
Optimizing MLOps for Sustainability
Machine learning operations (MLOps) are a set of practices that automate and simplify machine learning (ML) workflows and deployments. What is MLOps provides a detailed description of this concept. As ML workloads become increasingly complex and consume more energy and resources, a growing number of companies are looking for ways to manage both the costs and the carbon footprint associated with these workloads. AWS published Guidance for Optimizing MLOps for Sustainability on AWS to help customers maximize utilization and minimize waste in their ML workloads.
In this blog post, you will learn how to optimize MLOps for sustainability.
There are three main workflows in the overall process for building, deploying and using ML models, as shown in the following figure. The process begins with data preparation, followed by model training and tuning, and then model deployment and management.
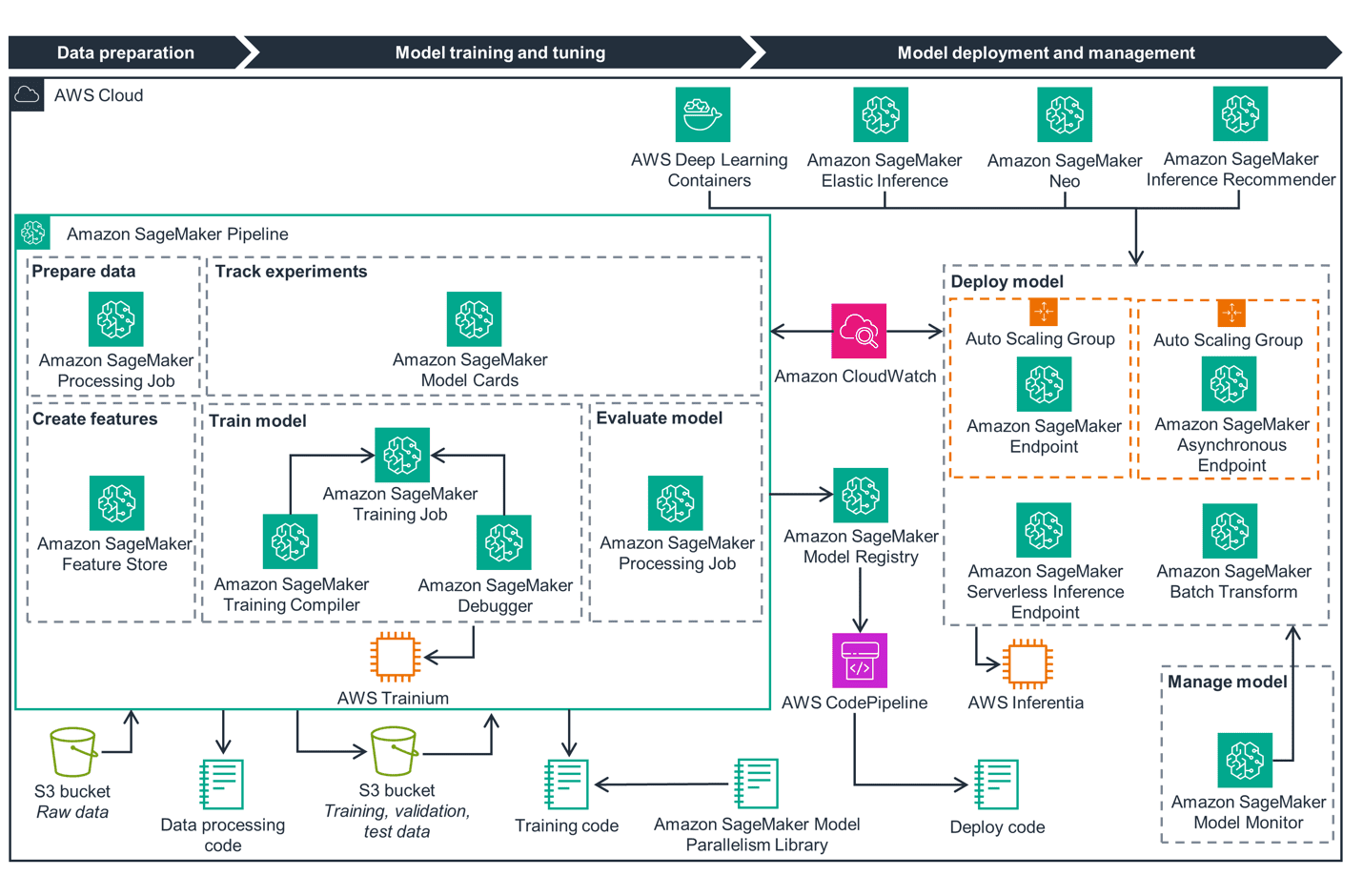
Data preparation
The workflow starts with data preparation, which includes four components: your data stream, Amazon SageMaker Processing job, Amazon SageMaker Feature Store and an Amazon Simple Storage Service (Amazon S3) bucket for raw data, as shown in the following figure.

