
Enhance your media search experience using Amazon Q Business and Amazon Transcribe
In today’s digital landscape, the demand for audio and video content is skyrocketing. Organizations are increasingly using media to engage with their audiences in innovative ways. From product documentation in video format to podcasts replacing traditional blog posts, content creators are exploring diverse channels to reach a wider audience. The rise of virtual workplaces has also led to a surge in content captured through recorded meetings, calls, and voicemails. Additionally, contact centers generate a wealth of media content, including support calls, screen-share recordings, and post-call surveys.
We are excited to introduce Mediasearch Q Business, an open source solution powered by Amazon Q Business and Amazon Transcribe. Mediasearch Q Business builds on the Mediasearch solution powered by Amazon Kendra and enhances the search experience using Amazon Q Business. Mediasearch Q Business supercharges the way you consume media files by using them as part of the knowledge base used by Amazon Q Business to generate reliable answers to user questions. The solution also features an enhanced Amazon Q Business query application that allows users to play the relevant section of the original media files or YouTube videos directly from the search results page, providing a seamless and intuitive user experience.
Solution overview
Mediasearch Q Business is straightforward to install and try out.
The solution has two components, as illustrated in the following diagram:
- A Mediasearch indexer that transcribes media files (audio and video) on an Amazon Simple Storage Service (Amazon S3) bucket or media from a YouTube playlist and ingests the transcriptions into either an Amazon Q Business native index (configured as part of the Amazon Q Business application) or an Amazon Kendra
- A Mediasearch finder, which provides a UI and makes API calls to the Amazon Q Business service APIs on behalf of the logged-in user. The response from API calls are displayed to the end-user.
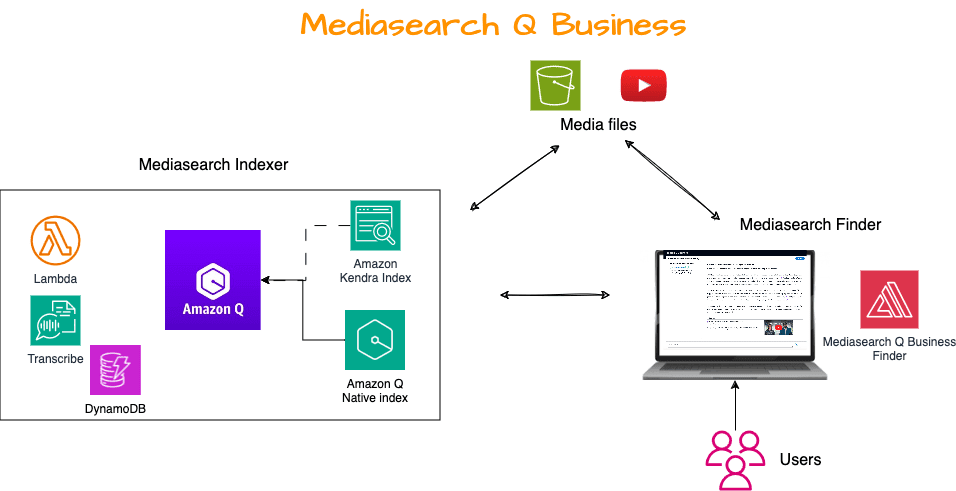
The Mediasearch indexer finds and transcribes audio and video files stored in an S3 bucket. The indexer can also index YouTube videos from a YouTube playlist as audio files and transcribe these audio files. It prepares the transcriptions by embedding time markers at the start of each sentence, and it indexes each prepared transcription in an Amazon Q Business native retriever or an Amazon Kendra retriever. The indexer runs the first time when you install it, and subsequently runs on an interval that you specify, maintaining the index to reflect any new, modified, or deleted files.
The Mediasearch finder is a web search client that you use to search for content in your Amazon Q Business application. Additionally, the Mediasearch finder includes in-line embedded media players in the search result, so you can see the relevant section of the transcript, and play the corresponding section from the original media (audio files and video files in your media bucket or a YouTube video) without navigating away from the search page.
In the sections that follow, we discuss the following topics:
- How to deploy the solution to your AWS account
- How to use it to index and search sample media files
- How to use the solution with your own media files
- How the solution works
- The estimated costs involved
- How to monitor usage and troubleshoot problems
- Options to customize and tune the solution
- How to uninstall and clean up when you’re done experimenting
Prerequisites
Make sure you have the following:
- An AWS account where you can launch an AWS CloudFormation stack
- An AWS IAM Identity Center instance ARN that would be used by the Amazon Q Business application to provide access to users
Deploy the Mediasearch Q Business solution
In this section, we walk through deploying the two solution components: the indexer and the finder. We use a CloudFormation stack to deploy the necessary resources in the us-east-1 AWS Region.
If you’re deploying the solution to another Region, follow the instructions in the README available in the Mediasearch Q Business GitHub repository.
Deploy the Mediasearch Q Business indexer component
To deploy the indexer component, complete the following steps:
- Choose Launch Stack.

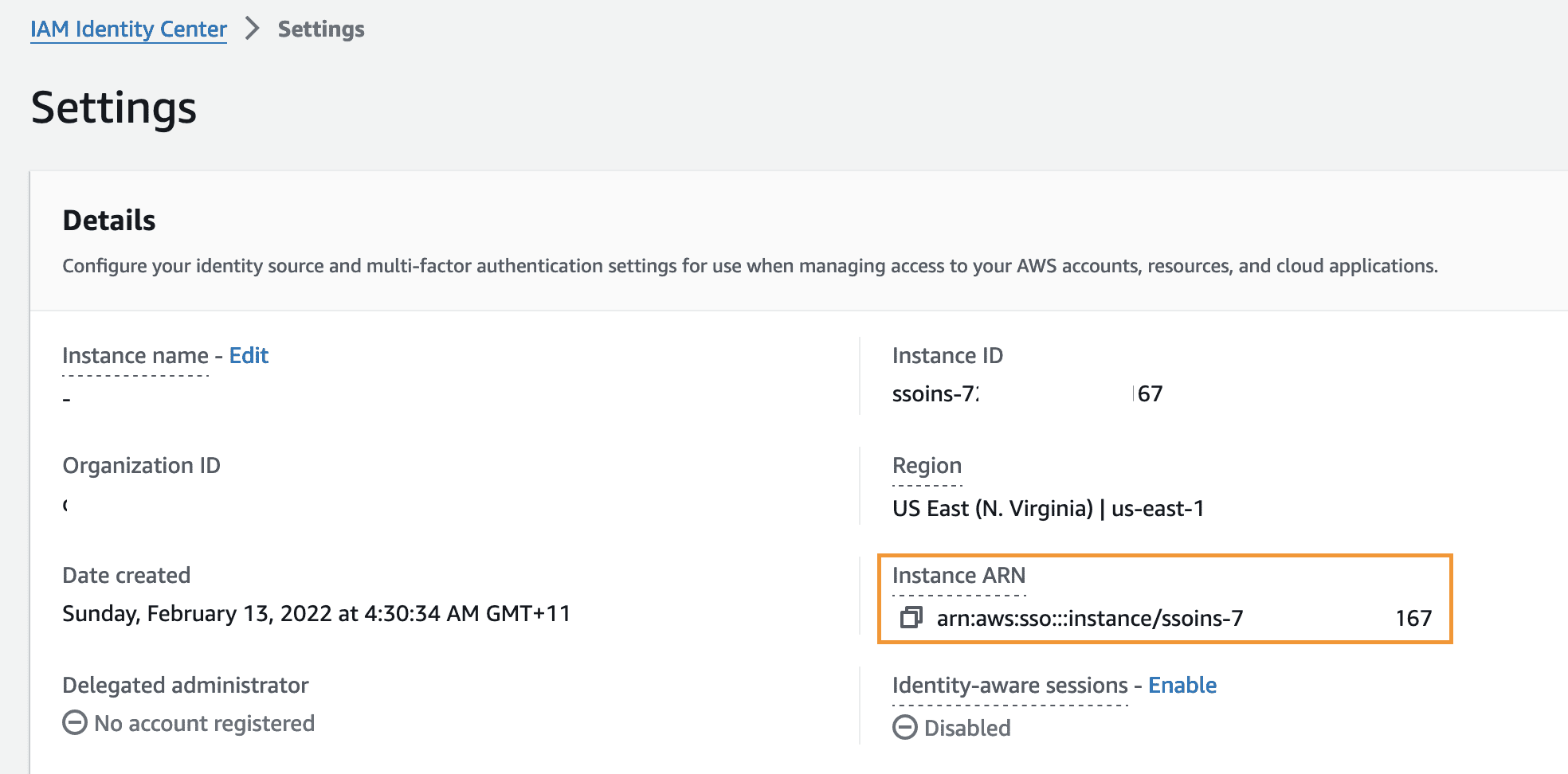
- In the Identity center ARN and Retriever selection section, for IdentityCenterInstanceArn, enter the ARN for your IAM Identity Center instance.
You can find the ARN on the Settings page of the IAM Identity Center console. The ARN is a required field.
- Use default values for all other parameters. We will customize these values later to suit your specific requirements.
- Acknowledge that the stack might create IAM resources with custom names, then choose Create stack.
The indexer stack takes around 10 minutes to deploy. Wait for the indexer to finish deploying before you deploy the Mediasearch Q Business finder.
Deploy the Mediasearch Q Business finder component
The Mediasearch finder uses Amazon Cognito to authenticate users to the solution. For an authenticated user to interact with an Amazon Q Business application, you must configure an IAM Identity Center customer managed application that either supports SAML 2.0 or OAuth 2.0.
In this post, we create a customer managed application that supports OAuth 2.0, a secure way for applications to communicate and share user data without exposing passwords. We use a technique called trusted identity propagation, which allows the Mediasearch Q Business finder app to access the Amazon Q service securely without sharing passwords between the two identity providers (Amazon Cognito and IAM Identity Center in our example).
