
Building scalable, secure, and reliable RAG applications using Knowledge Bases for Amazon Bedrock
Generative artificial intelligence (AI) has gained significant momentum with organizations actively exploring its potential applications. As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. However, to unlock the long-term success and viability of these AI-powered solutions, it is crucial to align them with well-established architectural principles.
The AWS Well-Architected Framework provides best practices and guidelines for designing and operating reliable, secure, efficient, and cost-effective systems in the cloud. Aligning generative AI applications with this framework is essential for several reasons, including providing scalability, maintaining security and privacy, achieving reliability, optimizing costs, and streamlining operations. Embracing these principles is critical for organizations seeking to use the power of generative AI and drive innovation.
This post explores the new enterprise-grade features for Knowledge Bases on Amazon Bedrock and how they align with the AWS Well-Architected Framework. With Knowledge Bases for Amazon Bedrock, you can quickly build applications using Retrieval Augmented Generation (RAG) for use cases like question answering, contextual chatbots, and personalized search.
Here are some features which we will cover:
- AWS CloudFormation support
- Private network policies for Amazon OpenSearch Serverless
- Multiple S3 buckets as data sources
- Service Quotas support
- Hybrid search, metadata filters, custom prompts for the
RetreiveAndGenerateAPI, and maximum number of retrievals.
AWS Well-Architected design principles
RAG-based applications built using Knowledge Bases for Amazon Bedrock can greatly benefit from following the AWS Well-Architected Framework. This framework has six pillars that help organizations make sure their applications are secure, high-performing, resilient, efficient, cost-effective, and sustainable:
- Operational Excellence – Well-Architected principles streamline operations, automate processes, and enable continuous monitoring and improvement of generative AI app performance.
- Security – Implementing strong access controls, encryption, and monitoring helps secure sensitive data used in your organization’s knowledge base and prevent misuse of generative AI.
- Reliability – Well-Architected principles guide the design of resilient and fault-tolerant systems, providing consistent value delivery to users.
- Performance Optimization – Choosing the appropriate resources, implementing caching strategies, and proactively monitoring performance metrics ensure that applications deliver fast and accurate responses, leading to optimal performance and an enhanced user experience.
- Cost Optimization – Well-Architected guidelines assist in optimizing resource usage, using cost-saving services, and monitoring expenses, resulting in long-term viability of generative AI projects.
- Sustainability – Well-Architected principles promote efficient resource utilization and minimizing carbon footprints, addressing the environmental impact of growing generative AI usage.
By aligning with the Well-Architected Framework, organizations can effectively build and manage enterprise-grade RAG applications using Knowledge Bases for Amazon Bedrock. Now, let’s dive deep into the new features launched within Knowledge Bases for Amazon Bedrock.
AWS CloudFormation support
For organizations building RAG applications, it’s important to provide efficient and effective operations and consistent infrastructure across different environments. This can be achieved by implementing practices such as automating deployment processes. To accomplish this, Knowledge Bases for Amazon Bedrock now offers support for AWS CloudFormation.
With AWS CloudFormation and the AWS Cloud Development Kit (AWS CDK), you can now create, update, and delete knowledge bases and associated data sources. Adopting AWS CloudFormation and the AWS CDK for managing knowledge bases and associated data sources not only streamlines the deployment process, but also promotes adherence to the Well-Architected principles. By performing operations (applications, infrastructure) as code, you can provide consistent and reliable deployments in multiple AWS accounts and AWS Regions, and maintain versioned and auditable infrastructure configurations.
The following is a sample CloudFormation script in JSON format for creating and updating a knowledge base in Amazon Bedrock:
Type specifies a knowledge base as a resource in a top-level template. Minimally, you must specify the following properties:
- Name – Specify a name for the knowledge base.
- RoleArn – Specify the Amazon Resource Name (ARN) of the AWS Identity and Access Management (IAM) role with permissions to invoke API operations on the knowledge base. For more information, see Create a service role for Knowledge bases for Amazon Bedrock.
- KnowledgeBaseConfiguration – Specify the embeddings configuration of the knowledge base. The following sub-properties are required:
- Type – Specify the value
VECTOR. - VectorKnowledgeBaseConfiguration – Contains details about the model used to create vector embeddings for the knowledge base.
- Type – Specify the value
- StorageConfiguration – Specify information about the vector store in which the data source is stored. The following sub-properties are required:
- Type – Specify the vector store service that you are using.
- You would also need to select one of the vector stores supported by Knowledge Bases such OpenSearchServerless, Pinecone or Amazon PostgreSQL and provide configuration for the selected vector store.
For details on all the fields and providing configuration of various vector stores supported by Knowledge Bases for Amazon Bedrock, refer to AWS::Bedrock::KnowledgeBase.