Data preparation is essential for model training and is also the first phase in the MLOps lifecycle. Optimizing the artificial intelligence and machine learning (AI/ML) data preparation workload on AWS with sustainability best practices helps reduce the carbon footprint and the cost.
The data preparation process can be complex and energy-intensive because of the vast amount of data processing and computations involved. This leads to substantial resource consumption. There are a few things to consider that can help reduce energy consumption.
Start with the AWS Region you choose for your workload. If possible, choose a Region that has low carbon intensity or where the electricity is attributed to 100% renewable energy sources. In addition, consider storing data and training models in the same Region if possible. This reduces the data movement and latency across the network, optimizing the networking resources required.
Using a serverless architecture can help further reduce resource consumption and remove maintenance overhead by provisioning resources only when required. It’s also important to avoid duplication and re-run of code across teams. Look for services such as Amazon SageMaker Feature Store which helps achieve this goal. Finally, choosing the right storage type for the data used for model training can limit the carbon impact of your workload.
For example, by using S3 One Zone-Infrequent Access to store data that isn’t frequently accessed, such as test data and training data, you can optimize the carbon impact of the data stored. Also, using S3 Intelligent-Tiering can help move the data to more energy-efficient tiers based on access patterns.
Model training and tuning
The second area for you to consider is model training and tuning, shown in the following figure.
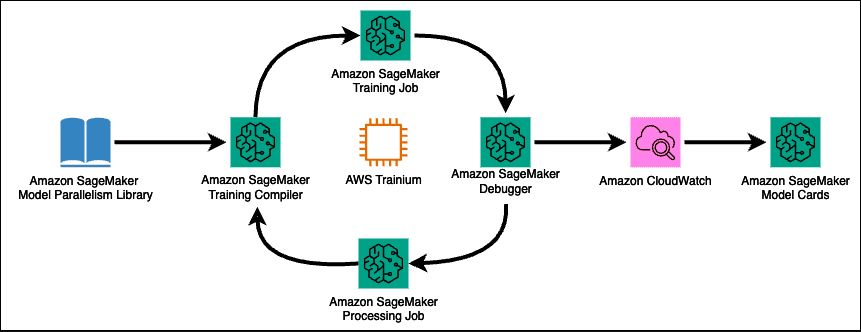
While data preparation isn’t unique to AI/ML workloads, the model training and tuning workflow is specific to AI/ML. It’s an important step in making the models functionally useful while also reducing the resources required to run them at scale. There are costs in terms of both operations and sustainability. The good news is that optimization for sustainability also helps to optimizing operations.
For example, SageMaker provides the model parallel library to help efficiently distribute and train models on multiple compute nodes. The library has multiple features that can be combined to more efficiently train models from relatively small parameter sets up to sets with hundreds of billions of parameters. The library can also help use the features of Elastic Fabric Adapter (EFA) supported devices to maximize throughput and minimize latency across nodes. Further optimization is possible using SageMaker Training Compiler to compile deep learning models for training on supported GPU instances. SageMaker Training Compiler converts deep learning models from high-level language representation to hardware-optimized instructions. Hardware-optimized instructions can speed up model training by up to 50% by more efficiently using the GPU memory and using a larger batch size per iteration, all without altering the final trained model.
To reduce the time and energy required to tune a model, SageMaker automatic model tuning (AMT) runs multiple training jobs on a given dataset; it then uses the results to converge on a set of hyperparameter values to create the best performing model for a given metric. There are multiple approaches to the process of searching for the right hyperparameter ranges. For example, Bayesian optimization typically requires 10 times fewer jobs to find the best set of values compared to other methods, reducing the resource usage and carbon footprint of the process.
Right-sizing is another method for managing resource usage and minimizing the environmental impact of your workloads. SageMaker debugger helps to optimize resource consumption by detecting under-utilization of system resources, identifying training problems, and using built-in rules to monitor and stop training jobs as soon as bugs are detected.
