
Deploy RAG applications on Amazon SageMaker JumpStart using FAISS
Generative AI has empowered customers with their own information in unprecedented ways, reshaping interactions across various industries by enabling intuitive and personalized experiences. This transformation is significantly enhanced by Retrieval Augmented Generation (RAG), which is a generative AI pattern where the large language model (LLM) being used references a knowledge corpus outside of its training data to generate a response. RAG has become a popular choice to improve performance of generative AI applications by taking advantage of additional information in the knowledge corpus to augment an LLM. Customers often prefer RAG for optimizing generative AI output over other techniques like fine-tuning due to cost benefits and quicker iteration.
In this post, we show how to build a RAG application on Amazon SageMaker JumpStart using Facebook AI Similarity Search (FAISS).
RAG applications on AWS
RAG models have proven useful for grounding language generation in external knowledge sources. By retrieving relevant information from a knowledge base or document collection, RAG models can produce responses that are more factual, coherent, and relevant to the user’s query. This can be particularly valuable in applications like question answering, dialogue systems, and content generation, where incorporating external knowledge is crucial for providing accurate and informative outputs.
Additionally, RAG has shown promise for improving understanding of internal company documents and reports. By retrieving relevant context from a corporate knowledge base, RAG models can assist with tasks like summarization, information extraction, and question answering on complex, domain-specific documents. This can help employees quickly find important information and insights buried within large volumes of internal materials.
A RAG workflow typically has four components: the input prompt, document retrieval, contextual generation, and output. A workflow begins with a user providing an input prompt, which is searched in a large knowledge corpus, and the most relevant documents are returned. These returned documents along with the original query are then fed into the LLM, which uses the additional conditional context to produce a more accurate output to users. RAG has become a popular technique to optimize generative AI applications because it uses external data that can be frequently modified to dynamically retrieve user output without the need retrain a model, which is both costly and compute intensive.
The next component in this pattern that we have chosen is SageMaker JumpStart. It provides significant advantages for building and deploying generative AI applications, including access to a wide range of pre-trained models with prepackaged artifacts, ease of use through a user-friendly interface, and scalability with seamless integration to the broader AWS ecosystem. By using pre-trained models and optimized hardware, SageMaker JumpStart allows you to quickly deploy both LLMs and embeddings models without spending too much time on configurations for scalability.
Solution overview
To implement our RAG workflow on SageMaker JumpStart, we use a popular open source Python library known as LangChain. Using LangChain, the RAG components are simplified into independent blocks that you can bring together using a chain object that will encapsulate the entire workflow. Let’s review these different components and how we bring them together:
- LLM (inference) – We need an LLM that will do the actual inference and answer our end-user’s initial prompt. For our use case, we use Meta Llama 3 for this component. LangChain comes with a default wrapper class for SageMaker endpoints that allows you to simply pass in the endpoint name to define an LLM object in the library.
- Embeddings model – We need an embeddings model to convert our document corpus into textual embeddings. This is necessary for when we are doing a similarity search on the input text to see what documents share similarities and possess the knowledge to help augment our response. For this example, we use the BGE Hugging Face embeddings model available through SageMaker JumpStart.
- Vector store and retriever – To house the different embeddings we have generated, we use a vector store. In this case, we use FAISS, which allows for similarity search as well. Within our chain object, we define the vector store as the retriever. You can tune this depending on how many documents you want to retrieve. Other vector store options include Amazon OpenSearch Service as you scale your experiments.
The following architecture diagram illustrates how you can use a vector index such as FAISS as a knowledge base and embeddings store.
