
Reimagining software development with the Amazon Q Developer Agent
Amazon Q Developer is an AI-powered assistant for software development that reimagines the experience across the entire software development lifecycle, making it faster to build, secure, manage, and optimize applications on or off of AWS. The Amazon Q Developer Agent includes an agent for feature development that automatically implements multi-file features, bug fixes, and unit tests in your integrated development environment (IDE) workspace using natural language input. After you enter your query, the software development agent analyzes your code base and formulates a plan to fulfill the request. You can accept the plan or ask the agent to iterate on it. After the plan is validated, the agent generates the code changes needed to implement the feature you requested. You can then review and accept the code changes or request a revision.
Amazon Q Developer uses generative artificial intelligence (AI) to deliver state-of-the-art accuracy for all developers, taking first place on the leaderboard for SWE-bench, a dataset that tests a system’s ability to automatically resolve GitHub issues. This post describes how to get started with the software development agent, gives an overview of how the agent works, and discusses its performance on public benchmarks. We also delve into the process of getting started with the Amazon Q Developer Agent and give an overview of the underlying mechanisms that make it a state-of-the-art feature development agent.
Getting started
To get started, you need to have an AWS Builder ID or be part of an organization with an AWS IAM Identity Center instance set up that allows you to use Amazon Q. To use Amazon Q Developer Agent for feature development in Visual Studio Code, start by installing the Amazon Q extension. The extension is also available for JetBrains, Visual Studio (in preview), and in the Command Line on macOS. Find the latest version on the Amazon Q Developer page.

After authenticating, you can invoke the feature development agent by entering /dev in the chat field.
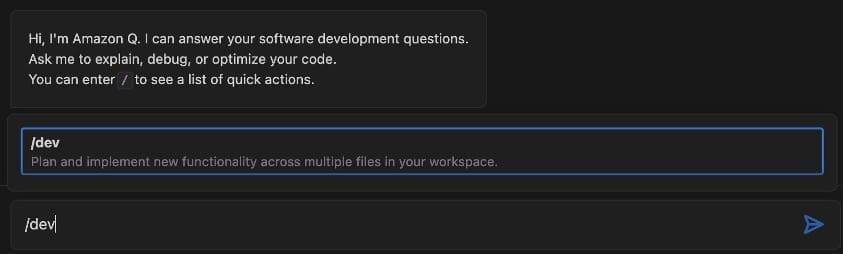
The feature development agent is now ready for your requests. Let’s use the repository of Amazon’s Chronos forecasting model to demonstrate how the agent works. The code for Chronos is already of high quality, but unit test coverage could be improved in places. Let’s ask the software development agent to improve the unit test coverage of the file chronos.py. Stating your request as clearly and precisely as you can will help the agent deliver the best possible solution.

The agent returns a detailed plan to add missing tests in the existing test suite test/test_chronos.py. To generate the plan (and later the code change), the agent has explored your code base to understand how to satisfy your request. The agent will work best if the names of files and functions are descriptive of their intent.
