
Best prompting practices for using Meta Llama 3 with Amazon SageMaker JumpStart
Llama 3, Meta’s latest large language model (LLM), has taken the artificial intelligence (AI) world by storm with its impressive capabilities. As developers and businesses explore the potential of this powerful model, crafting effective prompts is key to unlocking its full potential.
In this post, we dive into the best practices and techniques for prompting Meta Llama 3 using Amazon SageMaker JumpStart to generate high-quality, relevant outputs. We discuss how to use system prompts and few-shot examples, and how to optimize inference parameters, so you can get the most out of Meta Llama 3. Whether you’re building chatbots, content generators, or custom AI applications, these prompting strategies will help you harness the power of this cutting-edge model.
Meta Llama 2 vs. Meta Llama 3
Meta Llama 3 represents a significant advancement in the field of LLMs. Building upon the capabilities of its predecessor Meta Llama 2, this latest iteration brings state-of-the-art performance across a wide range of natural language tasks. Meta Llama 3 demonstrates improved capabilities in areas such as reasoning, code generation, and instruction following compared to Meta Llama 2.
The Meta Llama 3 release introduces four new LLMs by Meta, building upon the Meta Llama 2 architecture. They come in two variants—8 billion and 70 billion parameters—with each size offering both a base pre-trained version and an instruct-tuned version. Additionally, Meta is training an even larger 400-billion-parameter model, which is expected to further enhance the capabilities of Meta Llama 3. All Meta Llama 3 variants boast an impressive 8,000 token context length, allowing them to handle longer inputs compared to previous models.
Meta Llama 3 introduces several architectural changes from Meta Llama 2, using a decoder-only transformer along with a new 128,000 tokenizer to improve token efficiency and overall model performance. Meta has put significant effort into curating a massive and diverse pre-training dataset of over 15 trillion tokens from publicly available sources spanning STEM, history, current events, and more. Meta’s post-training procedures have reduced false refusal rates, aimed at better aligning outputs with human preferences while increasing response diversity.
Solution overview
SageMaker JumpStart is a powerful feature within the Amazon SageMaker machine learning (ML) platform that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs). With this managed service, ML practitioners get access to growing list of cutting-edge models from leading model hubs and providers that they can deploy to dedicated SageMaker instances within a network isolated environment, and customize models using SageMaker for model training and deployment.
With Meta Llama 3 now available on SageMaker JumpStart, developers can harness its capabilities through a seamless deployment process. You gain access to the full suite of Amazon SageMaker MLOps tools, such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, and monitoring—all within a secure AWS environment under virtual private cloud (VPC) controls.
Drawing from our previous learnings with Llama-2-Chat, we highlight key techniques to craft effective prompts and elicit high-quality responses tailored to your applications. Whether you are building conversational AI assistants, enhancing search engines, or pushing the boundaries of language understanding, these prompting strategies will help you unlock Meta Llama 3’s full potential.
Before we continue our deep dive into prompting, let’s make sure we have all the necessary requirements to follow the examples.
Prerequisites
To try out this solution using SageMaker JumpStart, you need the following prerequisites:
- An AWS account that will contain all your AWS resources.
- An AWS Identity and Access Management (IAM) role to access SageMaker. To learn more about how IAM works with SageMaker, refer to Identity and Access Management for Amazon SageMaker.
- Access to Amazon SageMaker Studio or a SageMaker notebook instance or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using SageMaker Studio for straightforward deployment and inference.
- The GitHub repository cloned in order to use the accompanying notebook.
- An ml.g5.12xlarge instance for endpoint usage to deploy the model to. You may need to request a quota increase; refer to Requesting a quota increase for more information.
Deploy Meta Llama 3 8B on SageMaker JumpStart
You can deploy your own model endpoint through the SageMaker JumpStart Model Hub available from SageMaker Studio or through the SageMaker SDK. To use SageMaker Studio, complete the following steps:
- In SageMaker Studio, choose JumpStart in the navigation pane.