Instead of sharing passwords, trusted identity propagation uses tokens. Tokens are like digital certificates that prove who the user is and what they’re allowed to do. AWS managed applications that work with trusted identity propagation get tokens directly from IAM Identity Center. IAM Identity Center can also exchange identity tokens and access tokens from external authorization servers like Amazon Cognito. This lets an application authenticate users and obtain tokens outside of AWS (like with Amazon Cognito, Microsoft Entra ID, or Okta), exchange that token for an IAM Identity Center token, and then use the new token to request access to AWS services like Amazon Q Business.
For more information, see Using trusted identity propagation with customer managed applications.
When the IAM Identity Center instance is in the same account where you are deploying the Mediasearch Q Business solution, the finder stack allows you to automatically create the IAM Identity Center customer managed application as part of the stack deployment.
If you use the organization instance of IAM Identity Center enabled in your management account, then you will be deploying the Mediasearch Q Business finder stack in a different AWS account. In this case, follow the steps in the README to create an IAM Identity Center application manually.
To deploy the finder component and create the IAM Identity Center customer managed application, complete the following steps:
- Choose Launch Stack.
- For IdentityCenterInstanceArn, enter the ARN for the IAM Identity Center instance. This is the same value you used while deploying the indexer stack.
- For CreateIdentityCenterApplication, choose Yes to create the IAM Identity Center application for the Mediasearch finder application.
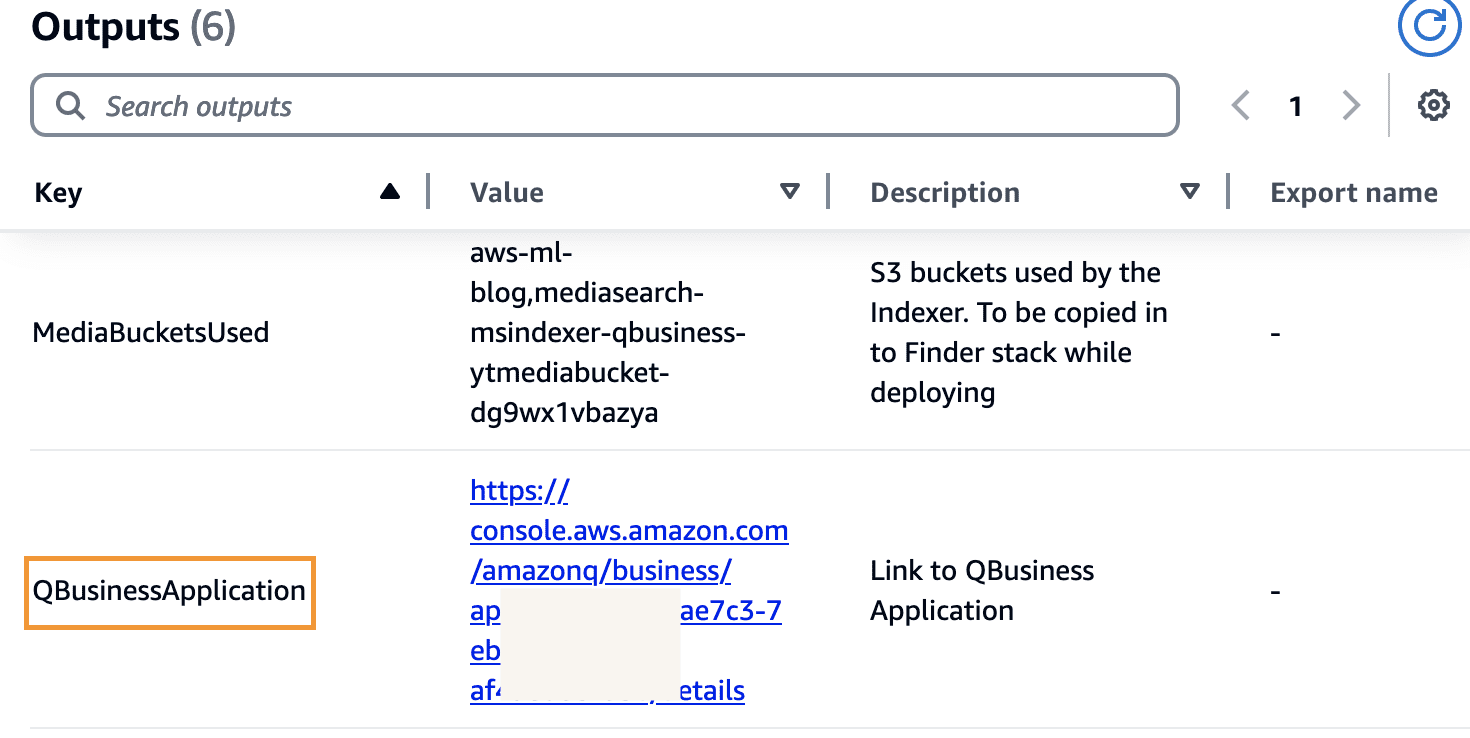
- Under Mediasearch Indexer parameters, enter the Amazon Q Business application ID that was created by the indexer stack. You can copy this from the
QBusinessApplicationIdoutput of the indexer stack. - Select the retriever type that was used to deploy the Mediasearch indexer. (If you deployed an Amazon Kendra index, then select Kendra, otherwise select Native.
- If you selected Kendra, enter the Amazon Kendra index ID that was used by the indexer stack.
- For MediaBucketNames, use the
MediaBucketsUsedoutput from the indexer CloudFormation stack to allow the search page to access media files acrossYTMediaBucketand Mediabucket. - Acknowledge that the stack might create IAM resources with custom names, then choose Create stack.
Configure user access to Amazon Q Business
To access the Mediasearch Q Business solution, add a user with an appropriate subscription to the Amazon Q Business application and to the IAM Identity Center customer managed application.
Add a user to the Amazon Q Business application
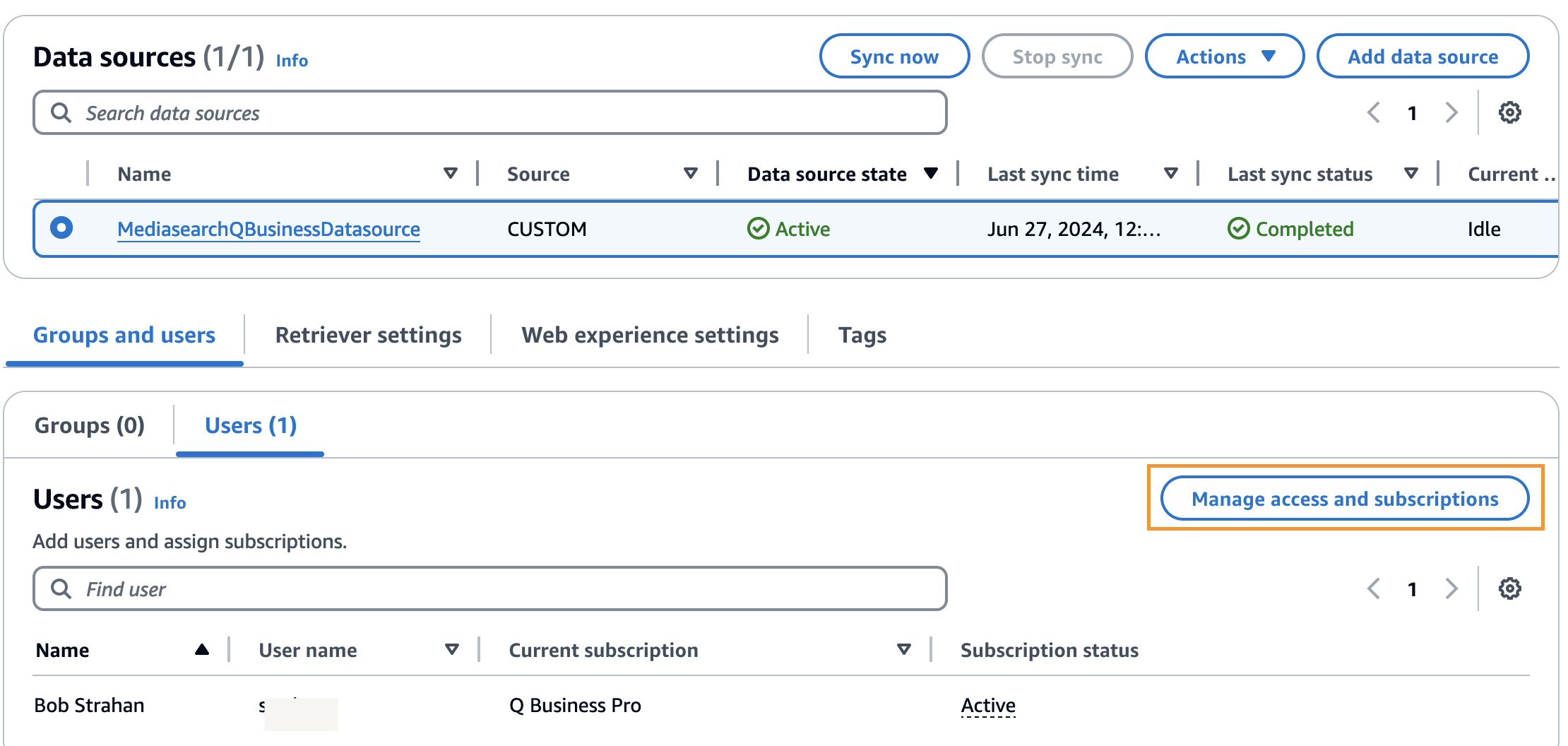
To start using the Amazon Q Business application, you can add users or groups to the Amazon Q Business application from your IAM Identity Center instance. Complete the following steps to add a user to the application:
- Access the Amazon Q Business application by choosing the link for
QBusinessApplicationin the indexer CloudFormation stack outputs.
- Under Groups and users, on the Users tab, choose Manage access and subscription.
