
Scalable intelligent document processing using Amazon Bedrock
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. However, traditional document processing workflows often involve complex and time-consuming manual tasks, hindering productivity and scalability.
In this post, we discuss an approach that uses the Anthropic Claude 3 Haiku model on Amazon Bedrock to enhance document processing capabilities. Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading artificial intelligence (AI) startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the AWS tools without having to manage any infrastructure.
At the heart of this solution lies the Anthropic Claude 3 Haiku model, the fastest and most affordable model in its intelligence class. With state-of-the-art vision capabilities and strong performance on industry benchmarks, Anthropic Claude 3 Haiku is a versatile solution for a wide range of enterprise applications. By using the advanced natural language processing (NLP) capabilities of Anthropic Claude 3 Haiku, our intelligent document processing (IDP) solution can extract valuable data directly from images, eliminating the need for complex postprocessing.
Scalable and efficient data extraction
Our solution overcomes the traditional limitations of document processing by addressing the following key challenges:
- Simple prompt-based extraction – This solution allows you to define the specific data you need to extract from the documents through intuitive prompts. The Anthropic Claude 3 Haiku model then processes the documents and returns the desired information, streamlining the entire workflow.
- Handling larger file sizes and multipage documents – To provide scalability and flexibility, this solution integrates additional AWS services to handle file sizes beyond the 5 MB limit of Anthropic Claude 3 Haiku. The solution can process both PDFs and image files, including multipage documents, providing comprehensive processing for unparalleled efficiency.
With the advanced NLP capabilities of the Anthropic Claude 3 Haiku model, our solution can directly extract the specific data you need without requiring complex postprocessing or parsing the output. This approach simplifies the workflow and enables more targeted and efficient document processing than traditional OCR-based solutions.
Confidence scores and human review
Maintaining data accuracy and quality is paramount in any document processing solution. This solution incorporates customizable rules, allowing you to define the criteria for invoking a human review. This provides a seamless collaboration between the automated extraction and human expertise, delivering high-quality results that meet your specific requirements.
In this post, we show how you can use Amazon Bedrock and Amazon Augmented AI (Amazon A2I) to build a workflow that enables multipage PDF document processing with a human reviewer loop.
Solution overview
The following architecture shows how you can have a serverless architecture to process multipage PDF documents or images with a human review. To implement this architecture, we take advantage of AWS Step Functions to build the overall workflow. As the workflow starts, it extracts individual pages from the multipage PDF document. It then uses the Map state to process multiple pages concurrently using the Amazon Bedrock API. After the data is extracted from the document, it validates against the business rules and sends the document to Amazon A2I for a human to review if any business rules fail. Reviewers use the Amazon A2I UI (a customizable website) to verify the extraction result. When the human review is complete, the callback task token is used to resume the state machine and store the output in an Amazon DynamoDB table.

You can deploy this solution following the steps in this post.
Prerequisites
For this walkthrough, you need the following:
- An AWS account.
- AWS Management Console access to create an AWS Cloud9 instance.
- Access to the Anthropic Claude 3 Haiku model on Amazon Bedrock. For instructions to request access, see Model access.
Create an AWS Cloud9 IDE
We use an AWS Cloud9 integrated development environment (IDE) to deploy the solution. It provides a convenient way to access a full development and build environment. Complete the following steps:
- Sign in to the AWS Management Console through your AWS account.
- Select the AWS Region in which you want to deploy the solution.
- On the AWS Cloud9 console, choose Create environment.
- Name your environment mycloud9.
- Choose “t3.small” instance on the Amazon Linux2 platform.
- Choose Create.
