
Scaling Thomson Reuters’ language model research with Amazon SageMaker HyperPod
Thomson Reuters, a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. The introduction of generative AI provides another opportunity for Thomson Reuters to work with customers and advance how they do their work, helping professionals draw insights and automate workflows, enabling them to focus their time where it matters most.
In this post, we explore the journey that Thomson Reuters took to enable cutting-edge research in training domain-adapted large language models (LLMs) using Amazon SageMaker HyperPod, an Amazon Web Services (AWS) feature focused on providing purpose-built infrastructure for distributed training at scale.
LLMs disrupt the industry
Towards the end of 2022, groundbreaking LLMs were released that realized drastic improvements over previous model capabilities. The resulting technology opened new doors to enhancing customer experiences by tailoring content, recommendations, and responses to individual customers in natural chat-like interfaces. For many businesses, the race was on to bring this technology into their products to maintain or gain competitive advantage. Thomson Reuters was no exception and keenly felt the need to help its customers be successful in this burgeoning, AI-augmented, world.
As with any technology, proper application and understanding of its limitations is critical. Consider the following elements.
- Hallucinations – LLMs have a remarkable ability to respond to natural language, and clearly encode significant amounts of knowledge. However, the stochastic nature of the technology means that responses are based on the probability of word occurrences. An LLM doesn’t model facts so much as it models language. The model has no idea if the words (tokens) generated are factually correct, though it may have successfully modeled the correct sequence of words to represent facts. As a result, LLMs may hallucinate—in other words, they may generate text that is untrue.
- Quality – While the general knowledge encoded in the latest LLMs is remarkably good, it may not be enough for your business or customer domains. Public and commercial LLMs are based on the knowledge of the internet—not what is behind your business’s closed doors. Adding to the problem, bias and factually incorrect information exists on the internet and there often isn’t enough transparency in what data is used and how commercial models are trained with it. Further, LLMs will only have encoded knowledge since their last training. They may not be up-to-date and businesses do not control the frequency of model retraining.
- Speed, cost, and capacity – Depending on your use cases, you may find existing commercial LLMs are either too slow or too expensive or be in such high demand that you cannot purchase enough capacity to meet your requirements. (This may only be a temporary challenge because we’ve observed increased capacity and reduced cost as hardware, optimizations, and economies of scale continue to improve).
Thomson Reuters’ customers require professional-grade AI. They are professionals with discerning information needs in legal, corporate, tax, risk, fraud, compliance, and news domains. Take, for example, legal customers. US law is based on legal precedent—the outcomes of past trial cases are used to determine decisions in new cases. Not only does Thomson Reuters curate and enhance publicly available content such as regulations and laws, but it also has decades of editorial content on most aspects of the law that it analyzes and reflects upon. Legal research is a critical area for Thomson Reuters customers—it needs to be as complete as possible. It needs to be grounded in fact—any kind of errors in fact are highly problematic. Solutions should be grounded in the content and data that Thomson Reuters has.
Research and training experimentation
Thinking about the limitations of publicly available, commercial language models as described in the previous section, Thomson Reuters asked themselves the following questions:
- Can Thomson Reuters’ editorially created, curated, or enhanced data be used to improve LLM knowledge for specific business tasks?
- Would smaller LLMs (for example, 12–30B parameters) trained with Thomson Reuters data perform on a par with very large LLMs upwards of a trillion parameters?
- What methods could be employed to train the Thomson Reuters domain-specific models to get the best results?
The potential benefits fell in three areas: quality, agency, and operational efficiency. With full access to model training, it’s possible that Thomson Reuters could tune LLM generation to their domain and allow for tighter Retrieval Augmented Generation (RAG) integration. This would directly impact quality. And if Thomson Reuters own the models, they would control how and when they are trained and updated. Lastly, if smaller tuned models could perform sufficiently, it could be a more cost-effective and scalable solution—improving overall operational efficiency.
Thomson Reuters’ research focused around answering these specific questions:
- How well do foundation models (FMs) (in the 7–30B parameters range) perform on specific tasks, unmodified? (This would be the baseline.)
- Does performance improve for specific tasks when augmented with Thomson Reuters domain-specific data using various training techniques?
