
Dynamic video content moderation and policy evaluation using AWS generative AI services
Organizations across media and entertainment, advertising, social media, education, and other sectors require efficient solutions to extract information from videos and apply flexible evaluations based on their policies. Generative artificial intelligence (AI) has unlocked fresh opportunities for these use cases. In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWS AI and generative AI services to provide a framework to streamline video extraction and evaluation processes.
Popular use cases
Advertising tech companies own video content like ad creatives. When it comes to video analysis, priorities include brand safety, regulatory compliance, and engaging content. This solution, powered by AWS AI and generative AI services, meets these needs. Advanced content moderation makes sure ads appear alongside safe, compliant content, building trust with consumers. You can use the solution to evaluate videos against content compliance policies. You can also use it to create compelling headlines and summaries, boosting user engagement and ad performance.
Educational tech companies manage large inventories of training videos. An efficient way to analyze videos will help them evaluate content against industry policies, index videos for efficient search, and perform dynamic detection and redaction tasks, such as blurring student faces in a Zoom recording.
The solution is available on the GitHub repository and can be deployed to your AWS account using an AWS Cloud Development Kit (AWS CDK) package.
Solution overview
- Media extraction – After a video uploaded, the app starts preprocessing by extracting image frames from a video. Each frame will be analyzed using Amazon Rekognition and Amazon Bedrock for metadata extraction. In parallel, the system extracts audio transcription from the uploaded content using Amazon Transcribe.
- Policy evaluation – Using the extracted metadata from the video, the system conducts LLM evaluation. This allows you to take advantage of the flexibility of LLMs to evaluate video against dynamic policies.
The following diagram illustrates the solution workflow and architecture.
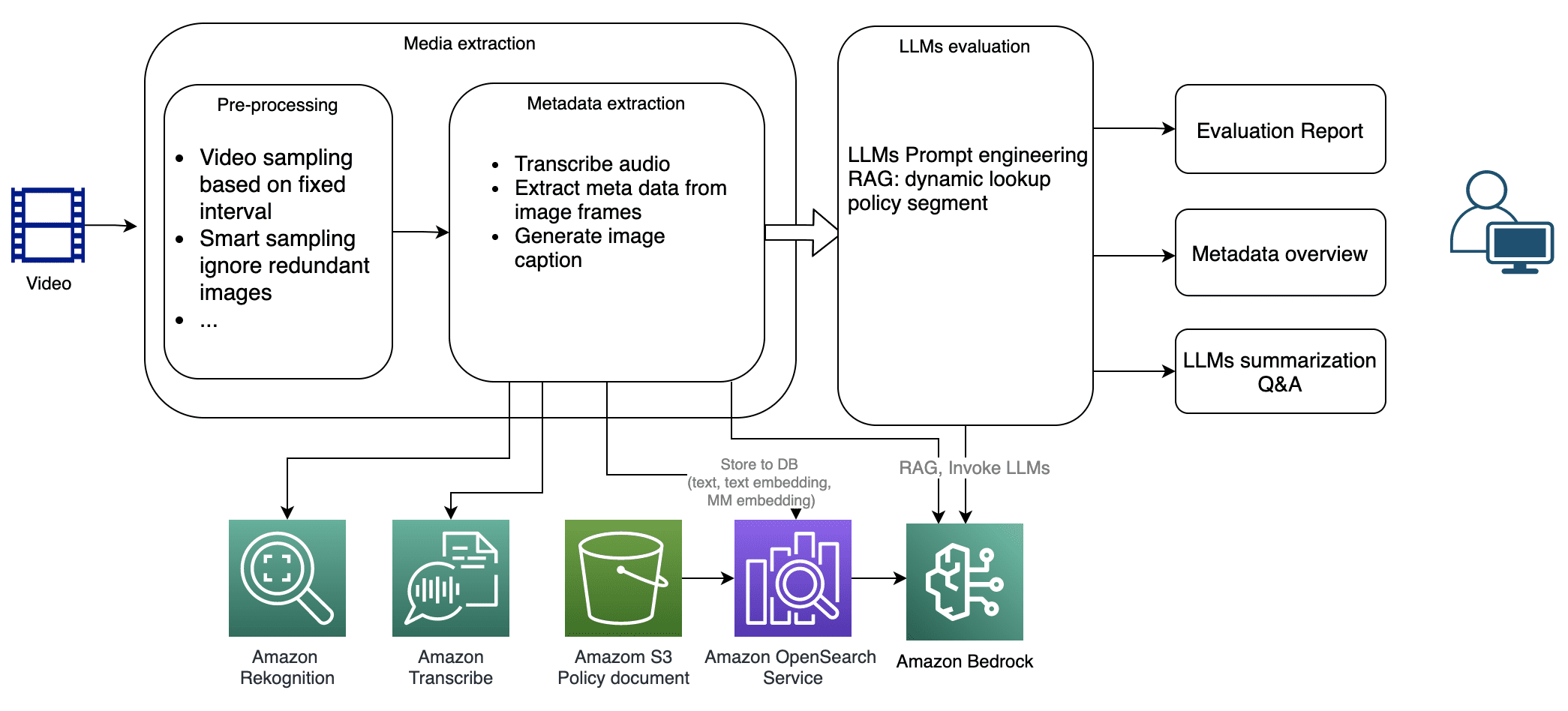
The solution adopts microservice design principles, with loosely coupled components that can be deployed together to serve the video analysis and policy evaluation workflow, or independently to integrate into existing pipelines. The following diagram illustrates the microservice architecture.
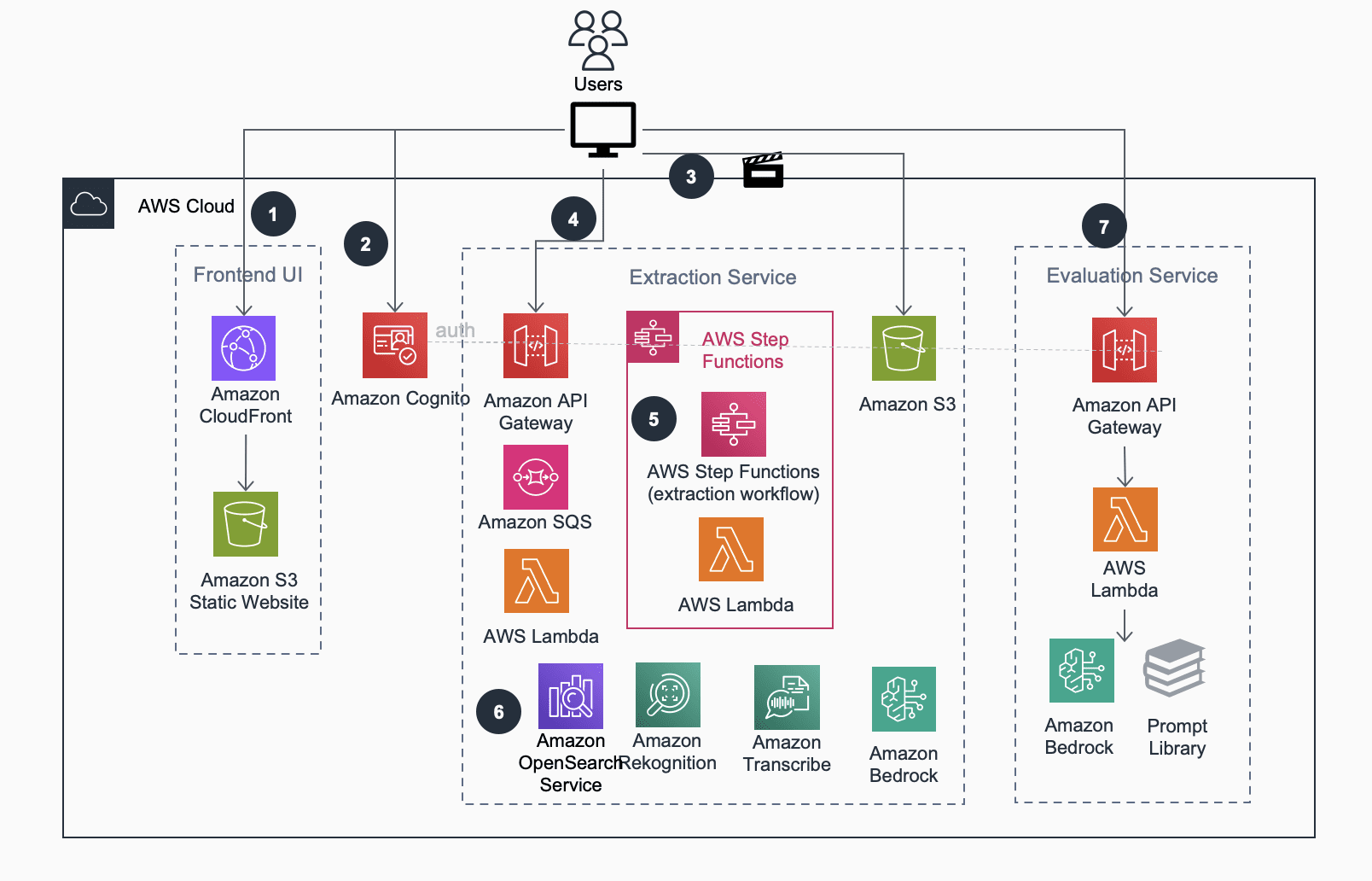
The microservice workflow consists of the following steps:
- Users access the frontend static website via Amazon CloudFront distribution. The static content is hosted on Amazon Simple Storage Service (Amazon S3).
- Users log in to the frontend web application and are authenticated by an Amazon Cognito user pool.
- Users upload videos to Amazon S3 directly from their browser using multi-part pre-signed Amazon S3 URLs.
- The frontend UI interacts with the extract microservice through a RESTful interface provided by Amazon API Gateway. This interface offers CRUD (create, read, update, delete) features for video task extraction management.
- An AWS Step Functions state machine oversees the analysis process. It transcribes audio using Amazon Transcribe, samples image frames from video using moviepy, and analyzes each image using Anthropic Claude Sonnet image summarization. It also generates text embedding and multimodal embedding on the frame level using Amazon Titan models.
- An Amazon OpenSearch Service cluster stores the extracted video metadata and facilitates users’ search and discovery needs. The UI constructs evaluation prompts and sends them to Amazon Bedrock LLMs, retrieving evaluation results synchronously.
- Using the solution UI, user selects existing template prompts, customize them and start the policy evaluation utilizing Amazon Bedrock. The solution runs the evaluation workflow and display the results back to the user.
In the following sections, we discuss the key components and microservices of the solution in more detail.
Website UI
The solution features a website that lets users browse videos and manage the uploading process through a user-friendly interface. It offers details of the extracted video information and includes a lightweight analytics UI for dynamic LLM analysis. The following screenshots show some examples.