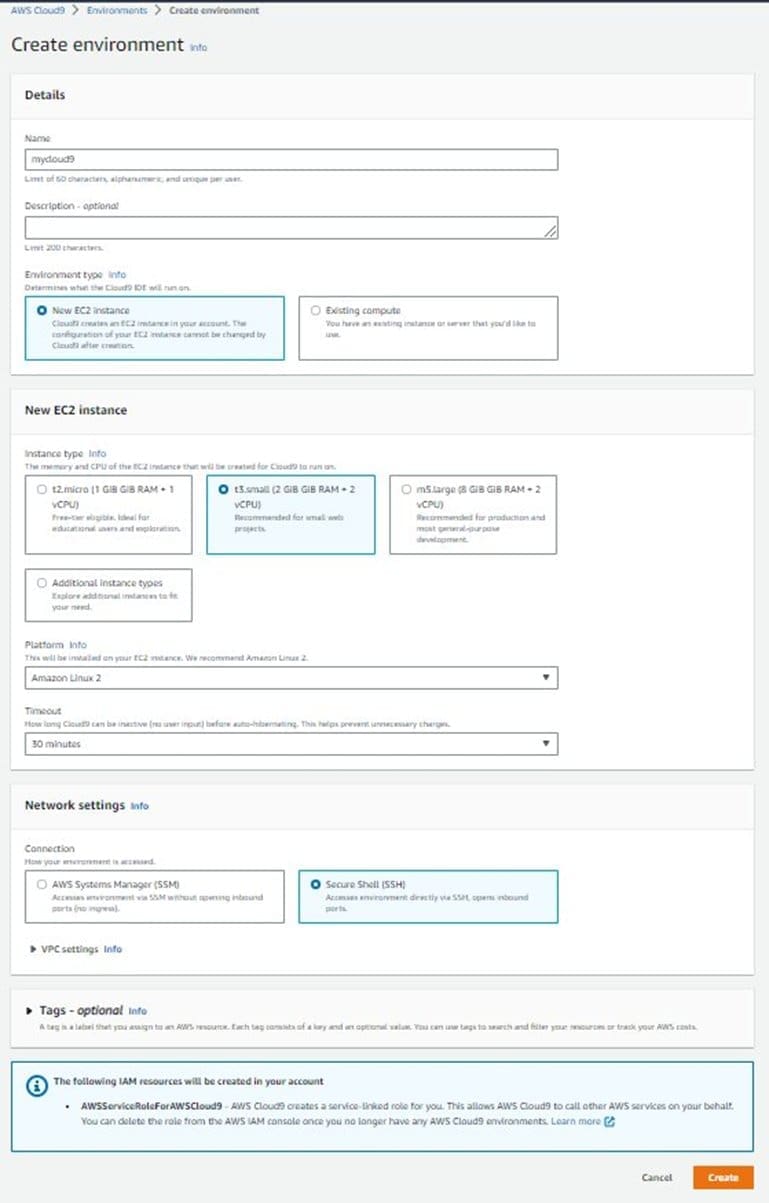
AWS Cloud9 automatically creates and sets up a new Amazon Elastic Compute Cloud (Amazon EC2) instance in your account.
- When the environment is ready, select it and choose Open.

The AWS Cloud9 instance opens in a new terminal tab, as shown in the following screenshot.
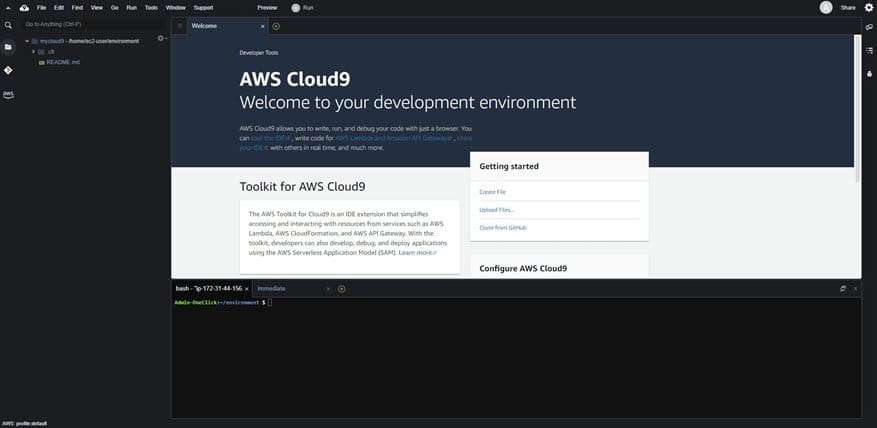
Clone the source code to deploy the solution
Now that your AWS Cloud9 IDE is set up, you can proceed with the following steps to deploy the solution.
