
Gemma is now available in Amazon SageMaker JumpStart
Today, we’re excited to announce that the Gemma model is now available for customers using Amazon SageMaker JumpStart. Gemma is a family of language models based on Google’s Gemini models, trained on up to 6 trillion tokens of text. The Gemma family consists of two sizes: a 7 billion parameter model and a 2 billion parameter model. Now, you can use Gemma 2B and Gemma 7B pretrained and instruction-tuned models within SageMaker JumpStart. JumpStart is the machine learning (ML) hub of SageMaker that provides access to foundation models in addition to built-in algorithms and end-to-end solution templates to help you quickly get started with ML.
In this post, we walk through how to deploy the Gemma model and fine tune it for your use cases in SageMaker JumpStart. The complete notebook is available on GitHub.
Gemma model
Gemma is a family of lightweight, state-of-the-art models built from the same research and technology used to create the Gemini models. Developed by Google DeepMind and other teams across Google, Gemma is inspired by Gemini. Gemma exhibits strong generalist capabilities in text domains and state-of-the-art understanding and reasoning skills at scale. It achieves better performance compared to other publicly available models of similar or larger scales across different domains, including question answering, commonsense reasoning, mathematics and science, and coding. Gemma released the model weights to support developer innovation using Gemma models. Gemma was launched with a new Responsible Generative AI Toolkit that provides guidance and essential tools for creating safer AI applications with Gemma.
Foundation models in SageMaker
JumpStart provides access to a range of models from popular model hubs including Hugging Face, PyTorch Hub, and TensorFlow Hub, which you can use within your ML development workflow in SageMaker. Recent advances in ML have given rise to a new class of models known as foundation models, which are typically trained on billions of parameters and are adaptable to a wide category of use cases, such as text summarization, generating digital art, and language translation. Because these models are expensive to train, customers want to use existing pre-trained foundation models and fine-tune them as needed, rather than train these models themselves. SageMaker provides a curated list of models that you can choose from on the SageMaker console.
You can now find foundation models from different model providers within JumpStart, enabling you to get started with foundation models quickly. You can find foundation models based on different tasks or model providers, and review model characteristics and usage terms. You can also try these models using a test UI widget. When you want to use a foundation model at scale, you can do so without leaving SageMaker by using pre-built notebooks from model providers. Because the models are hosted and deployed on AWS, your data, whether used for evaluating the model or using it at scale, is never shared with third parties.
Let’s explore how you can use the Llama Guard model in JumpStart.
Explore the Gemma model in Jumpstart
You can access Gemma foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, see Amazon SageMaker Studio.
In the AWS Management Console for SageMaker Studio, go to SageMaker JumpStart under Prebuilt and automated solutions. Jumpstart contains pre-trained models, notebooks, and prebuilt solutions.
On the SageMaker JumpStart landing page, you can find the Gemma model by searching for Gemma.
You can then select from a variety of Gemma model variants, including Gemma 2B, Gemma 7B, Gemma 2B instruct, and Gemma 7B instruct.
