
The journey of PGA TOUR’s generative AI virtual assistant, from concept to development to prototype
This is a guest post co-written with Scott Gutterman from the PGA TOUR.
Generative artificial intelligence (generative AI) has enabled new possibilities for building intelligent systems. Recent improvements in Generative AI based large language models (LLMs) have enabled their use in a variety of applications surrounding information retrieval. Given the data sources, LLMs provided tools that would allow us to build a Q&A chatbot in weeks, rather than what may have taken years previously, and likely with worse performance. We formulated a Retrieval-Augmented-Generation (RAG) solution that would allow the PGA TOUR to create a prototype for a future fan engagement platform that could make its data accessible to fans in an interactive fashion in a conversational format.
Using structured data to answer questions requires a way to effectively extract data that’s relevant to a user’s query. We formulated a text-to-SQL approach where by a user’s natural language query is converted to a SQL statement using an LLM. The SQL is run by Amazon Athena to return the relevant data. This data is again provided to an LLM, which is asked to answer the user’s query given the data.
Using text data requires an index that can be used to search and provide relevant context to an LLM to answer a user query. To enable quick information retrieval, we use Amazon Kendra as the index for these documents. When users ask questions, our virtual assistant rapidly searches through the Amazon Kendra index to find relevant information. Amazon Kendra uses natural language processing (NLP) to understand user queries and find the most relevant documents. The relevant information is then provided to the LLM for final response generation. Our final solution is a combination of these text-to-SQL and text-RAG approaches.