Data pre- and post-processing and model evaluation tasks can be run as Amazon SageMaker Processing jobs. In addition to evaluating the accuracy of your models, processing jobs help you to make informed decisions about the tradeoffs between a model’s accuracy and its carbon footprint. Thus, you can establish performance criteria that support your sustainability goals while meeting your business requirements. SageMaker Processing also provides Amazon CloudWatch logs and metrics that can be used for monitoring and right-sizing jobs based on CPU, memory, GPU, GPU memory, and disk metrics.
Dedicated Amazon Elastic Compute Cloud (Amazon EC2) Trn1 instances provide both efficiency and environmental benefits for running your training jobs. These instances use Trainium processors: purpose-built chips designed specifically for deep learning training of models that can exceed 100 billion parameters. Each Trn1 instance provides up to 16 Trainium accelerators, ensuring that jobs will be both efficient and cost optimized. EC2 Trn1 instances offer up to 52% cost-to-train savings compared to comparable EC2 instance types.
Next, you can use governance to share information about the environmental impact of your model. Amazon SageMaker Model Cards provide versioned records documenting various aspects and attributes of your model. This allows you to share the intended uses and assessed carbon impact of a model so that data scientists, ML engineers, and other teams can make informed decisions when choosing and running models.
Model deployment and management
The last area of MLOps is deployment and management, shown in the following figure.
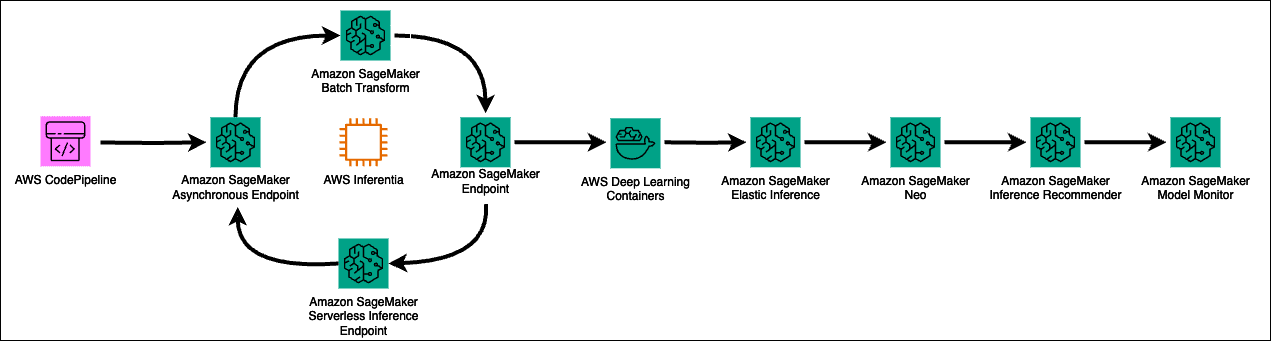
Automating the deployment of ML models provides several sustainability benefits. The deployed model can use a lot of resources when data or code is updated and retrained. You want to ensure that the deployed model is as efficient as possible to reduce the carbon footprint of the workload.
One approach is to use Amazon SageMaker Model Registry. This feature helps improve sustainability and resource optimization by providing a centralized repository for cataloging ML models and reducing redundancy. This approach improves model reusability by allowing existing models to be fine-tuned, rather than training new models from scratch. Consider running your deployment code using AWS CodePipeline to ensure repeatability and version control and optimize resource utilization by running only the necessary stages in the pipeline. This helps your workloads remove the waste associated with manual processes and supports incremental improvements over time.
If your workloads can tolerate latency, consider deploying your model on Amazon SageMaker Asynchronous Inference with auto-scaling groups. This can help minimize idle resources and reduce the impact of load spikes. This also means you pay for compute only when the endpoint is actively handling inference requests. Alternatively, if you don’t need real-time inference, use batch transform. Unlike persistent endpoints, clusters are decommissioned when a batch transform job is complete. Batch transform automatically partitions large datasets and distributes workloads across compute to ensure efficient resource utilization.
