
Integrate dynamic web content in your generative AI application using a web search API and Amazon Bedrock Agents
Amazon Bedrock Agents offers developers the ability to build and configure autonomous agents in their applications. These agents help users complete actions based on organizational data and user input, orchestrating interactions between foundation models (FMs), data sources, software applications, and user conversations.
Amazon Bedrock agents use the power of large language models (LLMs) to perform complex reasoning and action generation. This approach is inspired by the ReAct (reasoning and acting) paradigm, which combines reasoning traces and task-specific actions in an interleaved manner.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. The ReAct approach enables agents to generate reasoning traces and actions while seamlessly integrating with company systems through action groups. By offering accelerated development, simplified infrastructure, enhanced capabilities through chain-of-thought (CoT) prompting, and improved accuracy, Amazon Bedrock Agents allows developers to rapidly build sophisticated AI solutions that combine the power of LLMs with custom actions and knowledge bases, all without managing underlying complexity.
Web search APIs empower developers to seamlessly integrate powerful search capabilities into their applications, providing access to vast troves of internet data with just a few lines of code. These APIs act as gateways to sophisticated search engines, allowing applications to programmatically query the web and retrieve relevant results including webpages, images, news articles, and more.
By using web search APIs, developers can enhance their applications with up-to-date information from across the internet, enabling features like content discovery, trend analysis, and intelligent recommendations. With customizable parameters for refining searches and structured response formats for parsing, web search APIs offer a flexible and efficient solution for harnessing the wealth of information available on the web.
Amazon Bedrock Agents offers a powerful solution for enhancing chatbot capabilities, and when combined with web search APIs, they address a critical customer pain point. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
Benefits of integrating a web search API with Amazon Bedrock Agents
Let’s explore how this integration can revolutionize your chatbot experience:
- Seamless in-chat web search – By incorporating web search APIs into your Amazon Bedrock agents, you can empower your chatbot to perform real-time web searches without forcing users to leave the chat interface. This keeps users engaged within your application, improving overall user experience and retention.
- Dynamic information retrieval – Amazon Bedrock agents can use web search APIs to fetch up-to-date information on a wide range of topics. This makes sure that your chatbot provides the most current and relevant responses, enhancing its utility and user trust.
- Contextual responses – Amazon Bedrock agent uses CoT prompting, enabling FMs to plan and run actions dynamically. Through this approach, agents can analyze user queries and determine when a web search is necessary or—if enabled—gather more information from the user to complete the task. This allows your chatbot to blend information from APIs, knowledge bases, and up-to-date web-sourced content, creating a more natural and informative conversation flow. With these capabilities, agents can provide responses that are better tailored to the user’s needs and the current context of the interaction.
- Enhanced problem solving – By integrating web search APIs, your Amazon Bedrock agent can tackle a broader range of user inquiries. Whether it’s troubleshooting a technical issue or providing industry insights, your chatbot becomes a more versatile and valuable resource for users.
- Minimal setup, maximum impact – Amazon Bedrock agents simplify the process of adding web search functionality to your chatbot. With just a few configuration steps, you can dramatically expand your chatbot’s knowledge base and capabilities, all while maintaining a streamlined UI.
- Infrastructure as code – You can use AWS CloudFormation or the AWS Cloud Development Kit (AWS CDK) to deploy and manage Amazon Bedrock agents.
By addressing the customer challenge of expanding chatbot functionality without complicating the user experience, the combination of web search APIs and Amazon Bedrock agents offers a compelling solution. This integration allows businesses to create more capable, informative, and user-friendly chatbots that keep users engaged and satisfied within a single interface.
