
Build financial search applications using the Amazon Bedrock Cohere multilingual embedding model
Enterprises have access to massive amounts of data, much of which is difficult to discover because the data is unstructured. Conventional approaches to analyzing unstructured data use keyword or synonym matching. They don’t capture the full context of a document, making them less effective in dealing with unstructured data.
In contrast, text embeddings use machine learning (ML) capabilities to capture the meaning of unstructured data. Embeddings are generated by representational language models that translate text into numerical vectors and encode contextual information in a document. This enables applications such as semantic search, Retrieval Augmented Generation (RAG), topic modeling, and text classification.
For example, in the financial services industry, applications include extracting insights from earnings reports, searching for information from financial statements, and analyzing sentiment about stocks and markets found in financial news. Text embeddings enable industry professionals to extract insights from documents, minimize errors, and increase their performance.
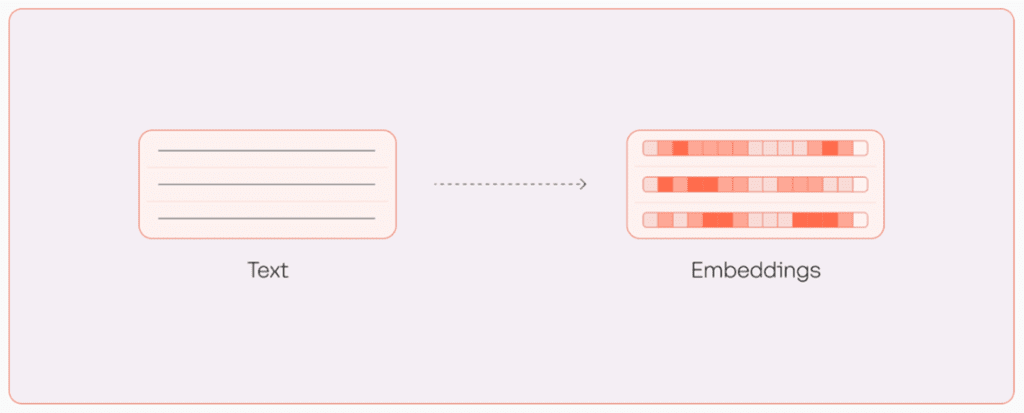
In this post, we showcase an application that can search and query across financial news in different languages using Cohere’s Embed and Rerank models with Amazon Bedrock.
Cohere’s multilingual embedding model
Cohere is a leading enterprise AI platform that builds world-class large language models (LLMs) and LLM-powered solutions that allow computers to search, capture meaning, and converse in text. They provide ease of use and strong security and privacy controls.
Cohere’s multilingual embedding model generates vector representations of documents for over 100 languages and is available on Amazon Bedrock. This allows AWS customers to access it as an API, which eliminates the need to manage the underlying infrastructure and ensures that sensitive information remains securely managed and protected.
The multilingual model groups text with similar meanings by assigning them positions that are close to each other in a semantic vector space. With a multilingual embedding model, developers can process text in multiple languages without the need to switch between different models, as illustrated in the following figure. This makes processing more efficient and improves performance for multilingual applications.
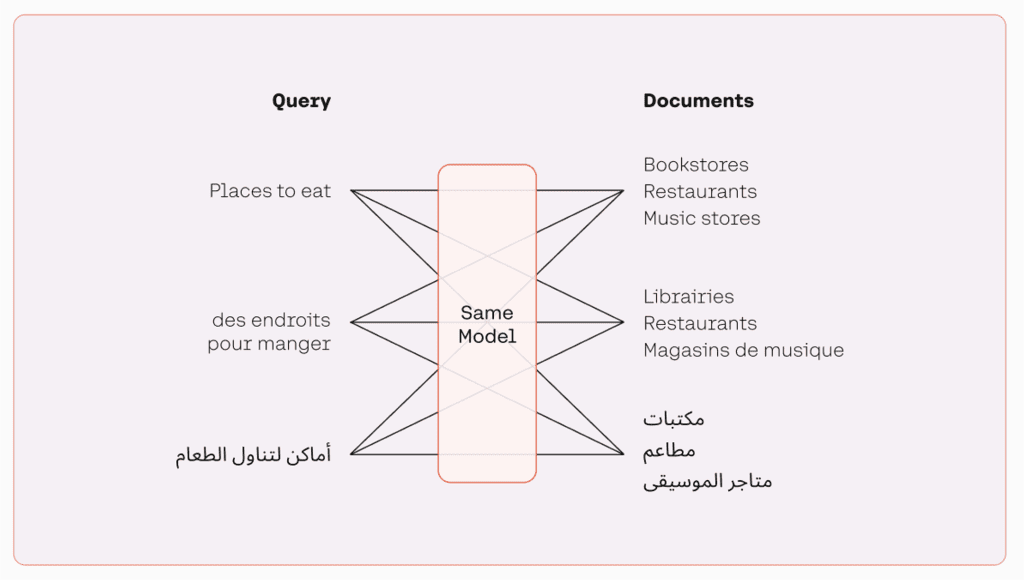
The following are some of the highlights of Cohere’s embedding model:
- Focus on document quality – Typical embedding models are trained to measure similarity between documents, but Cohere’s model also measures document quality
- Better retrieval for RAG applications – RAG applications require a good retrieval system, which Cohere’s embedding model excels at
- Cost-efficient data compression – Cohere uses a special, compression-aware training method, resulting in substantial cost savings for your vector database