To simplify deployment and management and increase resource utilization, use multi-model endpoints instead of separate endpoints for each model. One example for this approach is models with different data formats, such as recommendation systems that process text and images using separate endpoints. Or deploying a variety of models that include PyTorch, Scikit-learn, and TensorFlow models. Automatic scaling can amplify resource optimization for your hosted models. Auto scaling dynamically adjusts the number of instances provisioned for a model in response to changes in your workload. This helps you avoid cost and consumes less energy and resources. If your workload has intermittent or unpredictable traffic with idle periods between traffic peaks and can tolerate cold starts, use Amazon SageMaker Serverless Inference endpoints, which automatically launch compute resources and scale depending on traffic. Optionally, you can use Provisioned Concurrency with Serverless Inference when you have predictable bursts in your traffic.
AWS offers a few different options to better utilize your resources and lower emissions when working with inference workloads. AWS Inferentia is designed to deliver high performance at the lowest cost in EC2 instances for your deep learning and generative AI inference applications. AWS Inferentia is built for sustainability and provides up to 50% better performance per watt over comparable EC2 instances. You can further optimize resource utilization by combining AWS Inferentia and Amazon Elastic Inference to attach the right amount of GPU-powered inference acceleration to any EC2 or SageMaker instance type.
After training a model for high accuracy, developers often turn to more expensive large instances with lots of memory and processing power to achieve better throughput. You can reduce resource usage and avoid the need for more powerful instances by using pre-trained models and compiling them into optimized executables that can be hosted in SageMaker or edge devices for inference with Amazon SageMaker Neo.
Monitoring CPU, memory, and GPU resource utilization is critical to optimize model performance and avoid wasted resources. AWS offers a variety of tools that you can use to optimize MLOps for sustainability, such as CloudWatch, SageMaker Inference recommender, and SageMaker Model Monitor. Inference Recommender helps you choose the optimal instance type and configuration for ML models and workloads. You can use SageMaker Model Monitor to automate drift detection of your ML model in production, and only retrain it when prediction performance drops below predetermined key performance indicators (KPIs). This approach improves operational efficiency and retrains the model based on your business metrics.
Conclusion
Sustainability and ML are redefining how many companies deliver value for their customers. Incorporating sustainability into the design, development and deployment of ML models is a crucial long-term consideration. AWS is investing in the sustainability of the cloud and providing resources to assist customers in transforming their workloads to be more energy efficient. In this post, we have reviewed the Guidance for Optimizing MLOps for Sustainability on AWS, providing service-specific practices to understand and reduce the environmental impact of these workloads. MLOps consists of several distinct phases that can be independently optimized for sustainability. Regular reviews using tools such as AWS Well-Architected Machine Learning Lens help you identify optimization opportunities and provide a mechanism for you to meet your sustainability goals.
About the Authors
 Archana Srinivasan is a Senior Technical Account Manager within Enterprise Support at Amazon Web Services (AWS). Archana provides strategic technical guidance for independent software vendors (ISVs) to innovate and operate their workloads efficiently on AWS.
Archana Srinivasan is a Senior Technical Account Manager within Enterprise Support at Amazon Web Services (AWS). Archana provides strategic technical guidance for independent software vendors (ISVs) to innovate and operate their workloads efficiently on AWS.
 Chris Procunier is a Senior Technical Account Manager at AWS, based out of Washington DC. He has been managing systems and infrastructure for 25 years as an entrepreneur, IT Director and architect. Outside of work Chris is passionate about family, friends, music, cooking and cycling.
Chris Procunier is a Senior Technical Account Manager at AWS, based out of Washington DC. He has been managing systems and infrastructure for 25 years as an entrepreneur, IT Director and architect. Outside of work Chris is passionate about family, friends, music, cooking and cycling.
 Meghana Reddy is a Technical Account Manager at AWS, where she offers strategic technical guidance to Independent Software Vendors (ISVs) for optimizing their workloads on AWS. She is passionate about environmental sustainability and actively promotes sustainable practices within the cloud.
Meghana Reddy is a Technical Account Manager at AWS, where she offers strategic technical guidance to Independent Software Vendors (ISVs) for optimizing their workloads on AWS. She is passionate about environmental sustainability and actively promotes sustainable practices within the cloud.
 Steven David is a Principal Solutions Architect at Amazon Web Services (AWS). He has over 20 years of experience designing solutions for large enterprises. Through these engagements he has developed deep expertise in application development technologies and methodologies.
Steven David is a Principal Solutions Architect at Amazon Web Services (AWS). He has over 20 years of experience designing solutions for large enterprises. Through these engagements he has developed deep expertise in application development technologies and methodologies.
Leave a Reply