
Unifying image-caption and image-classification datasets with prefix conditioning
Pre-training visual language (VL) models on web-scale image-caption datasets has recently emerged as a powerful alternative to traditional pre-training on image classification data. Image-caption datasets are considered to be more “open-domain” because they contain broader scene types and vocabulary words, which result in models with strong performance in few- and zero-shot recognition tasks. However, images with fine-grained class descriptions can be rare, and the class distribution can be imbalanced since image-caption datasets do not go through manual curation. By contrast, large-scale classification datasets, such as ImageNet, are often curated and can thus provide fine-grained categories with a balanced label distribution. While it may sound promising, directly combining caption and classification datasets for pre-training is often unsuccessful as it can result in biased representations that do not generalize well to various downstream tasks.
In “Prefix Conditioning Unifies Language and Label Supervision”, presented at CVPR 2023, we demonstrate a pre-training strategy that uses both classification and caption datasets to provide complementary benefits. First, we show that naïvely unifying the datasets results in sub-optimal performance on downstream zero-shot recognition tasks as the model is affected by dataset bias: the coverage of image domains and vocabulary words is different in each dataset. We address this problem during training through prefix conditioning, a novel simple and effective method that uses prefix tokens to disentangle dataset biases from visual concepts. This approach allows the language encoder to learn from both datasets while also tailoring feature extraction to each dataset. Prefix conditioning is a generic method that can be easily integrated into existing VL pre-training objectives, such as Contrastive Language-Image Pre-training (CLIP) or Unified Contrastive Learning (UniCL).
High-level idea
We note that classification datasets tend to be biased in at least two ways: (1) the images mostly contain single objects from restricted domains, and (2) the vocabulary is limited and lacks the linguistic flexibility required for zero-shot learning. For example, the class embedding of “a photo of a dog” optimized for ImageNet usually results in a photo of one dog in the center of the image pulled from the ImageNet dataset, which does not generalize well to other datasets containing images of multiple dogs in different spatial locations or a dog with other subjects.
By contrast, caption datasets contain a wider variety of scene types and vocabularies. As shown below, if a model simply learns from two datasets, the language embedding can entangle the bias from the image classification and caption dataset, which can decrease the generalization in zero-shot classification. If we can disentangle the bias from two datasets, we can use language embeddings that are tailored for the caption dataset to improve generalization.
 |
| Top: Language embedding entangling the bias from image classification and caption dataset. Bottom: Language embeddings disentangles the bias from two datasets. |
Prefix conditioning
Prefix conditioning is partially inspired by prompt tuning, which prepends learnable tokens to the input token sequences to instruct a pre-trained model backbone to learn task-specific knowledge that can be used to solve downstream tasks. The prefix conditioning approach differs from prompt tuning in two ways: (1) it is designed to unify image-caption and classification datasets by disentangling the dataset bias, and (2) it is applied to VL pre-training while the standard prompt tuning is used to fine-tune models. Prefix conditioning is an explicit way to specifically steer the behavior of model backbones based on the type of datasets provided by users. This is especially helpful in production when the number of different types of datasets is known ahead of time.
During training, prefix conditioning learns a text token (prefix token) for each dataset type, which absorbs the bias of the dataset and allows the remaining text tokens to focus on learning visual concepts. Specifically, it prepends prefix tokens for each dataset type to the input tokens that inform the language and visual encoder of the input data type (e.g., classification vs. caption). Prefix tokens are trained to learn the dataset-type-specific bias, which enables us to disentangle that bias in language representations and utilize the embedding learned on the image-caption dataset during test time, even without an input caption.
We utilize prefix conditioning for CLIP using a language and visual encoder. During test time, we employ the prefix used for the image-caption dataset since the dataset is supposed to cover broader scene types and vocabulary words, leading to better performance in zero-shot recognition.
 |
| Illustration of the Prefix Conditioning. |
Experimental results
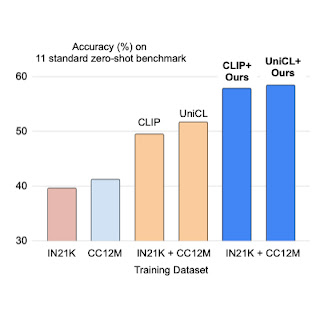
We apply prefix conditioning to two types of contrastive loss, CLIP and UniCL, and evaluate their performance on zero-shot recognition tasks compared to models trained with ImageNet21K (IN21K) and Conceptual 12M (CC12M). CLIP and UniCL models trained with two datasets using prefix conditioning show large improvements in zero-shot classification accuracy.
 |
| Zero-shot classification accuracy of models trained with only IN21K or CC12M compared to CLIP and UniCL models trained with both two datasets using prefix conditioning (“Ours”). |
Study on test-time prefix
The table below describes the performance change by the prefix used during test time. We demonstrate that by using the same prefix used for the classification dataset (“Prompt”), the performance on the classification dataset (IN-1K) improves. When using the same prefix used for the image-caption dataset (“Caption”), the performance on other datasets (Zero-shot AVG) improves. This analysis illustrates that if the prefix is tailored for the image-caption dataset, it achieves better generalization of scene types and vocabulary words.
 |
| Analysis of the prefix used for test-time. |
Study on robustness to image distribution shift
We study the shift in image distribution using ImageNet variants. We see that the “Caption” prefix performs better than “Prompt” in ImageNet-R (IN-R) and ImageNet-Sketch (IN-S), but underperforms in ImageNet-V2 (IN-V2). This indicates that the “Caption” prefix achieves generalization on domains far from the classification dataset. Therefore, the optimal prefix probably differs by how far the test domain is from the classification dataset.
 |
| Analysis on the robustness to image-level distribution shift. IN: ImageNet, IN-V2: ImageNet-V2, IN-R: Art, Cartoon style ImageNet, IN-S: ImageNet Sketch. |
Conclusion and future work
We introduce prefix conditioning, a technique for unifying image caption and classification datasets for better zero-shot classification. We show that this approach leads to better zero-shot classification accuracy and that the prefix can control the bias in the language embedding. One limitation is that the prefix learned on the caption dataset is not necessarily optimal for the zero-shot classification. Identifying the optimal prefix for each test dataset is an interesting direction for future work.
Acknowledgements
This research was conducted by Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. Thanks to Zizhao Zhang and Sergey Ioffe for their valuable feedback.
Leave a Reply