Use cases for text embedding
Text embeddings turn unstructured data into a structured form. This allows you to objectively compare, dissect, and derive insights from all of these documents. The following are example use cases that Cohere’s embedding model enables:
- Semantic search – Enables powerful search applications when coupled with a vector database, with excellent relevance based on search phrase meaning
- Search engine for a larger system – Finds and retrieves the most relevant information from connected enterprise data sources for RAG systems
- Text classification – Supports intent recognition, sentiment analysis, and advanced document analysis
- Topic modeling – Turns a collection of documents into distinct clusters to uncover emerging topics and themes
Enhanced search systems with Rerank
In enterprises where conventional keyword search systems are already present, how do you introduce modern semantic search capabilities? For such systems that have been part of a company’s information architecture for a long time, a complete migration to an embeddings-based approach is, in many cases, just not feasible.
Cohere’s Rerank endpoint is designed to bridge this gap. It acts as the second stage of a search flow to provide a ranking of relevant documents per a user’s query. Enterprises can retain an existing keyword (or even semantic) system for the first-stage retrieval and boost the quality of search results with the Rerank endpoint in the second-stage reranking.
Rerank provides a fast and straightforward option for improving search results by introducing semantic search technology into a user’s stack with a single line of code. The endpoint also comes with multilingual support. The following figure illustrates the retrieval and reranking workflow.
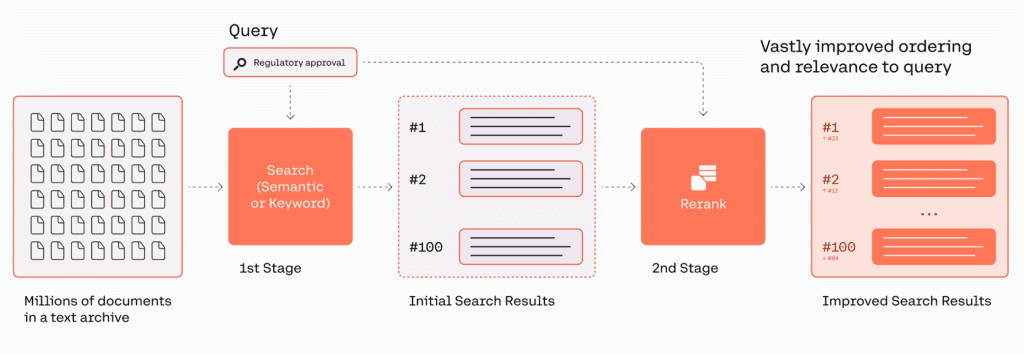
Solution overview
Financial analysts need to digest a lot of content, such as financial publications and news media, in order to stay informed. According to the Association for Financial Professionals (AFP), financial analysts spend 75% of their time gathering data or administering the process instead of added-value analysis. Finding the answer to a question across a variety of sources and documents is time-intensive and tedious work. The Cohere embedding model helps analysts quickly search across numerous article titles in multiple languages to find and rank the articles that are most relevant to a particular query, saving an enormous amount of time and effort.
In the following use case example, we showcase how Cohere’s Embed model searches and queries across financial news in different languages in one unique pipeline. Then we demonstrate how adding Rerank to your embeddings retrieval (or adding it to a legacy lexical search) can further improve results.
The supporting notebook is available on GitHub.
The following diagram illustrates the workflow of the application.
