
Boost employee productivity with automated meeting summaries using Amazon Transcribe, Amazon SageMaker, and LLMs from Hugging Face
The prevalence of virtual business meetings in the corporate world, largely accelerated by the COVID-19 pandemic, is here to stay. Based on a survey conducted by American Express in 2023, 41% of business meetings are expected to take place in hybrid or virtual format by 2024. Attending multiple meetings daily and keeping track of all ongoing topics gets increasingly more difficult to manage over time. This can have a negative impact in many ways, from delayed project timelines to loss of customer trust. Writing meeting summaries is the usual remedy to overcome this challenge, but it disturbs the focus required to listen to ongoing conversations.
A more efficient way to manage meeting summaries is to create them automatically at the end of a call through the use of generative artificial intelligence (AI) and speech-to-text technologies. This allows attendees to focus solely on the conversation, knowing that a transcript will be made available automatically at the end of the call.
This post presents a solution to automatically generate a meeting summary from a recorded virtual meeting (for example, using Amazon Chime) with several participants. The recording is transcribed to text using Amazon Transcribe and then processed using Amazon SageMaker Hugging Face containers to generate the meeting summary. The Hugging Face containers host a large language model (LLM) from the Hugging Face Hub.
If you prefer to generate post call recording summaries with Amazon Bedrock rather than Amazon SageMaker, checkout this Bedrock sample solution. For a generative AI powered Live Meeting Assistant that creates post call summaries, but also provides live transcripts, translations, and contextual assistance based on your own company knowledge base, see our new LMA solution.
Solution overview
The entire infrastructure of the solution is provisioned using the AWS Cloud Development Kit (AWS CDK), which is an infrastructure as code (IaC) framework to programmatically define and deploy AWS resources. The framework provisions resources in a safe, repeatable manner, allowing for a significant acceleration of the development process.
Amazon Transcribe is a fully managed service that seamlessly runs automatic speech recognition (ASR) workloads in the cloud. The service allows for simple audio data ingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Amazon Transcribe’s new ASR foundation model supports 100+ language variants. In this post, we use the speaker diarization feature, which enables Amazon Transcribe to differentiate between a maximum of 10 unique speakers and label a conversation accordingly.
Hugging Face is an open-source machine learning (ML) platform that provides tools and resources for the development of AI projects. Its key offering is the Hugging Face Hub, which hosts a vast collection of over 200,000 pre-trained models and 30,000 datasets. The AWS partnership with Hugging Face allows a seamless integration through SageMaker with a set of Deep Learning Containers (DLCs) for training and inference, and Hugging Face estimators and predictors for the SageMaker Python SDK.