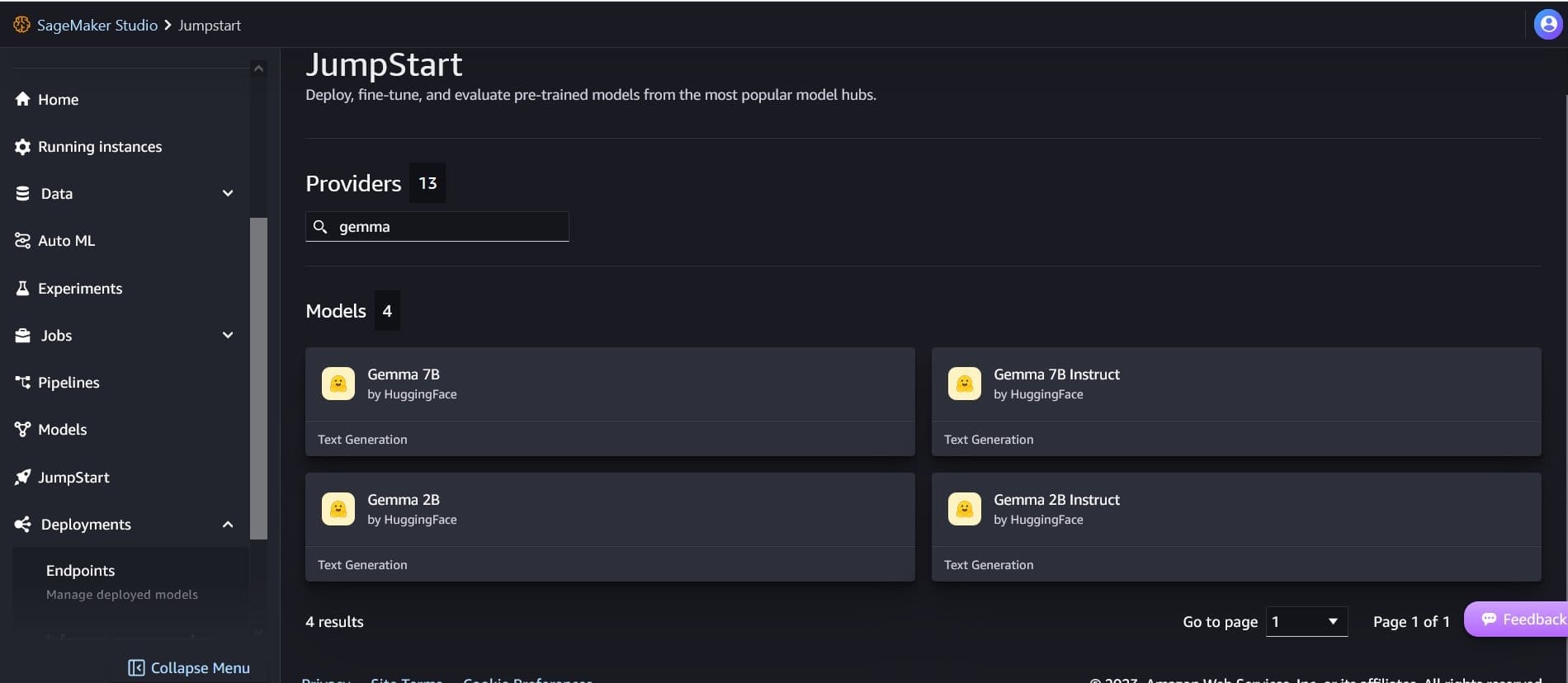
Choose the model card to view details about the model such as the license, data used to train, and how to use the model. You will also find a Deploy button, which takes you to a landing page where you can test inference with an example payload.
Deploy Gemma with SageMaker Python SDK
You can find the code showing the deployment of Gemma on JumpStart and an example of how to use the deployed model in this GitHub notebook.
Start by selecting the SageMaker Model Hub model ID and model version to use when deploying Gemma.
Choose a model ID from the following table, which details the default configuration options for the JumpStart deployment. Because of the large vocabulary size of 256 thousand tokens, Gemma 7B can only fit on a single A10G GPU when supporting a 1 thousand context length. For this reason, JumpStart uses a larger default instance for Gemma 7B.
| Model ID | Default inference instance | Tensor parallel degree | Supported context Length |
| huggingface-llm-gemma-2b | ml.g5.xlarge | 1 | 8k |
| huggingface-llm-gemma-2b-instruct | ml.g5.xlarge | 1 | 8k |
| huggingface-llm-gemma-7b | ml.g5.12xlarge | 4 | 8k |
| huggingface-llm-gemma-7b-instruct | ml.g5.12xlarge | 4 | 8k |
You can now deploy the model using SageMaker JumpStart. The following code uses the default instance ml.g5.12xlarge for the inference endpoint You can deploy the model on other instance types by passing instance_type in the JumpStartModel class. The deployment might take 5-10 minutes.
For successful deployment, you must manually change the accept_eula argument in the model’s deploy method to True. This model is deployed using the text-generation-inference (TGI) deep learning container.
Invoke endpoint
You can programmatically retrieve example payloads from the JumpStartModel object. This will help you get started by observing pre-formatted instruction prompts that Gemma can ingest.