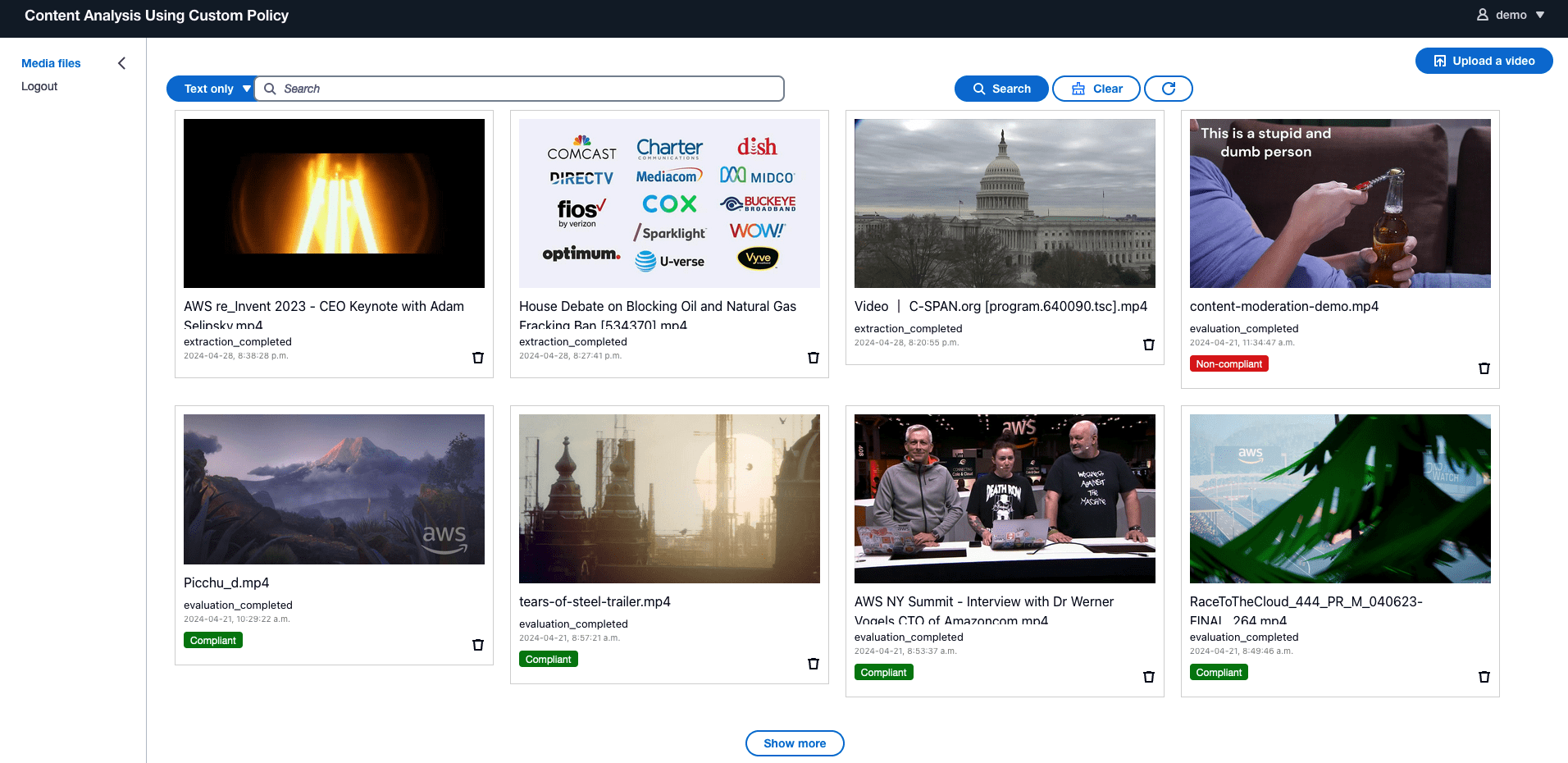
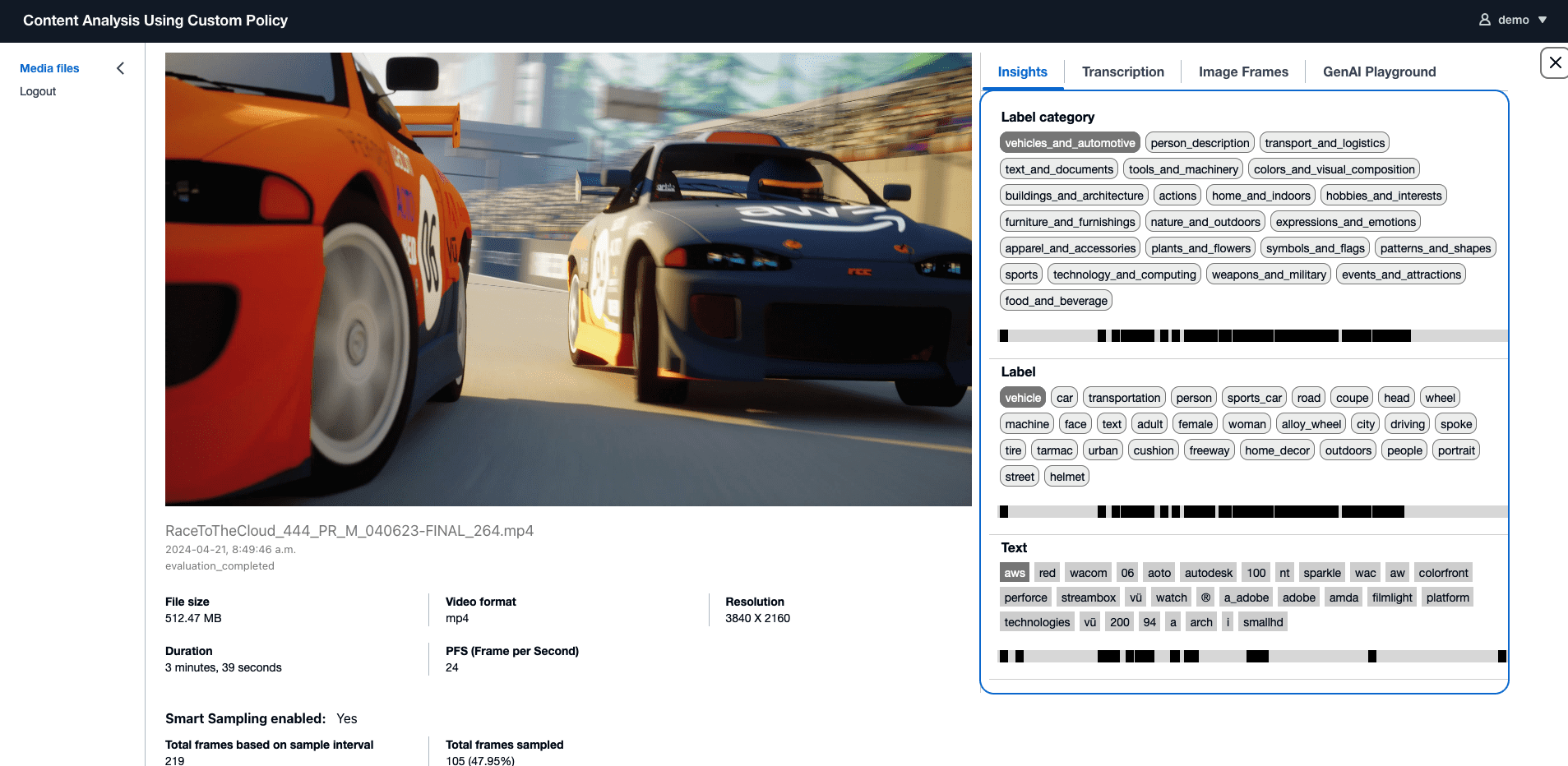
Extract information from videos
The solution includes a backend extraction service to manage video metadata extraction asynchronously. This involves extracting information from both the visual and audio components, including identifying objects, scenes, text, and human faces. The audio component is particularly important for videos with active narratives and conversations, because it often contains valuable information.
Building a robust solution to extract information from videos poses challenges from both machine learning (ML) and engineering perspectives. From the ML standpoint, our goal is to achieve generic extraction of information to serve as factual data for downstream analysis. On the engineering side, managing video sampling with concurrency, providing high availability, and flexible configuration options, as well as having an extendable architecture to support additional ML model plugins requires intensive effort.
The extraction service uses Amazon Transcribe to convert the audio portion of the video into text in subtitle formats. For visual extraction, there are a few major techniques involved:
- Frame sampling – The classic method for analyzing the visual aspect of a video uses a sampling technique. This involves capturing screenshots at specific intervals and then applying ML models to extract information from each image frame. Our solution uses sampling with the following considerations:
- The solution supports a configurable interval for the fixed sampling rate.