In this post we highlight how the AWS Generative AI Innovation Center collaborated with the AWS Professional Services and PGA TOUR to develop a prototype virtual assistant using Amazon Bedrock that could enable fans to extract information about any event, player, hole or shot level details in a seamless interactive manner. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Development: Getting the data ready
As with any data-driven project, performance will only ever be as good as the data. We processed the data to enable the LLM to be able to effectively query and retrieve relevant data.
For the tabular competition data, we focused on a subset of data relevant to the greatest number of user queries and labelled the columns intuitively, such that they would be easier for LLMs to understand. We also created some auxiliary columns to help the LLM understand concepts it might otherwise struggle with. For example, if a golfer shoots one shot less than par (such as makes it in the hole in 3 shots on a par 4 or in 4 shots on a par 5), it is commonly called a birdie. If a user asks, “How many birdies did player X make in last year?”, just having the score and par in the table is not sufficient. As a result, we added columns to indicate common golf terms, such as bogey, birdie, and eagle. In addition, we linked the Competition data with a separate video collection, by joining a column for a video_id, which would allow our app to pull the video associated with a particular shot in the Competition data. We also enabled joining text data to the tabular data, for example adding biographies for each player as a text column. The following figures shows the step-by-step procedure of how a query is processed for the text-to-SQL pipeline. The numbers indicate the series of step to answer a query.
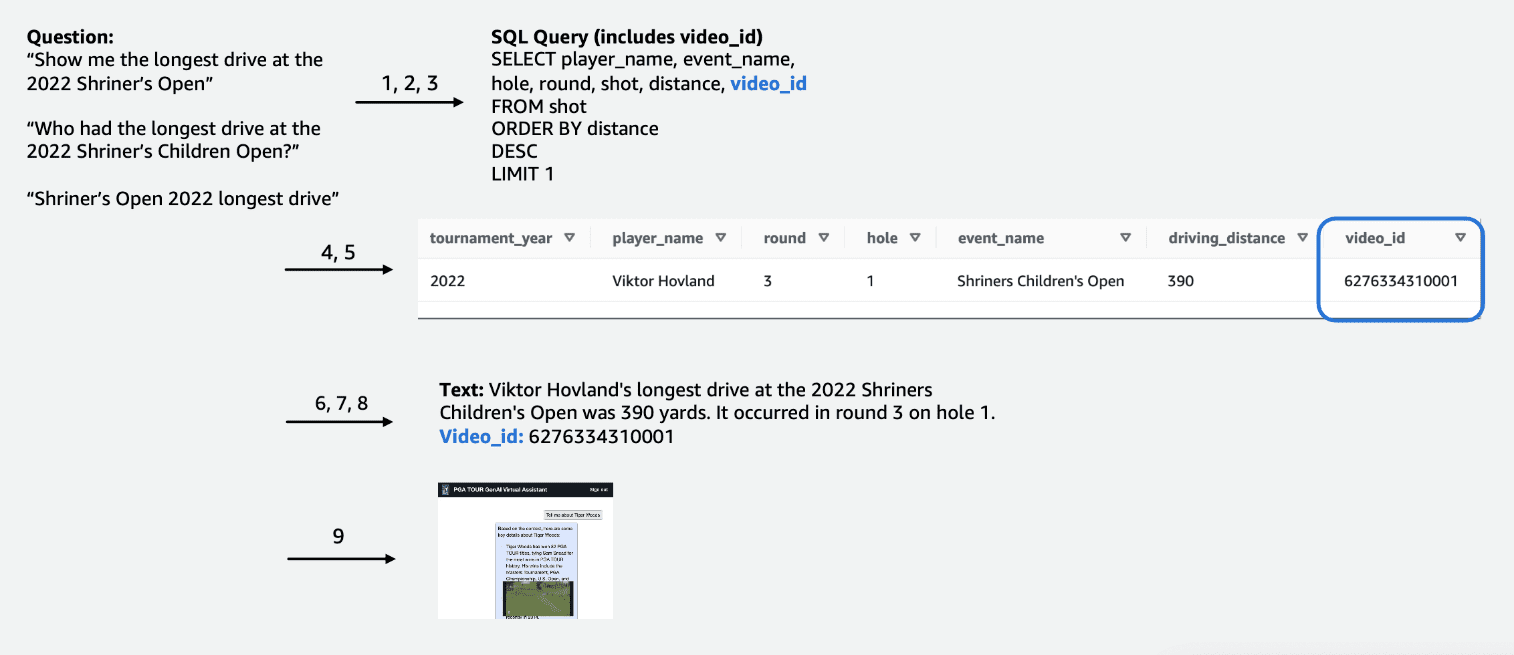
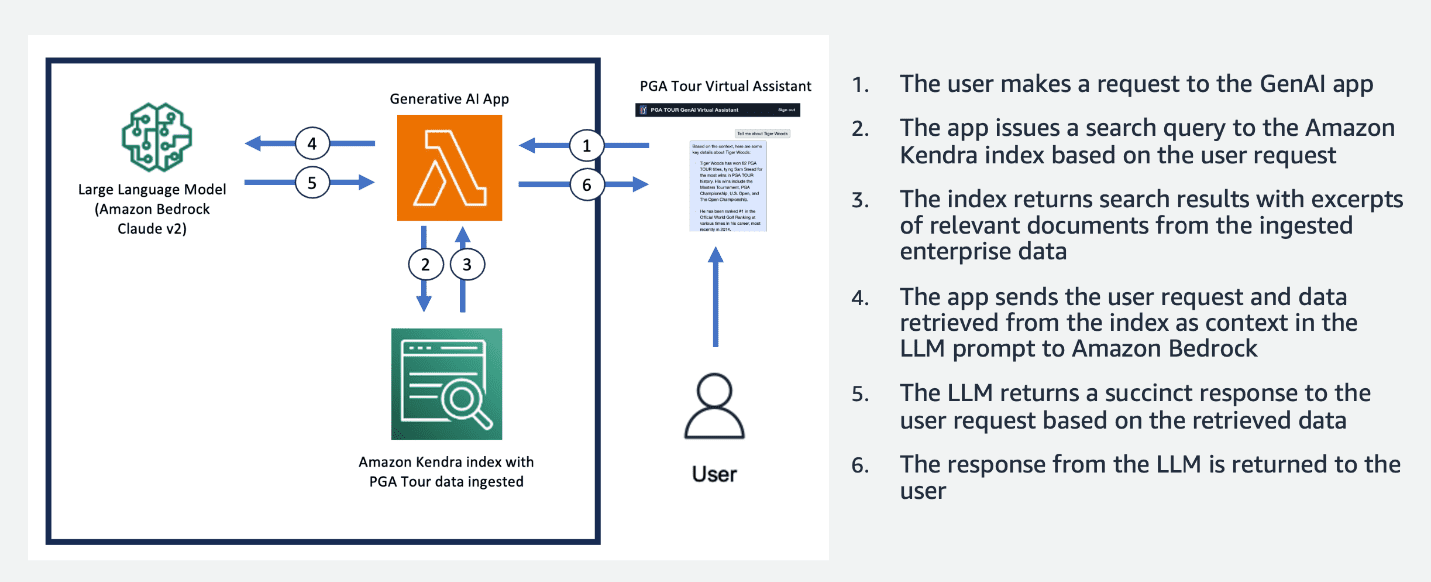
In the following figure we demonstrate our end-to-end pipeline. We use AWS Lambda as our orchestration function responsible for interacting with various data sources, LLMs and error correction based on the user query. Steps 1-8 are similar to what is shown in the proceeding figure. There are slight changes for the unstructured data, which we discuss next.