Solution overview
This solution uses Amazon Bedrock Agents with a web search capability that integrates external search APIs (SerpAPI and Tavily AI) with the agent. The architecture consists of the following key components:
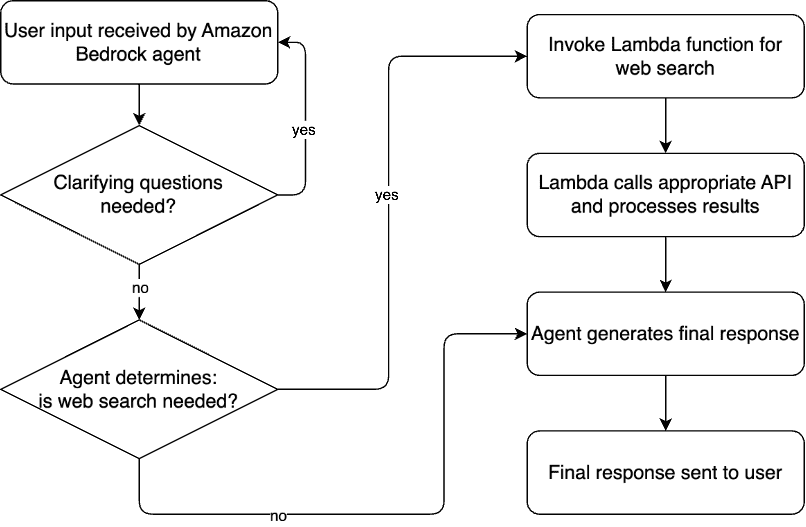
- An Amazon Bedrock agent orchestrates the interaction between the user and search APIs, handling the chat sessions and optionally long-term memory
- An AWS Lambda function implements the logic for calling external search APIs and processing results
- External search APIs (SerpAPI and Tavily AI) provide web search capabilities
- Amazon Bedrock FMs generate natural language responses based on search results
- AWS Secrets Manager securely stores API keys for external services
The solution flow is as follows:
- User input is received by the Amazon Bedrock agent, powered by Anthropic Claude 3 Sonnet on Amazon Bedrock.
- The agent determines if a web search is necessary, or comes back to the user with clarifying questions.
- If required, the agent invokes one of two Lambda functions to perform a web search: SerpAPI for up-to-date events or Tavily AI for web research-heavy questions.
- The Lambda function retrieves the API secrets securely from Secrets Manager, calls the appropriate search API, and processes the results.
- The agent generates the final response based on the search results.
- The response is returned to the user after final output guardrails are applied.
The following figure is a visual representation of the system we are going to implement.
We demonstrate two methods to build this solution. To set up the agent on the AWS Management Console, we use the new agent builder. The following GitHub repository contains the Python AWS CDK code to deploy the same example.
Prerequisites
Make sure you have the following prerequisites:
- An active AWS account.
- The prerequisites for Amazon Bedrock Agents in place.
- Amazon Bedrock agents are currently available in select AWS Regions. Check the latest list of supported Regions and make sure you’re working in one of those Regions.
Amazon Bedrock agents support models like Amazon Titan Text and Anthropic Claude models. Each model has different capabilities and pricing. For the full list of supported models, see Supported regions and models for Amazon Bedrock Agents.
For this post, we use the Anthropic Claude 3 Sonnet model.
Configure the web search APIs
Both SERPER (SerpAPI) and Tavily AI provide web search APIs that can be integrated with Amazon Bedrock agents by calling their REST-based API endpoints from a Lambda function. However, they have some key differences that can influence when you would use each one:
- SerpAPI provides access to multiple search engines, including Google, Bing, Yahoo, and others. It offers granular control over search parameters and result types (for example, organic results, featured snippets, images, and videos). SerpAPI might be better suited for tasks requiring specific search engine features or when you need results from multiple search engines.
- Tavily AI is specifically designed for AI agents and LLMs, focusing on delivering relevant and factual results. It offers features like including answers, raw content, and images in search results. It provides customization options such as search depth (basic or advanced) and the ability to include or exclude specific domains. It’s optimized for speed and efficiency in delivering real-time results.
You would use SerpAPI if you need results from specific search engines or multiple engines, and Tavily AI when relevance and factual accuracy are crucial.
Ultimately, the choice between SerpAPI and Tavily AI depends on your specific research requirements, the level of control you need over search parameters, and whether you prioritize general search engine capabilities or AI-optimized results.