- It also offers an advanced smart sampling option, which uses the Amazon Titan Multimodal Embeddings model to conduct similarity search against frames sampled from the same video. This process identifies similar images and discards redundant ones to optimize performance and cost.
- Extract information from image frames – The solution will iterate through images sampled from a video and process them concurrently. For each image, it will apply the following ML features to extract information:
- Recognize celebrity faces using the Amazon Rekognition celebrity API.
- Detect generic objects and labels using the Amazon Rekognition label detection API.
- Detect text using the Amazon Rekognition text detection API.
- Flag inappropriate content using the Amazon Rekognition moderation API.
- Use the Anthropic Claude V3 Haiku model to generate summarization of the image frame.
The following diagram illustrates how the extraction service is implemented.
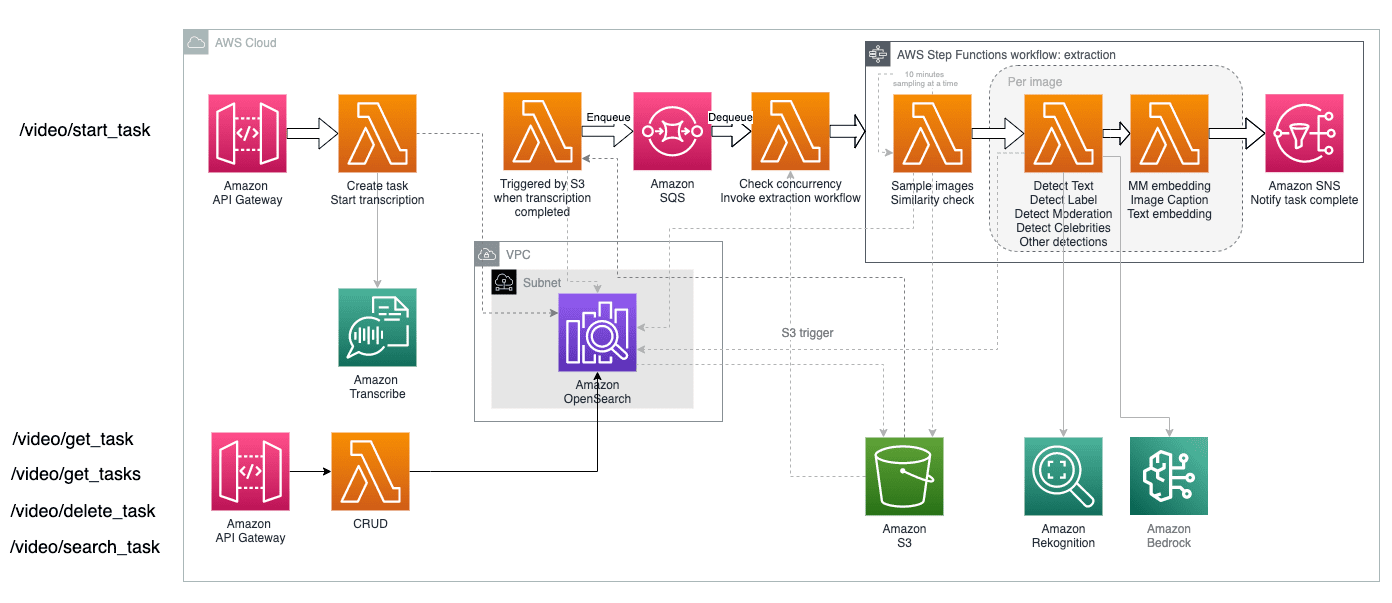
The extraction service uses Amazon Simple Queue Service (Amazon SQS) and Step Functions to manage concurrent video processing, allowing configurable settings. You can specify how many videos can be processed in parallel and how many frames for each video can be processed concurrently, based on your account’s service quota limits and performance requirements.