Generative AI CDK Constructs, an open-source extension of AWS CDK, provides well-architected multi-service patterns to quickly and efficiently create repeatable infrastructure required for generative AI projects on AWS. For this post, we illustrate how it simplifies the deployment of foundation models (FMs) from Hugging Face or Amazon SageMaker JumpStart with SageMaker real-time inference, which provides persistent and fully managed endpoints to host ML models. They are designed for real-time, interactive, and low-latency workloads and provide auto scaling to manage load fluctuations. For all languages that are supported by Amazon Transcribe, you can find FMs from Hugging Face supporting summarization in corresponding languages
The following diagram depicts the automated meeting summarization workflow.
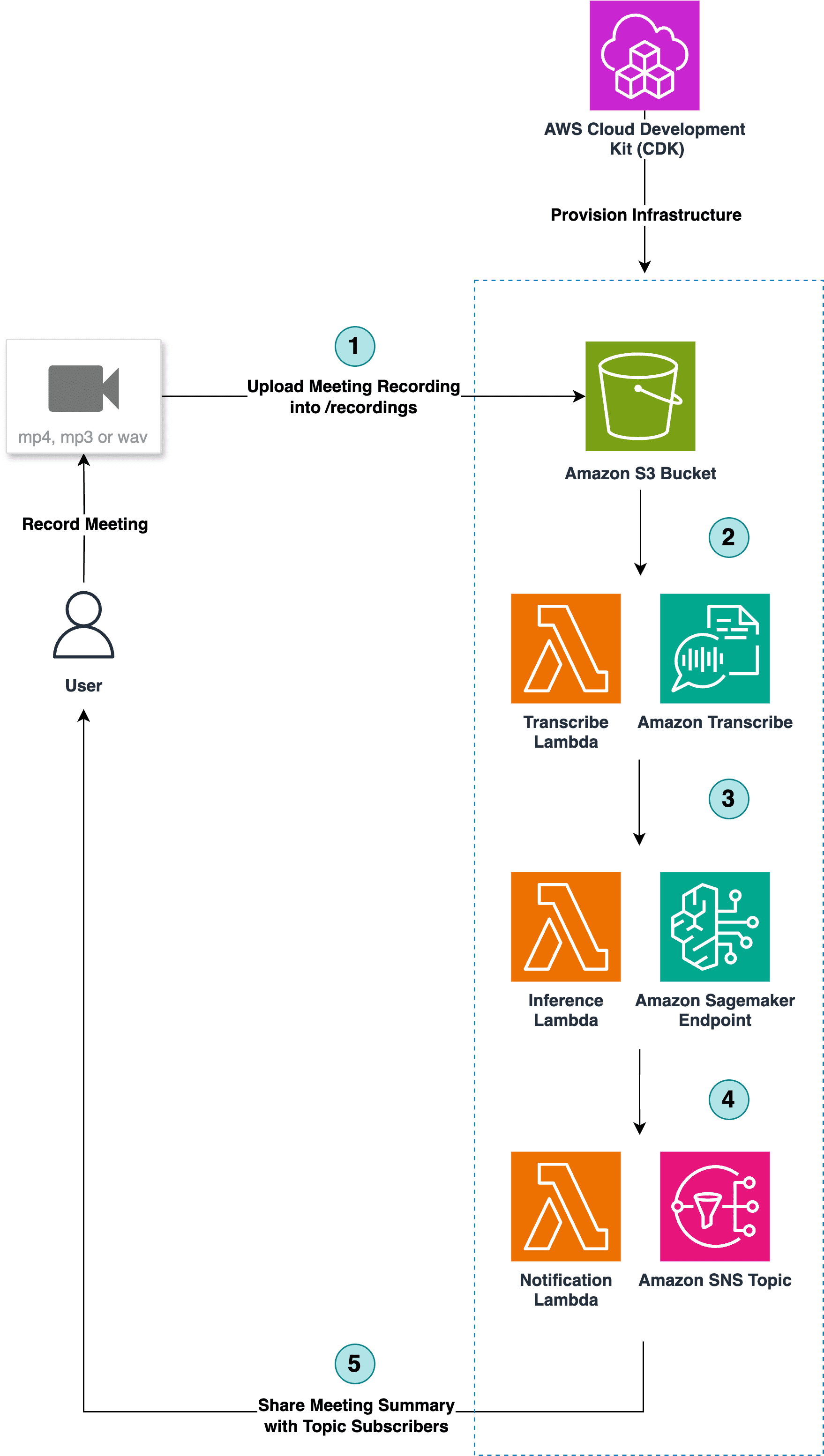
The workflow consists of the following steps:
- The user uploads the meeting recording as an audio or video file to the project’s Amazon Simple Storage Service (Amazon S3) bucket, in the
/recordingsfolder. - Every time a new recording is uploaded to this folder, an AWS Lambda Transcribe function is invoked and initiates an Amazon Transcribe job that converts the meeting recording into text. Transcripts are then stored in the project’s S3 bucket under
/transcriptions/TranscribeOutput/. - This triggers the Inference Lambda function, which preprocesses the transcript file into an adequate format for ML inference, stores it in the project’s S3 bucket under the prefix
/summaries/InvokeInput/processed-TranscribeOutput/, and invokes a SageMaker endpoint. The endpoint hosts the Hugging Face model that summarizes the processed transcript. The summary is loaded into the S3 bucket under the prefix/summaries. Note that the prompt template used in this example includes a single instruction, however for more sophisticated requirements the template can be easily extended to tailor the solution to your own use case. - This S3 event triggers the Notification Lambda function, which pushes the summary to an Amazon Simple Notification Service (Amazon SNS) topic.
- All subscribers of the SNS topic (such as meeting attendees) receive the summary in their email inbox.
In this post, we deploy the Mistral 7B Instruct, an LLM available in the Hugging Face Model Hub, to a SageMaker endpoint to perform the summarization tasks. Mistral 7B Instruct is developed by Mistral AI. It is equipped with over 7 billion parameters, enabling it to process and generate text based on user instructions. It has been trained on a wide-ranging corpus of text data to understand various contexts and nuances of language. The model is designed to perform tasks such as answering questions, summarizing information, and creating content, among others, by following specific prompts given by users. Its effectiveness is measured through metrics like perplexity, accuracy, and F1 score, and it is fine-tuned to respond to instructions with relevant and coherent text outputs.
