
How InsuranceDekho transformed insurance agent interactions using Amazon Bedrock and generative AI
This post is co-authored with Nishant Gupta from InsuranceDekho.
The insurance industry is complex and overwhelming, with numerous options that can be hard for consumers to understand. This complexity hinders customers from making informed decisions. As a result, customers face challenges in selecting the right insurance coverage, while insurance aggregators and agents struggle to provide clear and accurate information.
InsuranceDekho is a leading InsurTech service that offers a wide range of insurance products from over 49 insurance companies in India. The service operates through a vast network of 150,000 point of sale person (POSP) agents and direct-to-customer channels. InsuranceDekho uses cutting-edge technology to simplify the insurance purchase process for all users. The company’s mission is to make insurance transparent, accessible, and hassle-free for all customers through tech-driven solutions.
In this post, we explain how InsuranceDekho harnessed the power of generative AI using Amazon Bedrock and Anthropic’s Claude to provide responses to customer queries on policy coverages, exclusions, and more. This let our customer care agents and POSPs confidently help our customers understand the policies without reaching out to insurance subject matter experts (SMEs) or memorizing complex plans while providing sales and after-sales services. The use of this solution has improved sales, cross-selling, and overall customer service experience.
“Amazon Bedrock provided the flexibility to explore various leading LLM models using a single API, reducing the undifferentiated heavy lifting associated with hosting third-party models. Leveraging this, InsuranceDekho developed the industry’s first Health Pro Genie with the most efficient engine. It facilitates the insurance agents to choose the right plan for the end customer from the pool of over 125 health plans from 21 different health insurers available on the InsuranceDekho platform.”
– Ish Babbar, Co-Founder and CTO, InsuranceDekho
The challenge
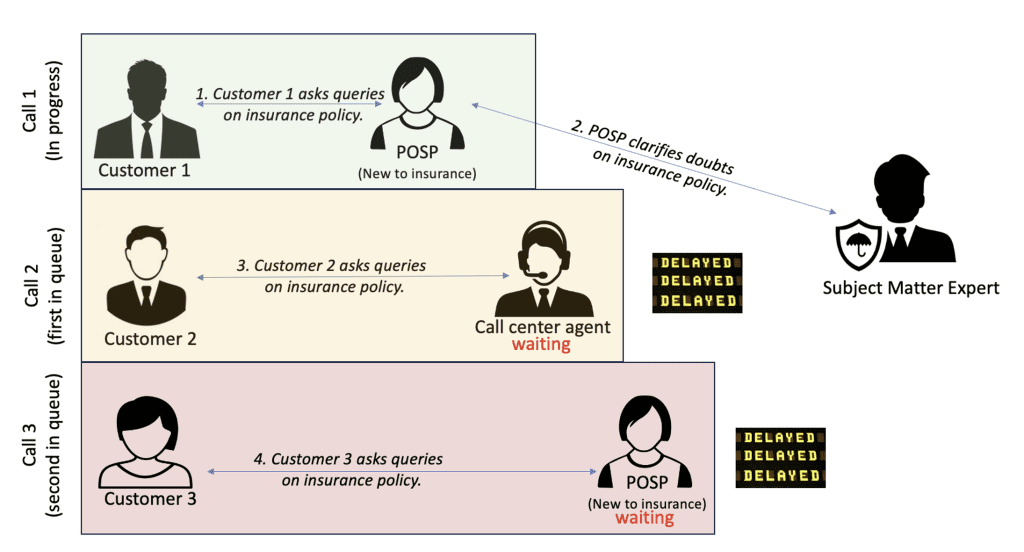
InsuranceDekho faced a significant challenge in responding to customer queries on insurance products in a timely manner. For a given lead, the insurance advisors, particularly those who are new to insurance, would often reach out to SMEs to inquire about policy or product-specific queries. The added step of SME consultation resulted in a process slowdown, requiring advisors to await expert input before responding to customers, introducing delays of a few minutes. Additionally, although SMEs can provide valuable guidance and expertise, their involvement introduces additional costs.