Redis Enterprise Cloud vector stores are not supported as of this writing in AWS CloudFormation. For latest information, please refer to the documentation above.
After you create a knowledge base, you need to create a data source from the Amazon Simple Storage Service (Amazon S3) bucket containing the files for your knowledge base. It calls the CreateDataSource and DeleteDataSource APIs.
The following is the sample CloudFormation script in JSON format:
Type specifies a data source as a resource in a top-level template. Minimally, you must specify the following properties:
- Name – Specify a name for the data source.
- KnowledgeBaseId – Specify the ID of the knowledge base for the data source to belong to.
- DataSourceConfiguration – Specify information about the S3 bucket containing the data source. The following sub-properties are required:
- Type – Specify the value S3.
- S3Configuration – Contains details about the configuration of the S3 object containing the data source.
- VectorIngestionConfiguration – Contains details about how to ingest the documents in a data source. You need to provide “ChunkingConfiguration” where you can define your chunking strategy.
- ServerSideEncryptionConfiguration – Contains the configuration for server-side encryption, where you can provide the Amazon Resource Name (ARN) of the AWS KMS key used to encrypt the resource.
For more information about setting up data sources in Amazon Bedrock, see Set up a data source for your knowledge base.
Note: You cannot change the chunking configuration after you create the data source.
The CloudFormation template allows you to define and manage your knowledge base resources using infrastructure as code (IaC). By automating the setup and management of the knowledge base, you can provide a consistent infrastructure across different environments. This approach aligns with the Operational Excellence pillar, which emphasizes performing operations as code. By treating your entire workload as code, you can automate processes, create consistent responses to events, and ultimately reduce human errors.
Private network policies for Amazon OpenSearch Serverless
For companies building RAG applications, it’s critical that the data remains secure and the network traffic does not go to public internet. To support this, Knowledge Bases for Amazon Bedrock now supports private network policies for Amazon OpenSearch Serverless.
Knowledge Bases for Amazon Bedrock provides an option for using OpenSearch Serverless as a vector store. You can now access OpenSearch Serverless collections that have a private network policy, which further enhances the security posture for your RAG application. To achieve this, you need to create an OpenSearch Serverless collection and configure it for private network access. First, create a vector index within the collection to store the embeddings. Then, while creating the collection, set Network access settings to Private and specify the VPC endpoint for access. Importantly, you can now provide private network access to OpenSearch Serverless collections specifically for Amazon Bedrock. To do this, select AWS service private access and specify bedrock.amazonaws.com as the service.
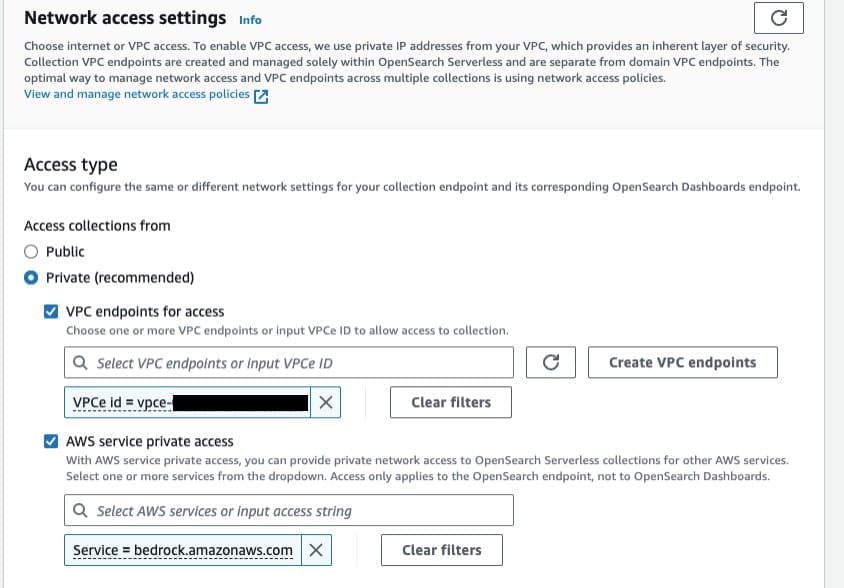
This private network configuration makes sure that your embeddings are stored securely and are only accessible by Amazon Bedrock, enhancing the overall security and privacy of your knowledge bases. It aligns closely with the Security Pillar of controlling traffic at all layers, because all network traffic is kept within the AWS backbone with these settings.
So far, we have explored the automation of creating, deleting, and updating knowledge base resources and the enhanced security through private network policies for OpenSearch Serverless to store vector embeddings securely. Now, let’s understand how to build more reliable, comprehensive, and cost-optimized RAG applications.