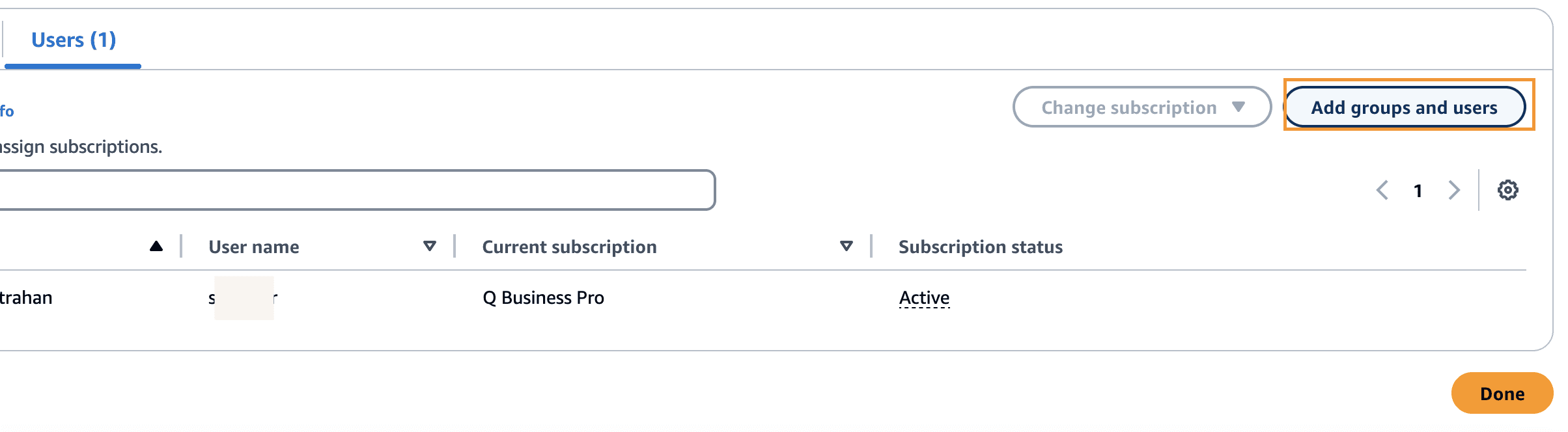
- Choose Add groups and users.
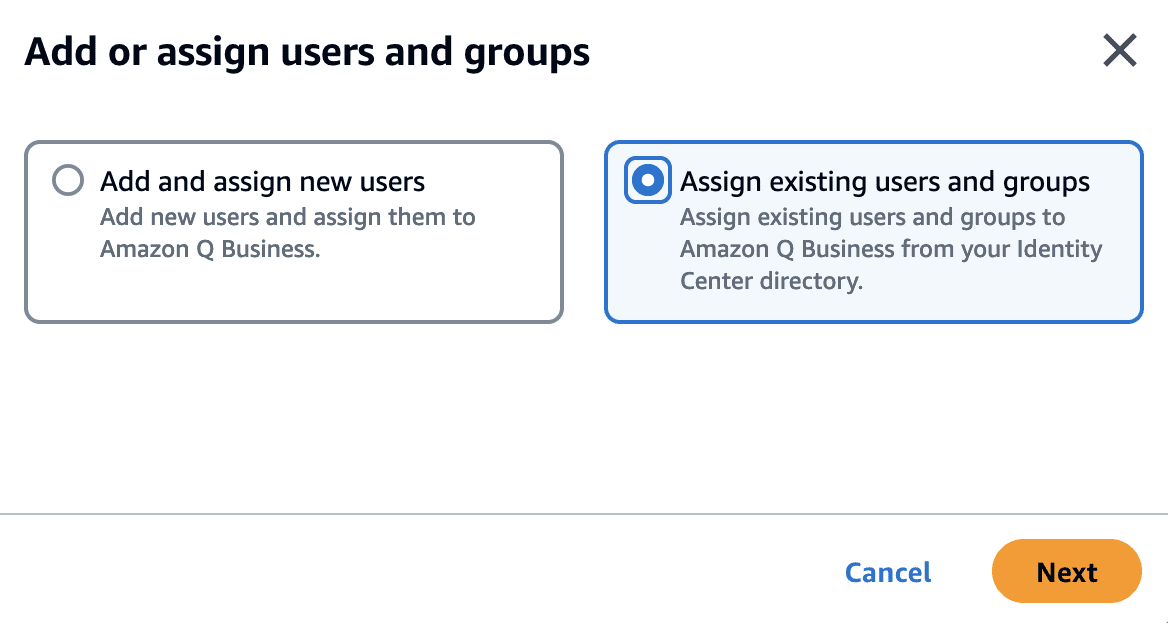
- Choose Add existing users and groups.
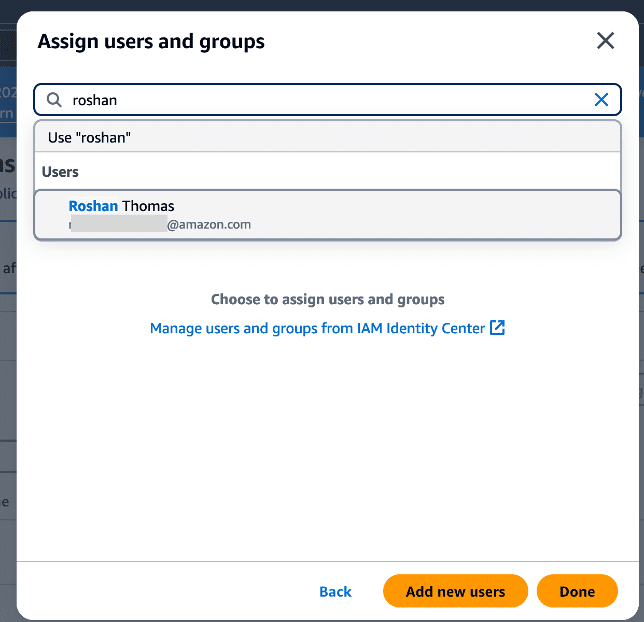
- Search for an existing user, choose the user, and choose Assign.
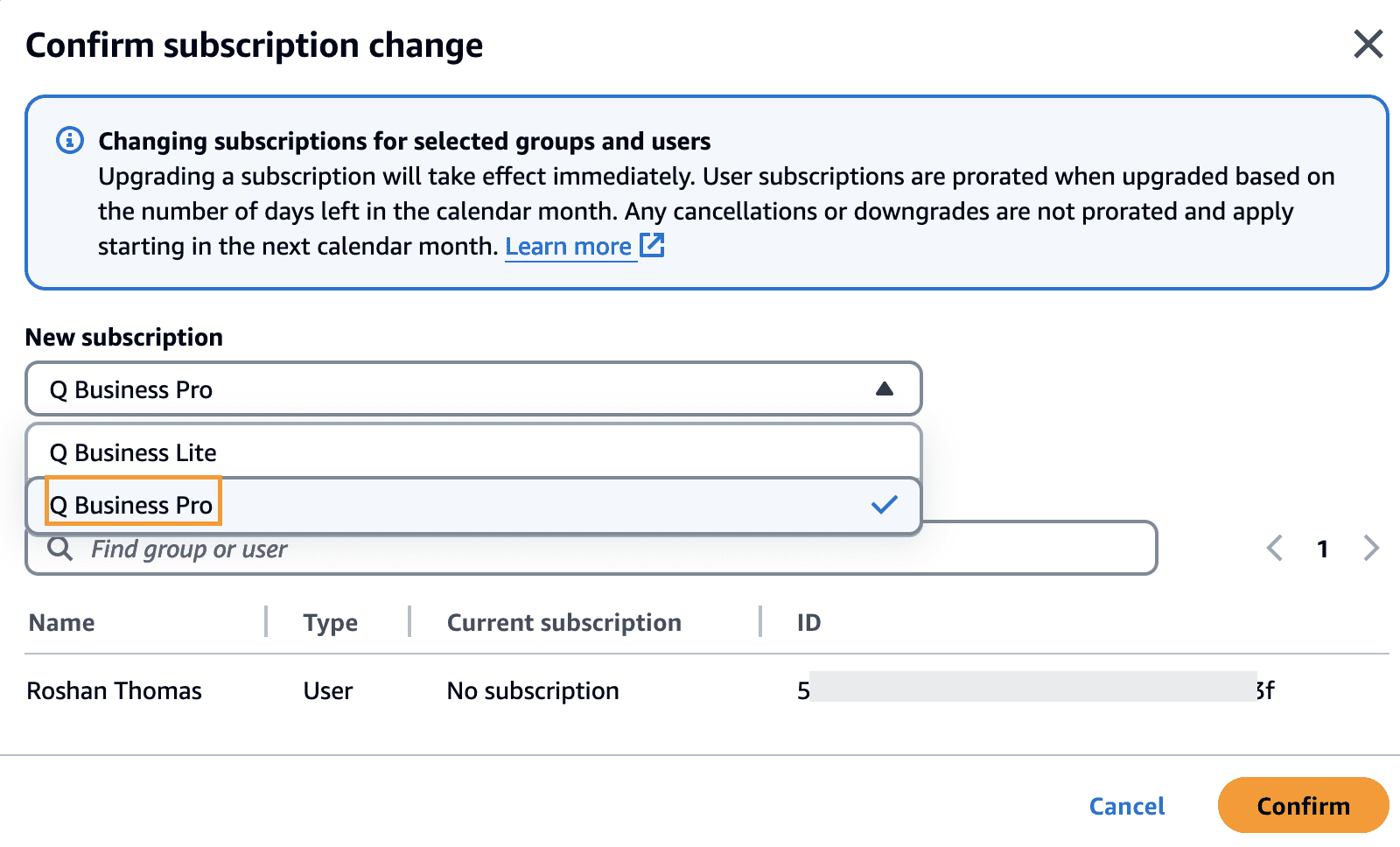
- Select the added user and on the Change subscription menu, choose Update subscription tier.