Confirm the Node.js version
AWS Cloud9 preinstalls Node.js. You can confirm the installed version by running the following command:
You should see output like the following:
If you’re on v20.x or higher, you can skip to the steps in “Install the AWS CDK” section. If you’re on a different version of Node.js, complete the following steps:
- In an AWS Cloud9 terminal, run the following command to confirm you have the latest version of Node.js Version Manager (nvm) :
- Install Node.js 20:
- Confirm the current Node.js version by running the following command:
Install the AWS CDK
Confirm whether you already have the AWS Cloud Development Kit (AWS CDK) installed. To do this, with the terminal session still open in the IDE, run the following command:
If the AWS CDK is installed, the output contains the AWS CDK version and build numbers. In this case, you can skip to the steps in “Download the source code” section. Otherwise, complete the following steps:
- Install the AWS CDK by running the npm command along with the install action, the name of the AWS CDK package to install, and the -g option to install the package globally in the environment:
- To confirm that the AWS CDK is installed and correctly referenced, run the cdk command with the –version option:
If successful, the AWS CDK version and build numbers are displayed.
Download the source code form the GitHub repo
Complete the following steps to download the source code:
- In an AWS Cloud9 terminal, clone the GitHub repo:
- Run the following commands to create the Sharp npm package and copy the package to the source code:
- Change to the repository directory:
- Run the following command:
The first time you deploy an AWS CDK app into an environment for a specific AWS account and Region combination, you must install a bootstrap stack. This stack includes various resources that the AWS CDK needs to complete its operations. For example, this stack includes an Amazon Simple Storage Service (Amazon S3) bucket that the AWS CDK uses to store templates and assets during its deployment processes.
- To install the bootstrap stack, run the following command:
- From the project’s root directory, run the following command to deploy the stack:
If successful, the output displays that the stack deployed without errors.
The last step is to update the cross-origin resource sharing (CORS) for the S3 bucket.
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Choose the name of the bucket that was created in the AWS CDK deployment step. It should have a name format like multipagepdfa2i-multipagepdf-xxxxxxxxx.
- Choose Permissions.
- In the Cross-origin resource sharing (CORS) section, choose Edit.
- In the CORS configuration editor text box, enter the following CORS configuration:
- Choose Save changes.
Create a private work team
A work team is a group of people you select to review your documents. You can create a work team from a workforce, which is made up of Amazon Mechanical Turk workers, vendor-managed workers, or your own private workers that you invite to work on your tasks. Whichever workforce type you choose, Amazon A2I takes care of sending tasks to workers. For this solution, you create a work team using a private workforce and add yourself to the team to preview the Amazon A2I workflow.
To create and manage your private workforce, you can use the Amazon SageMaker console. You can create a private workforce by entering worker emails or importing a preexisting workforce from an Amazon Cognito user pool.
To create your private work team, complete the following steps:
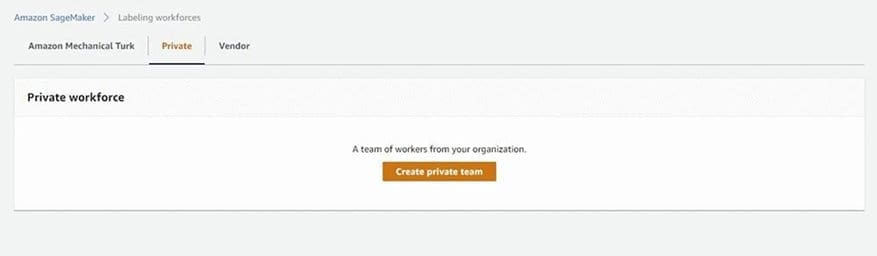
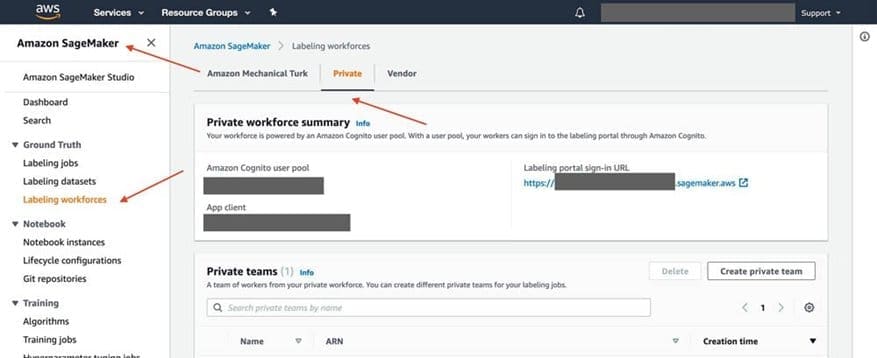
- On the SageMaker console, choose Labeling workforces under Ground Truth in the navigation pane.