Multiple S3 buckets as data sources
Knowledge Bases for Amazon Bedrock now supports adding multiple S3 buckets as data sources within single knowledge base, including cross-account access. This enhancement increases the knowledge base’s comprehensiveness and accuracy by allowing users to aggregate and use information from various sources seamlessly.
The following are key features:
- Multiple S3 buckets – Knowledge Bases for Amazon Bedrock can now incorporate data from multiple S3 buckets, enabling users to combine and use information from different sources effortlessly. This feature promotes data diversity and makes sure that relevant information is readily available for RAG-based applications.
- Cross-account data access – Knowledge Bases for Amazon Bedrock supports the configuration of S3 buckets as data sources across different accounts. You can provide the necessary credentials to access these data sources, expanding the range of information that can be incorporated into their knowledge bases.
- Efficient data management – When setting up a data source in a knowledge base, you can specify whether the data belonging to that data source should be retained or deleted if the data source is deleted. This feature ensures that your knowledge base remains up-to-date and free from obsolete or irrelevant data, maintaining the integrity and accuracy of the RAG process.
By supporting multiple S3 buckets as data sources, the need for creating multiple knowledge bases or redundant data copies is eliminated, thereby optimizing cost and promoting cloud financial management. Furthermore, the cross-account access capabilities enable the development of resilient architectures, aligning with the Reliability pillar of the AWS Well-Architected Framework, providing high availability and fault tolerance.
Other recently announced features for Knowledge Bases
To further enhance the reliability of your RAG application, Knowledge Bases for Amazon Bedrock now extends support for Service Quotas. This feature provides a single pane of glass to view applied AWS quota values and usage. For example, you now have quick access to information such as the allowed number of `RetrieveAndGenerate API requests per second.
This feature allows you to effectively manage resource quotas, prevent overprovisioning, and limit API request rates to safeguard services from potential abuse.
You can also enhance your application’s performance by using recently announced features like hybrid search, filtering based on metadata, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals. These features collectively improve the accuracy, relevance, and consistency of generated responses, and align with the Performance Efficiency pillar of the AWS Well-Architected Framework.
Knowledge Bases for Amazon Bedrock aligns with the Sustainability pillar of the AWS Well-Architected Framework by using managed services and optimizing resource utilization. As a fully managed service, Knowledge Bases for Amazon Bedrock removes the burden of provisioning, managing, and scaling the underlying infrastructure, thereby reducing the environmental impact associated with operating and maintaining these resources.
Additionally, by aligning with the AWS Well-Architected principles, organizations can design and operate their RAG applications in a sustainable manner. Practices such as automating deployments through AWS CloudFormation, implementing private network policies for secure data access, and using efficient services like OpenSearch Serverless contribute to minimizing the environmental impact of these workloads.
Overall, Knowledge Bases for Amazon Bedrock, combined with the AWS Well-Architected Framework, empowers organizations to build scalable, secure, and reliable RAG applications while prioritizing environmental sustainability through efficient resource utilization and the adoption of managed services.
Conclusion
The new enterprise-grade features, such as AWS CloudFormation support, private network policies, the ability to use multiple S3 buckets as data sources, and support for Service Quotas, make it straightforward to build scalable, secure, and reliable RAG applications with Knowledge Bases for Amazon Bedrock. Using AWS managed services and following Well-Architected best practices allows organizations to focus on delivering innovative generative AI solutions while providing operational excellence, robust security, and efficient resource utilization. As you build applications on AWS, aligning RAG applications with the AWS Well-Architected Framework provides a solid foundation for building enterprise-grade solutions that drive business value while adhering to industry standards.
For additional resources, refer to the following:
- Knowledge bases for Amazon Bedrock
- Use RAG to improve responses in generative AI application
- Amazon Bedrock Knowledge Base – Samples for building RAG workflows
About the authors
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
 Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
 Pallavi Nargund is a Principal Solutions Architect at AWS. In her role as a cloud technology enabler, she works with customers to understand their goals and challenges, and give prescriptive guidance to achieve their objective with AWS offerings. She is passionate about women in technology and is a core member of Women in AI/ML at Amazon. She speaks at internal and external conferences such as AWS re:Invent, AWS Summits, and webinars. Outside of work she enjoys volunteering, gardening, cycling and hiking.
Pallavi Nargund is a Principal Solutions Architect at AWS. In her role as a cloud technology enabler, she works with customers to understand their goals and challenges, and give prescriptive guidance to achieve their objective with AWS offerings. She is passionate about women in technology and is a core member of Women in AI/ML at Amazon. She speaks at internal and external conferences such as AWS re:Invent, AWS Summits, and webinars. Outside of work she enjoys volunteering, gardening, cycling and hiking.
Leave a Reply