- Select the appropriate subscription tier and choose Confirm.
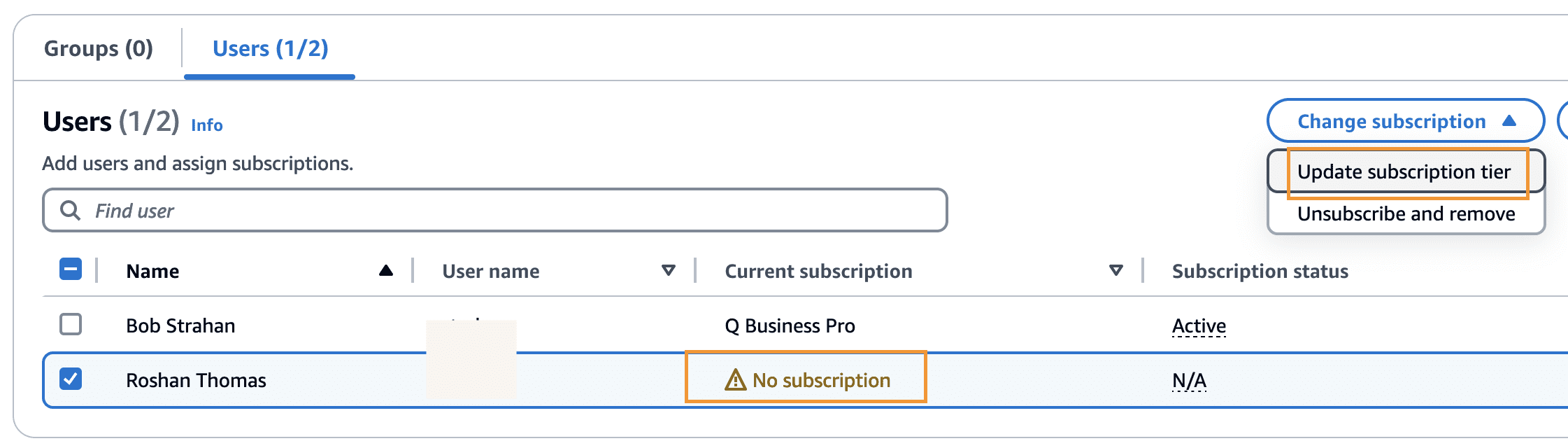
For details of each Amazon Q subscription, refer to Amazon Q Business pricing.
Assign users to the IAM Identity Center customer managed application
Now you can assign users or groups to the IAM Identity Center customer managed application. Complete the following steps to add a user:
- From the outputs section of the finder CloudFormation stack, choose the URL for
IdentityCenterApplicationConsoleURLtonavigate to the customer managed application.
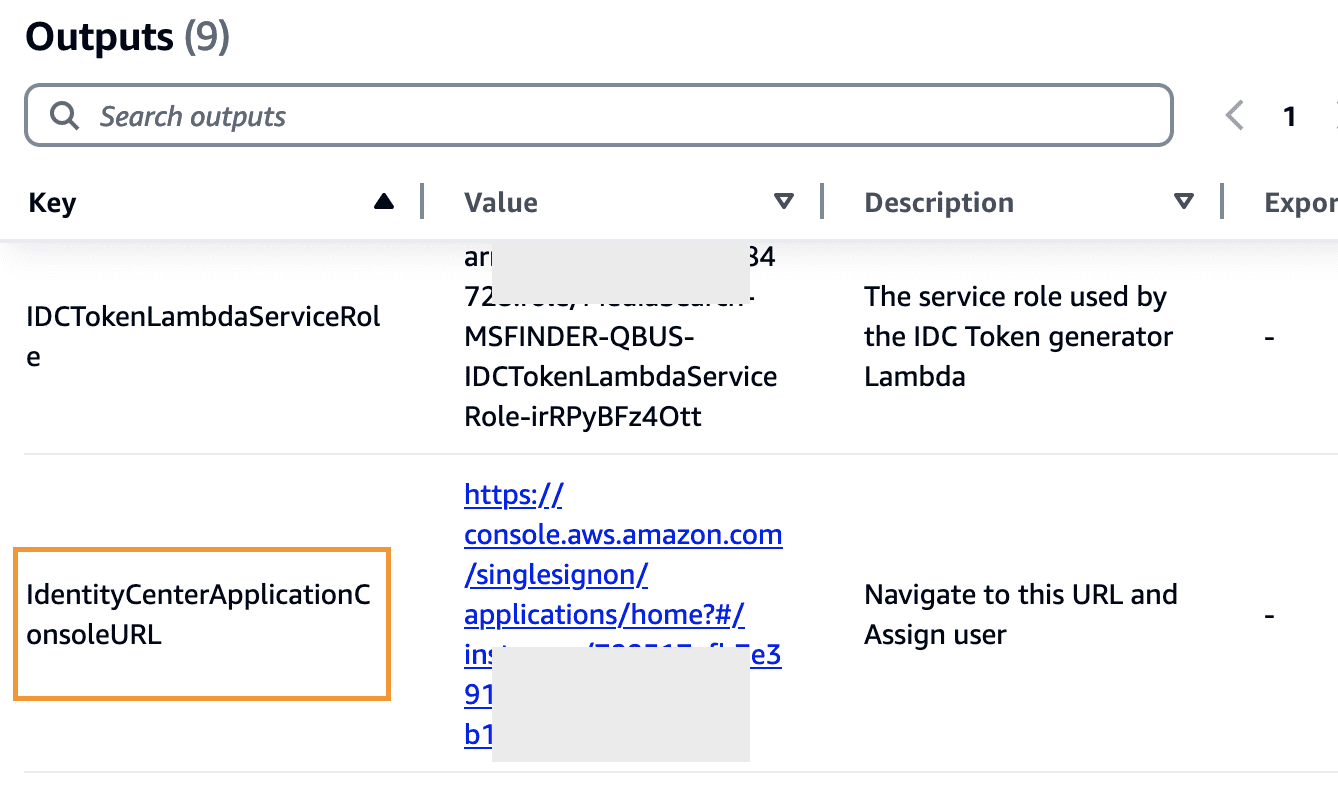
- Choose Assign users and groups.
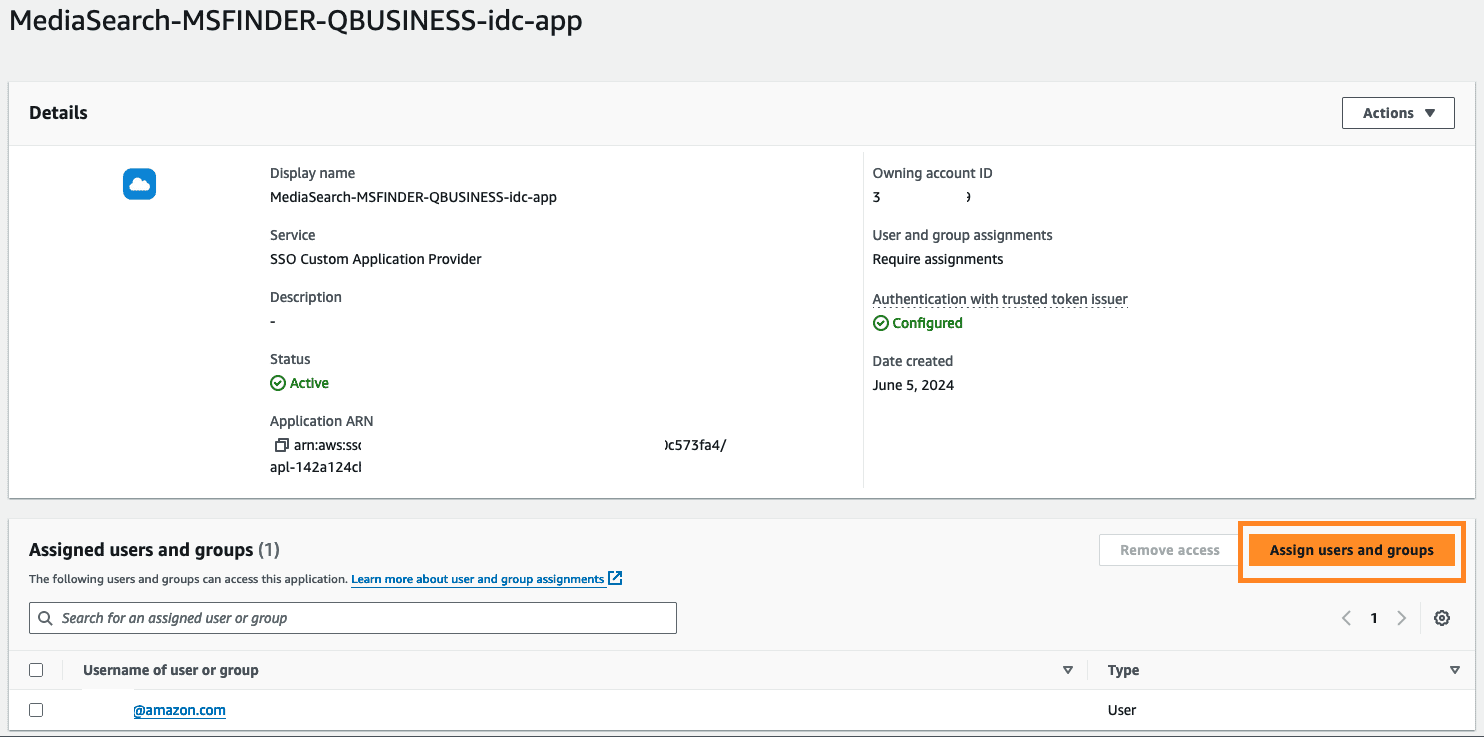
- Select users and choose Assign users.
