
Efficient and cost-effective multi-tenant LoRA serving with Amazon SageMaker
In the rapidly evolving landscape of artificial intelligence (AI), the rise of generative AI models has ushered in a new era of personalized and intelligent experiences. Organizations are increasingly using the power of these language models to drive innovation and enhance their services, from natural language processing to content generation and beyond.
Using generative AI models in the enterprise environment, however, requires taming their intrinsic power and enhancing their skills to address specific customer needs. In cases where an out-of-the-box model is missing knowledge of domain- or organization-specific terminologies, a custom fine-tuned model, also called a domain-specific large language model (LLM), might be an option for performing standard tasks in that domain or micro-domain. BloombergGPT is an example of LLM that was trained from scratch to have a better understanding of highly specialized vocabulary found in the financial domain. In the same sense, domain specificity can be addressed through fine-tuning at a smaller scale. Customers are fine-tuning generative AI models based on domains including finance, sales, marketing, travel, IT, HR, finance, procurement, healthcare and life sciences, customer service, and many more. Additionally, independent software vendors (ISVs) are building secure, managed, multi-tenant, end-to-end generative AI platforms with models that are customized and personalized based on their customer’s datasets and domains. For example, Forethought introduced SupportGPT, a generative AI platform for customer support.
As the demands for personalized and specialized AI solutions grow, businesses often find themselves grappling with the challenge of efficiently managing and serving a multitude of fine-tuned models across diverse use cases and customer segments. With the need to serve a wide range of AI-powered use cases, from resume parsing and job skill matching, domain-specific to email generation and natural language understanding, these businesses are often left with the daunting task of managing hundreds of fine-tuned models, each tailored to specific customer needs or use cases. The complexities of this challenge are compounded by the inherent scalability and cost-effectiveness concerns that come with deploying and maintaining such a diverse model ecosystem. Traditional approaches to model serving can quickly become unwieldy and resource intensive, leading to increased infrastructure costs, operational overhead, and potential performance bottlenecks.
Fine-tuning enormous language models is prohibitively expensive in terms of the hardware required and the storage and switching cost for hosting independent instances for different tasks. LoRA (Low-Rank Adaptation) is an efficient adaptation strategy that neither introduces inference latency nor reduces input sequence length while retaining high model quality. Importantly, it allows for quick task switching when deployed as a service by sharing the vast majority of the model parameters.
In this post, we explore a solution that addresses these challenges head-on using LoRA serving with Amazon SageMaker. By using the new performance optimizations of LoRA techniques in SageMaker large model inference (LMI) containers along with inference components, we demonstrate how organizations can efficiently manage and serve their growing portfolio of fine-tuned models, while optimizing costs and providing seamless performance for their customers.
The latest SageMaker LMI container offers unmerged-LoRA inference, sped up with our LMI-Dist inference engine and OpenAI style chat schema. To learn more about LMI, refer to LMI Starting Guide, LMI handlers Inference API Schema, and Chat Completions API Schema.
New LMI features for serving LoRA adapters at scale on SageMaker
There are two kinds of LoRA that can be put onto various engines:
- Merged LoRA – This applies the adapter by modifying the base model in place. It has zero added latency while running, but has a cost to apply or unapply the merge. It works best for cases with only a few adapters. It is best for single-adapter batches, and doesn’t support multi-adapter batches.
- Unmerged LoRA – This alters the model operators to factor in the adapters without changing the base model. It has a higher inference latency for the additional adapter operations. However, it does support multi-adapter batches. It works best for use cases with a large number of adapters.
The new LMI container offers out-of-box integration and abstraction with SageMaker for hosting multiple unmerged LoRA adapters with higher performance (low latency and high throughput) using the vLLM backend LMI-Dist backend that uses vLLM, which in-turn uses S-LORA and Punica. The LMI container offers two backends for serving LoRA adapters: the LMI-Dist backend (recommended) and the vLLM Backend. Both backends are based on the open source vLLM library for serving LoRA adapters, but the LMI-Dist backend provides additional optimized continuous (rolling) batching implementation. You are not required to configure these libraries separately; the LMI container provides the higher-level abstraction through the vLLM and LMI-Dist backends. We recommend you start with the LMI-Dist backend because it has additional performance optimizations related to continuous (rolling) batching.