To frame this research and give concrete evaluation targets, Thomson Reuters focused on several real-world tasks: legal summarization, classification, and question answering. Publicly available general textual data was used, as well as domain specific textual data from Thomson Reuters’ comprehensive stores of primary and secondary US law material. Primary law would include content published by the courts and enhanced by Thomson Reuters. Secondary law would include subject matter expert (SME) analysis and annotation of the law.
Thomson Reuters knew they would need to run a series of experiments—training LLMs from 7B to more than 30B parameters, starting with an FM and continuous pre-training (using various techniques) with a mix of Thomson Reuters and general data. Model fine-tuning would then take place to evaluate how much better it performed on specific legal tasks while at the same time evaluating for any loss in general knowledge or language understanding.
- Continuous pre-training – By further pre-training an existing FM, Thomson Reuters wished to enrich its understanding of legalese without compromising its general language abilities. This was largely an experiment in finding the right mix of domain and general training data to retain general knowledge while increasing domain-specific knowledge. Perplexity was used to measure impact of domain-specific training on general knowledge capabilities of the model.
- Instruction fine-tuning – This would be an exercise in generating impactful instruction datasets, including legal and general tasks. Thomson Reuters experimented with pre-training open source FMs, such as MPT, Flan-T5, and Mistral, and compared against industry standard commercial models, such as OpenAI’s GPT-4. In this case, Rouge was used to measure how well models performed on tasks.
Scaling language model training with Amazon SageMaker HyperPod
Thomson Reuters knew that training LLMs would require significant computing power. Training an LLM of even 7B parameters is a compute-intensive operation, requiring multi-node distributed computing capabilities. These compute nodes typically need large GPUs or similar hardware. In Thomson Reuters’ case, they focused on NVIDIA’s high performance A100 family of GPUs. Amazon Elastic Compute Cloud (Amazon EC2) P4d and P4de instances provided Thomson Reuters with the high performance they needed.
To estimate just how much compute power was required, Thomson Reuters used the Chinchilla scaling law to determine how much training data (in tokens) would be needed to retain quality at a given model size. The scaling law is based on published research that found that the model size to training tokens scales proportionally. From there, other publicly available information was used to estimate how much time (in days) would be required to complete training with a given number of GPUs.
| . | . | Model size | ||||
| P4d | #GPUs | 2.6b (days) | 6.6b (days) | 13b (days) | 30b (days) | 65b (days) |
| 8 | 64 | 1 | 6.6 | 24 | 125.4 | 918.4 |
| 16 | 128 | 0.5 | 3.3 | 12 | 62.7 | 459.2 |
| 32 | 256 | 0.2 | 1.7 | 6 | 31.3 | 229.6 |
| 55 | 440 | 0.1 | 1 | 3.5 | 17.9 | 164 |
| 64 | 512 | 0.1 | 0.9 | 3 | 15.7 | 114.8 |
| . | Chinchilla point | 52b | 132b | 260b | 600b | 1.3t |
So, for example, a 6.6B parameter model would require 132B input tokens and take just under 7 days to finish training with 64 A100 GPUs (or 8 P4d instances).
Apart from the ability to easily provision compute, there are other factors such as cluster resiliency, cluster management (CRUD operations), and developer experience, which can impact LLM training. With potentially hundreds of GPUs working in parallel, hardware failures are inevitable. To resolve these issues, customers typically have to identify, isolate, repair, and recover the faulty instance, or change configurations to continue without it, further delaying progress.
In order to provision a highly scalable cluster that is resilient to hardware failures, Thomson Reuters turned to Amazon SageMaker HyperPod. SageMaker HyperPod is a managed service that makes it easier for you to train FMs without interruptions or delays. It provides resilient and persistent clusters for large-scale deep learning training of FMs on long-running compute clusters. SageMaker HyperPod offers an interactive experience for rapid experimentation at scale, with resilience to hardware failures, enabling uninterrupted training jobs spanning weeks or months. With Amazon Elastic Kubernetes Service (Amazon EKS) support in SageMaker HyperPod, customers can associate a HyperPod cluster with an EKS cluster and manage ML workloads using the HyperPod cluster nodes as Kubernetes worker nodes, all through the Kubernetes control plane on the EKS cluster.
Amazon EKS support in SageMaker HyperPod offers several key resiliency features to make uninterrupted and efficient training of large ML models possible:
- Deep health checks – This is a managed health check for stress testing GPUs and AWS trn1 instances, as well as performing Elastic Fabric Adapter (EFA) checks. These checks can be run during the cluster creation, update, and node replacement phase and can be easily enabled or disabled through HyperPod APIs.