This delay not only affects the customer’s experience but also results in lost prospects because potential customers may decide not to purchase and explore competing services if they get better clarity on those products. The current process was inefficient, and InsuranceDekho needed a solution to empower its agents to respond to customer queries confidently and efficiently, without requiring excessive memorization.
The following figure depicts a common scenario where an SME receives multiple calls from insurance advisors, resulting in delays for the customers. Because SMEs can handle one call at a time, the advisors are left waiting for a response. This further prolongs the time it takes for customers to get clarity on the insurance product and decide on which product they want to purchase.
Solution overview
To overcome the limitations of relying on SMEs, a generative AI-based chat assistant was developed to autonomously resolve agent queries with accuracy. One of the key considerations while designing the chat assistant was to avoid responses from the default large language model (LLM) trained on generic data and only use the insurance policy documents. To generate such high-quality responses, we decided to go with the Retrieval Augmented Generation (RAG) approach using Amazon Bedrock and Anthropic’s Claude Haiku.
Amazon Bedrock
We conducted a thorough evaluation of several generative AI model providers and selected Amazon Bedrock as our primary provider for our foundation model (FM) needs. The key reasons that influenced this decision were:
- Managed service – Amazon Bedrock is a fully serverless offering that offers a choice of industry leading FMs without provisioning infrastructure, procuring GPUs around the clock, or configuring ML frameworks. As a result, it significantly reduces development, deployment overheads, and total cost of ownership, while enhancing efficiency and accelerating innovation in disruptive technologies like generative AI.
- Continuous model enhancements – Amazon Bedrock provides access to a vast and continuously expanding set of FMs through a single API. The continuous additions and updates to its model portfolio facilitate access to the latest advancements and improvements in AI technology, enabling us to evaluate upcoming LLMs and optimize output quality, latency, and cost by selecting the most suitable LLM for each specific task or application. We experienced this flexibility firsthand when we seamlessly transitioned from Anthropic’s Claude Instant to Anthropic’s Claude Haiku with the advent of Anthropic’s Claude 3, without requiring code changes.
- Performance – Amazon Bedrock provides options to achieve high-performance, low-latency, and scalable inference capabilities through on-demand and provisioned throughput options depending on the requirements.
- Secure model access – Secure, private model access using AWS PrivateLink gives controlled data transfer for inference without traversing the public internet, maintaining data privacy and helping to adhere to compliance requirements.
Retrieval Augmented Generation
RAG is a process in which LLMs access external documents or knowledge bases, promoting accurate and relevant responses. By referencing authoritative sources beyond their training data, RAG helps LLMs generate high-quality responses and overcome common pitfalls such as outdated or misleading information. RAG can be applied to various applications, including improving customer service, enhancing research capabilities, and streamlining business processes.
Solution building blocks
To begin designing the solution, we identified the key components needed, including the generative AI service, LLMs, vector databases, and caching engines. In this section, we delve into the key building blocks used in the solution, highlighting their importance in achieving optimal accuracy, cost-effectiveness, and performance:
- LLMs – After a thorough evaluation of various LLMs and benchmarking, we chose Anthropic’s Claude Haiku for its exceptional performance. The benchmarking results demonstrated unparalleled speed and affordability in its category. Additionally, it delivered rapid and accurate responses while handling straightforward queries or complex requests, making it an ideal choice for our use case.
- Embedding model – An embedding model is a type of machine learning (ML) model that maps discrete objects, such as words, phrases, or entities, into dense vector representations in a continuous embedding space. These vector representations, called embeddings, capture the semantic and syntactic relationships between the objects, allowing the model to reason about their similarities and differences. For our use case, we used a third-party embedding model.
- Vector database – For the purpose of vector database, we chose Amazon OpenSearch Service because of its scalability, high-performance search capabilities, and cost-effectiveness. Additionally, the OpenSearch Service flexible data model and integration with other features make it an ideal choice for our use case.
- Caching – To enhance the performance, efficiency, and cost-effectiveness of our chat assistant, we used Redis on Amazon ElastiCache to cache frequently accessed responses. This approach enables the chat assistant to rapidly retrieve cached responses, minimizing latency and computational load and resulting in a significantly improved user experience and reduced cost.
