
Implementing advanced prompt engineering with Amazon Bedrock
Despite the ability of generative artificial intelligence (AI) to mimic human behavior, it often requires detailed instructions to generate high-quality and relevant content. Prompt engineering is the process of crafting these inputs, called prompts, that guide foundation models (FMs) and large language models (LLMs) to produce desired outputs. Prompt templates can also be used as a structure to construct prompts. By carefully formulating these prompts and templates, developers can harness the power of FMs, fostering natural and contextually appropriate exchanges that enhance the overall user experience. The prompt engineering process is also a delicate balance between creativity and a deep understanding of the model’s capabilities and limitations. Crafting prompts that elicit clear and desired responses from these FMs is both an art and a science.
This post provides valuable insights and practical examples to help balance and optimize the prompt engineering workflow. We specifically focus on advanced prompt techniques and best practices for the models provided in Amazon Bedrock, a fully managed service that offers a choice of high-performing FMs from leading AI companies such as Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. With these prompting techniques, developers and researchers can harness the full capabilities of Amazon Bedrock, providing clear and concise communication while mitigating potential risks or undesirable outputs.
Overview of advanced prompt engineering
Prompt engineering is an effective way to harness the power of FMs. You can pass instructions within the context window of the FM, allowing you to pass specific context into the prompt. By interacting with an FM through a series of questions, statements, or detailed instructions, you can adjust FM output behavior based on the specific context of the output you want to achieve.
By crafting well-designed prompts, you can also enhance the model’s safety, making sure it generates outputs that align with your desired goals and ethical standards. Furthermore, prompt engineering allows you to augment the model’s capabilities with domain-specific knowledge and external tools without the need for resource-intensive processes like fine-tuning or retraining the model’s parameters. Whether seeking to enhance customer engagement, streamline content generation, or develop innovative AI-powered solutions, harnessing the abilities of prompt engineering can give generative AI applications a competitive edge.
To learn more about the basics of prompt engineering, refer to What is Prompt Engineering?
COSTAR prompting framework
COSTAR is a structured methodology that guides you through crafting effective prompts for FMs. By following its step-by-step approach, you can design prompts tailored to generate the types of responses you need from the FM. The elegance of COSTAR lies in its versatility—it provides a robust foundation for prompt engineering, regardless of the specific technique or approach you employ. Whether you’re using few-shot learning, chain-of-thought prompting, or another method (covered later in this post), the COSTAR framework equips you with a systematic way to formulate prompts that unlock the full potential of FMs.
COSTAR stands for the following:
- Context – Providing background information helps the FM understand the specific scenario and provide relevant responses
- Objective – Clearly defining the task directs the FM’s focus to meet that specific goal
- Style – Specifying the desired writing style, such as emulating a famous personality or professional expert, guides the FM to align its response with your needs
- Tone – Setting the tone makes sure the response resonates with the required sentiment, whether it be formal, humorous, or empathetic
- Audience – Identifying the intended audience tailors the FM’s response to be appropriate and understandable for specific groups, such as experts or beginners
- Response – Providing the response format, like a list or JSON, makes sure the FM outputs in the required structure for downstream tasks
By breaking down the prompt creation process into distinct stages, COSTAR empowers you to methodically refine and optimize your prompts, making sure every aspect is carefully considered and aligned with your specific goals. This level of rigor and deliberation ultimately translates into more accurate, coherent, and valuable outputs from the FM.
Chain-of-thought prompting
Chain-of-thought (CoT) prompting is an approach that improves the reasoning abilities of FMs by breaking down complex questions or tasks into smaller, more manageable steps. It mimics how humans reason and solve problems by systematically breaking down the decision-making process. With traditional prompting, a language model attempts to provide a final answer directly based on the prompt. However, in many cases, this may lead to suboptimal or incorrect responses, especially for tasks that require multistep reasoning or logical deductions.
