
Responsible AI at Google Research: PAIR

PAIR (People + AI Research) first launched in 2017 with the belief that “AI can go much further — and be more useful to all of us — if we build systems with people in mind at the start of the process.” We continue to focus on making AI more understandable, interpretable, fun, and usable by more people around the world. It’s a mission that is particularly timely given the emergence of generative AI and chatbots.
Today, PAIR is part of the Responsible AI and Human-Centered Technology team within Google Research, and our work spans this larger research space: We advance foundational research on human-AI interaction (HAI) and machine learning (ML); we publish educational materials, including the PAIR Guidebook and Explorables (such as the recent Explorable looking at how and why models sometimes make incorrect predictions confidently); and we develop software tools like the Learning Interpretability Tool to help people understand and debug ML behaviors. Our inspiration this year is “changing the way people think about what THEY can do with AI.” This vision is inspired by the rapid emergence of generative AI technologies, such as large language models (LLMs) that power chatbots like Bard, and new generative media models like Google’s Imagen, Parti, and MusicLM. In this blog post, we review recent PAIR work that is changing the way we engage with AI.
Generative AI research
Generative AI is creating a lot of excitement, and PAIR is involved in a range of related research, from using language models to create generative agents to studying how artists adopted generative image models like Imagen and Parti. These latter “text-to-image” models let a person input a text-based description of an image for the model to generate (e.g., “a gingerbread house in a forest in a cartoony style”). In a forthcoming paper titled “The Prompt Artists” (to appear in Creativity and Cognition 2023), we found that users of generative image models strive not only to create beautiful images, but also to create unique, innovative styles. To help achieve these styles, some would even seek unique vocabulary to help develop their visual style. For example, they may visit architectural blogs to learn what domain-specific vocabulary they can adopt to help produce distinctive images of buildings.
We are also researching solutions to challenges faced by prompt creators who, with generative AI, are essentially programming without using a programming language. As an example, we developed new methods for extracting semantically meaningful structure from natural language prompts. We have applied these structures to prompt editors to provide features similar to those found in other programming environments, such as semantic highlighting, autosuggest, and structured data views.
The growth of generative LLMs has also opened up new techniques to solve important long-standing problems. Agile classifiers are one approach we’re taking to leverage the semantic and syntactic strengths of LLMs to solve classification problems related to safer online discourse, such as nimbly blocking newer types of toxic language as quickly as it may evolve online. The big advance here is the ability to develop high quality classifiers from very small datasets — as small as 80 examples. This suggests a positive future for online discourse and better moderation of it: instead of collecting millions of examples to attempt to create universal safety classifiers for all use cases over months or years, more agile classifiers might be created by individuals or small organizations and tailored for their specific use cases, and iterated on and adapted in the time-span of a day (e.g., to block a new kind of harassment being received or to correct unintended biases in models). As an example of their utility, these methods recently won a SemEval competition to identify and explain sexism.
We’ve also developed new state-of-the-art explainability methods to identify the role of training data on model behaviors and misbehaviours. By combining training data attribution methods with agile classifiers, we also found that we can identify mislabelled training examples. This makes it possible to reduce the noise in training data, leading to significant improvements on model accuracy.
Collectively, these methods are critical to help the scientific community improve generative models. They provide techniques for fast and effective content moderation and dialogue safety methods that help support creators whose content is the basis for generative models’ amazing outcomes. In addition, they provide direct tools to help debug model misbehavior which leads to better generation.