- Automatic node replacement – A monitoring agent performs managed, lightweight, and noninvasive checks, coupled with automated node replacement capability. This monitoring agent continuously monitors and detects potential issues, including memory exhaustion, disk failures, GPU anomalies, kernel deadlocks, container runtime issues, and out-of-memory (OOM) crashes. Based on the underlying issue, the monitoring agent either replaces or reboots the node.
- Auto-resume – SageMaker HyperPod provides job auto-resume capability using the Kubeflow training operator for PyTorch so that training jobs can recover and continue in the event of interruptions or failures. The extension makes sure that the job waits and restarts after the node is replaced.
Initial findings
Over the course of 5 months, Thomson Reuters successfully ran 20 training jobs using Amazon SageMaker HyperPod. They were able to scale their cluster up to 16 P4d instances, with their largest job using the entire cluster. Thomson Reuters trained a 70B parameter model on 400B input tokens, with the entire training job taking 36 days to complete. During that period, Thomson Reuters experienced zero hardware failures.
Continuous pre-training
In continuous pre-training, you train from an existing open source LLM checkpoint. This is more than a time-saver; it is a strategic decision that allows for the nuanced growth of the model’s capabilities over time. The preliminary results of Thomson Reuters’ experimentation showed that they were able to train models on the legal domain without losing general knowledge.
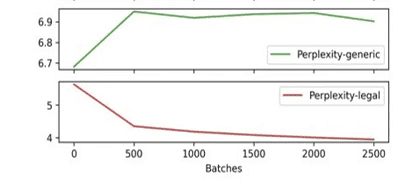
Thomson Reuters used a measure called perplexity. It quantifies how well the model predicts a sample of text. In essence, perplexity measures the confidence a model has in its predictions. Lower perplexity indicates that the model is more certain about its predictions. From the following graph, you can see that as Thomson Reuters increased their batches of training, legal perplexity decreased while general perplexity increased somewhat, before quickly leveling off.
Instruction fine-tuning (IFT)
Instruct fine-tuned LLMs are tuned to respond to specific instructions, enabling tasks such as question answering, summarization, and brainstorming. For instance, human-written instruction datasets include prompts such as “summarize this article” or “list fun weekend activities.” Thomson Reuters’ hypothesis was that legal LLMs can benefit from diverse legal instructions.
Thomson Reuters has discovered that their legal LLM greatly benefits from a vast array of diverse instructions. By compiling legal instructions, such as drafting legal headnotes, and combining them with publicly available instructions, Thomson Reuters’ MPT-TR-7b model, derived from MPT-7b, has showcased improvements correlated with an increased number of instruction datasets provided.
Thomson Reuters used an automatic measure called Rouge to determine how well domain adapted models performed compared to GPT-4. This automatic measure, based on term overlap, is not the same as human preference judgment, but gives Thomson Reuters some degree of confidence that they are headed in the right direction.
Legal summarization
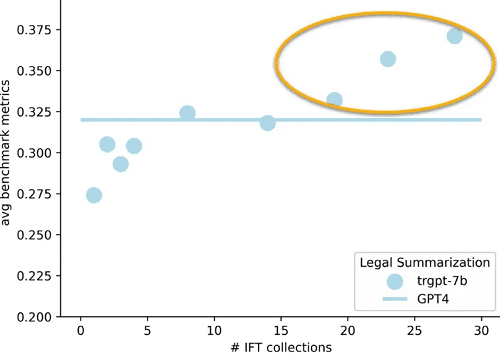
Thomson Reuters’ MPT-TR-7b model has demonstrated proficiency in legal summarization tasks, rivaling GPT-4’s performance when evaluated with automatic metrics assessing word overlap with reference summaries. While a human-based evaluation would offer deeper insights, the initial results are compelling evidence of the model’s capabilities. The following graph compares Thomson Reuters’ model with GPT-4.