For the example in this post, we chose to use both and let the agent decide which API is the more appropriate one, depending on the question or prompt. The agent can also opt to call both if one doesn’t provide a good enough answer. Both SerpAPI and Tavily AI provide a free tier that can be used for the example in this post.
For both APIs, API keys are required and are available from Serper and Tavily.
We securely store the obtained API keys in Secrets Manager. The following examples create secrets for the API keys:
When you enter commands in a shell, there is a risk of the command history being accessed or utilities having access to your command parameters. For more information, see Mitigate the risks of using the AWS CLI to store your AWS Secrets Manager secrets.
Now that the APIs are configured, you can start building the web search Amazon Bedrock agent.
In the following section, we present two methods to create your agent: through the console and using the AWS CDK. Although the console path offers a more visual approach, we strongly recommend using the AWS CDK for deploying the agent. This method not only provides a more robust deployment process, but also allows you to examine the underlying code. Let’s explore both options to help you choose the best approach for your needs.
Build a web search Amazon Bedrock agent using the console
In the first example, you build a web search agent using the Amazon Bedrock console to create and configure the agent, and then the Lambda console to configure and deploy a Lambda function.
Create a web search agent
To create a web search agent using the console, complete the following steps:
- On the Amazon Bedrock console, choose Agents in the navigation pane.
- Choose Create agent.
- Enter a name for the agent (such as
websearch-agent) and an optional description, then choose Create.

You are now in the new agent builder, where you can access and edit the configuration of an agent.
- For Agent resource role, leave the default Create and use a new service role
This option automatically creates the AWS Identity and Access Management (IAM) role assumed by the agent.
- For the model, choose Anthropic and Claude 3 Sonnet.

- For Instructions for the Agent, provide clear and specific instructions to tell the agent what it should do. For the web search agent, enter:
- Choose Add in the Action groups
Action groups are how agents can interact with external systems or APIs to get more information or perform actions.
- For Enter action group name, enter
action-group-web-searchfor the action group. - For Action group type, select Define with function details so you can specify functions and their parameters as JSON instead of providing an Open API schema.
- For Action group invocation, set up what the agent does after this action group is identified by the model. Because we want to call the web search APIs, select Quick create a new Lambda function.
With this option, Amazon Bedrock creates a basic Lambda function for your agent that you can later modify on the Lambda console for the use case of calling the web search APIs. The agent will predict the function and function parameters needed to fulfil its goal and pass the parameters to the Lambda function.

- Now, configure the two functions of the action group—one for the SerpAPI Google search, and one for the Tavily AI search.
- For each of the two functions, for Parameters, add
search_querywith a description.
This is a parameter of type String and is required by each of the functions.
- Choose Create to complete the creation of the action group.

We use the following parameter descriptions:
We encourage you to try to add a target website as an extra parameter to the action group functions. Take a look at the lambda function code and infer the settings.
You will be redirected to the agent builder console.
- Choose Save to save your agent configuration.
Configure and deploy a Lambda function
Complete the following steps to update the action group Lambda function:
- On the Lambda console, locate the new Lambda function with the name
action-group-web-search-. - Edit the provided starting code and implement the web search use case:
The code is truncated for brevity. The full code is available on GitHub.
- Choose Deploy.
The function is configured with a resource-based policy that allows Amazon Bedrock to invoke the function. For this reason, you don’t need to update the IAM role used by the agent.
As part of the Quick create a new Lambda function option selected earlier, the agent builder configured the function with a resource-based policy that allows the Amazon Bedrock service principal to invoke the function. There is no need to update the IAM role used by the agent. However, the function needs permission to access API keys saved in Secrets Manager.
- On the function details page, choose the Configuration tab, then choose Permissions.
- Choose the link for Role name to open the role on the IAM console.
- Open the JSON view of the IAM policy under Policy name and choose Edit to edit the policy.

- Add the following statement, which gives the Lambda function the required access to read the API keys from Secrets Manager. Adjust the Region code as needed, and provide your AWS account ID.
Test the agent
You’re now ready to test the agent.
- On the Amazon Bedrock console, on the
websearch-agentdetails page, choose Test. - Choose Prepare to prepare the agent and test it with the latest changes.