Visualization and education
To lower barriers in understanding ML-related work, we regularly design and publish highly visual, interactive online essays, called AI Explorables, that provide accessible, hands-on ways to learn about key ideas in ML. For example, we recently published new AI Explorables on the topics of model confidence and unintended biases. In our latest Explorable, “From Confidently Incorrect Models to Humble Ensembles,” we discuss the problem with model confidence: models can sometimes be very confident in their predictions… and yet completely incorrect. Why does this happen and what can be done about it? Our Explorable walks through these issues with interactive examples and shows how we can build models that have more appropriate confidence in their predictions by using a technique called ensembling, which works by averaging the outputs of multiple models. Another Explorable, “Searching for Unintended Biases with Saliency”, shows how spurious correlations can lead to unintended biases — and how techniques such as saliency maps can detect some biases in datasets, with the caveat that it can be difficult to see bias when it’s more subtle and sporadic in a training set.
|
| PAIR designs and publishes AI Explorables, interactive essays on timely topics and new methods in ML research, such as “From Confidently Incorrect Models to Humble Ensembles,” which looks at how and why models offer incorrect predictions with high confidence, and how “ensembling” the outputs of many models can help avoid this. |
Transparency and the Data Cards Playbook
Continuing to advance our goal of helping people to understand ML, we promote transparent documentation. In the past, PAIR and Google Cloud developed model cards. Most recently, we presented our work on Data Cards at ACM FAccT’22 and open-sourced the Data Cards Playbook, a joint effort with the Technology, AI, Society, and Culture team (TASC). The Data Cards Playbook is a toolkit of participatory activities and frameworks to help teams and organizations overcome obstacles when setting up a transparency effort. It was created using an iterative, multidisciplinary approach rooted in the experiences of over 20 teams at Google, and comes with four modules: Ask, Inspect, Answer and Audit. These modules contain a variety of resources that can help you customize Data Cards to your organization’s needs:
- 18 Foundations: Scalable frameworks that anyone can use on any dataset type
- 19 Transparency Patterns: Evidence-based guidance to produce high-quality Data Cards at scale
- 33 Participatory Activities: Cross-functional workshops to navigate transparency challenges for teams
- Interactive Lab: Generate interactive Data Cards from markdown in the browser
The Data Cards Playbook is accessible as a learning pathway for startups, universities, and other research groups.
Software Tools