- Choose Meta as the model provider to see all the models available by Meta AI.
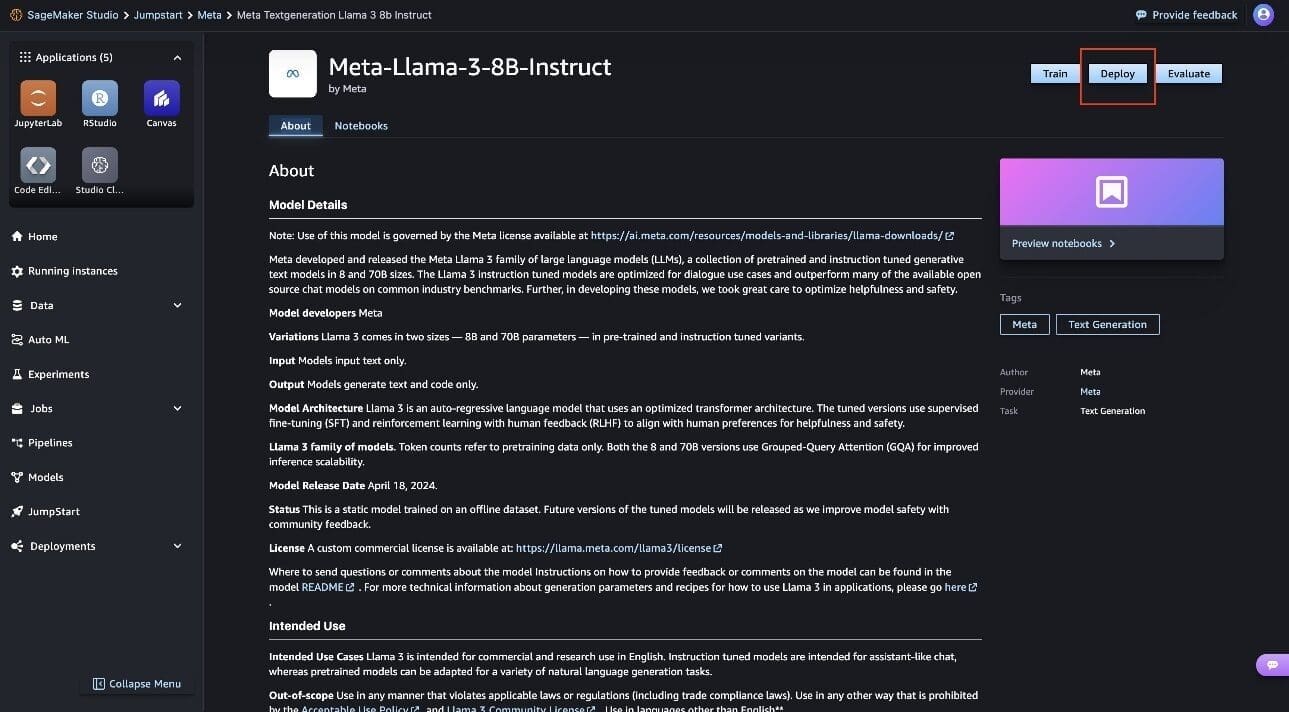
- Choose the Meta Llama 8B Instruct model to view the model details such as license, data used to train, and how to use the model.On the model details page, you will find two options, Deploy and Preview notebooks, to deploy the model and create an endpoint.
- Choose Deploy to deploy the model to an endpoint.