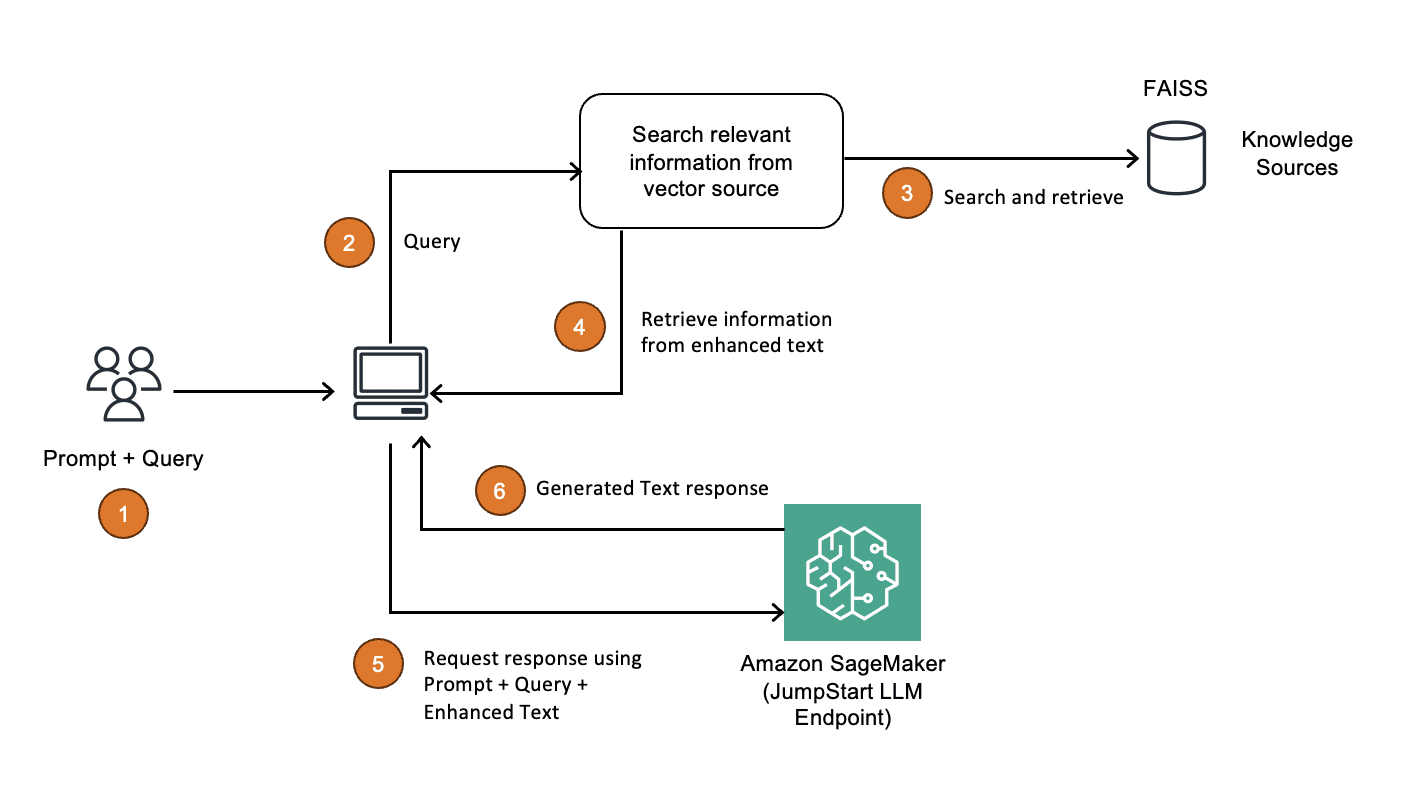
Standalone vector indexes like FAISS can significantly improve the search and retrieval of vector embeddings, but they lack capabilities that exist in any database. The following is an overview of the primary benefits to using a vector index for RAG workflows:
- Efficiency and speed – Vector indexes are highly optimized for fast, memory-efficient similarity search. Because vector databases are built on top of vector indexes, there are additional features that typically contribute additional latency. To build a highly efficient and low-latency RAG workflow, you can use a vector index (such as FAISS) deployed on a single machine with GPU acceleration.
- Simplified deployment and maintenance – Because vector indexes don’t require the effort of spinning up and maintaining a database instance, they’re a great option to quickly deploy a RAG workflow if continuous updates, high concurrency, or distributed storage aren’t a requirement.
