helping us set up the competition website.
Leave a Reply