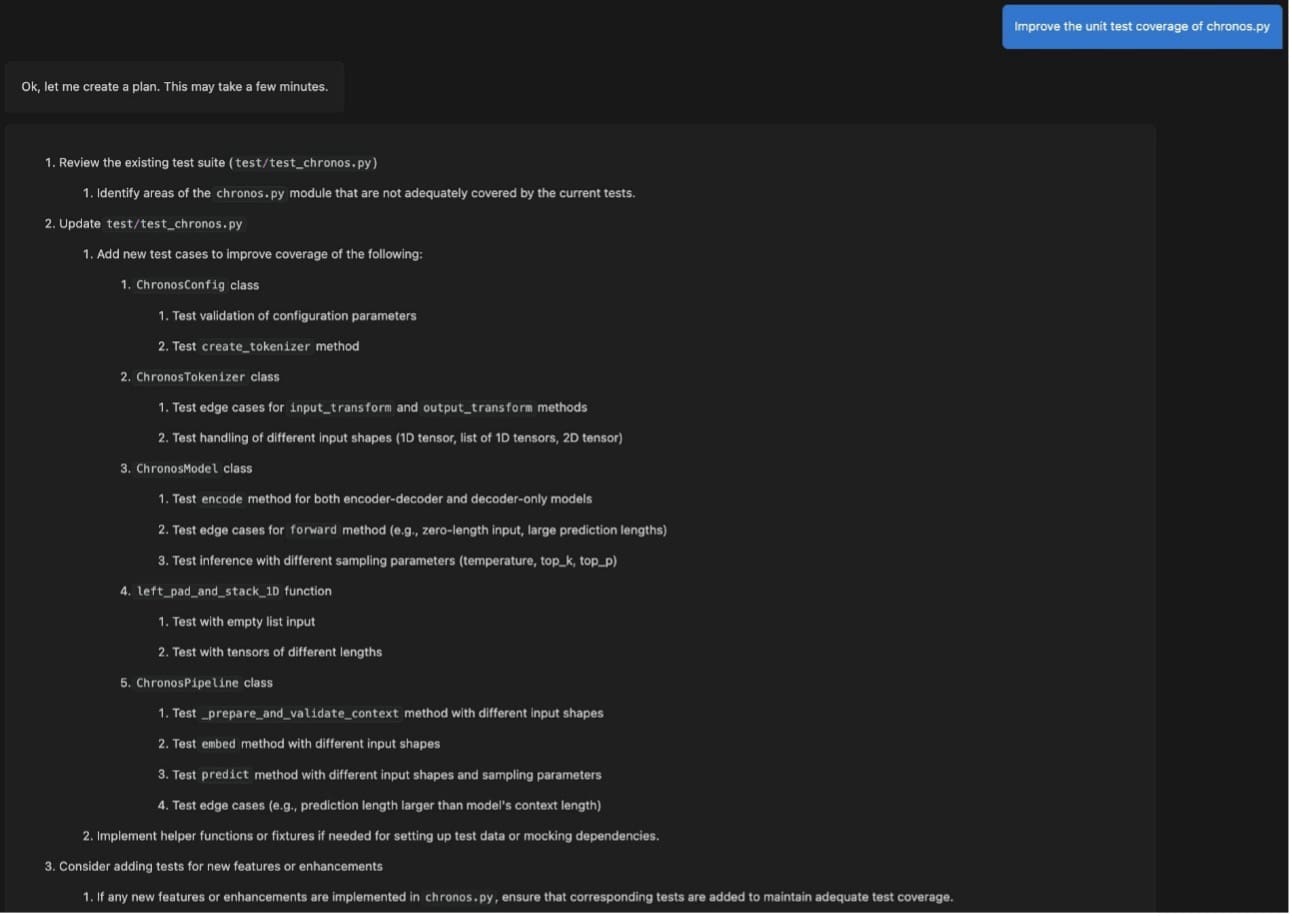
You are asked to review the plan. If the plan looks good and you want to proceed, choose Generate code. If you find that it can be improved in places, you can provide feedback and request an improved plan.
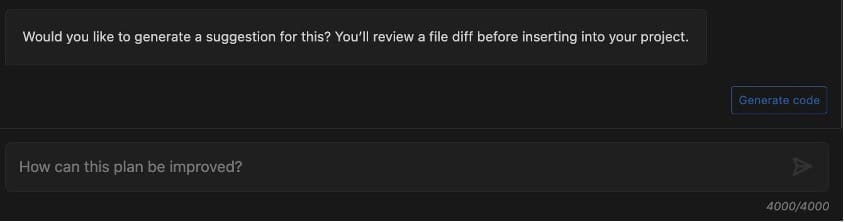
After the code is generated, the software development agent will list the files for which it has created a diff (for this post, test/test_chronos.py). You can review the code changes and decide to either insert them in your code base or provide feedback on possible improvements and regenerate the code.