CoT prompting addresses this issue by guiding the language model to explicitly lay out its step-by-step thought process, known as a reasoning chain, before arriving at the final answer. This approach makes the model’s reasoning process more transparent and interpretable. This technique has been shown to significantly improve performance on tasks that require multistep reasoning, logical deductions, or complex problem-solving. Overall, CoT prompting is a powerful technique that uses the strengths of FMs while mitigating their weaknesses in complex reasoning tasks, ultimately leading to more reliable and well-reasoned outputs.
Let’s look at some examples of CoT prompting with its different variants.
CoT with zero-shot prompting
The first example is a zero-shot CoT prompt. Zero-shot prompting is a technique that doesn’t include a desired output example in the initial prompt.
The following example uses Anthropic’s Claude in Amazon Bedrock. XML tags are used to provide further context in the prompt. Although Anthropic Claude can understand the prompt in a variety of formats, it was trained using XML tags. In this case, there are typically better quality and latency results if we use this tagging structure to add further instructions in the prompt. For more information on how to provide additional context or instructions, refer to the relevant documentation for the FM you are using.
You can use Amazon Bedrock to send Anthropic Claude Text Completions API or Anthropic Claude Messages API inference requests, as seen in the following examples. See the full documentation at Anthropic Claude models.
We enter the following prompt:
As you can see in the example, the FM provided reasoning using the
CoT with few-shot prompting
Few-shot prompting is a technique that includes a desired output example in the initial prompt. The following example includes a simple CoT sample response to help the model answer the follow-up question. Few-shot prompting examples can be defined in a prompt catalog or template, which is discussed later in this post.
The following is our standard few-shot prompt (not CoT prompting):
We get the following response:
Although this response is correct, we may want to know the number of goldfish and rainbow fish that are left. Therefore, we need to be more specific in how we want to structure the output. We can do this by adding a thought process we want the FM to mirror in our example answer.
The following is our CoT prompt (few-shot):
We get the following correct response:
Self-consistency prompting
To further improve your CoT prompting abilities, you can generate multiple responses that are aggregated and select the most common output. This is known as self-consistency prompting. Self-consistency prompting requires sampling multiple, diverse reasoning paths through few-shot CoT. It then uses the generations to select the most consistent answer. Self-consistency with CoT is proven to outperform standard CoT because selecting from multiple responses usually leads to a more consistent solution.
If there is uncertainty in the response or if the results disagree significantly, either a human or an overarching FM (see the prompt chaining section in this post) can review each outcome and select the most logical choice.
For further details on self-consistency prompting with Amazon Bedrock, see Enhance performance of generative language models with self-consistency prompting on Amazon Bedrock.
Tree of Thoughts prompting
Tree of Thoughts (ToT) prompting is a technique used to improve FM reasoning capabilities by breaking down larger problem statements into a treelike format, where each problem is divided into smaller subproblems. Think of this as a tree structure: the tree begins with a solid trunk (representing the main topic) and then separates into smaller branches (smaller questions or topics).
This approach allows the FMs to self-evaluate. The model is prompted to reason through each subtopic and combine the solutions to arrive at the final answer. The ToT outputs are then combined with search algorithms, such as breadth-first search (BFS) and depth-first search (DFS), which allows you to traverse forward and backward through each topic in the tree. According to Tree of Thoughts: Deliberate Problem Solving with Large Language Models, ToT substantially outperforms other prompting methods.
One method of using ToT is to ask the LMM to evaluate whether each thought in the tree is logical, possible, or impossible if you’re solving a complex problem. You can also apply ToT prompting in other use cases. For example, if you ask an FM, “What are the effects of climate change?” you can use ToT to help break this topic down into subtopics such as “list the environmental effects” and “list the social effects.”
The following example uses the ToT prompting technique to allow Claude 3 Sonnet to solve where the ball is hidden. The FM can take the ToT output (subproblems 1–5) and formulate a final answer.
We use the following prompt:
We get the following response:
Using the ToT prompting technique, the FM has broken down the problem of, “Where is the ball?” into a set of subproblems that are simpler to answer. We typically see more logical results with this prompting approach compared to a zero-shot direct question such as, “Where is the ball?”