Search the videos
Efficiently identifying videos within your inventory is a priority, and an effective search capability is critical for video analysis tasks. Traditional video search methods rely on full-text keyword searches. With the introduction of text embedding and multimodal embedding, new search methods based on semantics and images have emerged.
The solution offers search functionality via the extraction service, available as a UI feature. It generates vector embeddings at the image frame level as part of the extraction process to serve video search. You can search videos and their underlying frames either through the built-in web UI or via the RESTful API interface directly. There are three search options you can choose from:
- Full text search – Powered by OpenSearch Service, it uses a search index generated by text analyzers that is ideal for keyword search.
- Semantic search – Powered by the Amazon Titan Text Embeddings model, generated based on transcription and image metadata extracted at the frame level.
- Image search – Powered by the Amazon Titan Multimodal Embeddings model, generated using the same text message used for text embedding along with the image frame. This feature is suitable for image search, allowing you to provide an image and find similar frames in videos.
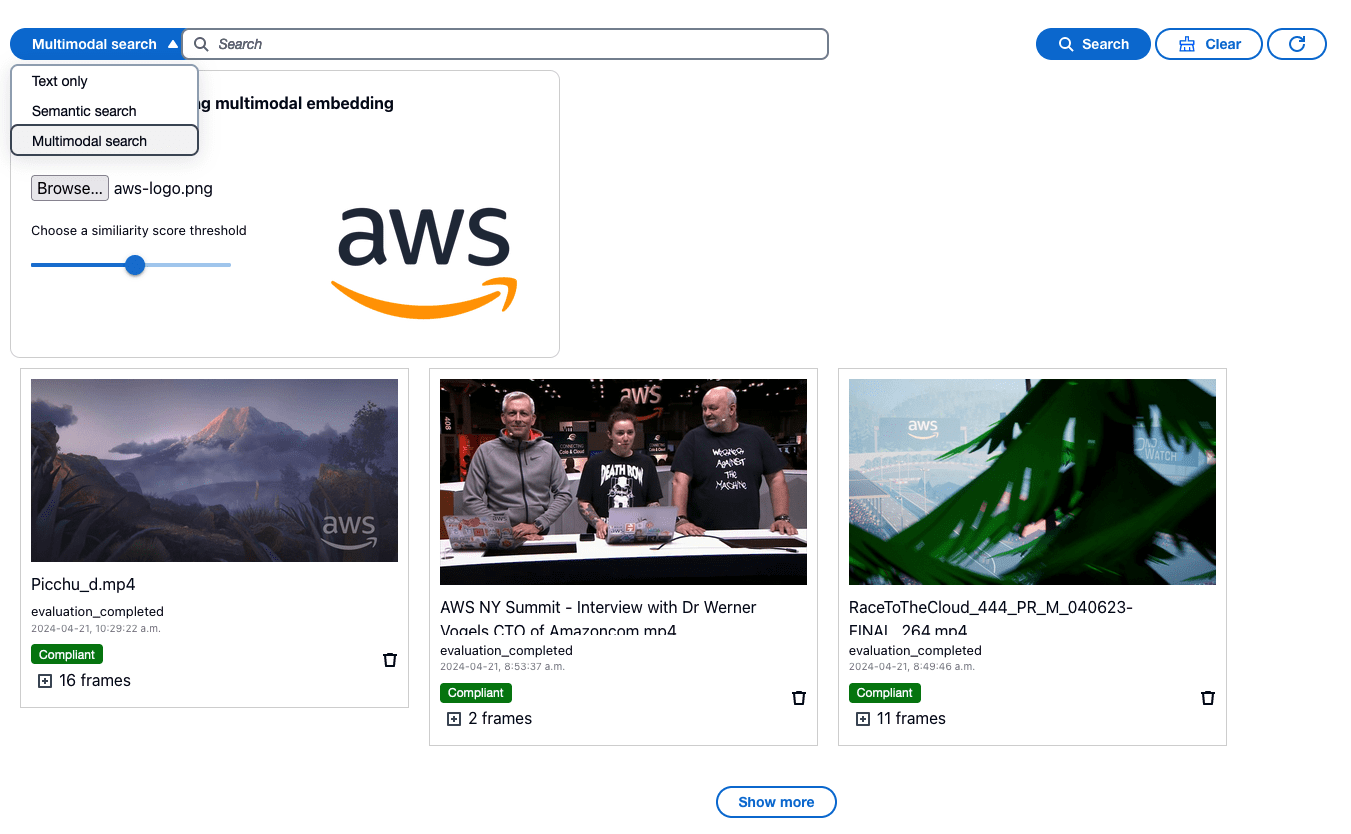
The following screenshot of the UI showcases the use of multimodal embedding to search for videos containing the AWS logo. The web UI displays three videos with frames that have a high similarity score when compared with the provided AWS logo image. You can also find the other two text search options on the dropdown menu, giving you the flexibility to switch among search options.