- Control and customization – Vector indexes offer granular control over parameters, the index type, and performance trade-offs, letting you optimize for exact or approximate searches based on the RAG use case.
- Memory efficiency – You can tune a vector index to minimize memory usage, especially when using data compression techniques such as quantization. This is advantageous in scenarios where memory is limited and high scalability is required so that more data can be stored in memory on a single machine.
In short, a vector index like FAISS is advantageous when trying to maximize speed, control, and efficiency with minimal infrastructure components and stable data.
In the following sections, we walk through the following notebook, which implements FAISS as the vector store in the RAG solution. In this notebook, we use several years of Amazon’s Letter to Shareholders as a text corpus and perform Q&A on the letters. We use this notebook to demonstrate advanced RAG techniques with Meta Llama 3 8B on SageMaker JumpStart using the FAISS embedding store.
We explore the code using the simple LangChain vector store wrapper, RetrievalQA and ParentDocumentRetriever. RetreivalQA is more advanced than a LangChain vector store wrapper and offers more customizations. ParentDocumentRetriever helps with advanced RAG options like invocation of parent documents for response generation, which enriches the LLM’s outputs with a layered and thorough context. We will see how the responses progressively get better as we move from simple to advanced RAG techniques.
Prerequisites
To run this notebook, you need access to an ml.t3.medium instance.
To deploy the endpoints for Meta Llama 3 8B model inference, you need the following:
- At least one ml.g5.12xlarge instance for Meta Llama 3 endpoint usage
- At least one ml.g5.2xlarge instance for embedding endpoint usage
Additionally, you may need to request a Service Quota increase.
Set up the notebook