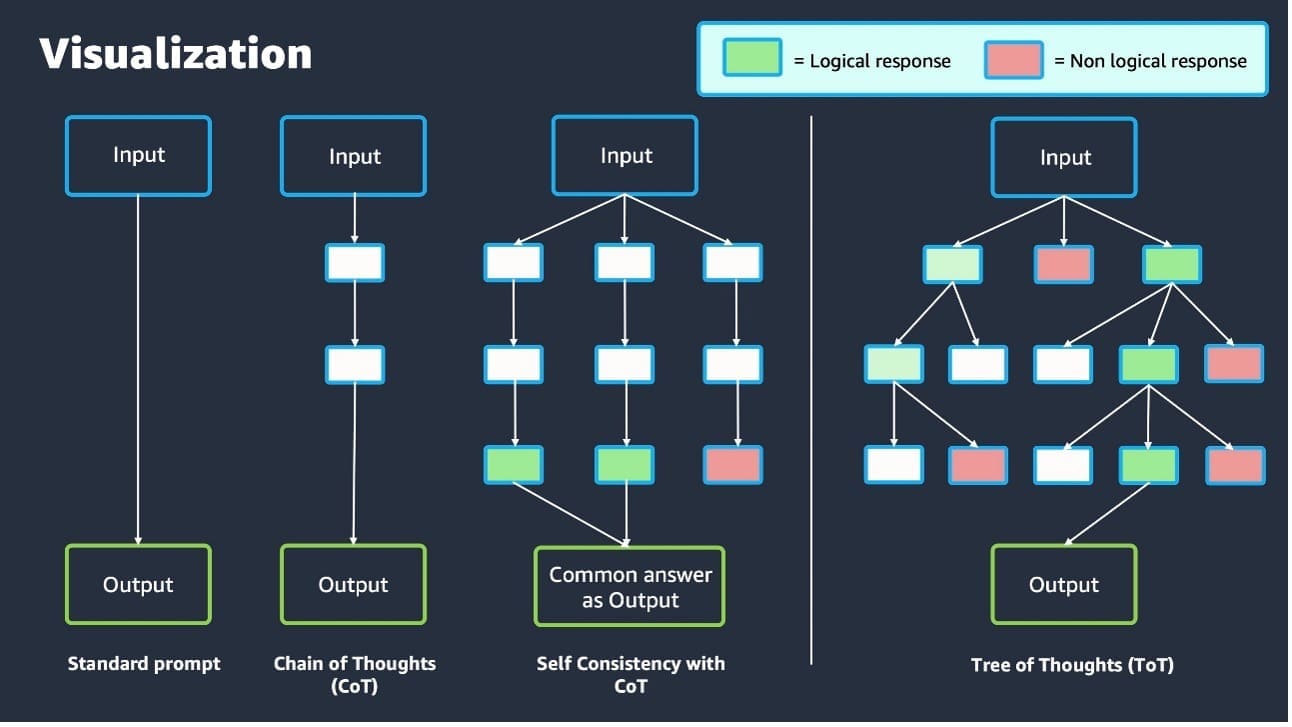
Differences between CoT and ToT
The following table summarizes the key differences between ToT and CoT prompting.
| CoT | ToT | |
| Structure | CoT prompting follows a linear chain of reasoning steps. | ToT prompting has a hierarchical, treelike structure with branching subproblems. |
| Depth | CoT can use the self-consistency method for increased understanding. | ToT prompting encourages the FM to reason more deeply by breaking down subproblems into smaller ones, allowing for more granular reasoning. |
| Complexity | CoT is a simpler approach, requiring less effort than ToT. | ToT prompting is better suited for handling more complex problems that require reasoning at multiple levels or considering multiple interrelated factors. |
| Visualization | CoT is simple to visualize because it follows a linear trajectory. If using self-consistency, it may require multiple reruns. | The treelike structure of ToT prompting can be visually represented in a tree structure, making it straightforward to understand and analyze the reasoning process. |
The following diagram visualizes the discussed techniques.