- On the Private tab, choose Create private team.

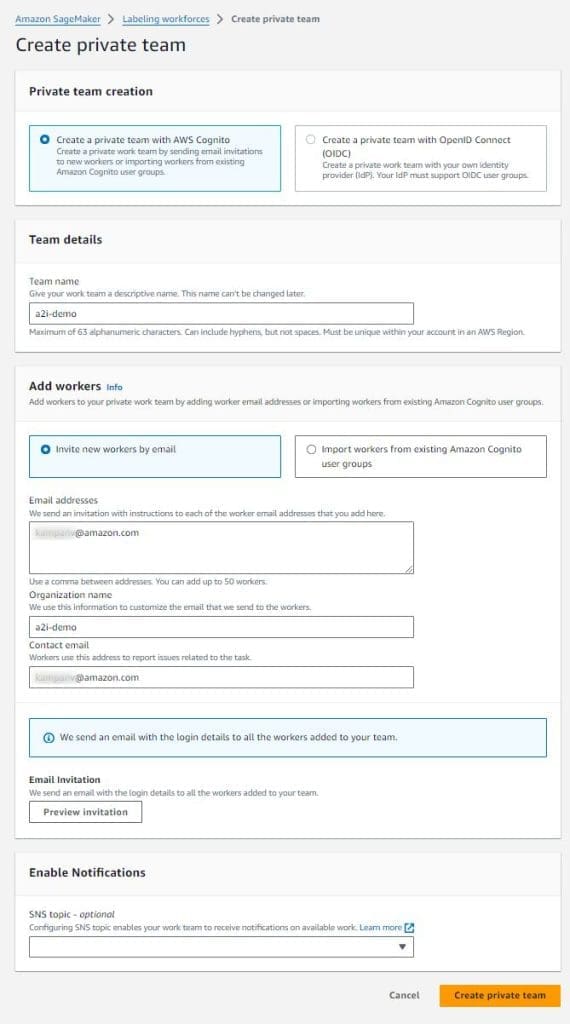
- Choose Invite new workers by email.
- In the Email addresses box, enter the email addresses for your work team (for this post, enter your email address).
You can enter a list of up to 50 email addresses, separated by commas.
- Enter an organization name and contact email.
- Choose Create private team.
After you create the private team, you get an email invitation. The following screenshot shows an example email.
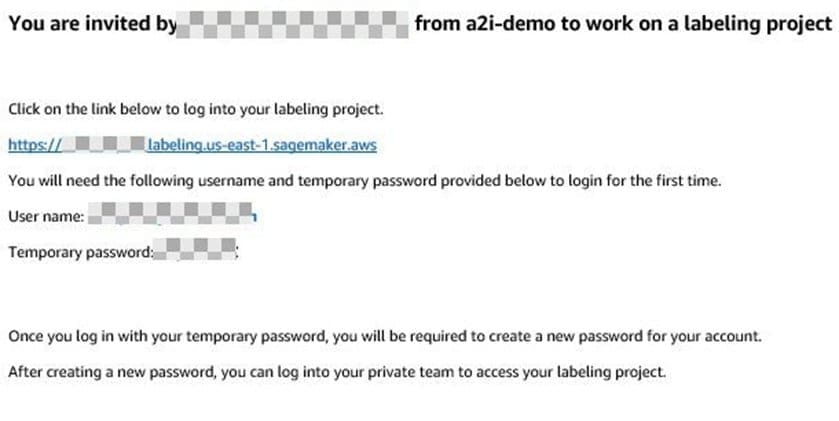
After you choose the link and change your password, you will be registered as a verified worker for this team. The following screenshot shows the updated information on the Private tab.