Analyze the videos
After gathering rich insights from the videos, you can analyze the data. The solution features a lightweight UI, implemented as a static React web application, powered by a backend microservice called the evaluation service. This service acts as a proxy atop the Amazon Bedrock LLMs to provide real-time evaluation. You can use this as a sandbox feature to test out LLMs prompts for dynamic video analysis. The web UI contains a few sample prompt templates to show how you can analyze video for different use cases, including the following:
- Content moderation – Flag unsafe scenes, text, or speech that violate your trust and safety policy
- Video summarization – Summarize the video into a concise description based on its audio or visual content cues
- IAB classification – Classify the video content into advertising IAB categories for better organization and understanding
You can also choose from a collection of LLMs models offered by Amazon Bedrock to test the evaluation results and find the most suitable one for your workload. LLMs can use the extraction data and perform analysis based on your instructions, making them flexible and extendable analytics tools that can support various use cases. The following are some examples of the prompt templates for video analysis. The placeholders within #### will be replaced by the corresponding video-extracted data at runtime.
The first example shows how to moderate a video based on audio transcription and object and moderation labels detected by Amazon Rekognition. This sample includes a basic inline policy. You can extend this section to add more rules. You can integrate longer trust and safety policy documents and runbooks in an Retrieval Augmented Generation (RAG) pattern using Knowledge Bases for Amazon Bedrock.
Classifying videos into IAB categories used to be challenging before generative AI became popular. It typically involved custom-trained text and image classification ML models, which often faced accuracy challenges. The following sample prompt uses the Amazon Bedrock Anthropic Claude V3 Sonnet model, which has built-in knowledge of the IAB taxonomy. Therefore, you don’t even need to include the taxonomy definitions as part of the LLM prompt.
Summary
Video analysis presents challenges that span technical difficulties in both ML and engineering. This solution provides a user-friendly UI to streamline the video analysis and policy evaluation processes. The backend components can serve as building blocks for integration into your existing analysis workflow, allowing you to focus on analytics tasks with greater business impact.
You can deploy the solution into your AWS account using the AWS CDK package available on the GitHub repo. For deployment details, refer to the step-by-step instructions.
About the Authors

Lana Zhang is a Senior Solutions Architect at AWS World Wide Specialist Organization AI Services team, specializing in AI and generative AI with a focus on use cases including content moderation and media analysis. With her expertise, she is dedicated to promoting AWS AI and generative AI solutions, demonstrating how generative AI can transform classic use cases with advanced business value. She assists customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising, and marketing.
 Negin Rouhanizadeh is a Solutions Architect at AWS focusing on AI/ML in Advertising and Marketing. Beyond crafting solutions for her customers, Negin enjoys painting, coding, spending time with family and her furry boys, Simba and Huchi.
Negin Rouhanizadeh is a Solutions Architect at AWS focusing on AI/ML in Advertising and Marketing. Beyond crafting solutions for her customers, Negin enjoys painting, coding, spending time with family and her furry boys, Simba and Huchi.
Leave a Reply