Implementation details
The following diagram illustrates the workflow of the current solution. Overall, the workflow can be divided into two workflows: the ingestion workflow and the response generation workflow.
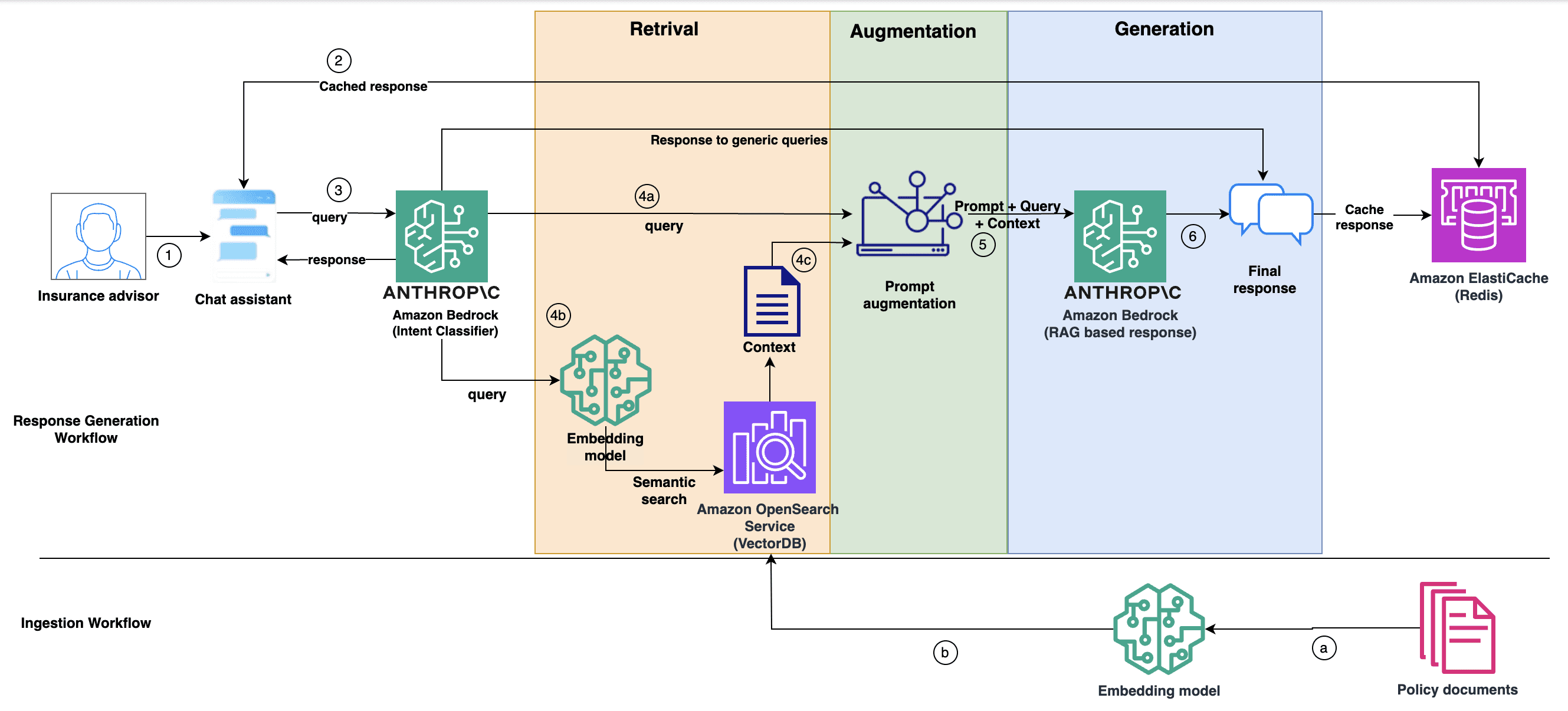
Ingestion workflow
The ingestion workflow serves as the foundation that fuels the entire response generation workflow by keeping the knowledge base up to date with the latest information. This process is crucial for making sure that the system can provide accurate and relevant responses based on the most recent insurance policy documents. The ingestion workflow involves three key components: policy documents, embedding model, and OpenSearch Service as a vector database.