Legal classification
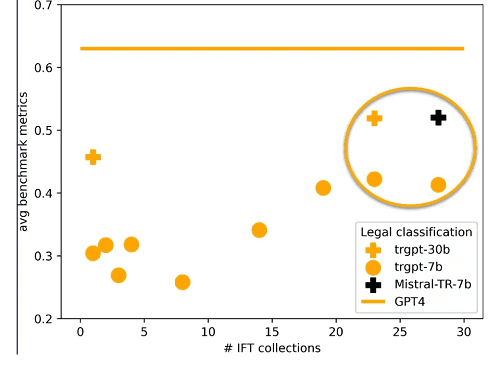
In other legal tasks, such as classification that was measured in accuracy and precision or recall, there’s still room to improve. Nonetheless, the performance uptick is evident with the expansion of instruction datasets, as shown in the following graph. Even more exciting is the leap in performance observed with larger base models such as MPT-30b.
Conclusion
In this post, we have discussed how Thomson Reuters was able to meet their LLM training requirements using Amazon SageMaker HyperPod. Using Amazon EKS on HyperPod, Thomson Reuters was able to scale up their capacity and easily run their training jobs, permitting Thomson Reuters to unlock benefits of LLMs in areas such as legal summarization and classification.
If your business operates in specialized or deep verticals with knowledge not generally available on the web, experimenting with model training may make sense. At the same time, you’ll need to weigh the costs associated with training and inference as well as keeping up with rapidly advancing LLM technology. Like Thomson Reuters, you might want to start with RAG solutions with off-the-shelf LLMs as a first step, then consider customization options from there. If you do decide that training LLMs makes sense, then you’ll need considerable computational power. Amazon SageMaker HyperPod helps you to provision and manage the infrastructure required. Read more about Amazon SageMaker HyperPod and Amazon EKS support in SageMaker HyperPod.
About the Authors
 John Duprey is a Distinguished Engineer at Thomson Reuters Labs with over 25 years of experience. In his role, John drives innovative solutions to complex problems and champions engineering excellence and culture. Recently, he has contributed to Thomson Reuters’ generative AI initiatives, focusing on scalability, platform design, and SDK development.
John Duprey is a Distinguished Engineer at Thomson Reuters Labs with over 25 years of experience. In his role, John drives innovative solutions to complex problems and champions engineering excellence and culture. Recently, he has contributed to Thomson Reuters’ generative AI initiatives, focusing on scalability, platform design, and SDK development.
 Adam Raffe is a Principal Solutions Architect at AWS. With over 8 years of experience in cloud architecture, Adam helps large enterprise customers solve their business problems using AWS.
Adam Raffe is a Principal Solutions Architect at AWS. With over 8 years of experience in cloud architecture, Adam helps large enterprise customers solve their business problems using AWS.
 Vu San Ha Huynh is a Solutions Architect at AWS. He has a PhD in computer science and enjoys working on different innovative projects to help support large enterprise customers.
Vu San Ha Huynh is a Solutions Architect at AWS. He has a PhD in computer science and enjoys working on different innovative projects to help support large enterprise customers.
 Ankit Anand is a Senior Foundation Models Go-To-Market (GTM) Specialist at AWS. He partners with top generative AI model builders, strategic customers, and AWS Service Teams to enable the next generation of AI/ML workloads on AWS. Ankit’s experience includes product management expertise within the financial services industry for high-frequency/low-latency trading and business development for Amazon Alexa.
Ankit Anand is a Senior Foundation Models Go-To-Market (GTM) Specialist at AWS. He partners with top generative AI model builders, strategic customers, and AWS Service Teams to enable the next generation of AI/ML workloads on AWS. Ankit’s experience includes product management expertise within the financial services industry for high-frequency/low-latency trading and business development for Amazon Alexa.
 Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He specializes in large model training workloads helping customers build LLM workloads using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, he enjoys running, hiking, and cooking.
Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He specializes in large model training workloads helping customers build LLM workloads using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, he enjoys running, hiking, and cooking.
 Simone Zucchet is a Solutions Architect Manager at AWS. With over 6 years of experience as a Cloud Architect, Simone enjoys working on innovative projects that help transform the way organizations approach business problems. He helps support large enterprise customers at AWS and is part of the Machine Learning TFC. Outside of his professional life, he enjoys working on cars and photography.
Simone Zucchet is a Solutions Architect Manager at AWS. With over 6 years of experience as a Cloud Architect, Simone enjoys working on innovative projects that help transform the way organizations approach business problems. He helps support large enterprise customers at AWS and is part of the Machine Learning TFC. Outside of his professional life, he enjoys working on cars and photography.
Leave a Reply