Before we look at specific prompts, let’s consider the chat template for Gemma Instruct models.
Here, you place your prompt in the [USER_PROMPT] location. There’s no support for a system instruction; instead, you can prepend the desired instruction to the user prompt. Additionally, if you have a multi-turn conversation, then the model prompt can alternate between user and assistant as needed.
Now consider a few instruction example prompts. Here, you ask Gemma to write a Hello World program.
The following is the expected output:
Next, invoke Gemma for the creative task of writing a poem.
The following is the output:
This looks pretty good!
Now, let’s look at latency and throughput performance benchmarking for model serving with the default JumpStart deployment configuration. Here, we show how model performance might differ for your typical endpoint workload. In the following tables, you can observe that small-sized queries (256 input words and 256 output tokens) are quite performant under a large number of concurrent users, reaching token throughput on the order of one thousand to two thousand tokens per second. However, as the number of input words approaches Gemma’s maximum supported context length of eight thousand tokens, the endpoint saturates its batching capacity—the number of concurrent requests allowed to be processed simultaneously—due to instance memory-bound constraints.
For more information on how to consider this information and adjust deployment configurations for your specific use case, see Benchmark and optimize endpoint deployment in Amazon SageMaker JumpStart.
| . | Throughput (tokens/s) | ||||||||||
| Concurrent users | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | |||
| model | Instance type | Input words | Output tokens | . | . | . | . | . | . | . | . |
| gemma-2b-instruct | ml.g5.xlarge | 256 | 256 | 73 | 137 | 262 | 486 | 829 | 1330 | 1849 | 1834 |
| 2048 | 256 | 69 | 126 | 227 | 373 | 537 | 704 | 764 | — | ||
| 7936 | 256 | 60 | 100 | 147 | 195 | 226 | 230 | — | — | ||
| gemma-7b-instruct | ml.g5.12xlarge | 256 | 256 | 62 | 119 | 227 | 413 | 601 | 811 | 937 | 962 |
| 2048 | 256 | 56 | 100 | 172 | 245 | 267 | 273 | — | — | ||
| 7936 | 256 | 44 | 67 | 77 | 77 | 78 | — | — | — | ||
| . | P50 latency (ms/token) | ||||||||||
| Concurrent users | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | |||
| model | Instance type | Input words | Output tokens | . | . | . | . | . | . | . | . |
| gemma-2b-instruct | ml.g5.xlarge | 256 | 256 | 13 | 14 | 15 | 16 | 19 | 23 | 33 | 49 |
| 2048 | 256 | 14 | 15 | 17 | 20 | 28 | 43 | 79 | — | ||
| 7936 | 256 | 16 | 19 | 26 | 39 | 68 | 136 | — | — | ||
| Gemma-7b-instruct | ml.g5.12xlarge | 256 | 256 | 16 | 16 | 17 | 19 | 26 | 38 | 57 | 110 |
| 2048 | 256 | 17 | 19 | 23 | 32 | 52 | 119 | — | — | ||
| 7936 | 256 | 22 | 29 | 45 | 105 | 197 | — | — | — | ||
Fine-tune Gemma using SageMaker Python SDK
Next, we show you how to fine-tune the Gemma 7B instruct model on a conversational-formatted dataset using QLoRA technique. As mentioned previously, due to the large vocabulary size of 256 thousand and the 8 thousand context length, JumpStart offers the following default configurations for QLoRA fine-tuning.
| Model ID | Default training instance | Maximum input sequence length | Per device training batch size | Gradient accumulation steps |
| huggingface-llm-gemma-2b | ml.g5.2xlarge | 1024 | 1 | 4 |
| huggingface-llm-gemma-2b-instruct | ml.g5.2xlarge | 1024 | 1 | 4 |
| huggingface-llm-gemma-7b | ml.g5.12xlarge | 2048 | 1 | 4 |
| huggingface-llm-gemma-7b-instruct | ml.g5.12xlarge | 2048 | 1 | 4 |
Let’s load and process the dataset in conversational format. The example dataset for this demonstration is OpenAssistant’s TOP-1 Conversation Threads.