Our team thrives on creating tools, toolkits, libraries, and visualizations that expand access and improve understanding of ML models. One such resource is Know Your Data, which allows researchers to test a model’s performance for various scenarios through interactive qualitative exploration of datasets that they can use to find and fix unintended dataset biases.
Recently, PAIR released a new version of the Learning Interpretability Tool (LIT) for model debugging and understanding. LIT v0.5 provides support for image and tabular data, new interpreters for tabular feature attribution, a “Dive” visualization for faceted data exploration, and performance improvements that allow LIT to scale to 100k dataset entries. You can find the release notes and code on GitHub.
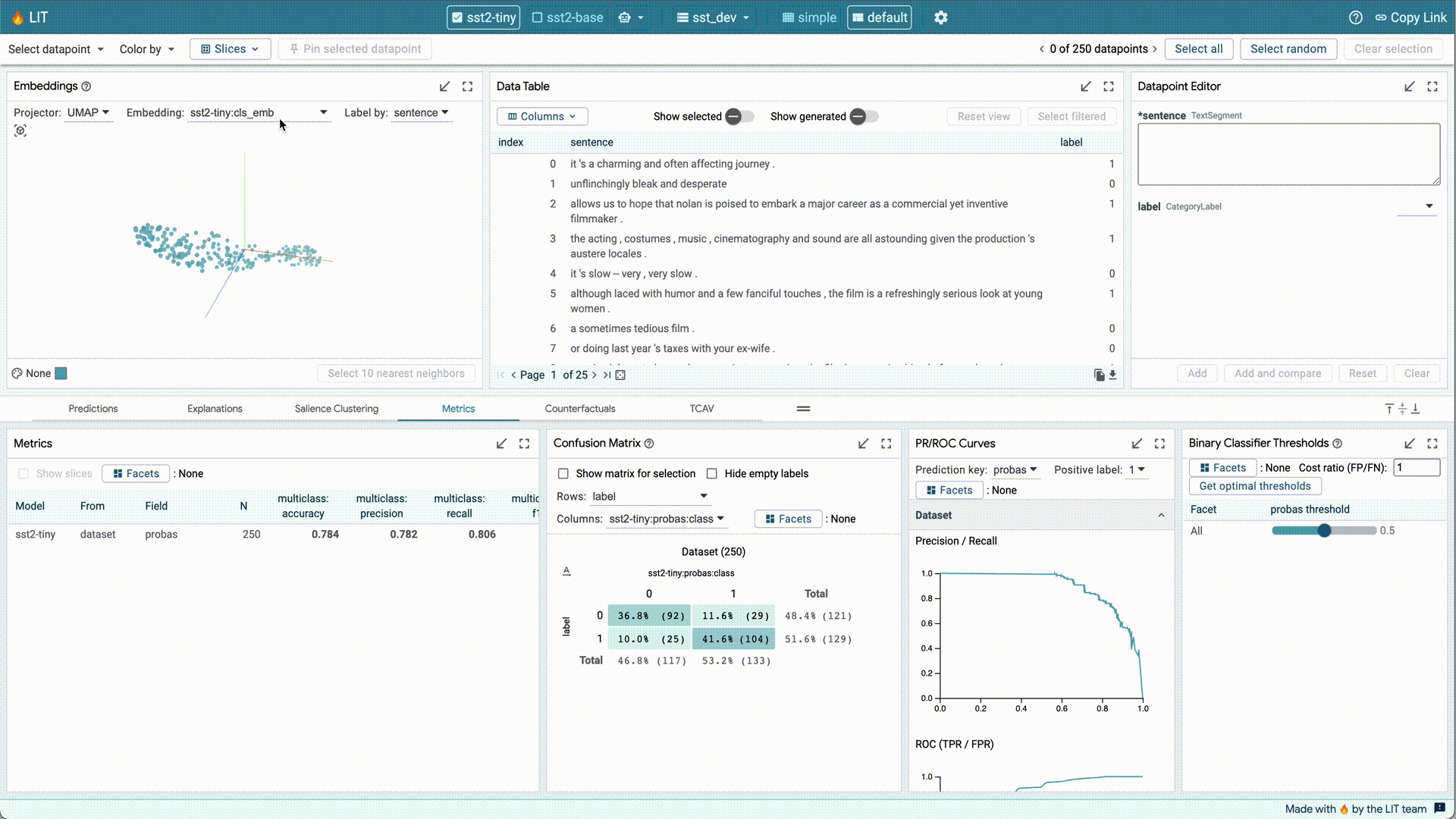 |
| PAIR’s Learning Interpretability Tool (LIT), an open-source platform for visualization and understanding of ML models. |
PAIR has also contributed to MakerSuite, a tool for rapid prototyping with LLMs using prompt programming. MakerSuite builds on our earlier research on PromptMaker, which won an honorable mention at CHI 2022. MakerSuite lowers the barrier to prototyping ML applications by broadening the types of people who can author these prototypes and by shortening the time spent prototyping models from months to minutes.
 |
| A screenshot of MakerSuite, a tool for rapidly prototyping new ML models using prompt-based programming, which grew out of PAIR’s prompt programming research. |
Ongoing work
As the world of AI moves quickly ahead, PAIR is excited to continue to develop new tools, research, and educational materials to help change the way people think about what THEY can do with AI.
For example, we recently conducted an exploratory study with five designers (presented at CHI this year) that looks at how people with no ML programming experience or training can use prompt programming to quickly prototype functional user interface mock-ups. This prototyping speed can help inform designers on how to integrate ML models into products, and enables them to conduct user research sooner in the product design process.
Based on this study, PAIR’s researchers built PromptInfuser, a design tool plugin for authoring LLM-infused mock-ups. The plug-in introduces two novel LLM-interactions: input-output, which makes content interactive and dynamic, and frame-change, which directs users to different frames depending on their natural language input. The result is more tightly integrated UI and ML prototyping, all within a single interface.
Recent advances in AI represent a significant shift in how easy it is for researchers to customize and control models for their research objectives and goals.These capabilities are transforming the way we think about interacting with AI, and they create lots of new opportunities for the research community. PAIR is excited about how we can leverage these capabilities to make AI easier to use for more people.
Acknowledgements
Thanks to everyone in PAIR, to Reena Jana and to all of our collaborators.
Leave a Reply