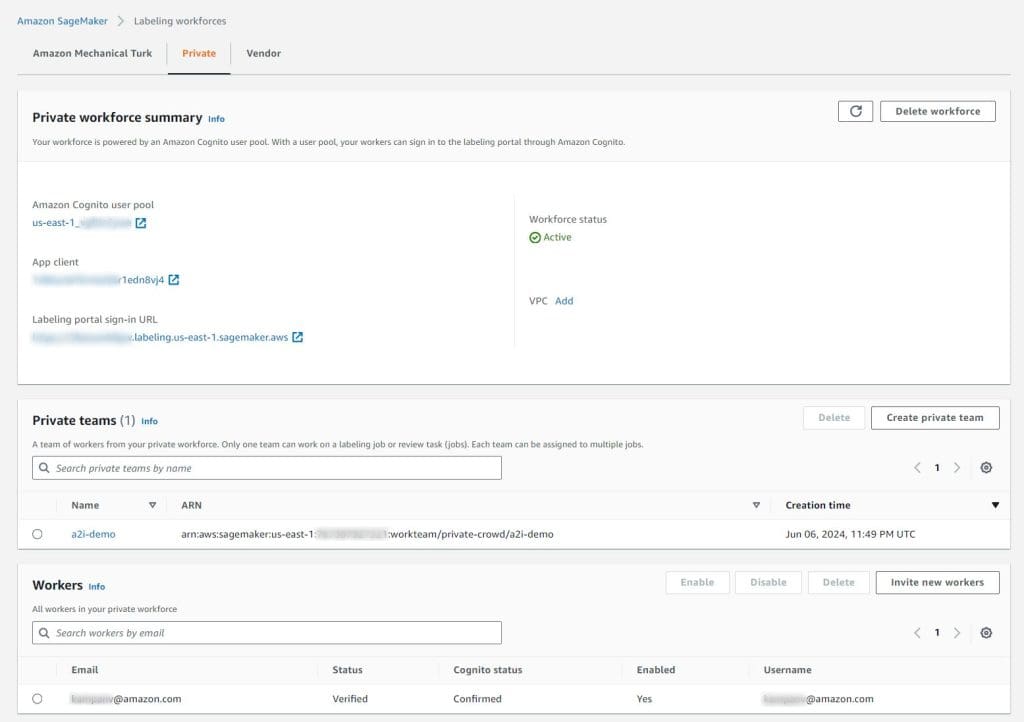
Your one-person team is now ready, and you can create a human review workflow.
Create a human review workflow
You define the business conditions under which the Amazon Bedrock extracted content should go to a human for review. These business conditions are set in Parameter Store, a capability of AWS Systems Manager. For example, you can look for specific keys in the document. When the extraction is complete, in the AWS Lambda function, check for those keys and their values. If the key is not present or the value is blank, the form will go for human review.
Complete the following steps to create a worker task template for your document review task:
- On the SageMaker console, choose Worker task templates under Augmented AI in the navigation pane.
- Choose Create template.
- In the template properties section, enter a unique template name for Template name and select Custom for Template type.
- Copy the contents from the Custom template file you downloaded from GitHub repo and replace the content in the Template editor section.
- Choose Create and the template will be created successfully.

Next, you create instructions to help workers complete your document review task.
- Choose Human review workflows under Augmented AI in the navigation pane.
- Choose Create human review workflow.
- In the Workflow settings section, for Name, enter a unique workflow name.
- For S3 bucket, enter the S3 bucket that was created in the AWS CDK deployment step. It should have a name format like
multipagepdfa2i-multipagepdf-xxxxxxxxx.
This bucket is where Amazon A2I will store the human review results.
- For IAM role, choose Create a new role for Amazon A2I to create a role automatically for you.
- For S3 buckets you specify, select Specific S3 buckets.