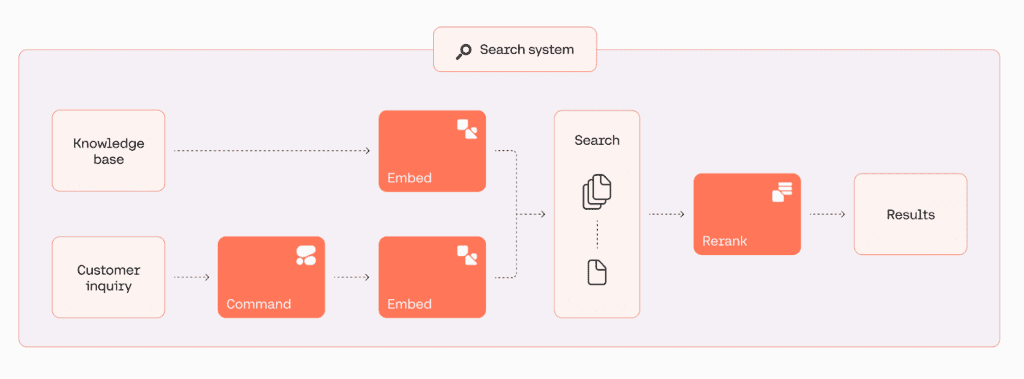
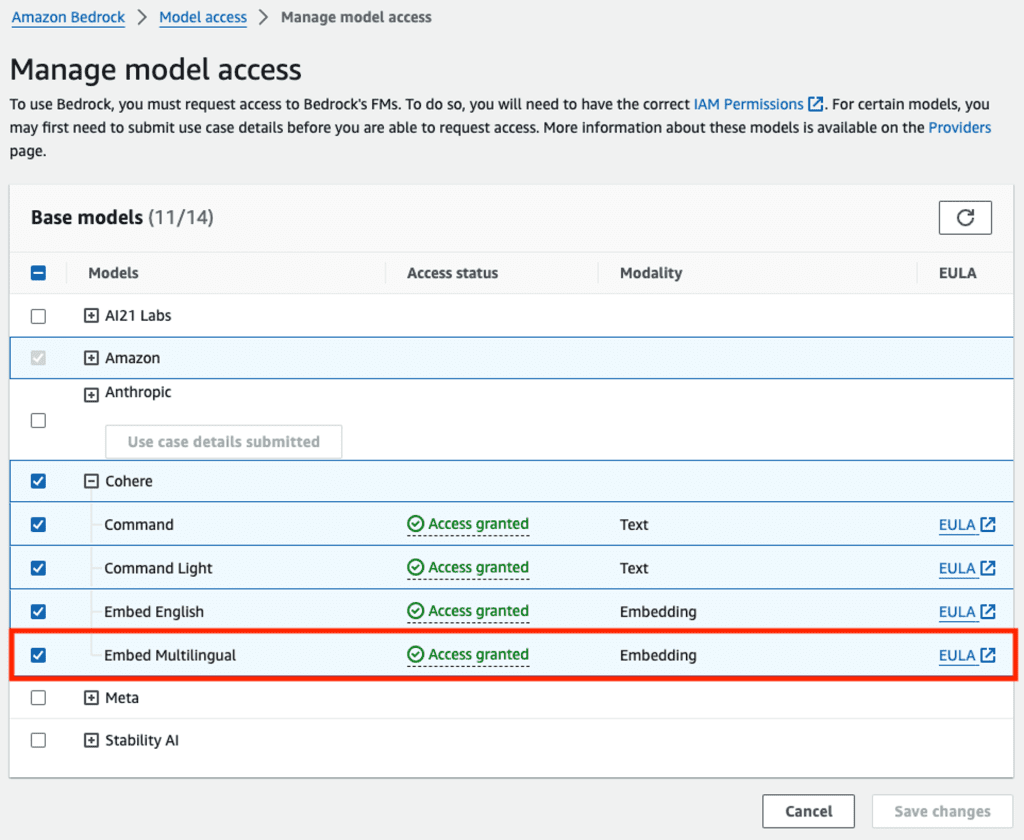
Enable model access through Amazon Bedrock
Amazon Bedrock users need to request access to models to make them available for use. To request access to additional models, choose Model access the navigation pane on the Amazon Bedrock console. For more information, see Model access. For this walkthrough, you need to request access to the Cohere Embed Multilingual model.
Install packages and import modules
First, we install the necessary packages and import the modules we’ll use in this example:
Import documents
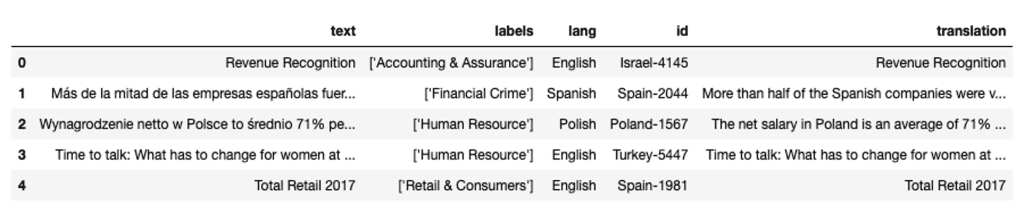
We use a dataset (MultiFIN) containing a list of real-world article headlines covering 15 languages (English, Turkish, Danish, Spanish, Polish, Greek, Finnish, Hebrew, Japanese, Hungarian, Norwegian, Russian, Italian, Icelandic, and Swedish). This is an open source dataset curated for financial natural language processing (NLP) and is available on a GitHub repository.