Prompt chaining
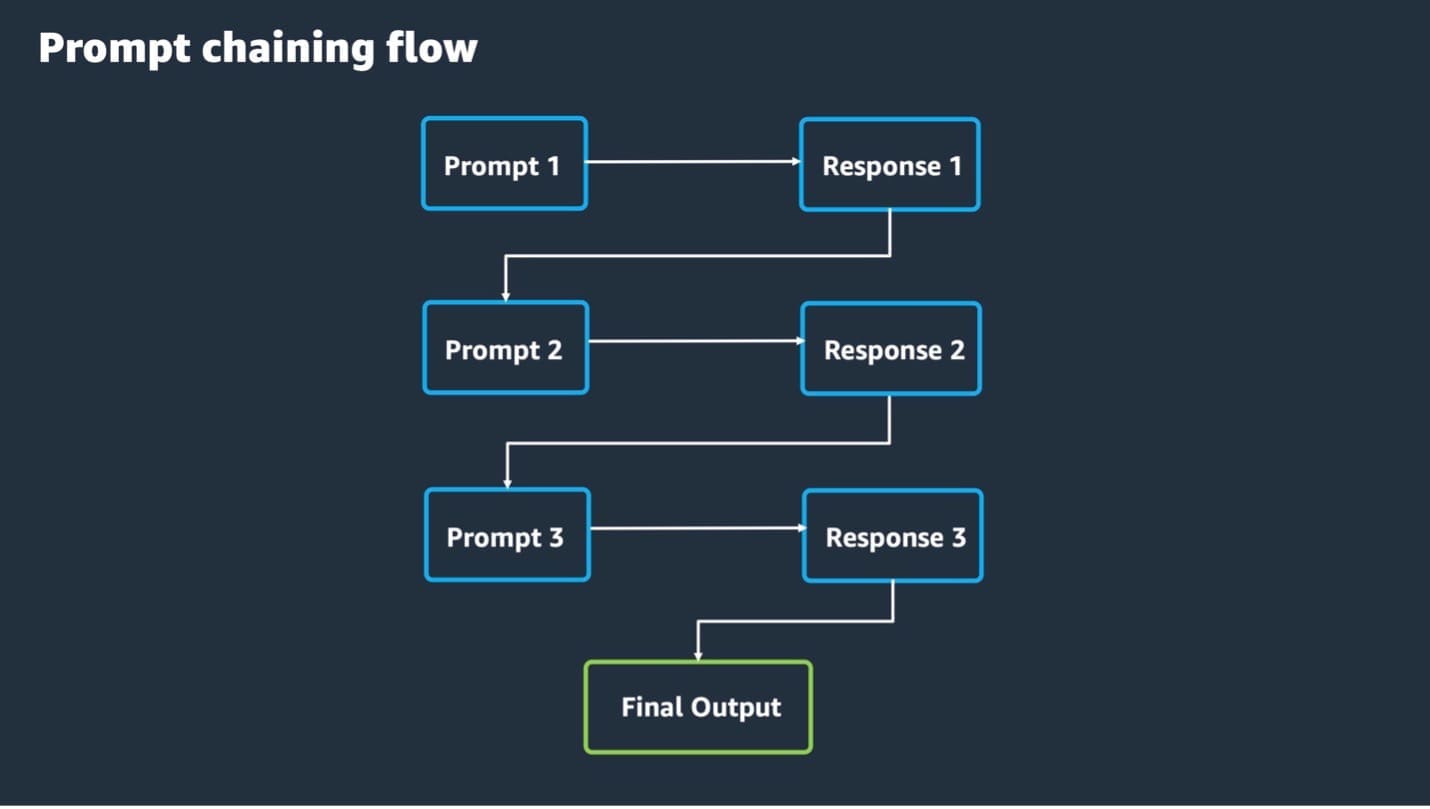
Building on the discussed prompting techniques, we now explore prompt chaining methods, which are useful in handling more advanced problems. In prompt chaining, the output of an FM is passed as input to another FM in a predefined sequence of N models, with prompt engineering between each step. This allows you to break down complex tasks and questions into subtopics, each as a different input prompt to a model. You can use ToT, CoT, and other prompting techniques with prompt chaining.