- The policy documents contain the insurance policy information that needs to be ingested into the knowledge base.
- These documents are processed by the embedding model, which converts the textual content into high-dimensional vector representations, capturing the semantic meaning of the text. After the embedding model generates the vector representations of the policy documents, these embeddings are stored in OpenSearch Service. This ingestion workflow enables the chat assistant to provide responses based on the latest policy information available.
Response generation workflow
The response generation workflow is the core of our chat assistant solution. Insurance advisors use it to provide comprehensive responses to customers’ queries regarding policy coverage, exclusions, and other related topics.
- To initiate this workflow, our chatbot serves as the entry point, facilitating seamless interaction between the insurance advisors and the underlying response generation system.
- This solution incorporates a caching mechanism that uses semantic search to check if a query has been recently processed and answered. If a match is found in the cache (Redis), the chat assistant retrieves and returns the corresponding response, bypassing the full response generation workflow for redundant queries, thereby enhancing system performance.
- If no match is found in the cache, the query goes to the intent classifier powered by Anthropic’s Claude Haiku. It analyzes the query to understand the user’s intent and classify it accordingly. This enables dynamic prompting and tailored processing based on the query type. For generic or common queries, the intent classifier can provide the final response independently, bypassing the full RAG workflow, thereby optimizing efficiency and response times.
- For queries requiring the full RAG workflow, the intent classifier passes the query to the retrieval step, where a semantic search is performed on a vector database containing insurance policy documents to find the most relevant information, that is, the context based on the query.
- After the retrieval step, the retrieved context is integrated with the query and prompt, and this augmented information is fed into the generation process. This augmentation is the core component that enables the enhancement of the generation.
- In the final generation step, the actual response to the query is produced based on the external knowledge base of policy documents.
Results
The implementation of the generative AI-powered RAG chat assistant solution has yielded impressive results for InsuranceDekho. By using this solution, insurance advisors can now confidently and efficiently address customer queries autonomously, without the constant need for SME involvement. Additionally, the implementation of this solution has resulted in a significant reduction in response time to address customer queries. InsuranceDekho has witnessed a remarkable 80% decrease in the response time of the customer queries to understand the plan features, inclusions, and exclusions.
InsuranceDekho’s adoption of this generative AI-powered solution has streamlined the customer service process, making sure that customers receive precise and trustworthy responses to their inquiries in a timely manner.
Conclusion
In this post, we discussed how InsuranceDekho harnessed the power of generative AI to equip its insurance advisors with the tools to efficiently respond to customer queries regarding various insurance policies. By implementing a RAG-based chat assistant using Amazon Bedrock and OpenSearch Service, InsuranceDekho empowered its insurance advisors to deliver exceptional service. This solution minimized the reliance on SMEs and significantly reduced response times so advisors could address customer inquiries promptly and accurately.
About the Authors
 Vishal Gupta is a Senior Solutions Architect at AWS India, based in Delhi. In his current role at AWS, he works with digital native business customers and enables them to design, architect, and innovate highly scalable, resilient, and cost-effective cloud architectures. An avid blogger and speaker, Vishal loves to share his knowledge with the tech community. Outside of work, he enjoys traveling to new destinations and spending time with his family.
Vishal Gupta is a Senior Solutions Architect at AWS India, based in Delhi. In his current role at AWS, he works with digital native business customers and enables them to design, architect, and innovate highly scalable, resilient, and cost-effective cloud architectures. An avid blogger and speaker, Vishal loves to share his knowledge with the tech community. Outside of work, he enjoys traveling to new destinations and spending time with his family.
 Nishant Gupta is working as Vice President, Engineering at InsuranceDekho with 14 years of experience. He is passionate about building highly scalable, reliable, and cost-optimized solutions that can handle massive amounts of data efficiently.
Nishant Gupta is working as Vice President, Engineering at InsuranceDekho with 14 years of experience. He is passionate about building highly scalable, reliable, and cost-optimized solutions that can handle massive amounts of data efficiently.
Leave a Reply