S-LoRA stores all adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory. To efficiently use the GPU memory and reduce fragmentation, S-LoRA proposes unified paging. Unified paging uses a unified memory pool to manage dynamic adapter weights with different ranks and KV cache tensors with varying sequence lengths. Additionally, S-LoRA employs a novel tensor parallelism strategy and highly optimized custom CUDA kernels for heterogeneous batching of LoRA computation. Collectively, these features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with a small overhead.
Punica is designed to efficiently serve multiple LoRA models on a shared GPU cluster. It achieves this by following three design guidelines:
- Consolidating multi-tenant LoRA serving workloads to a small number of GPUs to increase overall GPU utilization
- Enabling batching for different LoRA models to improve performance and GPU utilization
- Focusing on the decode stage performance, which is the predominant factor in the cost of model serving
Punica uses a new CUDA kernel design called Segmented Gather Matrix-Vector Multiplication (SGMV) to batch GPU operations for concurrent runs of multiple LoRA models, significantly improving GPU efficiency in terms of memory and computation. Punica also implements a scheduler that routes requests to active GPUs and migrates requests for consolidation, optimizing GPU resource allocation. Overall, Punica achieves high throughput and low latency in serving multi-tenant LoRA models on a shared GPU cluster. For more information, read the Punica whitepaper.
The following figure shows the multi LoRA adapter serving stack of the LMI container on SageMaker.

As shown in the preceding figure, the LMI container provides the higher-level abstraction through the vLLM and LMI-Dist backends to serve LoRA adapters at scale on SageMaker. As a result, you’re not required to configure the underlying libraries (S-LORA, Punica, or vLLM) separately. However, there might be cases where you want to control some of the performance driving parameters depending on your use case and application performance requirements. The following are the common configuration options the LMI container provides to tune LoRA serving. For more details on configuration options specific to each backend, refer to vLLM Engine User Guide and LMI-Dist Engine User Guide.
Design patterns for serving fine-tuned LLMs at scale
Enterprises grappling with the complexities of managing generative AI models often encounter scenarios where a robust and flexible design pattern is crucial. One common use case involves a single base model with multiple LoRA adapters, each tailored to specific customer needs or use cases. This approach allows organizations to use a foundational language model while maintaining the agility to fine-tune and deploy customized versions for their diverse customer base.
Single-base model with multiple fine-tuned LoRA adapters
An enterprise offering a resume parsing and job skill matching service may use a single high-performance base model, such as Mistral 7B. The Mistral 7B base model is particularly well-suited for job-related content generation tasks, such as creating personalized job descriptions and tailored email communications. Mistral’s strong performance in natural language generation and its ability to capture industry-specific terminology and writing styles make it a valuable asset for such an enterprise’s customers in the HR and recruitment space. By fine-tuning Mistral 7B with LoRA adapters, enterprises can make sure the generated content aligns with the unique branding, tone, and requirements of each customer, delivering a highly personalized experience.
Multi-base models with multiple fine-tuned LoRA adapters
On the other hand, the same enterprise may use the Llama 3 base model for more general natural language processing tasks, such as resume parsing, skills extraction, and candidate matching. Llama 3’s broad knowledge base and robust language understanding capabilities enable it to handle a wide range of documents and formats, making sure their services can effectively process and analyze candidate information, regardless of the source. By fine-tuning Llama 3 with LoRA adapters, such enterprises can tailor the model’s performance to specific customer requirements, such as regional dialects, industry-specific terminology, or unique data formats. By employing a multi-base model, multi-adapter design pattern, enterprises can take advantage of the unique strengths of each language model to deliver a comprehensive and highly personalized job profile to a candidate resume matching service. This approach allows enterprises to cater to the diverse needs of their customers, making sure each client receives tailored AI-powered solutions that enhance their recruitment and talent management processes.
Effectively implementing and managing these design patterns, where multiple base models are coupled with numerous LoRA adapters, is a key challenge that enterprises must address to unlock the full potential of their generative AI investments. A well-designed and scalable approach to model serving is crucial in delivering cost-effective, high-performance, and personalized experiences to customers.