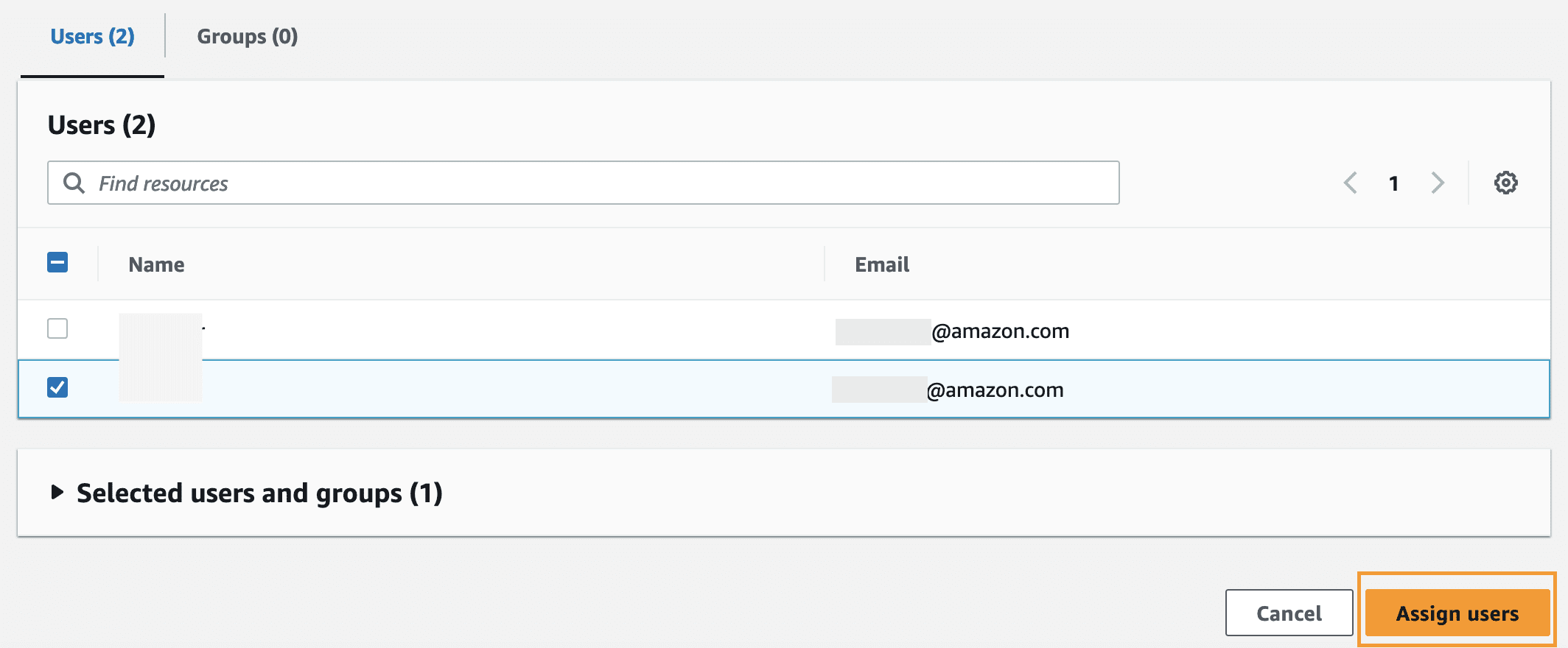
This concludes the user access configuration to the Mediasearch Q Business solution.
Test with the sample media files
When the Mediasearch indexer and finder stack are deployed, the indexer should have completed processing the audio (mp3) files for the YouTube videos and sample media files (selected AWS Podcast episodes and AWS Knowledge Center videos). You can now run your first Mediasearch query.
- To log in to the Mediasearch finder application, choose the URL for
MediasearchFinderURLin the stack outputs.
The Mediasearch finder application in your browser will show a splash page for Amazon Q Business.
- Choose Get Started to access the Amazon Cognito page.

To access Mediasearch Q Business, you need to log in to the application using a user ID in the Amazon Cognito user pool created by the finder stack. The email address in Amazon Cognito must match the email address for the user in IAM Identity Center. Alternatively, the Mediasearch solution allows you to create a user through the application.
- On the Create Account tab, enter your email (which matches the email address in IAM Identity Center), followed by a password and password confirmation, and choose Create Account.
Amazon Cognito will send an email with a confirmation code for email verification.
- Enter this confirmation code to complete your email verification.
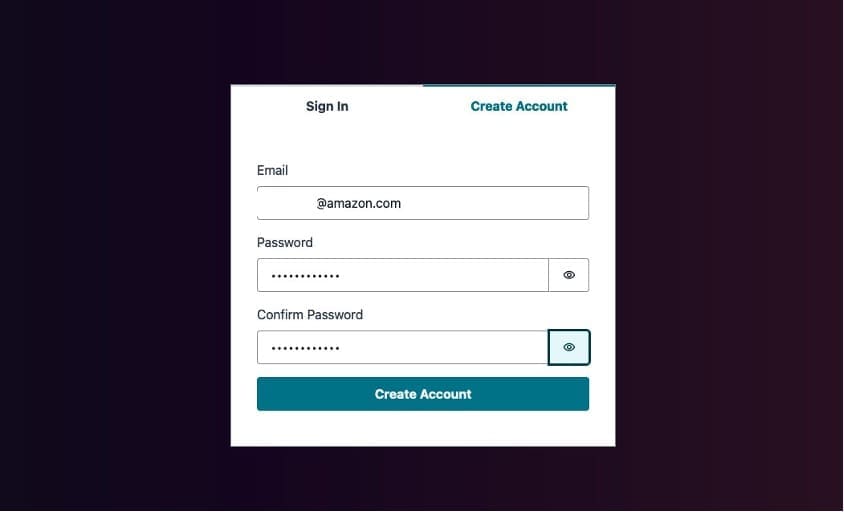
- After email verification, you will now be able to log in to the Mediasearch Q Business application.
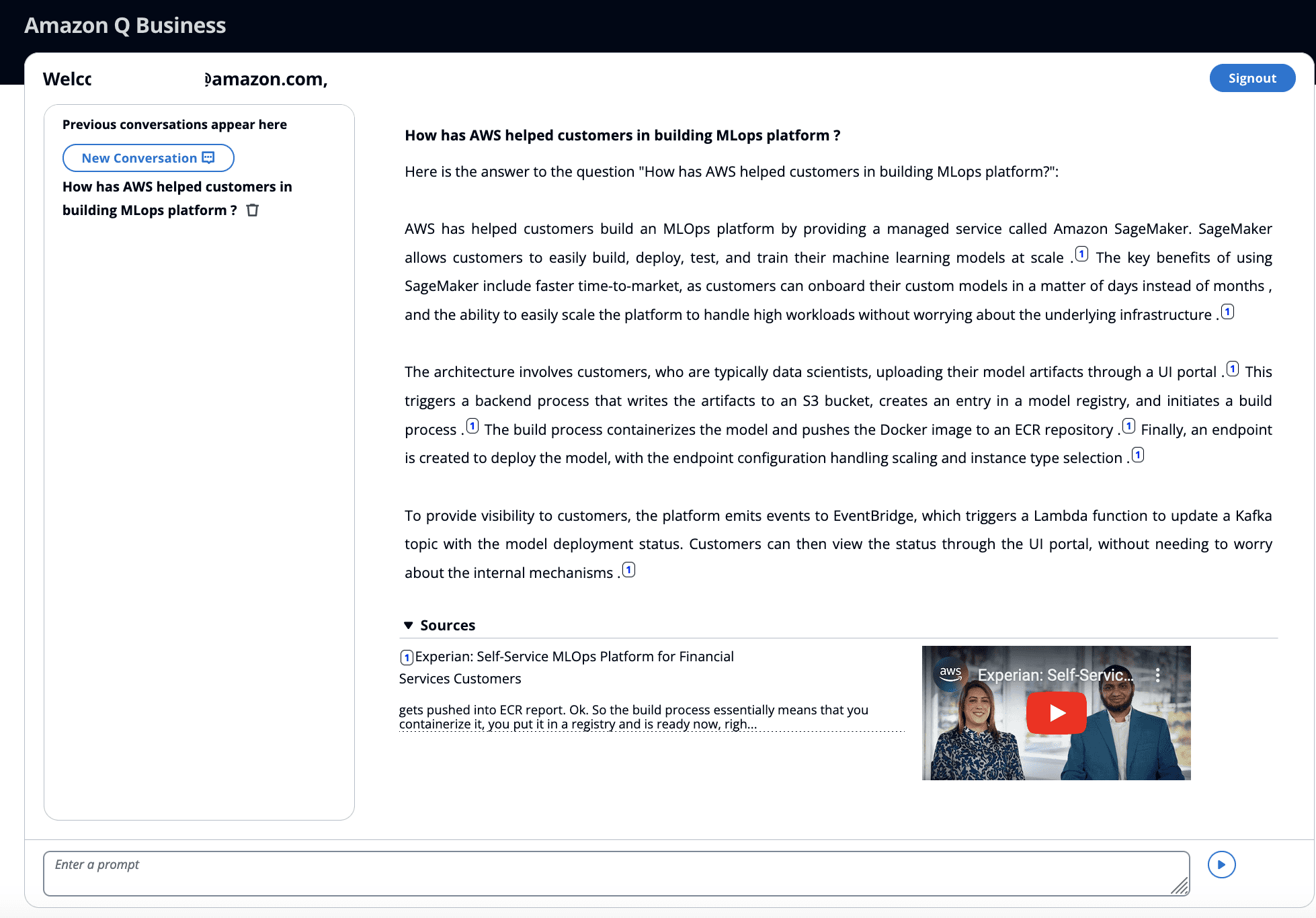
- After you’re logged in, in the Enter a prompt box, write a query, such as “What is AWS Fargate?”
The query returns a response from Amazon Q Business based on the media (sample media files and YouTube audio sources) ingested into the index.