Complete the following steps to create a SageMaker notebook instance (you can also use Amazon SageMaker Studio with JupyterLab):
- On the SageMaker console, choose Notebooks in the navigation pane.
- Choose Create notebook instance.
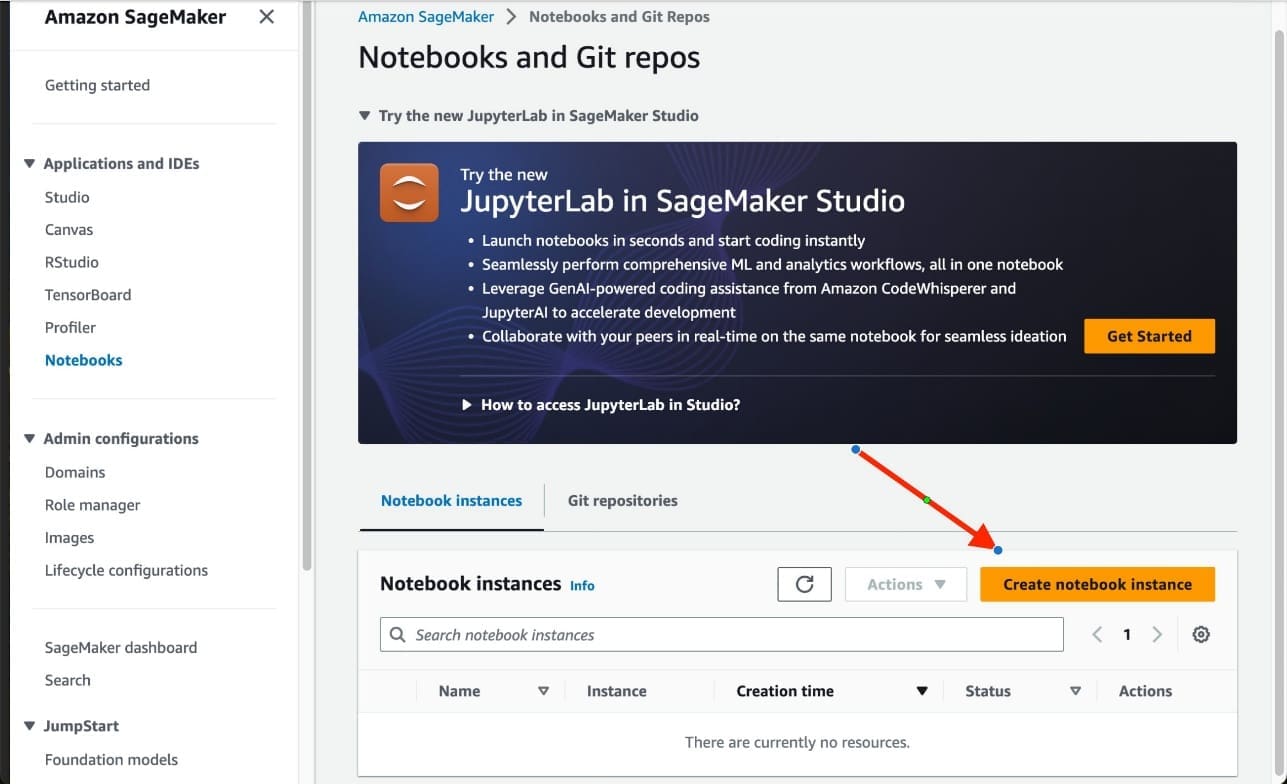
- For Notebook instance type, choose t3.medium.
- Under Additional configuration, for Volume size in GB, enter 50 GB.
This configuration might need to change depending on the RAG solution you are working with and the amount of data you will have on the file system itself.
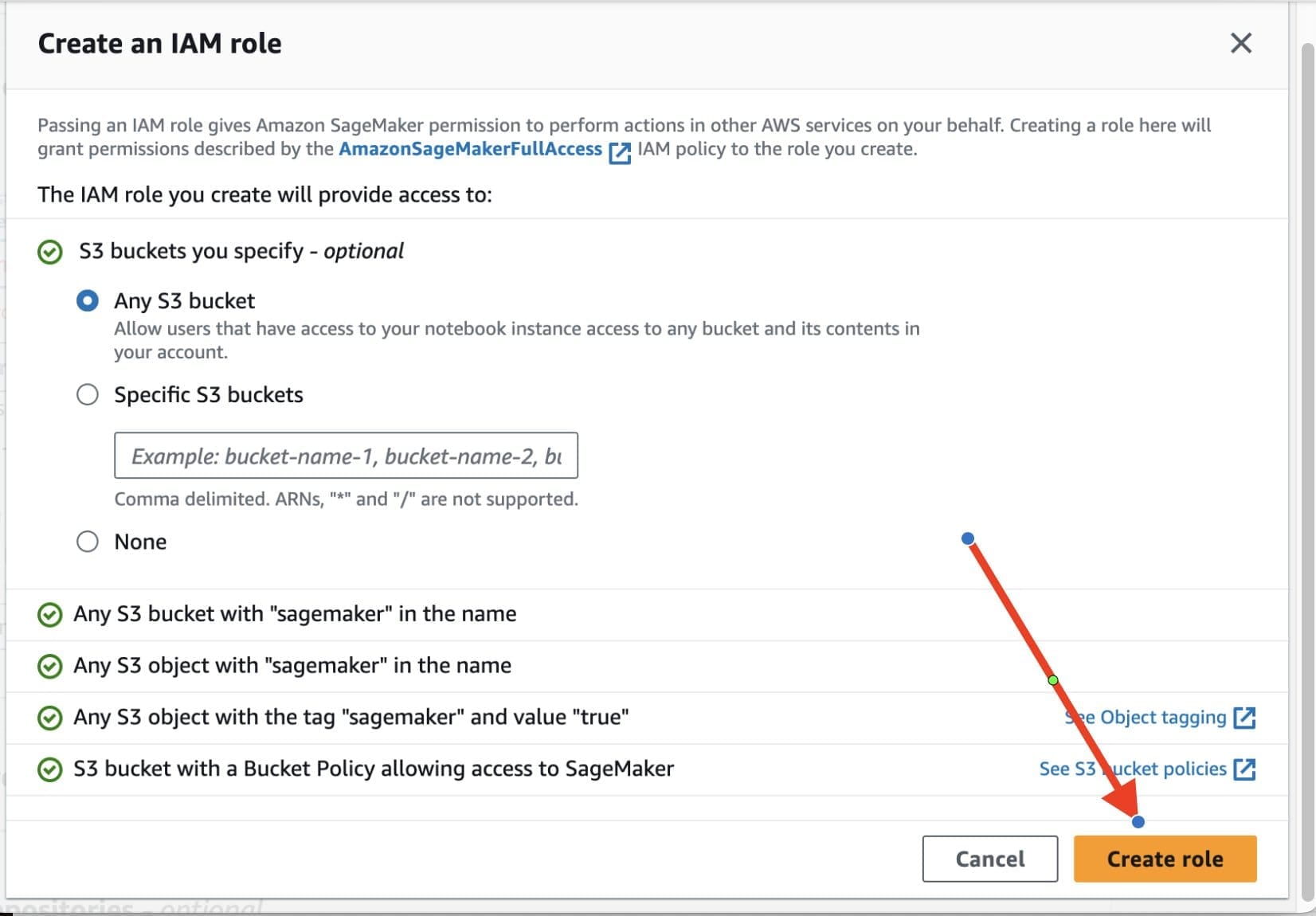
- For IAM role, choose Create a new role.
- Create an AWS Identity and Access Management (IAM) role with SageMaker full access and any other service-related policies that are necessary for your operations.
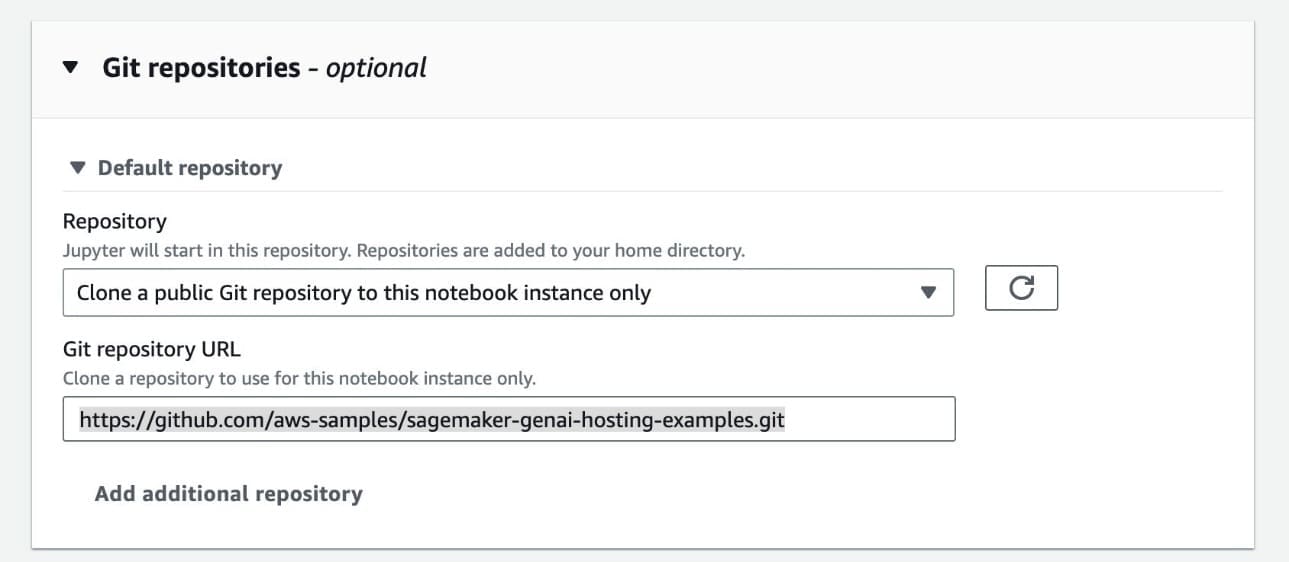
- Expand the Git repositories section and for Git repository URL, enter
https://github.com/aws-samples/sagemaker-genai-hosting-examples.git.