- Enter the S3 bucket you specified earlier in Step 9; for example,
multipagepdfa2i-multipagepdf-xxxxxxxxxx. - Choose Create.
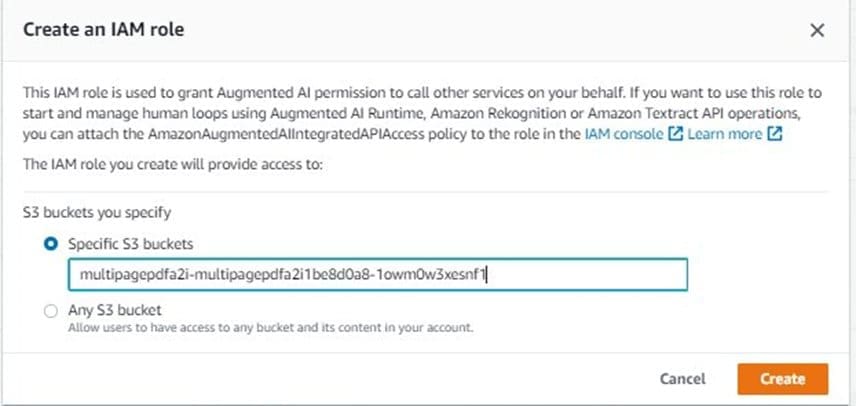
You see a confirmation when role creation is complete, and your role is now pre-populated on the IAM role dropdown menu.
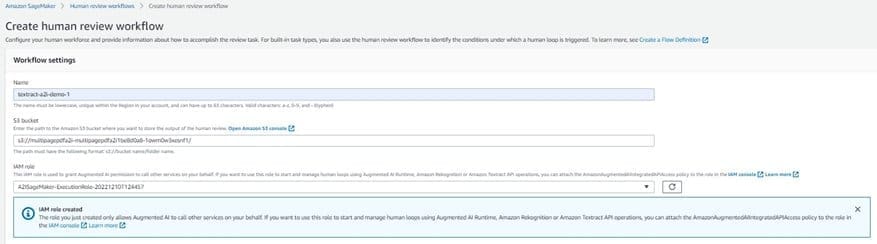
- For Task type, select Custom.
- In the worker task template section, choose the template that you previously created.
- For Task Description, enter “Review the extracted content from the document and make changes as needed”.
- For Worker types, select Private.
- For Private teams, choose the work team you created earlier.
- Choose Create.
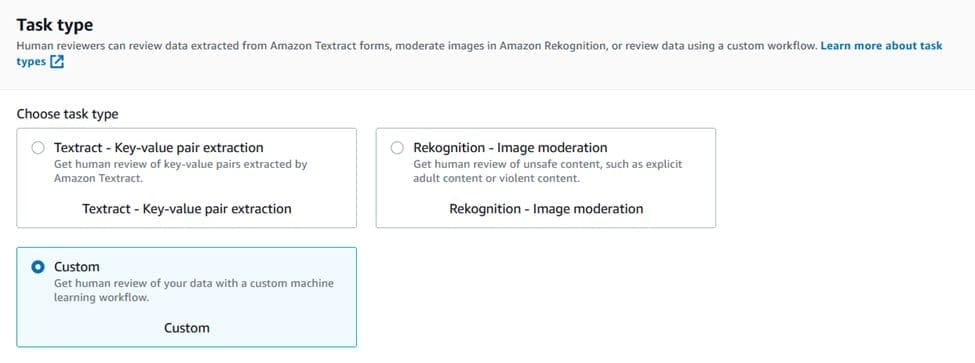

You’re redirected to the Human review workflows page, where you will see a confirmation message.