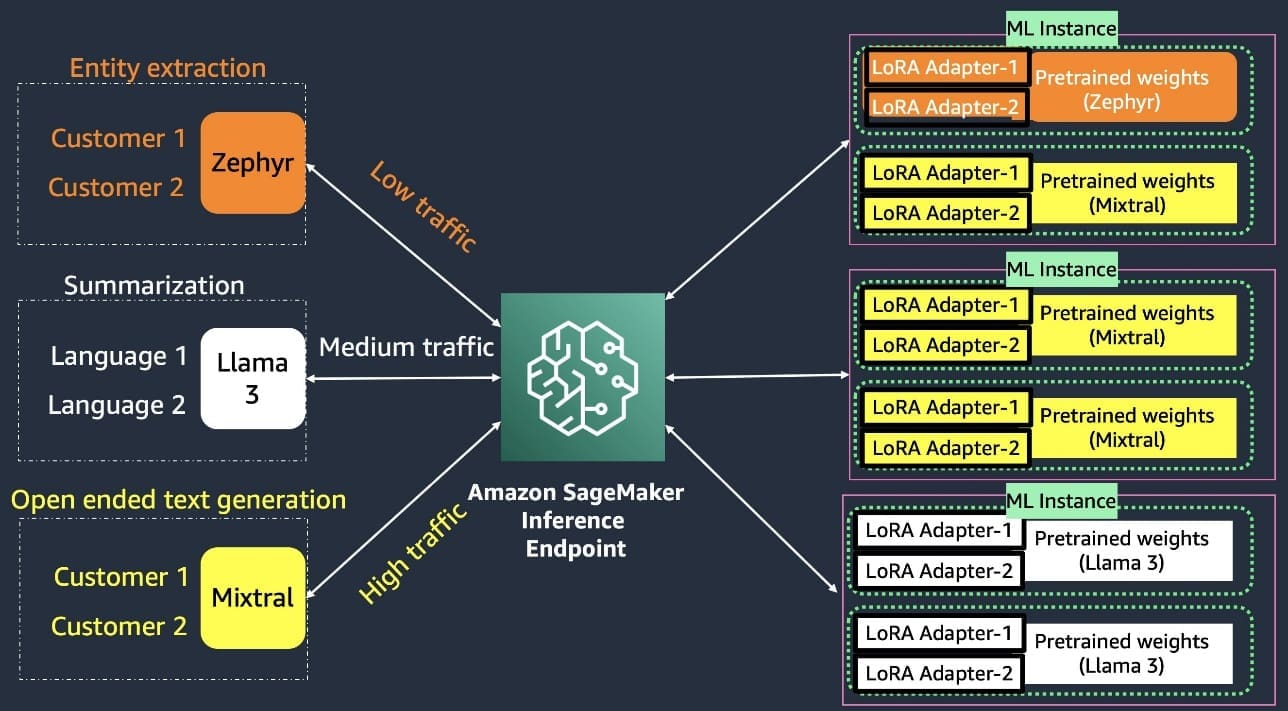
Solution overview
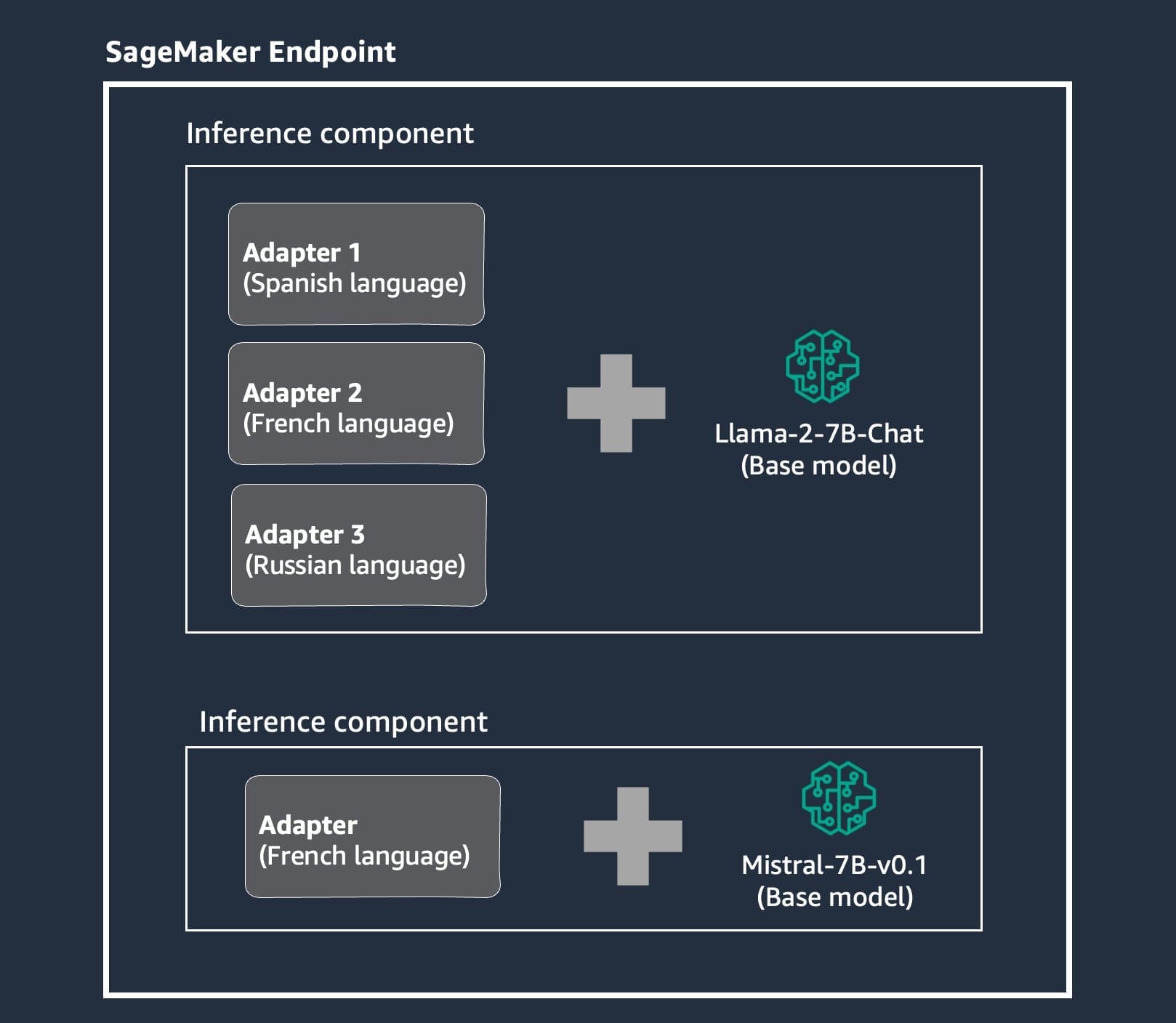
The following sections outline the coding steps to deploy a base LLM, TheBloke/Llama-2-7B-Chat-fp16, with LoRA adapters on SageMaker. It involves preparing a compressed archive with the base model files and LoRA adapter files, uploading it to Amazon Simple Storage Service (Amazon S3), selecting and configuring the SageMaker LMI container to enable LoRA support, creating a SageMaker endpoint configuration and endpoint, defining an inference component for the model, and sending inference requests specifying different LoRA adapters like Spanish (“es”) and French (“fr”) in the request payload to use those fine-tuned language capabilities. For more information on deploying models using SageMaker inference components, see Amazon SageMaker adds new inference capabilities to help reduce foundation model deployment costs and latency.
To showcase multi-base models with their LoRA adapters, we add another base model, mistralai/Mistral-7B-v0.1, and its LoRA adapter to the same SageMaker endpoint, as shown in the following diagram.
