
Build a Hugging Face text classification model in Amazon SageMaker JumpStart
Amazon SageMaker JumpStart provides a suite of built-in algorithms, pre-trained models, and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning. They can process various types of input data, including image, text, and tabular.
This post introduces using the text classification and fill-mask models available on Hugging Face in SageMaker JumpStart for text classification on a custom dataset. We also demonstrate performing real-time and batch inference for these models. This supervised learning algorithm supports transfer learning for all pre-trained models available on Hugging Face. It takes a piece of text as input and outputs the probability for each of the class labels. You can fine-tune these pre-trained models using transfer learning even when a large corpus of text isn’t available. It’s available in the SageMaker JumpStart UI in Amazon SageMaker Studio. You can also use it through the SageMaker Python SDK, as demonstrated in the example notebook Introduction to SageMaker HuggingFace – Text Classification.
Solution overview
Text classification with Hugging Face in SageMaker provides transfer learning on all pre-trained models available on Hugging Face. According to the number of class labels in the training data, a classification layer is attached to the pre-trained Hugging Face model. Then either the whole network, including the pre-trained model, or only the top classification layer can be fine-tuned on the custom training data. In this transfer learning mode, training can be achieved even with a smaller dataset.
In this post, we demonstrate how to do the following:
- Use the new Hugging Face text classification algorithm
- Perform inference with the Hugging Face text classification algorithm
- Fine-tune the pre-trained model on a custom dataset
- Perform batch inference with the Hugging Face text classification algorithm
Prerequisites
Before you run the notebook, you must complete some initial setup steps. Let’s set up the SageMaker execution role so it has permissions to run AWS services on your behalf:
Run inference on the pre-trained model
SageMaker JumpStart support inference for any text classification model available through Hugging Face. The model can be hosted for inference and support text as the application/x-text content type. This will not only allow you to use a set of pre-trained models, but also enable you to choose other classification tasks.
The output contains the probability values, class labels for all classes, and the predicted label corresponding to the class index with the highest probability encoded in JSON format. The model processes a single string per request and outputs only one line. The following is an example of a JSON format response:
If accept is set to application/json, then the model only outputs probabilities. For more details on training and inference, see the sample notebook.
You can run inference on the text classification model by passing the model_id in the environment variable while creating the object of the Model class. See the following code:
Fine-tune the pre-trained model on a custom dataset
You can fine-tune each of the pre-trained fill-mask or text classification models to any given dataset made up of text sentences with any number of classes. The pretrained model attaches a classification layer to the text embedding model and initializes the layer parameters to random values. The output dimension of the classification layer is determined based on the number of classes detected in the input data. The objective is to minimize classification errors on the input data. Then you can deploy the fine-tuned model for inference.
The following are the instructions for how the training data should be formatted for input to the model:
- Input – A directory containing a
data.csvfile. Each row of the first column should have an integer class label between 0 and the number of classes. Each row of the second column should have the corresponding text data. - Output – A fine-tuned model that can be deployed for inference or further trained using incremental training.
The following is an example of an input CSV file. The file should not have any header. The file should be hosted in an Amazon Simple Storage Service (Amazon S3) bucket with a path similar to the following: s3://bucket_name/input_directory/. The trailing / is required.
The algorithm also supports transfer learning for Hugging Face pre-trained models. Each model is identified by a unique model_id. The following example shows how to fine-tune a BERT base model identified by model_id=huggingface-tc-bert-base-cased on a custom training dataset. The pre-trained model tarballs have been pre-downloaded from Hugging Face and saved with the appropriate model signature in S3 buckets, such that the training job runs in network isolation.
For transfer learning on your custom dataset, you might need to change the default values of the training hyperparameters. You can fetch a Python dictionary of these hyperparameters with their default values by calling hyperparameters.retrieve_default, update them as needed, and then pass them to the Estimator class. The hyperparameter Train_only_top_layer defines which model parameters change during the fine-tuning process. If train_only_top_layer is True, parameters of the classification layers change and the rest of the parameters remain constant during the fine-tuning process. If train_only_top_layer is False, all parameters of the model are fine-tuned. See the following code:
For this use case, we provide SST2 as a default dataset for fine-tuning the models. The dataset contains positive and negative movie reviews. It has been downloaded from TensorFlow under the Apache 2.0 License. The following code provides the default training dataset hosted in S3 buckets:
We create an Estimator object by providing the model_id and hyperparameters values as follows:
To launch the SageMaker training job for fine-tuning the model, call .fit on the object of the Estimator class, while passing the S3 location of the training dataset:
You can view performance metrics such as training loss and validation accuracy/loss through Amazon CloudWatch while training. You can also fetch these metrics and analyze them using TrainingJobAnalytics:
The following graph shows different metrics collected from the CloudWatch log using TrainingJobAnalytics.