The training data should be formulated in JSON lines (.jsonl) format, where each line is a dictionary representing a set of conversations. One example within the JSON lines file is shown below. For details on how to process the dataset, see the notebook in GitHub.
Underlying the training scripts, JumpStart uses HuggingFace SFTTrainer with QLoRA and FlashAttention. Flash Attention enables scaling efficiency, leading to faster training and inference. Besides chat-based fine-tuning, JumpStart also supports instruction and domain adaptation fine-tuning with QLoRA. For details, see the notebook in GitHub.
After the fine-tuning, you can deploy the fine-tuned model to a SageMaker endpoint.
You can choose to deploy the model fine-tuned on conversation data in SageMaker endpoint with HuggingFace messages API feature as an alternative approach. The benefit of using Message API feature is that it allow users to pass the query examples in raw format as shown in the following table and chat_template within the endpoint will convert the query examples into the proper format before sending them into the model. For details, see the deployment section after fine-tuning in the notebook.
After deploying the fine-tuned model in an endpoint, you can compare output responses from pre-trained and fine-tuned Gemma models. The examples are collected from test data, which is a hold-out set from the training data. The inference parameters are max_tokens as 512, top_p as 0.9, temperature as 0.4, and top_k as 50.
As you can see with the fine tuning results, the agent answers are more accurate.
To further evaluate your fine tuned models, you may explore FM evaluation with Amazon SageMaker Clarify to see how your fine tuned model performs in comparison to base model.
| Inputs | Ground truth | Response from base model | Response from fine-tuned model | |
| 1 |
User: I want to work on my vocabulary, can you give me some simple ways that I can find new words to use to increase the diversity of my sentences? Assistant: Certainly! Improving your vocabulary is an ongoing process, but here are some simple ways to find new words and increase the diversity of your sentences: 1. Read widely: Reading books, articles, and blogs from different genres and subjects exposes you to new words and phrases. Note down any unfamiliar words you encounter and look up their meanings. 2. Use a thesaurus: Whenever you write or read, use a thesaurus to find synonyms for commonly used words. This not only helps you learn new words but also enhances your understanding of their subtle differences in meaning. 3. Word-a-day calendars or apps: Subscribe to a word-a-day email or download a vocabulary-building app. These tools introduce you to a new word each day, along with its meaning, pronunciation, and usage examples. 4. Join a book club or discussion group: Engaging in conversations and discussions about books, articles, or any other topic exposes you to different perspectives and new vocabulary. Listen attentively to others and try using new words in context. 5. Play word games: Games like Scrabble, Boggle, and crossword puzzles challenge your vocabulary skills and help you learn new words in an enjoyable way. 6. Watch movies, TV shows, or documentaries: Visual media often use diverse language, slang, and jargon. Watching movies, TV shows, or documentaries with subtitles can help you better understand and remember new words. 7. Practice writing: Regularly writing stories, essays, or journal entries encourages you to use new words and phrases. Experiment with different writing styles and genres to expand your vocabulary. 8. Learn a new word’s etymology: Understanding the origin and history of a word can make it easier to remember and use correctly. Researching the etymology also exposes you to related words and concepts. 9. Use flashcards or spaced repetition software: Create flashcards with new words, their meanings, and example sentences. Review them regularly or use spaced repetition software like Anki to optimize your learning. 10. Set personal goals: Set achievable targets, such as learning five new words per week. Keep track of your progress and reward yourself for meeting your goals. By consistently incorporating these strategies into your daily routine, you’ll gradually build a diverse and robust vocabulary. User: Hm, i really like the idea of reading. Can you recomend me a cool science-fiction thriller which i could read? |
Assistant: Certainly! Here are a few recommendations for science-fiction thrillers that you might enjoy: 1. “The Three-Body Problem” by Liu Cixin – This award-winning novel explores the first contact between humanity and an alien civilization, and the political and personal ramifications that result. It’s a gripping and thought-provoking read that delves into deep questions about the nature of existence and the universe. 2. “Annihilation” by Jeff Vandermeer – This novel follows a group of scientists as they venture into a mysterious area known as “Area X,” where they encounter strange and unsettling phenomena. As they delve deeper into the area, they begin to uncover dark secrets about the nature of reality and the world around them. 3. “Dark Matter” by Blake Crouch – This novel follows a brilliant physicist named Jason Dessen, who is abducted and transported to a parallel universe. As he tries to find his way back to his own reality, he must confront his own choices and the consequences of his actions. 