- As test input, you can ask a question such as “What are the latest news from AWS?”
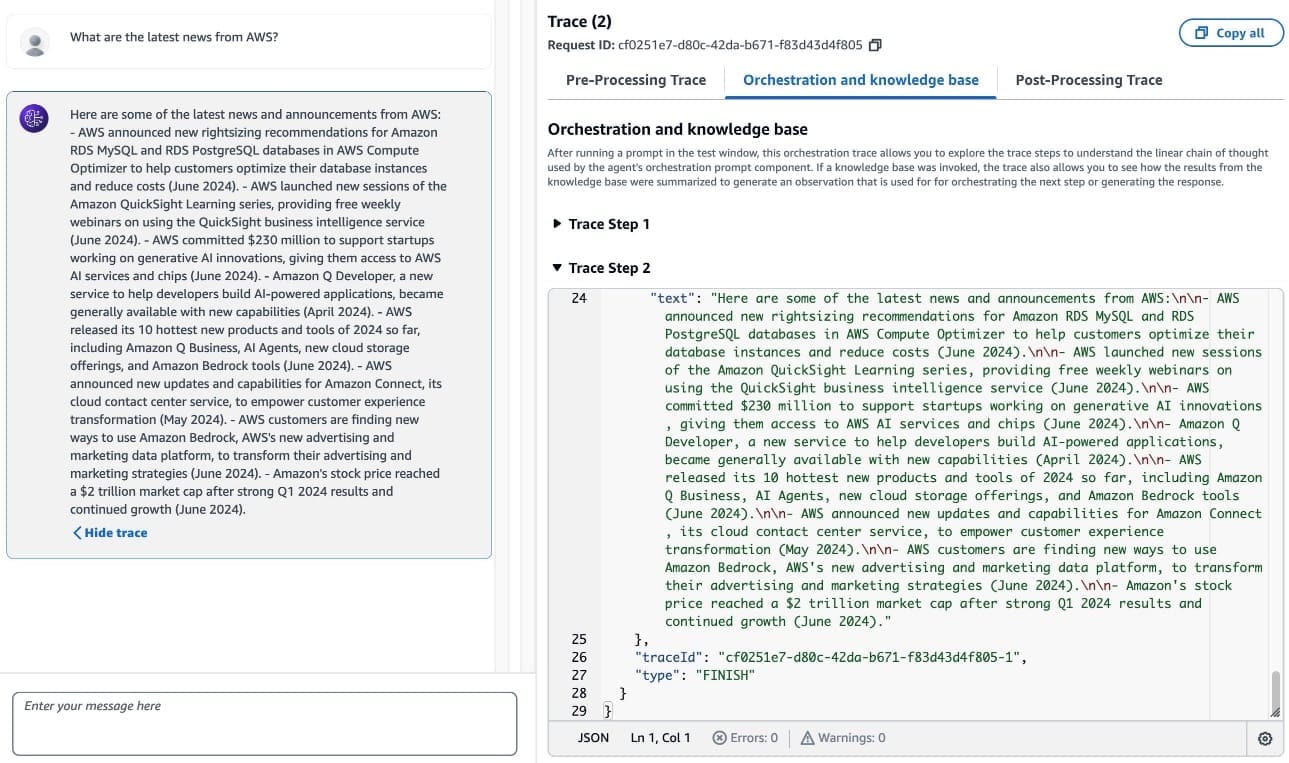
- To see the details of each step of the agent orchestration, including the reasoning steps, choose Show trace (already opened in the preceding screenshot).
This helps you understand the agent decisions and debug the agent configuration if the result isn’t as expected. We encourage you to investigate how the instructions for the agent and the tool instructions are handed to the agent by inspecting the traces of the agent.
In the next section, we walk through deploying the web search agent with the AWS CDK.
Build a web search Amazon Bedrock agent with the AWS CDK
Both AWS CloudFormation and AWS CDK support have been released for Amazon Bedrock Agents, so you can develop and deploy the preceding agent completely in code.