Text data requires unique processing steps that chunk (or segment) long documents into parts digestible by the LLM, while maintaining topic coherence. We experimented with several approaches and settled on a page-level chunking scheme that aligned well with the format of the Media Guides. We used Amazon Kendra, which is a managed service that takes care of indexing documents, without requiring specification of embeddings, while providing an easy API for retrieval. The following figure illustrates this architecture.
The unified, scalable pipeline we developed allows the PGA TOUR to scale to their full history of data, some of which goes back to the 1800s. It enables future applications that can take live on the course context to create rich real-time experiences.
Development: Evaluating LLMs and developing generative AI applications
We carefully tested and evaluated the first- and third-party LLMs available in Amazon Bedrock to choose the model that is best suited for our pipeline and use case. We selected Anthropic’s Claude v2 and Claude Instant on Amazon Bedrock. For our final structured and unstructured data pipeline, we observe Anthropic’s Claude 2 on Amazon Bedrock generated better overall results for our final data pipeline.
Prompting is a critical aspect of getting LLMs to output text as desired. We spent considerable time experimenting with different prompts for each of the tasks. For example, for the text-to-SQL pipeline we had several fallback prompts, with increasing specificity and gradually simplified table schemas. If a SQL query was invalid and resulted in an error from Athena, we developed an error correction prompt that would pass the error and incorrect SQL to the LLM and ask it to fix it. The final prompt in the text-to-SQL pipeline asks the LLM to take the Athena output, which can be provided in Markdown or CSV format, and provide an answer to the user. For the unstructured text, we developed general prompts to use the context retrieved from Amazon Kendra to answer the user question. The prompt included instructions to use only the information retrieved from Amazon Kendra and not rely on data from the LLM pre-training.
Latency is often a concern with generative AI applications, and it is also the case here. It is especially a concern for text-to-SQL, which requires an initial SQL generation LLM invocation, followed by a response generation LLM invocation. If we’re using a large LLM, such as Anthropic’s Claude V2, this effectively doubles the latency of just one LLM invocation. We experimented with several configurations of large and smaller LLMs to evaluate run time as well as correctness. The following table shows an example for one question is shown below that demonstrates the latency, as well as the generated responses with Anthropic’s Claude V2 and Claude Instant on Amazon Bedrock.

Prototype
In our application, we used a Lambda function to orchestrate the prompt choices and communication between Amazon Athena, Amazon Kendra, and Amazon Bedrock. The virtual assistant features a conversational interface, built with React and the Cloudscape Design System, that uses text and videos to engage with users.
Our virtual assistant can field a wide range of questions about PGA TOUR events, players, statistics, history, and more. For example, when asked about Tony Finau’s longest drives at the Shriners Children’s Open (one of the Signature events of the PGA TOUR), the assistant can query structured data to pull his shot level data. It can extract the exact distance in yards, the round number and the hole during which he achieved this record using the text-to-SQL pipeline. The assistant then interprets this numerical data to generate a final response. The following table contains some example responses.
| Question | Response |
| What was the longest drive hit by Tony Finau in the Shriners Children’s Open? | The longest drive hit by Tony Finau in the Shriners Childrens Open was 382 yards, which he hit during the first round on hole number 4 in 2018. |
| What was the longest drive hit by Collin Morikawa in the Shriners Children’s Open? | Collin Morikawa’s longest drive at the Shriners Childrens Open was 334 yards. This occurred in 2019 during the first round on hole number 15. |
| Did anyone make an ace at the 2022 Shriners Children’s Open? | Yes, Adam Hadwin made a hole-in-one on hole 14 during round 3 of the 2022 Shriners Children’s Open |
The following explainer video highlights a few examples of interacting with the virtual assistant.