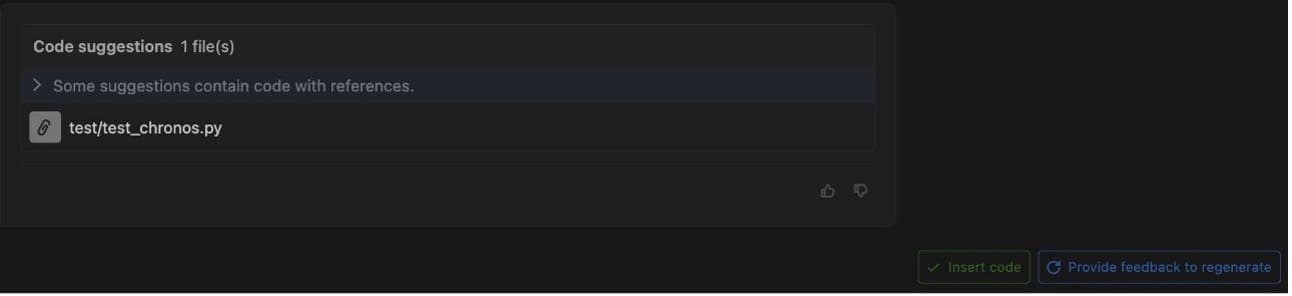
Choosing a modified file opens a diff view in the IDE showing which lines have been added or modified. The agent has added multiple unit tests for parts of chronos.py that were not previously covered.
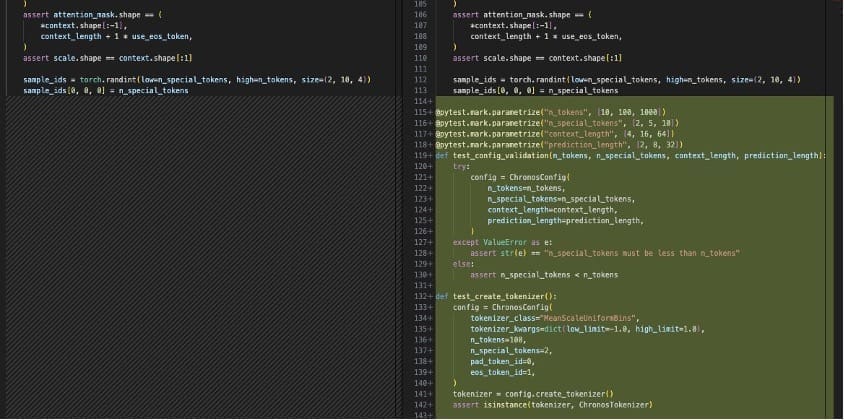
After you review the code changes, you can decide to insert them, provide feedback to generate the code again, or discard it altogether. That’s it; there is nothing else for you to do. If you want to request another feature, invoke dev again in Amazon Q Developer.
System overview
Now that we have shown you how to use Amazon Q Developer Agent for software development, let’s explore how it works. This is an overview of the system as of May 2024. The agent is continuously being improved. The logic described in this section will evolve and change.
When you submit a query, the agent generates a structured representation of the repository’s file system in XML. The following is an example output, truncated for brevity:
An LLM then uses this representation with your query to determine which files are relevant and should be retrieved. We use automated systems to check that the files identified by the LLM are all valid. The agent uses the retrieved files with your query to generate a plan for how it will resolve the task you have assigned to it. This plan is returned to you for validation or iteration. After you validate the plan, the agent moves to the next step, which ultimately ends with a proposed code change to resolve the issue.
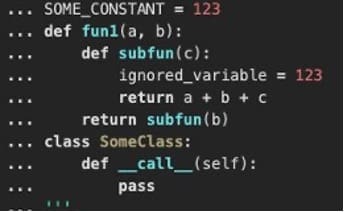
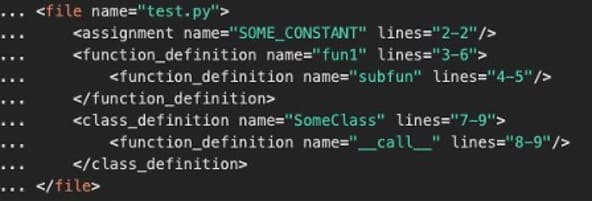
The content of each retrieved code file is parsed with a syntax parser to obtain an XML syntax tree representation of the code, which the LLM is capable of using more efficiently than the source code itself while using far fewer tokens. The following is an example of that representation. Non-code files are encoded and chunked using a logic commonly used in Retrieval Augmented Generation (RAG) systems to allow for the efficient retrieval of chunks of documentation.