The AWS CDK example in this post uses Python. The following are the required steps to deploy this solution:
- Install the AWS CDK version 2.174.3 or later and set up your AWS CDK Python environment with Python 3.11 or later.
- Clone the GitHub repository and install the dependencies.
- Run AWS CDK bootstrapping on your AWS account.
The structure of the sample AWS CDK application repository is:
- /app.py file – Contains the top-level definition of the AWS CDK app
- /cdk folder – Contains the stack definition for the web search agent stack
- /lambda folder – Contains the Lambda function runtime code that handles the calls to the Serper and Tavily AI APIs
- /test folder – Contains a Python script to test the deployed agent
To create an Amazon Bedrock agent, the key resources required are:
- An action group that defines the functions available to the agent
- A Lambda function that implements these functions
- The agent itself, which orchestrates the interactions between the FMs, functions, and user conversations
AWS CDK code to define an action group
The following Python code defines an action group as a Level 1 (L1) construct. L1 constructs, also known as AWS CloudFormation resources, are the lowest-level constructs available in the AWS CDK and offer no abstraction. Currently, the available Amazon Bedrock AWS CDK constructs are L1. With the action_group_executor parameter of AgentActionGroupProperty, you define the Lambda function containing the business logic that is carried out when the action is invoked.
After the Amazon Bedrock agent determines the API operation that it needs to invoke in an action group, it sends information alongside relevant metadata as an input event to the Lambda function.
The following code shows the Lambda handler function that extracts the relevant metadata and populated fields from the request body parameters to determine which function (Serper or Tavily AI) to call. The extracted parameter is search_query, as defined in the preceding action group function. The complete Lambda Python code is available in the GitHub repository.
Lastly, with the CfnAgent AWS CDK construct, specify an agent as a resource. The auto_prepare=True parameter creates a DRAFT version of the agent that can be used for testing.
Deploy the AWS CDK application
Complete the following steps to deploy the agent using the AWS CDK:
- Clone the example AWS CDK code:
- Create a Python virtual environment, activate it, and install Python dependencies (make sure that you’re using Python 3.11 or later):
- To deploy the agent AWS CDK example, run the cdk deploycommand:
When the AWS CDK deployment is finished, it will output values for agent_id and agent_alias_id:
For example:
Make a note of the outputs; you need them to test the agent in the next step.
Test the agent
To test the deployed agent, a Python script is available in the test/ folder. You must be authenticated using an AWS account and an AWS_REGION environment variable set. For details, see Configure the AWS CLI.
To run the script, you need the output values and to pass in a question using the -prompt parameter:
For example, with the outputs we received from the preceding cdk deploy command, you would run the following:
You would receive the following response (output is truncated for brevity):
Clean up
To delete the resources deployed with the agent AWS CDK example, run the following command:
Use the following commands to delete the API keys created in Secrets Manager:
Key considerations
Let’s dive into some key considerations when integrating web search into your AI systems.
API usage and cost management
When working with external APIs, it’s crucial to make sure that your rate limits and quotas don’t become bottlenecks for your workload. Regularly check and identify limiting factors in your system and validate that it can handle the load as it scales. This might involve implementing a robust monitoring system to track API usage, setting up alerts for when you’re approaching limits, and developing strategies to gracefully handle rate-limiting scenarios.
Additionally, carefully consider the cost implications of external APIs. The amount of content returned by these services directly translates into token usage in your language models, which can significantly impact your overall costs. Analyze the trade-offs between comprehensive search results and the associated token consumption to optimize your system’s efficiency and cost-effectiveness. Consider implementing caching mechanisms for frequently requested information to reduce API calls and associated costs.
Privacy and security considerations
It’s essential to thoroughly review the pricing and privacy agreements of your chosen web search provider. The agentic systems you’re building can potentially leak sensitive information to these providers through the search queries sent. To mitigate this risk, consider implementing data sanitization techniques to remove or mask sensitive information before it reaches the search provider. This becomes especially crucial when building or enhancing secure chatbots and internally facing systems—educating your users about these privacy considerations is therefore of utmost importance.