- Accept defaults for the rest of the configurations and choose Create notebook instance.
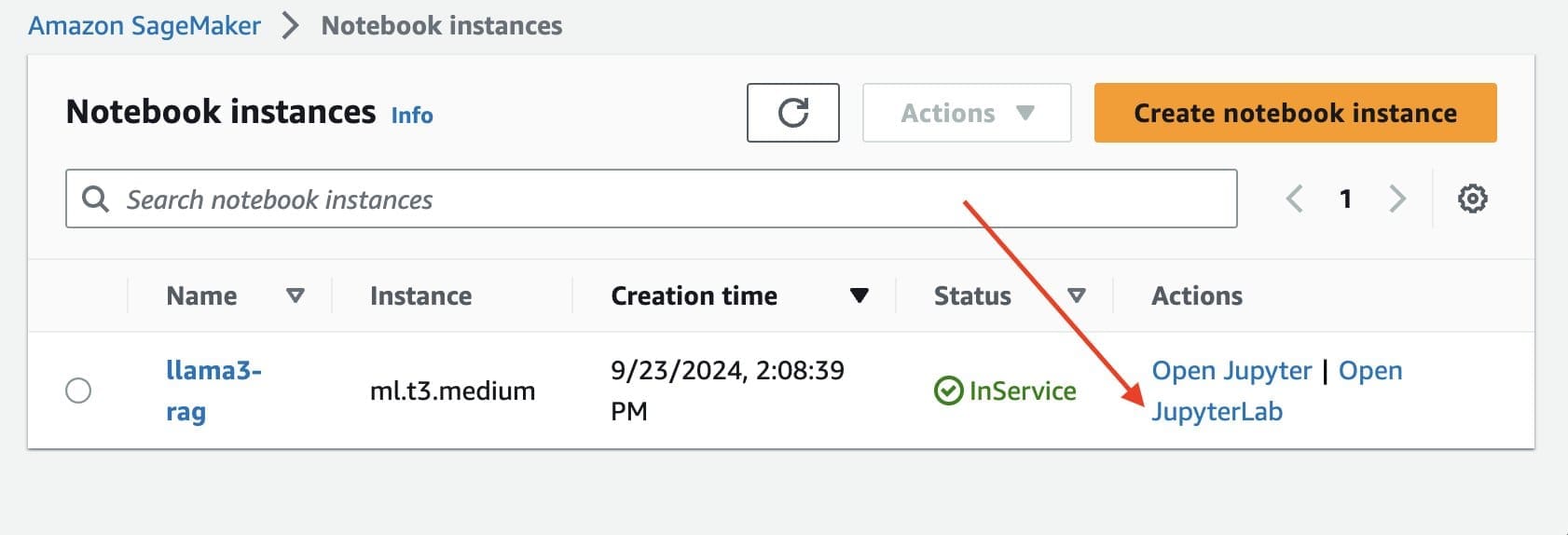
- Wait for the notebook to be InService and then choose the Open JupyterLab link to launch JupyterLab.