Amazon Bedrock Prompt Flows can orchestrate the end-to-end prompt chaining workflow, allowing users to input prompts in a logical sequence. These features are designed to accelerate the development, testing, and deployment of generative AI applications so developers and business users can create more efficient and effective solutions that are simple to maintain. You can use prompt management and flows graphically in the Amazon Bedrock console or Amazon Bedrock Studio or programmatically through the Amazon Bedrock AWS SDK APIs.
Other options for prompt chaining include using third-party LangChain libraries or LangGraph, which can manage the end-to-end orchestration. These are third-party frameworks designed to simplify the creation of applications using FMs.
The following diagram showcases how a prompt chaining flow can work:
The following example uses prompt chaining to perform a legal case review.
Prompt 1:
Response 1:
We then provide a follow-up prompt and question.
Prompt 2:
Response 2:
The following is a final prompt and question.
Prompt 3:
Response 3 (final output):
To get started with hands-on examples of prompt chaining, refer to the GitHub repo.
Prompt catalogs
A prompt catalog, also known as a prompt library, is a collection of prewritten prompts and prompt templates that you can use as a starting point for various natural language processing (NLP) tasks, such as text generation, question answering, or data analysis. By using a prompt catalog, you can save time and effort crafting prompts from scratch and instead focus on fine-tuning or adapting the existing prompts to your specific use cases. This approach also assists with consistency and re-usability, as the template can be shared across teams within an organization.
Prompt Management for Amazon Bedrock consists of a prompt builder, a prompt library (catalog), versioning, and testing methods for prompt templates. For more information on how to orchestrate the prompt flow by using Prompt Management for Amazon Bedrock, refer to Advanced prompts in Amazon Bedrock.
The following example uses a prompt template to structure the FM response.
Prompt template:
Sample prompt:
Model response:
For further examples of prompting templates, refer to the following resources:
- Prompt templates and examples for Amazon Bedrock text models
- The Anthropic Claude Prompt Library, a collection of Anthropic Claude optimized prompts for a breadth of tasks
- LangSmith Prompt Hub, where you can discover, share, and version prompts for LangChain and FMs in general
Prompt misuses
When building and designing a generative AI application, it’s crucial to understand FM vulnerabilities regarding prompt engineering. This section covers some of the most common types of prompt misuses so you can adopt security in the design from the beginning.
FMs available through Amazon Bedrock already provide built-in protections to prevent the generation of harmful responses. However, it’s best practice to add additional, personalized prompt security measures, such as with Guardrails for Amazon Bedrock. Refer to the prompt defense techniques section in this post to learn more about handling these use cases.
Prompt injection
Prompt injection attacks involve injecting malicious or unintended prompts into the system, potentially leading to the generation of harmful, biased, or unauthorized outputs from the FM. In this case, an unauthorized user crafts a prompt to trick the FM into running unintended actions or revealing sensitive information. For example, an unauthorized user could inject a prompt that instructs the FM to ignore or bypass security filters such as XML tags, allowing the generation of offensive or illegal content. For examples, refer to Hugging Face prompt-injections.
The following is an example attacker prompt:
Prompt leaking
Prompt leaking can be considered a form of prompt injection. Prompt leaking occurs when an unauthorized user aims to leak the details or instructions from the original prompt. This attack can expose behind-the-scenes prompt data or instructions in the response back to the user. For example:
Jailbreaking
Jailbreaking, in the context of prompt engineering security, refers to an unauthorized user attempting to bypass the ethical and safety constraints imposed on the FM. This can lead it to generate unintended responses. For example:
Alternating languages and special characters
Alternating languages in the input prompt increases the chance of confusing the FM with conflicting instructions or bypassing certain FM guardrails (see more on FM guardrails in the prompt defense techniques section). This also applies to the use of special characters in a prompt, such as , +, → or !—, which is an attempt to get the FM to forget its original instructions.