To add an extra layer of security, you can implement guardrails, such as those provided by Amazon Bedrock Guardrails, in the Lambda functions that call the web search. This additional safeguard can help protect against inadvertent information leakage to web search providers. These guardrails could include pattern matching to detect potential personally identifiable information (PII), allow and deny lists for certain types of queries, or AI-powered content classifiers to flag potentially sensitive information.
Localization and contextual search
When designing your web search agent, it’s crucial to consider that end-users are accustomed to the search experience provided by standard web browsers, especially on mobile devices. These browsers often supply additional context as part of a web search, significantly enhancing the relevance of results. Key aspects of localization and contextual search include language considerations, geolocation, search history and personalization, and time and date context. For language considerations, you can implement language detection to automatically identify the user’s preferred language or provide it through the agent’s session context.
Refer to Control agent session context for details on how to provide session context in Amazon Bedrock Agents for more details.
It’s important to support multilingual queries and results, using a model that supports your specific language needs. Geolocation is another critical factor; utilizing the user’s approximate location (with permission) can provide geographically relevant results. Search history and personalization can greatly enhance the user experience. Consider implementing a system (with user consent) to remember recent searches and use this context for result ranking. You can customize an Amazon Bedrock agent with the session state feature. Adding a user’s location attributes to the session state is a potential implementation option.
Additionally, allow users to set persistent preferences for result types, such as preferring videos over text articles. Time and date context is also vital; use the user’s local time zone for time-sensitive queries like “latest news on quarterly numbers of company XYZ, now,” and consider seasonal context for queries that might have different meanings depending on the time of year.
For instance, without providing such extra information, a query like “What is the current weather in Zurich?” could yield results for any Zurich globally, be it in Switzerland or various locations in the US. By incorporating these contextual elements, your search agent can distinguish that a user in Europe is likely asking about Zurich, Switzerland, whereas a user in Illinois might be interested in the weather at Lake Zurich. To implement these features, consider creating a system that safely collects and utilizes relevant user context. However, always prioritize user privacy and provide clear opt-in mechanisms for data collection. Clearly communicate what data is being used and how it enhances the search experience. Offer users granular control over their data and the ability to opt out of personalized features. By carefully balancing these localization and contextual search elements, you can create a more intuitive and effective web search agent that provides highly relevant results while respecting user privacy.
Performance optimization and testing
Performance optimization and testing are critical aspects of building a robust web search agent. Implement comprehensive latency testing to measure response times for various query types and content lengths across different geographical regions. Conduct load testing to simulate concurrent users and identify system limits if applicable to your application. Optimize your Lambda functions for cold starts and runtime, and consider using Amazon CloudFront to reduce latency for global users. Implement error handling and resilience measures, including fallback mechanisms and retry logic. Set up Amazon CloudWatch alarms for key metrics such as API latency and error rates to enable proactive monitoring and quick response to performance issues.
To test the solution end to end, create a dataset of questions and correct answers to test if changes to your system improve or deteriorate the information retrieval capabilities of your app.
Migration strategies
For organizations considering a migration from open source frameworks like LangChain to Amazon Bedrock Agents, it’s important to approach the transition strategically. Begin by mapping your current ReAct agent’s logic to the Amazon Bedrock agents’ action groups and Lambda functions. Identify any gaps in functionality and plan for alternative solutions or custom development where necessary. Adapt your existing API calls to work with the Amazon Bedrock API and update authentication methods to use IAM roles and policies.
Develop comprehensive test suites to make sure functionalities are correctly replicated in the new environment. One significant advantage of Amazon Bedrock agents is the ability to implement a gradual rollout. By using the agent alias ID, you can quickly direct traffic between different versions of your agent, allowing for a smooth and controlled migration process. This approach enables you to test and validate your new implementation with a subset of users or queries before fully transitioning your entire system.
By carefully balancing these considerations—from API usage and costs to privacy concerns, localization, performance optimization, and migration strategies—you can create a more intelligent, efficient, and user-friendly search experience that respects individual preferences and data protection regulations. As you build and refine your web search agent with Amazon Bedrock, keep these factors in mind to provide a robust, scalable, and responsible AI system.