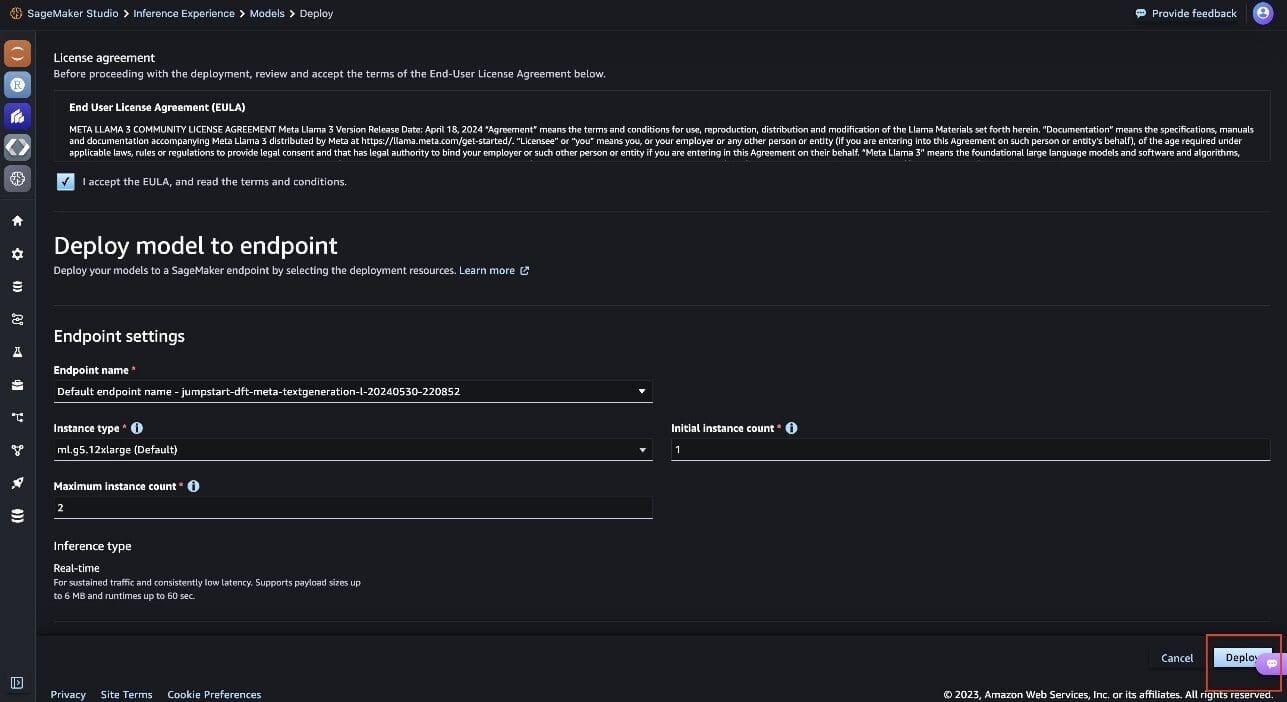
- You can use the default endpoint and networking configurations or modify them based on your requirements.
- Choose Deploy to deploy the model.
Crafting effective prompts
Prompting is important when working with LLMs like Meta Llama 3. It is the main way to communicate what you want the model to do and guide its responses. Crafting clear, specific prompts for each interaction is key to getting useful, relevant outputs from these models.
Although language models share some similarities in how they’re built and trained, each has its own differences when it comes to effective prompting. This is because they’re trained on different data, using different techniques and settings, which can lead to subtle differences in how they behave and perform. For example, some models might be more sensitive to the exact wording or structure of the prompt, whereas others might need more context or examples to generate accurate responses. On top of that, the intended use case and domain of the model can also influence the best prompting strategies, because different tasks might benefit from different approaches.
You should experiment and adjust your prompts to find the most effective approach for each specific model and application. This iterative process is crucial for unlocking the full potential of each model and making sure the outputs align with what you’re looking for.
Prompt components
In this section, we discuss components by Meta Llama 3 Instruct expects in a prompt. Newlines (‘n’) are part of the prompt format; for clarity in the examples, they have been represented as actual new lines.
The following is an example instruct prompt with a system message:
The prompt contains the following key sections:
- <|begin_of_text|> – Specifies the start of the prompt.
- <|start_header_id|>system<|end_header_id|> – Specifies the role for the following message (for example,
system). - You are a helpful AI assistant for travel tips and recommendations – Includes the system message.