In initial testing, our PGA TOUR virtual assistant has shown great promise in improving fan experiences. By blending AI technologies like text-to-SQL, semantic search, and natural language generation, the assistant delivers informative, engaging responses. Fans are empowered to effortlessly access data and narratives that were previously hard to find.
What does the future hold?
As we continue development, we will expand the range of questions our virtual assistant can handle. This will require extensive testing, through collaboration between AWS and the PGA TOUR. Over time, we aim to evolve the assistant into a personalized, omni-channel experience accessible across web, mobile, and voice interfaces.
The establishment of a cloud-based generative AI assistant lets the PGA TOUR present its vast data source to multiple internal and external stakeholders. As the sports generative AI landscape evolves, it enables the creation of new content. For example, you can use AI and machine learning (ML) to surface content fans want to see as they’re watching an event, or as production teams are looking for shots from previous tournaments that match a current event. For example, if Max Homa is getting ready to take his final shot at the PGA TOUR Championship from a spot 20 feet from the pin, the PGA TOUR can use AI and ML to identify and present clips, with AI-generated commentary, of him attempting a similar shot five times previously. This kind of access and data allows a production team to immediately add value to the broadcast or allow a fan to customize the type of data that they want to see.
“The PGA TOUR is the industry leader in using cutting-edge technology to improve the fan experience. AI is at the forefront of our technology stack, where it is enabling us to create a more engaging and interactive environment for fans. This is the beginning of our generative AI journey in collaboration with the AWS Generative AI Innovation Center for a transformational end-to-end customer experience. We are working to leverage Amazon Bedrock and our propriety data to create an interactive experience for PGA TOUR fans to find information of interest about an event, player, stats, or other content in an interactive fashion.”
– Scott Gutterman, SVP of Broadcast and Digital Properties at PGA TOUR.
Conclusion
The project we discussed in this post exemplifies how structured and unstructured data sources can be fused using AI to create next-generation virtual assistants. For sports organizations, this technology enables more immersive fan engagement and unlocks internal efficiencies. The data intelligence we surface helps PGA TOUR stakeholders like players, coaches, officials, partners, and media make informed decisions faster. Beyond sports, our methodology can be replicated across any industry. The same principles apply to building assistants that engage customers, employees, students, patients, and other end-users. With thoughtful design and testing, virtually any organization can benefit from an AI system that contextualizes their structured databases, documents, images, videos, and other content.
If you’re interested in implementing similar functionalities, consider using Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock as an alternative, fully AWS-managed solution. This approach could further investigate providing intelligent automation and data search abilities through customizable agents. These agents could potentially transform user application interactions to be more natural, efficient, and effective.
About the authors
 Scott Gutterman is the SVP of Digital Operations for the PGA TOUR. He is responsible for the TOUR’s overall digital operations, product development and is driving their GenAI strategy.
Scott Gutterman is the SVP of Digital Operations for the PGA TOUR. He is responsible for the TOUR’s overall digital operations, product development and is driving their GenAI strategy.
 Ahsan Ali is an Applied Scientist at the Amazon Generative AI Innovation Center, where he works with customers from different domains to solve their urgent and expensive problems using Generative AI.
Ahsan Ali is an Applied Scientist at the Amazon Generative AI Innovation Center, where he works with customers from different domains to solve their urgent and expensive problems using Generative AI.
 Tahin Syed is an Applied Scientist with the Amazon Generative AI Innovation Center, where he works with customers to help realize business outcomes with generative AI solutions. Outside of work, he enjoys trying new food, traveling, and teaching taekwondo.
Tahin Syed is an Applied Scientist with the Amazon Generative AI Innovation Center, where he works with customers to help realize business outcomes with generative AI solutions. Outside of work, he enjoys trying new food, traveling, and teaching taekwondo.