The following is an example of a prompt misuse. The text in the brackets represents a language other than English:
For more information on prompt misuses, refer to Common prompt injection attacks.
Prompt defense techniques
This section discusses how to help prevent these misuses of FM responses by putting security mechanisms in place.
Guardrails for Amazon Bedrock
FM guardrails help to uphold data privacy and provide safe and reliable model outputs by preventing the generation of harmful or biased content. Guardrails for Amazon Bedrock evaluates user inputs and FM responses based on use case–specific policies and provides an additional layer of safeguards regardless of the underlying FM. You can apply guardrails across FMs on Amazon Bedrock, including fine-tuned models. This additional layer of security detects harmful instructions in an incoming prompt and catches it before the event reaches the FM. You can customize your guardrails based on your internal AI policies.
For examples of the differences between responses with or without guardrails in place, refer this Comparison table. For more information, see How Guardrails for Amazon Bedrock works.
Use unique delimiters to wrap prompt instructions
As highlighted in some of the examples, prompt engineering techniques can use delimiters (such as XML tags) in their template. Some prompt injection attacks try to take advantage of this structure by wrapping malicious instructions in common delimiters, leading the model to believe that the instruction was part of its original template. By using a unique delimiter value (for example,
Detect threats by providing specific instructions
You can also include instructions that explain common threat patterns to teach the FM how to detect malicious events. The instructions focus on the user input query. They instruct the FM to identify the presence of key threat patterns and return “Prompt Attack Detected” if it discovers a pattern. These instructions serve as a shortcut for the FM to deal with common threats. This shortcut is mostly relevant when the template uses delimiters, such as the
For more information, see Prompt engineering best practices to avoid prompt injection attacks on modern LLMs.
Prompt engineering best practices
In this section, we summarize prompt engineering best practices.
Clearly define prompts using COSTAR framework
Craft prompts in a way that leaves minimal room for misinterpretation by using the discussed COSTAR framework. It’s important to explicitly state the type of response expected, such as a summary, analysis, or list. For example, if you ask for a novel summary, you need to clearly indicate that you want a concise overview of the plot, characters, and themes rather than a detailed analysis.
Sufficient prompt context
Make sure that there is sufficient context within the prompt and, if possible, include an example output response (few-shot technique) to guide the FM toward the desired format and structure. For instance, if you want a list of the most popular movies from the 1990s presented in a table format, you need to explicitly state the number of movies to list and specify that the output should be in a table. This level of detail helps the FM understand and meet your expectations.
Balance simplicity and complexity
Remember that prompt engineering is an art and a science. It’s important to balance simplicity and complexity in your prompts to avoid vague, unrelated, or unexpected responses. Overly simple prompts may lack the necessary context, whereas excessively complex prompts can confuse the FM. This is particularly important when dealing with complex topics or domain-specific language that may be less familiar to the LM. Use plain language and delimiters (such as XML tags if your FM supports them) and break down complex topics using the techniques discussed to enhance FM understanding.
Iterative experimentation
Prompt engineering is an iterative process that requires experimentation and refinement. You may need to try multiple prompts or different FMs to optimize for accuracy and relevance. Continuously test, analyze, and refine your prompts, reducing their size or complexity as needed. You can also experiment with adjusting the FM temperature setting. There are no fixed rules for how FMs generate output, so flexibility and adaptability are essential for achieving the desired results.
Prompt length
Models are better at using information that occurs at the very beginning or end of its prompt context. Performance can degrade when models must access and use information located in the middle of its prompt context. If the prompt input is very large or complex, it should be broken down using the discussed techniques. For more details, refer to Lost in the Middle: How Language Models Use Long Contexts.
Tying it all together
Let’s bring the overall techniques we’ve discussed together into a high-level architecture to showcase a full end-to-end prompting workflow. The overall workflow may look similar to the following diagram.