- <|eot_id|> – Specifies the end of the input message.
- <|start_header_id|>user<|end_header_id|> – Specifies the role for the following message (for example,
user). - What can you help me with? – Includes the user message.
- <|start_header_id|>assistant<|end_header_id|> – Ends with the assistant header, to prompt the model to start generation. The model expects the assistant header at the end of the prompt to start completing it.
Following this prompt, Meta Llama 3 completes it by generating the {{assistant_message}}. It signals the end of the {{assistant_message}} by generating the <|eot_id|>.
The following is an example prompt with a single user message:
The following is the system prompt and multiple-turn conversation between the user and assistant:
Fundamental techniques
The following are some fundamental techniques in crafting our prompts:
- Zero-shot prompting – Zero-shot prompting provides no examples to the model and relies solely on the model’s preexisting knowledge to generate a response based on the instruction given. The following is an example zero-shot prompt:
This produces the following response:
- Few-shot prompting – Few-shot prompting involves providing the model with a few examples (usually two or more) of the desired input and output format. The model learns from these examples to generate an appropriate response for a new input. The following is an example few-shot prompt:
- Task decomposition – Task decomposition is a powerful technique that enhances the performance of LLMs by breaking down complex tasks into smaller, manageable sub-tasks. This approach not only improves efficiency and accuracy, but also allows for better resource management and adaptability to task complexity. The following is an example task decomposition prompt:
This produces the following response:
To summarize:
- Zero-shot uses no examples, relying on the model’s existing knowledge
- Few-shot provides a small number of examples to guide the model
- Task decomposition enhances LLM performance by breaking down complex tasks into smaller, manageable sub-tasks.
- CoT breaks down complex reasoning into step-by-step prompts
The choice of technique depends on the complexity of the task and the availability of good example prompts. More complex reasoning usually benefits from CoT prompting.
Meta Llama 3 inference parameters
For Meta Llama 3, the Messages API allows you to interact with the model in a conversational way. You can define the role of the message and the content. The role can be either system, assistant, or user. The system role is used to provide context to the model, and the user role is used to ask questions or provide input to the model.
Users can get tailored responses for their use case using the following inference parameters while invoking Meta Llama 3:
- Temperature – Temperature is a value between 0–1, and it regulates the creativity of Meta Llama 3 responses. Use a lower temperature if you want more deterministic responses, and use a higher temperature if you want more creative or different responses from the model.
- Top-k – This is the number of most-likely candidates that the model considers for the next token. Choose a lower value to decrease the size of the pool and limit the options to more likely outputs. Choose a higher value to increase the size of the pool and allow the model to consider less likely outputs.
- Top-p – Top-p is used to control the token choices made by the model during text generation. It works by considering only the most probable token options and ignoring the less probable ones, based on a specified probability threshold value (p). By setting the top-p value below 1.0, the model focuses on the most likely token choices, resulting in more stable and repetitive completions. This approach helps reduce the generation of unexpected or unlikely outputs, providing greater consistency and predictability in the generated text.
- Stop sequences – This refers to the parameter to control the stopping sequence for the model’s response to a user query. This value can either be
"<|start_header_id|>","<|end_header_id|>", or"<|eot_id|>".
The following is an example prompt with inference parameters specific to the Meta Llama 3 model:
Llama3 Prompt:
Llama3 Inference Parameters:
Example prompts
In this section, we present two example prompts.
The following prompt is for a question answering use case:
This produces the following response:
Clean up
To avoid incurring unnecessary costs, when you are done, delete the SageMaker endpoints using the following code snippets:
Alternatively, to use the SageMaker console, complete the following steps:
- On the SageMaker console, under Inference in the navigation pane, choose Endpoints.
- Search for the embedding and text generation endpoints.
- On the endpoint details page, choose Delete.
- Choose Delete again to confirm.