Prerequisites
You need to complete some prerequisites before you can run the notebook:
- Have a Hugging Face user access token and authorization to access to mistralai/Mistral-7B-v0.1 model
- Have a SageMaker quota for one ml.g5.12xlarge instance for endpoint usage
Upload your LoRA adapters to Amazon S3
To prepare the LoRA adapters, create a adapters.tar.gz compressed archive containing the LoRA adapters directory. The adapters directory should contain subdirectories for each of the LoRA adapters, with each adapter subdirectory containing the adapter_model.bin file (the adapter weights) and the adapter_config.json file (the adapter configuration). We typically obtain these adapter files by using the PeftModel.save_pretrained() method from the Peft library. After you assemble the adapters directory with the adapter files, you compress it into a adapters.tar.gz archive and upload it to an S3 bucket for deployment or sharing. We include the LoRA adapters in the adapters directory as follows:
Download LoRA adapters, compress them, and upload the compressed file to Amazon S3:
Select and LMI container and configure LMI to enable LoRA
SageMaker provides optimized containers for LMI that support different frameworks for model parallelism, allowing the deployment of LLMs across multiple GPUs. For this post, we employ the DeepSpeed container, which encompasses frameworks such as DeepSpeed and vLLM, among others. See the following code:
Create a SageMaker endpoint configuration
Create an endpoint configuration using the appropriate instance type. Set ContainerStartupHealthCheckTimeoutInSeconds to account for the time taken to download the LLM weights from Amazon S3 or the model hub, and the time taken to load the model on the GPUs:
Create a SageMaker endpoint
Create a SageMaker endpoint based on the endpoint configuration defined in the previous step. You use this endpoint for hosting the inference component (model) inference and make invocations.
Create a SageMaker inference component (model)
Now that you have created a SageMaker endpoint, let’s create our model as an inference component. The SageMaker inference component enables you to deploy one or more foundation models (FMs) on the same SageMaker endpoint and control how many accelerators and how much memory is reserved for each FM. See the following code:
Make inference requests using different LoRA adapters
With the endpoint and inference model ready, you can now send requests to the endpoint using the LoRA adapters you fine-tuned for Spanish and French languages. The specific LoRA adapter is specified in the request payload under the "adapters" field. We use "es" for the Spanish language adapter and "fr" for the French language adapter, as shown in the following code:
Add another base model and inference component and its LoRA adapter
Let’s add another base model and its LoRA adapter to the same SageMaker endpoint for multi-base models with multiple fine-tuned LoRA adapters. The code is very similar to the previous code for creating the Llama base model and its LoRA adapter.
Configure the SageMaker LMI container to host the base model (mistralai/Mistral-7B-v0.1) and its LoRA adapter (mistral-lora-multi-adapter/adapters/fr):
Create a new SageMaker model and inference component for the base model (mistralai/Mistral-7B-v0.1) and its LoRA adapter (mistral-lora-multi-adapter/adapters/fr):
Invoke the same SageMaker endpoint for the newly created inference component for the base model (mistralai/Mistral-7B-v0.1) and its LoRA adapter (mistral-lora-multi-adapter/adapters/fr):
Clean up
Delete the SageMaker inference components, models, endpoint configuration, and endpoint to avoid incurring unnecessary costs:
Conclusion
The ability to efficiently manage and serve a diverse portfolio of fine-tuned generative AI models is paramount if you want your organization to deliver personalized and intelligent experiences at scale in today’s rapidly evolving AI landscape. With the inference capabilities of SageMaker LMI coupled with the performance optimizations of LoRA techniques, you can overcome the challenges of multi-tenant fine-tuned LLM serving. This solution enables you to consolidate AI workloads, batch operations across multiple models, and optimize resource utilization for cost-effective, high-performance delivery of tailored AI solutions to your customers. As demand for specialized AI experiences continues to grow, we’ve shown how the scalable infrastructure and cutting-edge model serving techniques of SageMaker position AWS as a powerful platform for unlocking generative AI’s full potential. To start exploring the benefits of this solution for yourself, we encourage you to use the code example and resources we’ve provided in this post.
About the authors
 Michael Nguyen is a Senior Startup Solutions Architect at AWS, specializing in leveraging AI/ML to drive innovation and develop business solutions on AWS. Michael holds 12 AWS certifications and has a BS/MS in Electrical/Computer Engineering and an MBA from Penn State University, Binghamton University, and the University of Delaware.
Michael Nguyen is a Senior Startup Solutions Architect at AWS, specializing in leveraging AI/ML to drive innovation and develop business solutions on AWS. Michael holds 12 AWS certifications and has a BS/MS in Electrical/Computer Engineering and an MBA from Penn State University, Binghamton University, and the University of Delaware.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
![]() Vivek Gangasani is a AI/ML Startup Solutions Architect for Generative AI startups at AWS. He helps emerging GenAI startups build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
Vivek Gangasani is a AI/ML Startup Solutions Architect for Generative AI startups at AWS. He helps emerging GenAI startups build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
 Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
Leave a Reply