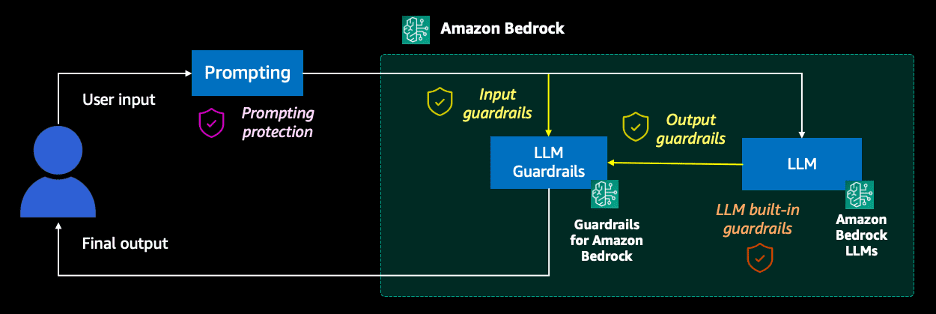
The workflow consists of the following steps:
- Prompting – The user decides which prompt engineering techniques they want to adopt. They then send the prompt request to the generative AI application and wait for a response. A prompt catalog can also be used during this step.
- Input guardrails (Amazon Bedrock) – A guardrail combines a single policy or multiple policies configured for prompts, including content filters, denied topics, sensitive information filters, and word filters. The prompt input is evaluated against the configured policies specified in the guardrail. If the input evaluation results in a guardrail intervention, a configured blocked message response is returned, and the FM inference is discarded.
- FM and LLM built-in guardrails – Most modern FM providers are trained with security protocols and have built-in guardrails to prevent inappropriate use. It is best practice to also create and establish an additional security layer using Guardrails for Amazon Bedrock.
- Output guardrails (Amazon Bedrock) – If the response results in a guardrail intervention or violation, it will be overridden with preconfigured blocked messaging or masking of the sensitive information. If the response’s evaluation succeeds, the response is returned to the application without modifications.
- Final output – The response is returned to the user.
Cleanup
Running the lab in the GitHub repo referenced in the conclusion is subject to Amazon Bedrock inference charges. For more information about pricing, see Amazon Bedrock Pricing.
Conclusion
Ready to get hands-on with these prompting techniques? As a next step, refer to our GitHub repo. This workshop contains examples of the prompting techniques discussed in this post using FMs in Amazon Bedrock as well as deep-dive explanations.
We encourage you to implement the discussed prompting techniques and best practices when developing a generative AI application. For more information about advanced prompting techniques, see Prompt engineering guidelines.
Happy prompting!
About the Authors

Jonah Craig is a Startup Solutions Architect based in Dublin, Ireland. He works with startup customers across the UK and Ireland and focuses on developing AI and machine learning (AI/ML) and generative AI solutions. Jonah has a master’s degree in computer science and regularly speaks on stage at AWS conferences, such as the annual AWS London Summit and the AWS Dublin Cloud Day. In his spare time, he enjoys creating music and releasing it on Spotify.

Manish Chugh is a Principal Solutions Architect at AWS based in San Francisco, CA. He specializes in machine learning and generative AI. He works with organizations ranging from large enterprises to early-stage startups on problems related to machine learning. His role involves helping these organizations architect scalable, secure, and cost-effective machine learning workloads on AWS. He regularly presents at AWS conferences and other partner events. Outside of work, he enjoys hiking on East Bay trails, road biking, and watching (and playing) cricket.

Doron Bleiberg is a Senior Startup Solutions Architect at AWS, based in Tel Aviv, Israel. In his role, Doron provides FinTech startups with technical guidance and support using AWS Cloud services. With the advent of generative AI, Doron has helped numerous startups build and deploy generative AI workloads in the AWS Cloud, such as financial chat assistants, automated support agents, and personalized recommendation systems.
Leave a Reply