Conclusion
Model providers such as Meta AI are releasing improved capabilities of their FMs in the form of new generation model families. It is critical for developers and businesses to understand the key differences between previous generation models and new generation models in order to take full advantage their capabilities. This post highlighted the differences between previous generation Meta Llama 2 and the new generation Meta Llama3 models, and demonstrated how developers can discover and deploy the Meta Llama3 models for inference using SageMaker JumpStart.
To fully take advantage of the model’s extensive abilities, you must understand and apply creative prompting techniques and adjust inference parameters. We highlighted key techniques to craft effective prompts for Meta Llama3 to help the LLMs produce high-quality responses tailored to your applications.
Visit SageMaker JumpStart in SageMaker Studio now to get started. For more information, refer to Train, deploy, and evaluate pretrained models with SageMaker JumpStart, JumpStart Foundation Models, and Getting started with Amazon SageMaker JumpStart. Use the SageMaker notebook provided in the GitHub repository as a starting point to deploy the model and run inference using the prompting best practices discussed in this post.
About the Authors
 Sebastian Bustillo is a Solutions Architect at AWS. He focuses on AI/ML technologies with a profound passion for generative AI and compute accelerators. At AWS, he helps customers unlock business value through generative AI. When he’s not at work, he enjoys brewing a perfect cup of specialty coffee and exploring the world with his wife.
Sebastian Bustillo is a Solutions Architect at AWS. He focuses on AI/ML technologies with a profound passion for generative AI and compute accelerators. At AWS, he helps customers unlock business value through generative AI. When he’s not at work, he enjoys brewing a perfect cup of specialty coffee and exploring the world with his wife.
 Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
 Supriya Puragundla is a Senior Solutions Architect at AWS. She helps key customer accounts on their generative AI and AI/ML journey. She is passionate about data-driven AI and the area of depth in machine learning and generative AI.
Supriya Puragundla is a Senior Solutions Architect at AWS. She helps key customer accounts on their generative AI and AI/ML journey. She is passionate about data-driven AI and the area of depth in machine learning and generative AI.
 Farooq Sabir a Senior AI/ML Specialist Solutions Architect at AWS. He holds a PhD in Electrical Engineering from the University of Texas at Austin. He helps customers solve their business problems using data science, machine learning, artificial intelligence, and numerical optimization.
Farooq Sabir a Senior AI/ML Specialist Solutions Architect at AWS. He holds a PhD in Electrical Engineering from the University of Texas at Austin. He helps customers solve their business problems using data science, machine learning, artificial intelligence, and numerical optimization.
 Brayan Montiel is a Solutions Architect at AWS based in Austin, Texas. He supports enterprise customers in the automotive and manufacturing industries, helping to accelerate cloud adoption technologies and modernize IT infrastructure. He specializes in AI/ML technologies, empowering customers to use generative AI and innovative technologies to drive operational growth and efficiencies. Outside of work, he enjoys spending quality time with his family, being outdoors, and traveling.
Brayan Montiel is a Solutions Architect at AWS based in Austin, Texas. He supports enterprise customers in the automotive and manufacturing industries, helping to accelerate cloud adoption technologies and modernize IT infrastructure. He specializes in AI/ML technologies, empowering customers to use generative AI and innovative technologies to drive operational growth and efficiencies. Outside of work, he enjoys spending quality time with his family, being outdoors, and traveling.
 Jose Navarro is an AI/ML Solutions Architect at AWS, based in Spain. Jose helps AWS customers—from small startups to large enterprises—architect and take their end-to-end machine learning use cases to production. In his spare time, he loves to exercise, spend quality time with friends and family, and catch up on AI news and papers.
Jose Navarro is an AI/ML Solutions Architect at AWS, based in Spain. Jose helps AWS customers—from small startups to large enterprises—architect and take their end-to-end machine learning use cases to production. In his spare time, he loves to exercise, spend quality time with friends and family, and catch up on AI news and papers.
Leave a Reply