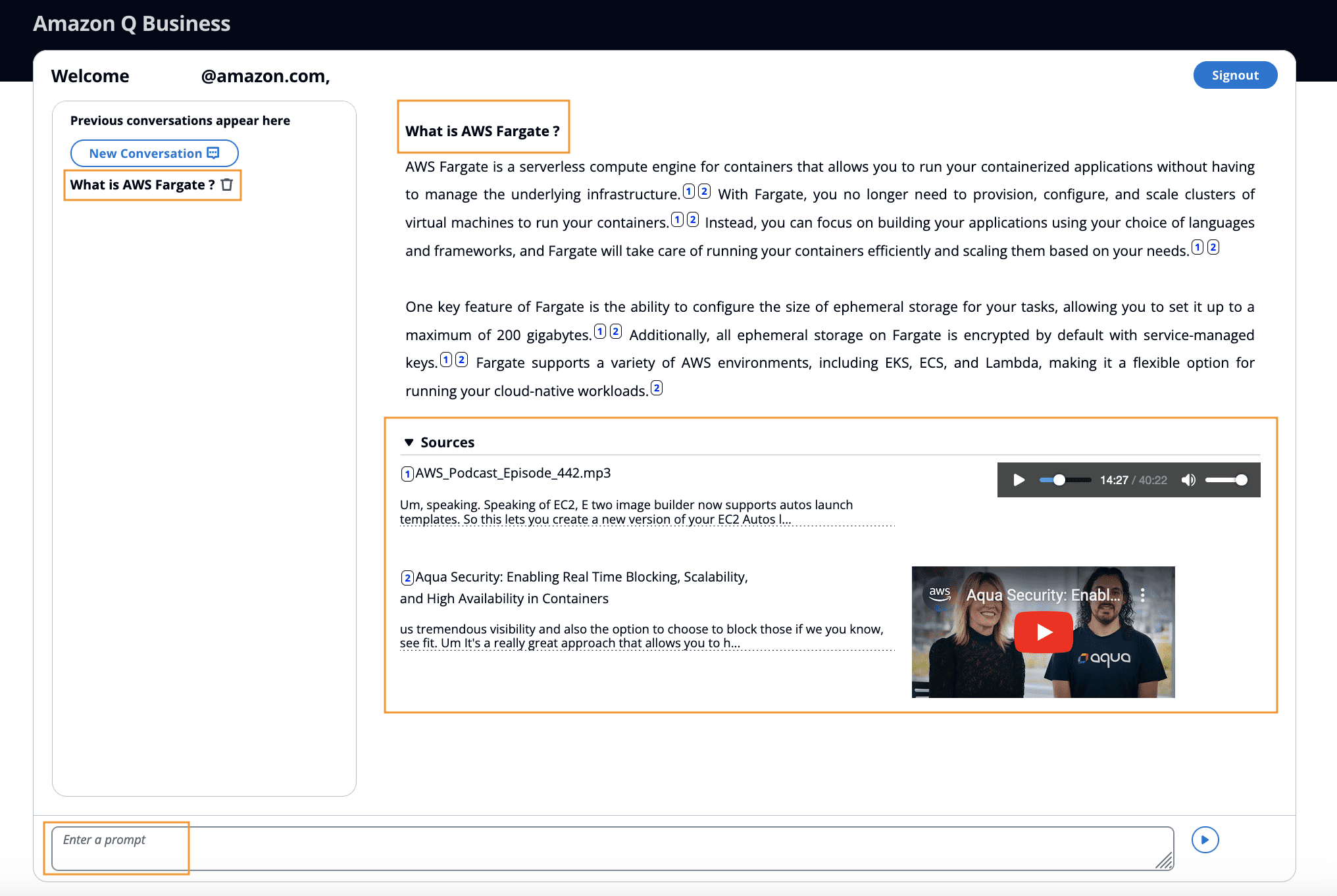
The response includes citations, with reference to sources. Users can verify their answer from Amazon Q Business by playing media files from their S3 buckets or YouTube starting at the time marker where the relevant information is found.
- Use the embedded video player to play the original video inline. Observe that the media playback starts at the relevant section of the video based on the time marker.
- To play the video full screen in a new browser tab, use the Full screen menu option in the player, or choose the media file hyperlink shown above the answer text.
- Choose (right-click) the video file hyperlink, copy the URL, and enter it into a text editor.
If the media is an audio file for a YouTube video, it looks something like the following:
https://www.youtube.com/watch?v=unFVfqj9cQ8&t=36.58s
If the media file is a non-YouTube audio file that resides in MediaBucket, the URL looks like the following:
https://mediasearchtest.s3.amazonaws.com/mediasamples/What_is_an_Interface_VPC_Endpoint_and_how_can_I_create_Interface_Endpoint_for_my_VPC_.mp4?AWSAccessKeyId=ASIAXMBGHMGZLSYWJHGD&Expires=1625526197&Signature=BYeOXOzT585ntoXLDoftkfS4dBU%3D&x-amz-security-token=.... #t=253.52
This is a presigned S3 URL that provides your browser with temporary read access to the media file referenced in the search result. Using presigned URLs means you don’t need to provide permanent public access to all of your indexed media files.
- Experiment with additional queries, such as “How has AWS helped customers in building MLOps platform?” or “How can I use Generative AI to improve customer experience?” or try your own questions.
Index and search your own media files
To index media files stored in your own S3 bucket, replace the MediaBucket and MediaFolderPrefix parameters with your own bucket name and prefix when you install or update the indexer component stack, and modify the MediaBucketName parameter with your own bucket name when you install or update the finder component stack. Additionally, you can replace the YouTube playlist (PlayListURL) with your own playlist URL and update the indexer stack.
- When creating a new MediaSearch indexer stack, you can choose to use either a native retriever or an Amazon Kendra retriever. You can make this selection using the parameter
RetrieverType. When using the Amazon Kendra retriever, you can either let indexer stack create an Amazon Kendra index or use an existing Amazon KendraIndexIdto add files stored in the new location. To deploy a new indexer, follow the steps from earlier in this post, but replace the defaults to specify the media bucket name and prefix for your own media files or replace the YouTube playlist URL with your own playlist URL. Make sure that you comply with the YouTube Terms of Service. - Alternatively, update an existing MediaSearch indexer stack to replace the previously indexed files with files from the new location or update the YouTube playlist URL or the number of videos to download from the playlist:
- Select the stack on the AWS CloudFormation console, choose Update, then Use current template, then Next.
- Modify the media bucket name and prefix parameter values as needed.
- Modify the YouTube Playlist URL and Number of YouTube Videos values as needed.
- Choose Next twice, select the acknowledgement check box, and choose Update stack.
- Update an existing MediaSearch finder stack to change bucket names or add additional bucket names to the
MediaBucketNames
When the MediaSearch indexer stack is successfully created or updated, the indexer automatically finds, transcribes, and indexes the media files stored in your S3 bucket. When it’s complete, you can submit queries and find answers from the audio tracks of your own audio and video files.
You have the option to provide metadata for any or all of your media files. Use metadata to assign values to index attributes for sorting, filtering, and faceting your search results, or to specify access control lists to govern access to the files. Metadata files can be in the same S3 folder as your media files (default), or in a parallel folder structure specified by the optional indexer parameter MetadataFolderPrefix. For more information about how to create metadata files, see Amazon S3 document metadata.
You can also provide customized transcription options for any or all of your media files. This allows you to take full advantage of Amazon Transcribe features such as custom vocabularies, automatic content redaction, and custom language models.
How the Mediasearch solution works
Let’s take a quick look at how the solution works, as illustrated in the following diagram.
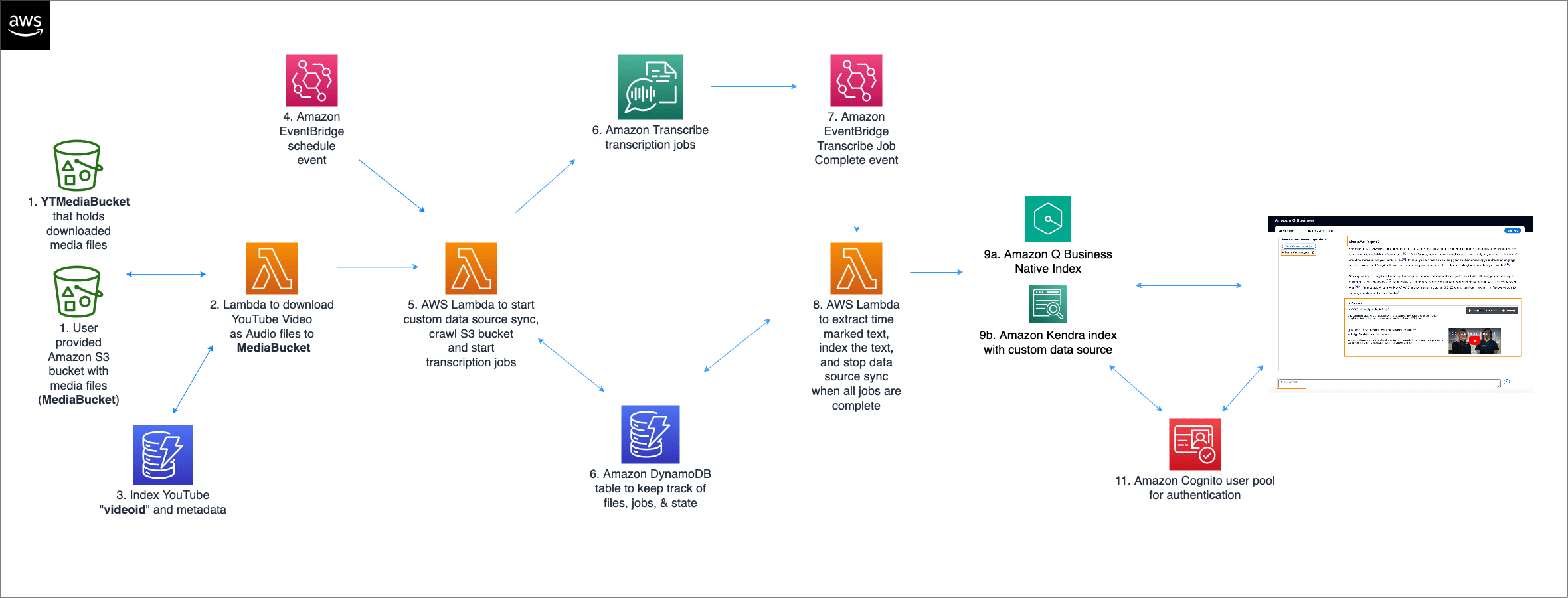
The Mediasearch solution has an event-driven serverless computing architecture with the following steps:
- You provide an S3 bucket containing the audio and video files you want to index and search. This is also known as the
MediaBucket. Leave this blank if you don’t want to index media from yourMediaBucket. - You also provide your YouTube playlist URL and the number of videos to index from the YouTube playlist. Make sure that you comply with the YouTube Terms of Service. The
YTIndexerwill index the latest files from the YouTube playlist. For example, if the number of videos is set to 5, then theYTIndexerwill index the five latest videos in the playlist. Any YouTube video indexed prior is ignored from being indexed. - An AWS Lambda function fetches the YouTube videos from the playlist as audio (mp3 files) into the
YTMediaBucketand also creates a metadata file in theMetadataFolderPrefixlocation with metadata for the YouTube video. The YouTubevideoidalong with the related metadata are recorded in an Amazon DynamoDB table (YTMediaDDBQueueTable). - Amazon EventBridge generates events on a repeating interval (every 2 hours, every 6 hours, and so on) These events invoke the Lambda function S3CrawlLambdaFunction.