4. “The Andromeda Strain” by Michael Crichton – This classic novel follows a team of scientists as they try to contain and study a deadly extraterrestrial microbe that has landed on Earth. As they race against time to find a way to neutralize the microbe, they must also contend with political intrigue and personal conflicts. 5. “Ready Player One” by Ernest Cline – This novel is set in a dystopian future where the majority of the population spends their time in a virtual reality world known as the OASIS. When the creator of the OASIS dies and leaves behind a challenge to find a hidden Easter egg, a young protagonist sets out on a thrilling quest that will change his life forever. I hope one of these recommendations sparks your interest! |
Assistant: The text does not contain information about your reading preferences or interests, therefore I cannot provide a book recommendation. |
Assistant: Sure, here are a few science-fiction thriller recommendations that you might enjoy: – “Dune” by Frank Herbert: This epic sci-fi novel is set on the desert planet of Arrakis, where a young prince named Paul Atreides must face the challenges of a hostile environment and a treacherous political landscape. – “The Martian” by Andy Weir: This gripping sci-fi thriller follows the story of Mark Watney, an astronaut stranded on Mars after a dust storm, as he uses his ingenuity and resourcefulness to survive and eventually make his way back to Earth. – “The Time Machine” by H.G. Wells: This classic sci-fi novel takes a philosophical approach to the concept of time travel, exploring the consequences of altering the past and the future. – “The Blade Runner” by Philip K. Dick: This neo-noir sci-fi novel, set in a futuristic Los Angeles, explores the intersection of human and artificial intelligence, and its influence on society and the nature of reality. – “The Androids” by Isaac Asimov: This sci-fi novel explores the concept of artificial intelligence and its potential consequences, particularly when humans develop advanced androids that challenge traditional human values and beliefs. These are just a few suggestions, and ultimately the best book for you will depend on your personal preferences and what kind of experience you’re looking for in a sci-fi thriller. But I hope these recommendations give you a good starting point for exploring the genre. Please let me know if you have any further questions or if there’s anything I can help you with. |
| 2 |
User: Write a Hello World program in VB.NET Assistant: Here you go: “`vbnet User: Make it take input from the $ and then say “Hello, $” instead of “Hello, World!” |
Assistant: Public Module HelloWorld Public Sub Main() System.Console.WriteLine(“What is your name?”) Dim name As String = System.Console.ReadLine() System.Console.WriteLine(“Hello, ” & name & “!”) End Sub End Module |
Assistant: “`vbnet Public Module HelloWorld Public Sub Main() Dim name As String = Console.ReadLine() Console.WriteLine(“Hello, ” & name) End Sub End Module |
Assistant: Sure! Here is an example: “`vbnet |
| 3 |
User: Give me a list of to do items when starting a project to train a large language model that can understanding and respond to human questions Assistant: The following steps are a condensed list of steps to take when starting a project to train a large language model capable of comprehending and responding to human inquiries: 1. Establish project scope and objectives, target audience. This should give you a basic idea of what the required steps are. Should I go into more detail on one of the points? User: These tasks need to be broken down further, could you please provide an updated to-do list with a more detailed breakdown of the tasks ahead |
Assistant: Here is a more detailed breakdown of each step: 1. Establish project scope and objectives: It is important to clearly define the goals of the project and what the target audience is. This will help you make decisions about what type of data to gather and what model architecture is appropriate. 2. Gather and preprocess data: This is an important step as the quality and diversity of the data will directly impact the performance of the model. Preprocessing may involve cleaning the data, tokenizing text, and converting words to numerical representations. 3. Select model architecture: There are many different types of models to choose from, including recurrent neural networks (RNNs), transformer models, and convolutional neural networks (CNNs). The choice will depend on the specific requirements of the project and the amount of data available. 4. Divide dataset and implement data augmentation: Splitting the data into training, validation, and testing subsets is important for monitoring the performance of the model during training. Data augmentation can be used to artificially increase the size of the dataset and improve the robustness of the model. 