In our case, we’ve created a CSV file with MultiFIN’s data as well as a column with translations. We don’t use this column to feed the model; we use it to help us follow along when we print the results for those who don’t speak Danish or Spanish. We point to that CSV to create our dataframe:
Select a list of documents to query
MultiFIN has over 6,000 records in 15 different languages. For our example use case, we focus on three languages: English, Spanish, and Danish. We also sort the headers by length and pick the longest ones.
Because we’re picking the longest articles, we ensure the length is not due to repeated sequences. The following code shows an example where that is the case. We will clean that up.
df['text'].iloc[2215]
Our list of documents is nicely distributed across the three languages:
The following is the longest article header in our dataset:
Embed and index documents
Now, we want to embed our documents and store the embeddings. The embeddings are very large vectors that encapsulate the semantic meaning of our document. In particular, we use Cohere’s embed-multilingual-v3.0 model, which creates embeddings with 1,024 dimensions.
When a query is passed, we also embed the query and use the hnswlib library to find the closest neighbors.
It only takes a few lines of code to establish a Cohere client, embed the documents, and create the search index. We also keep track of the language and translation of the document to enrich the display of the results.
Build a retrieval system
Next, we build a function that takes a query as input, embeds it, and finds the four headers more closely related to it:
Query the retrieval system
Let’s explore what our system does with a couple of different queries. We start with English:
The results are as follows:
Notice the following:
- We’re asking related, but slightly different questions, and the model is nuanced enough to present the most relevant results at the top.
- Our model does not perform keyword-based search, but semantic search. Even if we’re using a term like “data science” instead of “AI,” our model is able to understand what’s being asked and return the most relevant result at the top.
How about a query in Danish? Let’s look at the following query:
In the preceding example, the English acronym “PP&E” stands for “property, plant, and equipment,” and our model was able to connect it to our query.
In this case, all returned results are in Danish, but the model can return a document in a language other than the query if its semantic meaning is closer. We have complete flexibility, and with a few lines of code, we can specify whether the model should only look at documents in the language of the query, or whether it should look at all documents.
Improve results with Cohere Rerank
Embeddings are very powerful. However, we’re now going to look at how to refine our results even further with Cohere’s Rerank endpoint, which has been trained to score the relevancy of documents against a query.
Another advantage of Rerank is that it can work on top of a legacy keyword search engine. You don’t have to change to a vector database or make drastic changes to your infrastructure, and it only takes a few lines of code. Rerank is available in Amazon SageMaker.
Let’s try a new query. We use SageMaker this time:
In this case, a semantic search was able to retrieve our answer and display it in the results, but it’s not at the top. However, when we pass the query again to our Rerank endpoint with the list of docs retrieved, Rerank is able to surface the most relevant document at the top.
First, we create the client and the Rerank endpoint:
When we pass the documents to Rerank, the model is able to pick the most relevant one accurately:
Conclusion
This post presented a walkthrough of using Cohere’s multilingual embedding model in Amazon Bedrock in the financial services domain. In particular, we demonstrated an example of a multilingual financial articles search application. We saw how the embedding model enables efficient and accurate discovery of information, thereby boosting the productivity and output quality of an analyst.
Cohere’s multilingual embedding model supports over 100 languages. It removes the complexity of building applications that require working with a corpus of documents in different languages. The Cohere Embed model is trained to deliver results in real-world applications. It handles noisy data as inputs, adapts to complex RAG systems, and delivers cost-efficiency from its compression-aware training method.
Start building with Cohere’s multilingual embedding model in Amazon Bedrock today.
About the Authors
 James Yi is a Senior AI/ML Partner Solutions Architect in the Technology Partners COE Tech team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy, and scale AI/ML applications to derive business value. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
James Yi is a Senior AI/ML Partner Solutions Architect in the Technology Partners COE Tech team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy, and scale AI/ML applications to derive business value. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
 Gonzalo Betegon is a Solutions Architect at Cohere, a provider of cutting-edge natural language processing technology. He helps organizations address their business needs through the deployment of large language models.
Gonzalo Betegon is a Solutions Architect at Cohere, a provider of cutting-edge natural language processing technology. He helps organizations address their business needs through the deployment of large language models.
 Meor Amer is a Developer Advocate at Cohere, a provider of cutting-edge natural language processing (NLP) technology. He helps developers build cutting-edge applications with Cohere’s Large Language Models (LLMs).
Meor Amer is a Developer Advocate at Cohere, a provider of cutting-edge natural language processing (NLP) technology. He helps developers build cutting-edge applications with Cohere’s Large Language Models (LLMs).
Leave a Reply