 Grace Lang is an Associate Data & ML engineer with AWS Professional Services. Driven by a passion for overcoming tough challenges, Grace helps customers achieve their goals by developing machine learning powered solutions.
Grace Lang is an Associate Data & ML engineer with AWS Professional Services. Driven by a passion for overcoming tough challenges, Grace helps customers achieve their goals by developing machine learning powered solutions.
 Jae Lee is a Senior Engagement Manager in ProServe’s M&E vertical. She leads and delivers complex engagements, exhibits strong problem solving skill sets, manages stakeholder expectations, and curates executive level presentations. She enjoys working on projects focused on sports, generative AI, and customer experience.
Jae Lee is a Senior Engagement Manager in ProServe’s M&E vertical. She leads and delivers complex engagements, exhibits strong problem solving skill sets, manages stakeholder expectations, and curates executive level presentations. She enjoys working on projects focused on sports, generative AI, and customer experience.
 Karn Chahar is a Security Consultant with the shared delivery team at AWS. He is a technology enthusiast who enjoys working with customers to solve their security challenges and to improve their security posture in the cloud.
Karn Chahar is a Security Consultant with the shared delivery team at AWS. He is a technology enthusiast who enjoys working with customers to solve their security challenges and to improve their security posture in the cloud.
 Mike Amjadi is a Data & ML Engineer with AWS ProServe focused on enabling customers to maximize value from data. He specializes in designing, building, and optimizing data pipelines following well-architected principles. Mike is passionate about using technology to solve problems and is committed to delivering the best results for our customers.
Mike Amjadi is a Data & ML Engineer with AWS ProServe focused on enabling customers to maximize value from data. He specializes in designing, building, and optimizing data pipelines following well-architected principles. Mike is passionate about using technology to solve problems and is committed to delivering the best results for our customers.
 Vrushali Sawant is a Front End Engineer with Proserve. She is highly skilled in creating responsive websites. She loves working with customers, understanding their requirements and providing them with scalable, easy to adopt UI/UX solutions.
Vrushali Sawant is a Front End Engineer with Proserve. She is highly skilled in creating responsive websites. She loves working with customers, understanding their requirements and providing them with scalable, easy to adopt UI/UX solutions.
 Neelam Patel is a Customer Solutions Manager at AWS, leading key Generative AI and cloud modernization initiatives. Neelam works with key executives and technology owners to address their cloud transformation challenges and helps customers maximize the benefits of cloud adoption. She has an MBA from Warwick Business School, UK and a Bachelors in Computer Engineering, India.
Neelam Patel is a Customer Solutions Manager at AWS, leading key Generative AI and cloud modernization initiatives. Neelam works with key executives and technology owners to address their cloud transformation challenges and helps customers maximize the benefits of cloud adoption. She has an MBA from Warwick Business School, UK and a Bachelors in Computer Engineering, India.
 Dr. Murali Baktha is Global Golf Solution Architect at AWS, spearheads pivotal initiatives involving Generative AI, data analytics and cutting-edge cloud technologies. Murali works with key executives and technology owners to understand customer’s business challenges and designs solutions to address those challenges. He has an MBA in Finance from UConn and a doctorate from Iowa State University.
Dr. Murali Baktha is Global Golf Solution Architect at AWS, spearheads pivotal initiatives involving Generative AI, data analytics and cutting-edge cloud technologies. Murali works with key executives and technology owners to understand customer’s business challenges and designs solutions to address those challenges. He has an MBA in Finance from UConn and a doctorate from Iowa State University.
 Mehdi Noor is an Applied Science Manager at Generative Ai Innovation Center. With a passion for bridging technology and innovation, he assists AWS customers in unlocking the potential of Generative AI, turning potential challenges into opportunities for rapid experimentation and innovation by focusing on scalable, measurable, and impactful uses of advanced AI technologies, and streamlining the path to production.
Mehdi Noor is an Applied Science Manager at Generative Ai Innovation Center. With a passion for bridging technology and innovation, he assists AWS customers in unlocking the potential of Generative AI, turning potential challenges into opportunities for rapid experimentation and innovation by focusing on scalable, measurable, and impactful uses of advanced AI technologies, and streamlining the path to production.
Leave a Reply