The following screenshot shows a chunk of Python code.
The following is its syntax tree representation.
The LLM is prompted again with the problem statement, the plan, and the XML tree structure of each of the retrieved files to identify the line ranges that need updating in order to resolve the issue. This approach allows you to be more frugal with your usage of LLM bandwidth.
The software development agent is now ready to generate the code that will resolve your issue. The LLM directly rewrites sections of code, rather than attempting to generate a patch. This task is much closer to those that the LLM was optimized to perform compared to attempting to directly generate a patch. The agent proceeds to some syntactic validation of the generated code and attempts to fix issues before moving to the final step. The original and rewritten code are passed to a diff library to generate a patch programmatically. This creates the final output that is then shared with you to review and accept.
System accuracy
In the press release announcing the launch of Amazon Q Developer Agent for feature development, we shared that the model scored 13.82% on SWE-bench and 20.33% on SWE-bench lite, putting it at the top of the SWE-bench leaderboard as of May 2024. SWE-bench is a public dataset of over 2,000 tasks from 12 popular Python open source repositories. The key metric reported in the leaderboard of SWE-bench is the pass rate: how often we see all the unit tests associated to a specific issue passing after an AI-generated code changes are applied. This is an important metric because our customers want to use the agent to solve real-world problems and we are proud to report a state-of-the-art pass rate.
A single metric never tells the whole story. We look at the performance of our agent as a point on the Pareto front over multiple metrics. The Amazon Q Developer Agent for software development is not specifically optimized for SWE-bench. Our approach focuses on optimizing for a range of metrics and datasets. For instance, we aim to strike a balance between accuracy and resource efficiency, such as the number of LLMs calls and input/output tokens used, because this directly impacts runtime and cost. In this regard, we take pride in our solution’s ability to consistently deliver results within minutes.
Limitations of public benchmarks
Public benchmarks such as SWE-bench are an incredibly useful contribution to the AI code generation community and present an interesting scientific challenge. We are grateful to the team releasing and maintaining this benchmark. We are proud to be able to share our state-of-the-art results on this benchmark. Nonetheless, we would like to call out a few limitations, which are not exclusive to SWE-bench.
The success metric for SWE-bench is binary. Either a code change passes all tests or it does not. We believe that this doesn’t capture the full value feature development agents can generate for developers. Agents save developers a lot of time even when they don’t implement the entirety of a feature at once. Latency, cost, number of LLM calls, and number of tokens are all highly correlated metrics that represent the computational complexity of a solution. This dimension is as important as accuracy for our customers.
The test cases included in the SWE-bench benchmark are publicly available on GitHub. As such, it’s possible that these test cases may have been used in the training data of various large language models. Although LLMs have the capability to memorize portions of their training data, it’s challenging to quantify the extent to which this memorization occurs and whether the models are inadvertently leaking this information during testing.
To investigate this potential concern, we have conducted multiple experiments to evaluate the possibility of data leakage across different popular models. One approach to testing memorization involves asking the models to predict the next line of an issue description given a very short context. This is a task that they should theoretically struggle with in the absence of memorization. Our findings indicate that recent models exhibit signs of having been trained on the SWE-bench dataset.
The following figure shows the distribution of rougeL scores when asking each model to complete the next sentence of an SWE-bench issue description given the preceding sentences.