5. Train model and monitor progress: This step involves training the model on the training data, using the validation set to monitor progress and adjust hyperparameters as needed. It may be necessary to repeat this process several times until the model is performing well on the validation set. 6. Evaluate model on test set: Once the model is trained, it’s important to evaluate its performance on a separate test set to get an idea of its generalization ability. This can be done by comparing the model’s predictions to the actual outcomes and analyzing the errors. 7. Fine-tune for specific tasks or domains: This step involves further training the model on task-specific data to improve its performance for a particular domain. This can be done through transfer learning, where a pre-trained model is fine-tuned on new data, or through fine-tuning, where the model is trained from scratch on the new data. 8. Create an interface for user input: This involves designing an interface that allows users to input questions or requests, and receive responses from the model. 9. Test in controlled environment: Before deploying the model in a real-world setting, it’s important to test it in a controlled environment and gather feedback from users. This will help identify any errors or biases in the model and provide opportunities for improvement. 10. Continuously monitor and improve performance: Finally, it is important to continuously monitor the performance of the model and make updates and improvements as needed. This may involve retraining the model on new data, fine-tuning hyperparameters, or updating the architecture. |
Assistant: ## To-Do List for Training a Large Language Model for Question Answering **1. Project Scope & Objectives:** * Define project goals and desired functionalities. **2. Data Acquisition & Preprocessing:** * Identify sources for training data and gather a diverse text dataset. **3. Model Selection & Configuration:** * Select an appropriate model architecture based on the task complexity and desired performance. **4. Training & Evaluation:** * Divide the training data into training, validation, and testing subsets. **5. Fine-Tuning & Interface Development:** * Fine-tune the model for specific tasks or domains through transfer learning. **6. Testing & Improvement:** * Test the model in a controlled environment with various input scenarios. **Additional Considerations:** * Set a timeline and budget for the project. **Note:** This list is not exhaustive and may need to be adapted based on the specific project requirements. |
Assistant: Sure, here is a more detailed breakdown of the tasks involved in training a large language model to understand and respond to human questions: **1. Establish Project Scope and Objectives** **2. Gather and Preprocess a Comprehensive/Diverse Text Dataset** **3. Select an Appropriate Model Architecture, Adjust Hyperparameters for Accuracy/Speed** **4. Divide Dataset into Training, Validation, Testing Subsets, Implement Data Augmentation** **5. Train Model, Monitor Progress on Validation Set, Adjust as Needed** **6. Evaluate Model on Test Set, Compare to Benchmarks, Analyze Errors and Biases** **7. Fine-Tune for Specific Tasks or Domains Through Transfer Learning or Fine-Tuning** **8. Create Interface for User Input and Model Response** **9. Test in Controlled Environment, Gather Feedback for Improvement** **10. Continuously Monitor and Improve Performance Through Retraining and Fine-Tuning** These are the steps involved in training a large language model to understand and respond to human questions. Please let me know if you have question. |
Clean up
After you have tested the endpoints, delete the SageMaker inference endpoints and the model to avoid incurring charges.
Conclusion
In this post, we showed you how to get started with Gemma in SageMaker Studio and deploy the model for inference. We also showed you how you can fine tune Gemma models on SageMaker Jumpstart.
Because foundation models are pre-trained, they can help lower training and infrastructure costs and enable customization for your use case. Visit SageMaker JumpStart in SageMaker Studio now to get started.
This guidance is for informational purposes only. You should still perform your own independent assessment, and take measures to ensure that you comply with your own specific quality control practices and standards, and the local rules, laws, regulations, licenses and terms of use that apply to you, your content, and the third-party model referenced in this guidance. AWS has no control or authority over the third-party model referenced in this guidance, and does not make any representations or warranties that the third-party model is secure, virus-free, operational, or compatible with your production environment and standards. AWS does not make any representations, warranties or guarantees that any information in this guidance will result in a particular outcome or result.
About the authors
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
 Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
 Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in future and bring economical and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in future and bring economical and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
 Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He enjoys cooking and going on runs in New York City.
Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He enjoys cooking and going on runs in New York City.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Leave a Reply