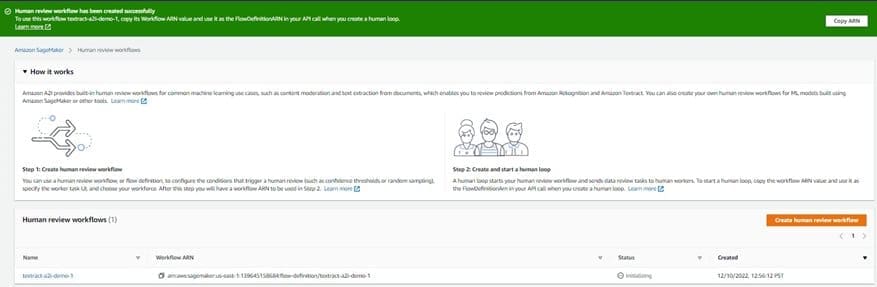
In a few seconds, the status of the workflow will be changed to active. Record your new human review workflow ARN, which you use to configure your human loop in a later step.
Update the solution with the human review workflow
You’re now ready to add your human review workflow Amazon Resource Name (ARN):
- Within the code you downloaded from GitHub repo, open the file
- Update line 23 with the ARN that you copied earlier:
- Save the changes you made.
- Deploy by entering the following command:
Test the solution without business rules validation
To test the solution without using a human review, create a folder called uploads in the S3 bucket multipagepdfa2i-multipagepdf-xxxxxxxxx and upload the sample PDF document provided. For example, uploads/Vital-records-birth-application.pdf.
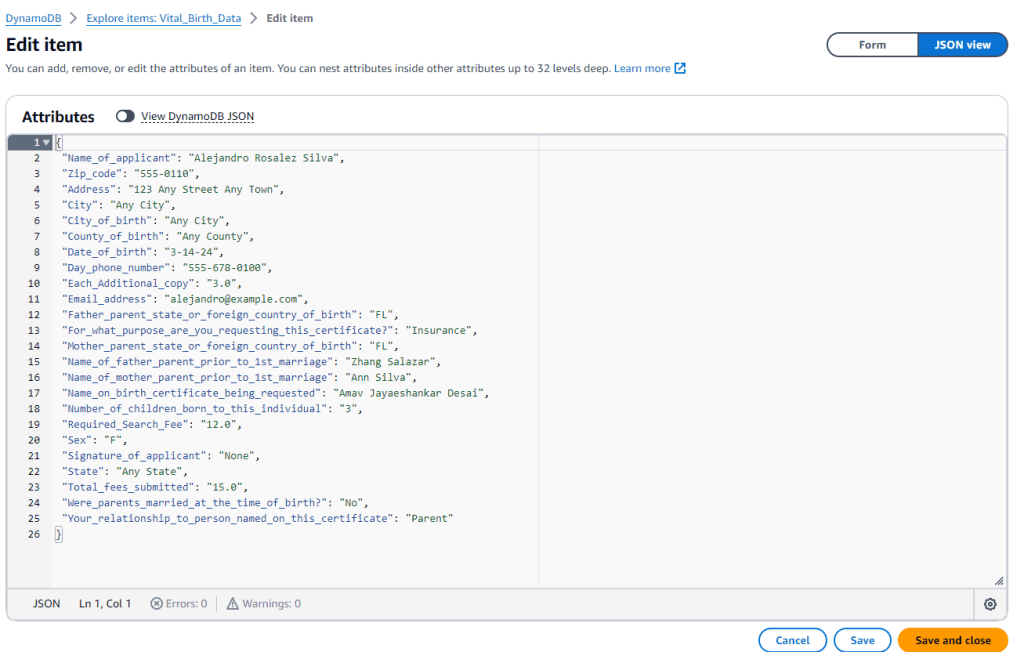
The content will be extracted, and you will see the data in the DynamoDB table
multipagepdfa2i-ddbtableVitalBirthDataXXXXX
Test the solution with business rules validation
Complete the following steps to test the solution with a human review:
- On the Systems Manager console , choose Parameter Store in the navigation pane.
- Select the Parameter
/business_rules/validationrequiedand update the value to yes. - upload the sample PDF document provided to the
uploadsfolder that you created earlier in the S3 bucketmultipagepdfa2i-multipagepdf-xxxxxxxxx - On the SageMaker console, choose Labeling workforces under Ground Truth in the navigation pane.
- On the Private tab, choose the link under Labeling portal sign-in URL.
- Sign in with the account you configured with Amazon Cognito.
- Select the job you want to complete and choose Start working.