- An AWS Lambda function is invoked initially when the CloudFormation stack is first deployed, and then subsequently by the scheduled events from EventBridge. The S3CrawlLambdaFunction function crawls through the
MediaBucketand theYTMediabucketand starts an Amazon Q Business index (or Amazon Kendra) data source sync job. The Lambda function lists all the supported media files (FLAC, MP3, MP4, Ogg, WebM, AMR, or WAV) and associated metadata and transcribe options stored in the user provided S3 bucket. - Each new file is added to another DynamoDB tracking table and submitted to be transcribed by an Amazon Transcribe job. Any file that has been previously transcribed is submitted for transcription again only if it has been modified since it was previously transcribed, or if associated Amazon Transcribe options have been updated. The DynamoDB table is updated to reflect the transcription status and last modified timestamp of each file. Any tracked files that no longer exist in the S3 bucket are removed from the DynamoDB table and from the Amazon Q Business index (or Amazon Kendra index). If no new or updated files are discovered, the Amazon Q Business index (or Amazon Kendra) data source sync job is immediately stopped. The DynamoDB table holds a record for each media file with attributes to track transcription job names and status, and last modified timestamps.
- As each Amazon Transcribe job completes, EventBridge generates a job complete event, which invokes another Lambda function (S3JobCompletionLambdaFunction).
- The Lambda function processes the transcription job output, generating a modified transcription that has a time marker inserted at the start of each sentence. This modified transcription is indexed in Amazon Q Business (or Amazon Kendra), and the job status for the file is updated in the DynamoDB table. When the last file has been transcribed and indexed, the Amazon Q Business (or Amazon Kendra) data source sync job is stopped.
- The index is populated and kept in sync with the transcriptions of all the media files in the S3 bucket monitored by the Mediasearch indexer component, integrated with any additional content from any other provisioned data sources. The media transcriptions are used by the Amazon Q Business application, which allows users to find content and answers to their questions.
- The sample finder client application enhances users’ search experience by embedding an inline media player with each source or citation that is based on a transcribed media file. The client uses the time markers embedded in the transcript to start media playback at the relevant section of the original media file.
- An Amazon Cognito user pool is used to authenticate users and is configured to exchange tokens from IAM Identity Center to support Amazon Q Business service calls.
Estimated costs
In addition to Amazon S3 costs associated with storing your media, the Mediasearch solution incurs usage costs from the Amazon Q, Amazon Kendra (if using an Amazon Kendra index), Amazon Transcribe, and Amazon API Gateway. Additional minor costs are incurred by the other services mentioned after free tier allowances have been used. For more information, see the pricing pages for Amazon Q Business, Amazon Kendra, Amazon Transcribe, Lambda, DynamoDB, and EventBridge.
Monitor and troubleshoot
To see the details of each media file transcript job, navigate to the Transcription jobs page on the Amazon Transcribe console.
Each media file is transcribed only one time, unless the file is modified. Modified files are re-transcribed and re-indexed to reflect the changes.
Choose any transcription job to review the transcription and examine additional job details.
![]()
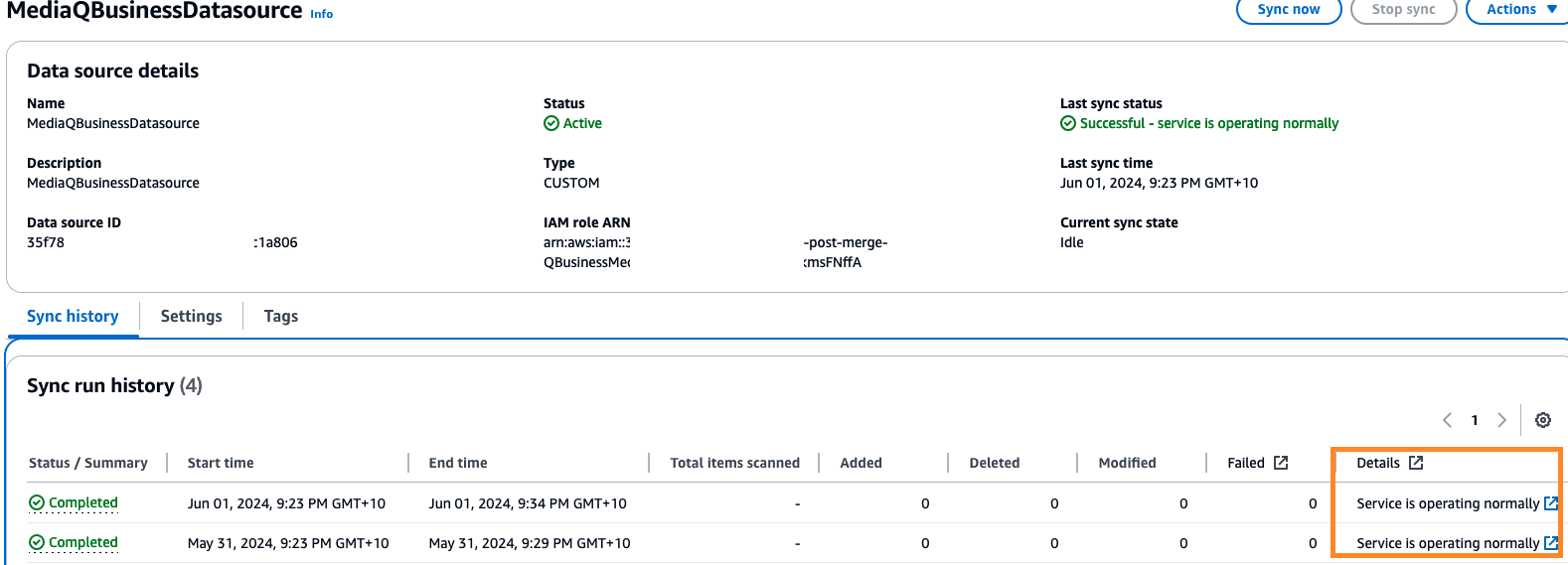
You can check the status of the data source sync by navigating to the Amazon Q Business application deployed by the indexer stack (choose the link on the indexer stack outputs page for QApplication). In the data source section, choose the custom data source and view the status of the sync job.
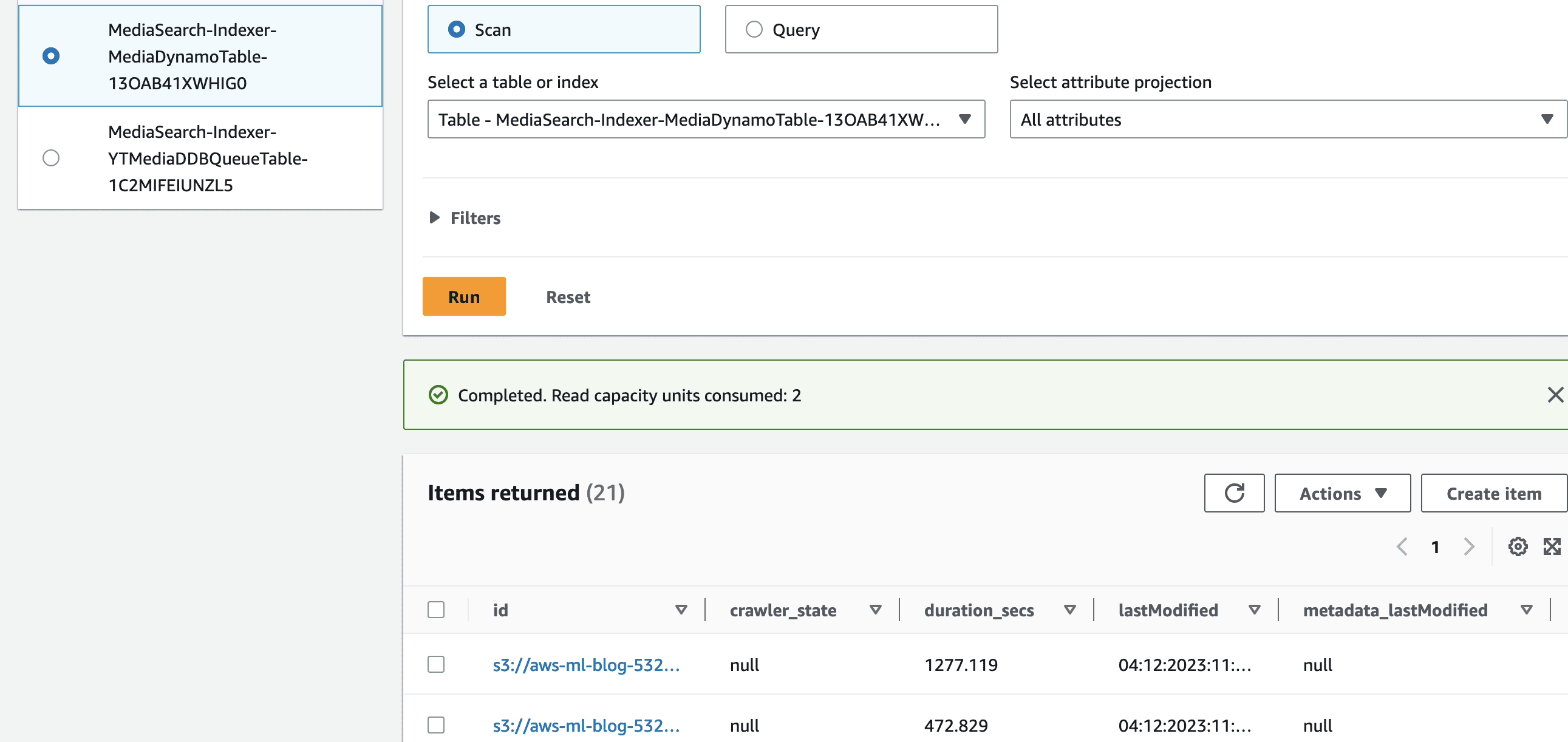
On the DynamoDB console, choose Tables in the navigation pane. Use your MediaSearch stack name as a filter to display the MediaSearch DynamoDB tables, and examine the items showing each indexed media file and corresponding status.