Prerequisites
To follow along with this post, you should have the following prerequisites:
- Python version greater than 3.9
- AWS CDK version 2.0
Deploy the solution
To deploy the solution in your own AWS account, refer to the GitHub repository to access the full source code of the AWS CDK project in Python:
If you are deploying AWS CDK assets for the first time in your AWS account and the AWS Region you specified, you need to run the bootstrap command first. It sets up the baseline AWS resources and permissions required for AWS CDK to deploy AWS CloudFormation stacks in a given environment:
Finally, run the following command to deploy the solution. Specify the summary’s recipient mail address in the SubscriberEmailAddress parameter:
Test the solution
We have provided a few sample meeting recordings in the data folder of the project repository. You can upload the test.mp4 recording into the project’s S3 bucket under the /recordings folder. The summary will be saved in Amazon S3 and sent to the subscriber. The end-to-end duration is approximately 2 minutes given an input of approximately 250 tokens.
The following figure shows the input conversation and output summary.
![]()
Limitations
This solution has the following limitations:
- The model provides high-accuracy completions for English language. You can use other languages such as Spanish, French, or Portuguese, but the quality of the completions may degrade. You can find other Hugging Face models that are better suited for other languages.
- The model used in this post is limited by a context length of approximately 8,000 tokens, which equates to approximately 6,000 words. If a larger context length is required, you can replace the model by referencing the new model ID in the respective AWS CDK construct.
- Like other LLMs, Mistral 7B Instruct may hallucinate, generating content that strays from factual reality or includes fabricated information.
- The format of the recordings must be either .mp4, .mp3, or .wav.
Clean up
To delete the deployed resources and stop incurring charges, run the following command:
Alternatively, to use the AWS Management Console, complete the following steps:
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Select the stack called Text-summarization-Infrastructure-stack and choose Delete.
Conclusion
In this post, we proposed an architecture pattern to automatically transform your meeting recordings into insightful conversation summaries. This workflow showcases how the AWS Cloud and Hugging Face can help you accelerate with your generative AI application development by orchestrating a combination of managed AI services such as Amazon Transcribe, and externally sourced ML models from the Hugging Face Hub such as those from Mistral AI.
If you are eager to learn more about how conversation summaries can apply to a contact center environment, you can deploy this technique in our suite of solutions for Live Call Analytics and Post Call Analytics.
References
Mistral 7B release post, by Mistral AI
Our team
This post has been created by AWS Professional Services, a global team of experts that can help realize desired business outcomes when using the AWS Cloud. We work together with your team and your chosen member of the AWS Partner Network (APN) to implement your enterprise cloud computing initiatives. Our team provides assistance through a collection of offerings that help you achieve specific outcomes related to enterprise cloud adoption. We also deliver focused guidance through our global specialty practices, which cover a variety of solutions, technologies, and industries.
About the Authors
 Gabriel Rodriguez Garcia is a Machine Learning engineer at AWS Professional Services in Zurich. In his current role, he has helped customers achieve their business goals on a variety of ML use cases, ranging from setting up MLOps inference pipelines to developing a fraud detection application. Whenever he is not working, he enjoys doing physical activities, listening to podcasts, or reading books.
Gabriel Rodriguez Garcia is a Machine Learning engineer at AWS Professional Services in Zurich. In his current role, he has helped customers achieve their business goals on a variety of ML use cases, ranging from setting up MLOps inference pipelines to developing a fraud detection application. Whenever he is not working, he enjoys doing physical activities, listening to podcasts, or reading books.
 Jahed Zaïdi is an AI & Machine Learning specialist at AWS Professional Services in Paris. He is a builder and trusted advisor to companies across industries, helping businesses innovate faster and on a larger scale with technologies ranging from generative AI to scalable ML platforms. Outside of work, you will find Jahed discovering new cities and cultures, and enjoying outdoor activities.
Jahed Zaïdi is an AI & Machine Learning specialist at AWS Professional Services in Paris. He is a builder and trusted advisor to companies across industries, helping businesses innovate faster and on a larger scale with technologies ranging from generative AI to scalable ML platforms. Outside of work, you will find Jahed discovering new cities and cultures, and enjoying outdoor activities.
 Mateusz Zaremba is a DevOps Architect at AWS Professional Services. Mateusz supports customers at the intersection of machine learning and DevOps specialization, helping them to bring value efficiently and securely. Beyond tech, he is an aerospace engineer and avid sailor.
Mateusz Zaremba is a DevOps Architect at AWS Professional Services. Mateusz supports customers at the intersection of machine learning and DevOps specialization, helping them to bring value efficiently and securely. Beyond tech, he is an aerospace engineer and avid sailor.
 Kemeng Zhang is currently working at AWS Professional Services in Zurich, Switzerland, with a specialization in AI/ML. She has been part of multiple NLP projects, from behavioral change in digital communication to fraud detection. Apart from that, she is interested in UX design and playing cards.
Kemeng Zhang is currently working at AWS Professional Services in Zurich, Switzerland, with a specialization in AI/ML. She has been part of multiple NLP projects, from behavioral change in digital communication to fraud detection. Apart from that, she is interested in UX design and playing cards.
Leave a Reply