Expanding the solution
With this post, you’ve taken the first step towards revolutionizing your applications with Amazon Bedrock Agents and the power of agentic workflows with LLMs. You’ve not only learned how to integrate dynamic web content, but also gained insights into the intricate relationship between AI agents and external information sources.
Transitioning your existing systems to Amazon Bedrock agents is a seamless process, and with the AWS CDK, you can manage your agentic AI infrastructure as code, providing scalability, reliability, and maintainability. This approach not only streamlines your development process, but also paves the way for more sophisticated AI-driven applications that can adapt and grow with your business needs.
Expand your horizons and unlock even more capabilities:
- Connect to an Amazon Bedrock knowledge base – Augment your agents’ knowledge by integrating them with a centralized knowledge repository, enabling your AI to draw upon a vast, curated pool of information tailored to your specific domain.
- Embrace streaming – Use the power of streaming responses to provide an enhanced user experience and foster a more natural and interactive conversation flow, mimicking the real-time nature of human dialogue and keeping users engaged throughout the interaction.
- Expose ReAct prompting and tool use – Parse the streaming output on your frontend to visualize the agent’s reasoning process and tool usage, providing invaluable transparency and interpretability for your users, building trust, and allowing users to understand and verify the AI’s decision-making process.
- Utilize memory for Amazon Bedrock Agents – Amazon Bedrock agents can retain a summary of their conversations with each user and are able to provide a smooth, adaptive experience if enabled. This allows you to give extra context for tasks like web search and topics of interest, creating a more personalized and contextually aware interaction over time.
- Give extra context – As outlined earlier, context matters. Try to implement additional user context through the session attributes that you can provide through the session state. Refer to Control agent session context for the technical implementations, and consider how this context can be used responsibly to enhance the relevance and accuracy of your agent’s responses.
- Add agentic web research – Agents allow you to build very sophisticated workflows. Our system is not limited to a simple web search. The Lambda function can also serve as an environment to implement an agentic web research with multi-agent collaboration, enabling more comprehensive and nuanced information gathering and analysis.
What other tools would you use to complement your agent? Refer to the aws-samples GitHub repo for Amazon Bedrock Agents to see what others have built and consider how these tools might be integrated into your own unique AI solutions.
Conclusion
The future of generative AI is here, and Amazon Bedrock Agents is your gateway to unlocking its full potential. Embrace the power of agentic LLMs and experience the transformative impact they can have on your applications and user experiences. As you embark on this journey, remember that the true power of AI lies not just in its capabilities, but in how we thoughtfully and responsibly integrate it into our systems to solve real-world problems and enhance human experiences.
If you would like us to follow up with a second post tackling any points discussed here, feel free to leave a comment. Your engagement helps shape the direction of our content and makes sure we’re addressing the topics that matter most to you and the broader AI community.
In this post, you have seen the steps needed to integrate dynamic web content and harness the full potential of generative AI, but don’t stop here. Transitioning your existing systems to Amazon Bedrock agents is a seamless process, and with the AWS CDK, you can manage your agentic AI infrastructure as code, providing scalability, reliability, and maintainability.
About the Authors
 Philipp Kaindl is a Senior Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. With a background in data science and mechanical engineering, his focus is on empowering customers to create lasting business impact with the help of AI. Connect with Philipp on LinkedIn.
Philipp Kaindl is a Senior Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. With a background in data science and mechanical engineering, his focus is on empowering customers to create lasting business impact with the help of AI. Connect with Philipp on LinkedIn.
 Markus Rollwagen is a Senior Solutions Architect at AWS, based in Switzerland. He enjoys deep dive technical discussions, while keeping an eye on the big picture and the customer goals. With a software engineering background, he embraces infrastructure as code and is passionate about all things security. Connect with Markus on LinkedIn.
Markus Rollwagen is a Senior Solutions Architect at AWS, based in Switzerland. He enjoys deep dive technical discussions, while keeping an eye on the big picture and the customer goals. With a software engineering background, he embraces infrastructure as code and is passionate about all things security. Connect with Markus on LinkedIn.
Leave a Reply