The table MediaSearch-Indexer-YTMediaDDBQueueTable has one record for each YouTube videoid that is downloaded as an audio (mp3) file along with the metadata for the video like author, view count, video title, and so on.
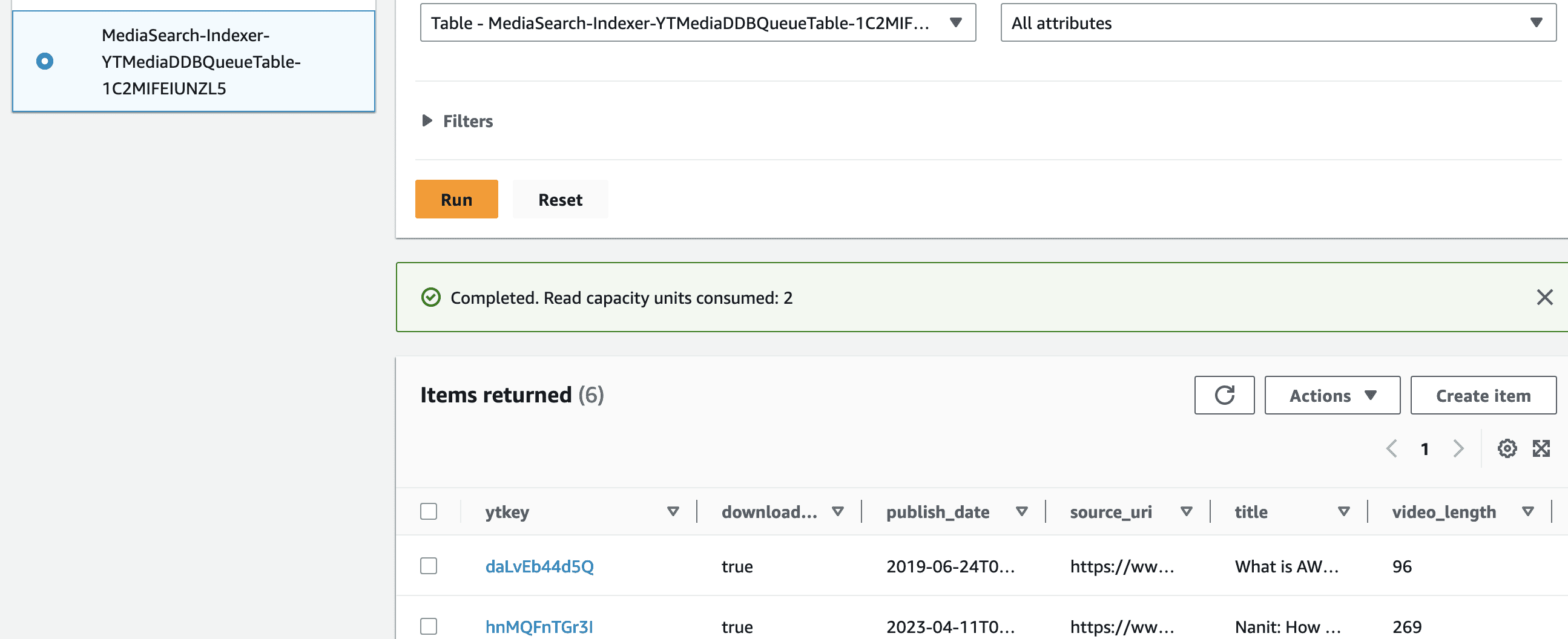
The table MediaSearch-Indexer-MediaDynamoTable has one record for each media file (including YouTube videos), and contains attributes with information about the file and its processing status.
On the Functions page of the Lambda console, use your indexer stack name as a filter to list the Lambda functions that are part of the solution:
- The
YouTubeVideoIndexerfunction indexes and downloads YouTube videos if the CloudFormation stack parameterPlayListURLis set to a valid YouTube playlist - The S3CrawlLambdaFunction function crawls the
YTMediaBucketand theMediaBucketfor media files and initiates the transcription jobs for the media files
When the transcription job is complete, a completion event invokes the S3JobCompletionLambdaFunction function, which ingests the transcription into the Amazon Q Business index (or Amazon Kendra index) with any related metadata.
Choose any of the functions to examine the function details, including environment variables, source code, and more. Choose Monitor and View logs in CloudWatch to examine the output of each function invocation and troubleshoot any issues.
On the Functions page of the Lambda console, use your finder stack name as a filter to list the Lambda functions that are part of the solution:
- The
BuildTriggerLambdafunction runs the build of the finder AWS Amplify application after cloning the AWS CodeCommit repository with the finder ReactJS code. - The
IDCTokenCreateLambdafunction uses the authorization header that contains a JWT token from a successful authentication with Amazon Cognito to exchange bearer tokens from IAM Identity Center. - The
IDCAppCreateLambdafunction creates an OAuth 2.0 IAM Identity Center application to exchange tokens from IAM Identity Center and a trusted token issuer for the Amazon Cognito user pool. - The
UserConversationLambdafunction is called from API Gateway to list or delete Amazon Q Business conversations. - The
UserPromptsLambdafunction is called from API Gateway to call the chat_sync API of the Amazon Q Business service. - The
PreSignedURLCreateLambdafunction is called from API Gateway to create a presigned URL for S3 buckets. The presigned URL is used to play the media files residing on theMediabucketthat serves as the source for an Amazon Q Business response.
Choose any of the functions to examine the function details, including environment variables, source code, and more. Choose Monitor and View logs in CloudWatch to examine the output of each function invocation and troubleshoot any issues.
Customize and enhance the solution
You can fork the MediaSearch Q Business GitHub repository, enhance the code, and send us pull requests so we can incorporate and share your improvements.
The following are a few suggestions for features you might want to implement:
- Enhance the indexer stack to allow the existing Amazon Q Business application IDs to be used
- Extend your search sources to include other video streaming platforms relevant to your organization
- Build Amazon CloudWatch metrics and dashboards to improve the manageability of MediaSearch
Clean up
When you’re finished experimenting with this solution, clean up your resources by using the AWS CloudFormation console to delete the indexer and finder stacks that you deployed. This deletes all the resources that were created by deploying the solution.
Preexisting Amazon Q Business applications or indexes or IAM Identity Center applications or trusted token issuers that were created manually aren’t deleted.
Conclusion
The combination of Amazon Q Business and Amazon Transcribe enables a scalable, cost-effective solution to surface insights from your media files. You can use the content of your media files to find accurate answers to your users’ questions, whether they’re from text documents or media files, and consume them in their native format. This solution enhances the overall experience of the previous Mediasearch solution by using the powerful generative artificial intelligence (AI) capabilities of Amazon Q Business.
The sample MediaSearch Q Business solution is provided as open source—use it as a starting point for your own solution, and help us make it better by contributing back fixes and features through GitHub pull requests. For expert assistance, AWS Professional Services and other Amazon partners are here to help.
We’d love to hear from you. Let us know what you think in the comments section, or use the issues forum in the MediaSearch Q Business GitHub repository.
About the Authors
 Roshan Thomas is a Senior Solutions Architect at Amazon Web Services. He is based in Melbourne, Australia, and works closely with power and utilities customers to accelerate their journey in the cloud. He is passionate about technology and helping customers architect and build solutions on AWS.
Roshan Thomas is a Senior Solutions Architect at Amazon Web Services. He is based in Melbourne, Australia, and works closely with power and utilities customers to accelerate their journey in the cloud. He is passionate about technology and helping customers architect and build solutions on AWS.
 Anup Dutta is a Solutions Architect with AWS based in Chennai, India. In his role at AWS, Anup works closely with startups to design and build cloud-centered solutions on AWS.
Anup Dutta is a Solutions Architect with AWS based in Chennai, India. In his role at AWS, Anup works closely with startups to design and build cloud-centered solutions on AWS.
 Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
 Abhinav Jawadekar is a Principal Solutions Architect in the Amazon Q Business service team at AWS. Abhinav works with AWS customers and partners to help them build generative AI solutions on AWS.
Abhinav Jawadekar is a Principal Solutions Architect in the Amazon Q Business service team at AWS. Abhinav works with AWS customers and partners to help them build generative AI solutions on AWS.
Leave a Reply