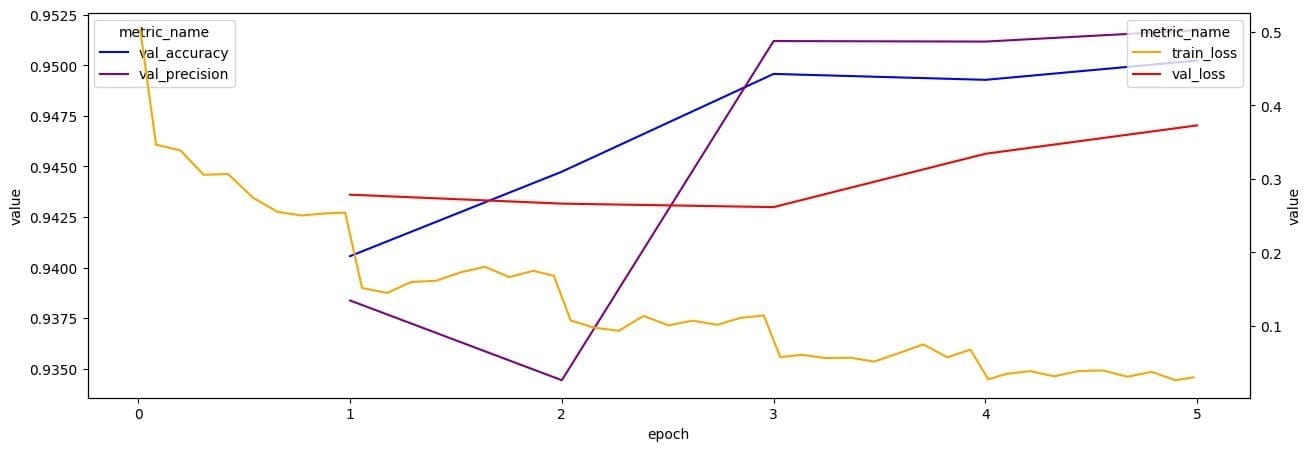
For more information about how to use the new SageMaker Hugging Face text classification algorithm for transfer learning on a custom dataset, deploy the fine-tuned model, run inference on the deployed model, and deploy the pre-trained model as is without first fine-tuning on a custom dataset, see the following example notebook.
Fine-tune any Hugging Face fill-mask or text classification model
SageMaker JumpStart supports the fine-tuning of any pre-trained fill-mask or text classification Hugging Face model. You can download the required model from the Hugging Face hub and perform the fine-tuning. To use these models, the model_id is provided in the hyperparameters as hub_key. See the following code:
Now you can construct an object of the Estimator class by passing the updated hyperparameters. You call .fit on the object of the Estimator class while passing the S3 location of the training dataset to perform the SageMaker training job for fine-tuning the model.
Fine-tune a model with automatic model tuning
SageMaker automatic model tuning (ATM), also known as hyperparameter tuning, finds the best version of a model by running many training jobs on your dataset using the algorithm and ranges of hyperparameters that you specify. It then chooses the hyperparameter values that result in a model that performs the best, as measured by a metric that you choose. In the following code, you use a HyperparameterTuner object to interact with SageMaker hyperparameter tuning APIs:
After you have defined the arguments for the HyperparameterTuner object, you pass it the Estimator and start the training. This will find the best-performing model.
Perform batch inference with the Hugging Face text classification algorithm
If the goal of inference is to generate predictions from a trained model on a large dataset where minimizing latency isn’t a concern, then the batch inference functionality may be most straightforward, more scalable, and more appropriate.
Batch inference is useful in the following scenarios:
- Preprocess datasets to remove noise or bias that interferes with training or inference from your dataset
- Get inference from large datasets
- Run inference when you don’t need a persistent endpoint
- Associate input records with inferences to assist the interpretation of results
For running batch inference in this use case, you first download the SST2 dataset locally. Remove the class label from it and upload it to Amazon S3 for batch inference. You create the object of Model class without providing the endpoint and create the batch transformer object from it. You use this object to provide batch predictions on the input data. See the following code:
After you run batch inference, you can compare the predication accuracy on the SST2 dataset.
Conclusion
In this post, we discussed the SageMaker Hugging Face text classification algorithm. We provided example code to perform transfer learning on a custom dataset using a pre-trained model in network isolation using this algorithm. We also provided the functionality to use any Hugging Face fill-mask or text classification model for inference and transfer learning. Lastly, we used batch inference to run inference on large datasets. For more information, check out the example notebook.
About the authors
 Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
 Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Leave a Reply