In the reviewer UI, you will see instructions and the document to work on. You can use the toolbox to zoom in and out, fit image, and reposition the document.
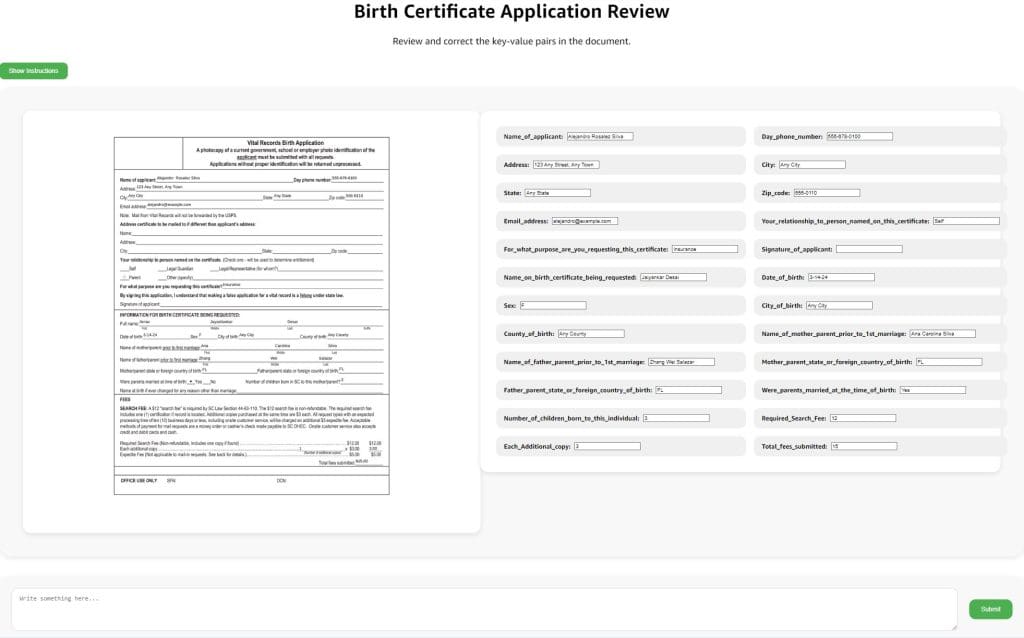
This UI is specifically designed for document-processing tasks. On the right side of the preceding screenshot, the extracted data is automatically prefilled with the Amazon Bedrock response. As a worker, you can quickly refer to this sidebar to make sure the extracted information is identified correctly.
When you complete the human review, you will see the data in the DynamoDB table
multipagepdfa2i-ddbtableVitalBirthDataXXXXX
Conclusion
In this post, we showed you how to use the Anthropic Claude 3 Haiku model on Amazon Bedrock and Amazon A2I to automatically extract data from multipage PDF documents and images. We also demonstrated how to conduct a human review of the pages for given business criteria. By eliminating the need for complex postprocessing, handling larger file sizes, and integrating a flexible human review process, this solution can help your business unlock the true value of your documents, drive informed decision-making, and gain a competitive edge in the market.
Overall, this post provides a roadmap for building an scalable document processing workflow using Anthropic Claude models on Amazon Bedrock.
As next steps, check out What is Amazon Bedrock to start using the service. Follow the Amazon Bedrock on the AWS Machine Learning Blog to keep up to date with new capabilities and use cases for Amazon Bedrock.
About the Authors
 Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Venkata Kampana is a Senior Solutions Architect in the AWS Health and Human Services team and is based in Sacramento, CA. In that role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
 Jim Daniel is the Public Health lead at Amazon Web Services. Previously, he held positions with the United States Department of Health and Human Services for nearly a decade, including Director of Public Health Innovation and Public Health Coordinator. Before his government service, Jim served as the Chief Information Officer for the Massachusetts Department of Public Health.
Jim Daniel is the Public Health lead at Amazon Web Services. Previously, he held positions with the United States Department of Health and Human Services for nearly a decade, including Director of Public Health Innovation and Public Health Coordinator. Before his government service, Jim served as the Chief Information Officer for the Massachusetts Department of Public Health.
Leave a Reply