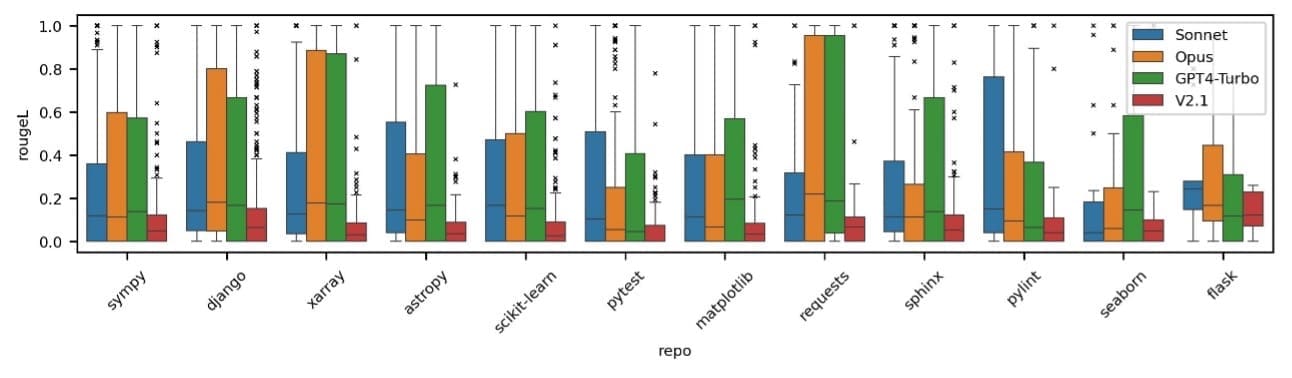
We have shared measurements of the performance of our software development agent on SWE-bench to offer a reference point. We recommend testing the agents on private code repositories that haven’t been used in the training of any LLMs and compare these results with the ones of publicly available baselines. We will continue benchmarking our system on SWE-bench while focusing our testing on private benchmarking datasets that haven’t been used to train models and that better represent the tasks submitted by our customers.
Conclusion
This post discussed how to get started with Amazon Q Developer Agent for software development. The agent automatically implements features that you describe with natural language in your IDE. We gave you an overview of how the agent works behind the scenes and discussed its state-of-the-art accuracy and position at the top of the SWE-bench leaderboard.
You are now ready to explore the capabilities of Amazon Q Developer Agent for software development and make it your personal AI coding assistant! Install the Amazon Q plugin in your IDE of choice and start using Amazon Q (including the software development agent) for free using your AWS Builder ID or subscribe to Amazon Q to unlock higher limits.
About the authors
 Christian Bock is an applied scientist at Amazon Web Services working on AI for code.
Christian Bock is an applied scientist at Amazon Web Services working on AI for code.
 Laurent Callot is a Principal Applied Scientist at Amazon Web Services leading teams creating AI solutions for developers.
Laurent Callot is a Principal Applied Scientist at Amazon Web Services leading teams creating AI solutions for developers.
 Tim Esler is a Senior Applied Scientist at Amazon Web Services working on Generative AI and Coding Agents for building developer tools and foundational tooling for Amazon Q products.
Tim Esler is a Senior Applied Scientist at Amazon Web Services working on Generative AI and Coding Agents for building developer tools and foundational tooling for Amazon Q products.
 Prabhu Teja is an Applied Scientist at Amazon Web Services. Prabhu works on LLM assisted code generation with a focus on natural language interaction.
Prabhu Teja is an Applied Scientist at Amazon Web Services. Prabhu works on LLM assisted code generation with a focus on natural language interaction.
 Martin Wistuba is a senior applied scientist at Amazon Web Services. As part of Amazon Q Developer, he is helping developers to write more code in less time.
Martin Wistuba is a senior applied scientist at Amazon Web Services. As part of Amazon Q Developer, he is helping developers to write more code in less time.
 Giovanni Zappella is a Principal Applied Scientist working on the creations of intelligent agents for code generation. While at Amazon he also contributed to the creation of new algorithms for Continual Learning, AutoML and recommendations systems.
Giovanni Zappella is a Principal Applied Scientist working on the creations of intelligent agents for code generation. While at Amazon he also contributed to the creation of new algorithms for Continual Learning, AutoML and recommendations systems.
Leave a Reply