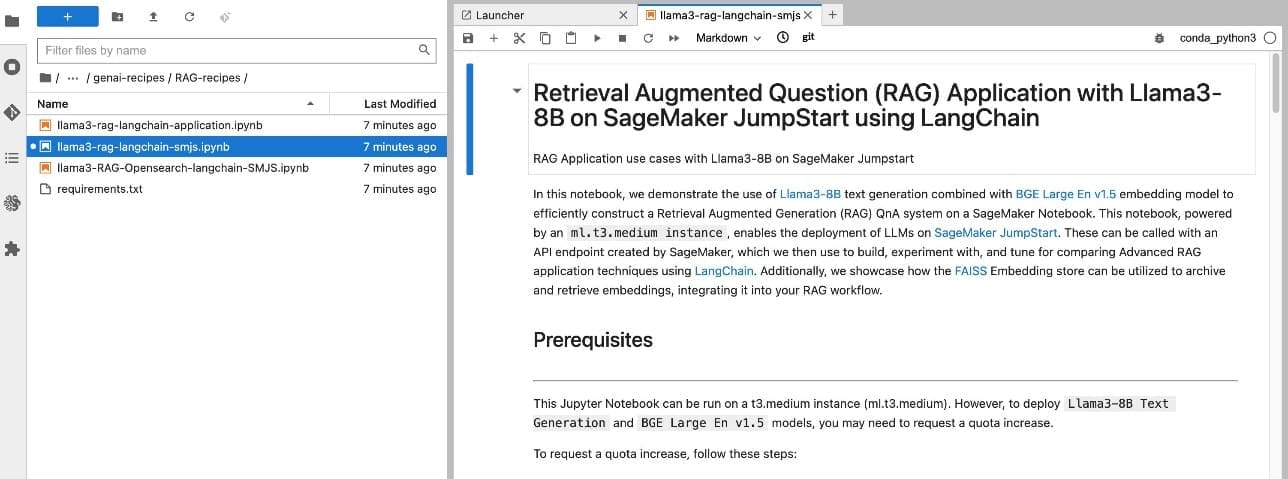
- Open
genai-recipes/RAG-recipes/llama3-rag-langchain-smjs.ipynbto work through the notebook.
Deploy the model
Before you start building the end-to-end RAG workflow, it’s necessary to deploy the LLM and embeddings model of your choice. SageMaker JumpStart simplifies this process because the model artifacts, data, and container specifications are all pre-packaged for optimal inference. These are then exposed using SageMaker Python SDK high-level API calls, which let you specify the model ID for deployment to a SageMaker real-time endpoint:
LangChain comes with built-in support for SageMaker JumpStart and endpoint-based models, so you can encapsulate the endpoints with these constructs so they can later be fit into the encompassing RAG chain:
After you have set up the models, you can focus on the data preparation and setup of the FAISS vector store.
Data preparation and vector store setup
For this RAG use case, we take public documents of Amazon’s Letter to Shareholders as the text corpus and document source that we will be working with:
LangChain comes with built-in processing for PDF documents, and you can use this to load the data from the text corpus. You can also tune or iterate over parameters such as chunk size depending on the documents that you’re working with for your use case.
You can then combine the documents and embeddings models and point towards FAISS as your vector store. LangChain has widespread support for different LLMs such as SageMaker JumpStart, and also has built-in API calls for integrating with FAISS, which we use in this case:
You can then make sure the vector store is performing as expected by sending a few sample queries and reviewing the output that is returned:
LangChain inference
Now that you have set up the vector store and models, you can encapsulate this into a singular chain object. In this case, we use a RetrievalQA Chain tailored for RAG applications provided by LangChain. With this chain, you can customize the document fetching process and control parameters such as number of documents to retrieve. We define a prompt template and pass in our retriever as well as these tertiary parameters:
You can then test some sample inference and trace the relevant source documents that helped answer the query:
Optionally, if you want to further augment or enhance your RAG applications for more advanced use cases with larger documents, you can also explore using options such as a parent document retriever chain. Depending on your use case, it’s crucial to identify the different RAG processes and architectures that can optimize your generative AI application.
Clean up
After you have built the RAG application with FAISS as a vector index, make sure to clean up the resources that were used. You can delete the LLM endpoint using the delete_endpoint Boto3 API call. In addition, make sure to stop your SageMaker notebook instance to not incur any further charges.
Conclusion
RAG can revolutionize customer interactions across industries by providing personalized and intuitive experiences. RAG’s four-component workflow—input prompt, document retrieval, contextual generation, and output—allows for dynamic, up-to-date responses without the need for costly model retraining. This approach has gained popularity due to its cost-effectiveness and ability to quickly iterate.
In this post, we saw how SageMaker JumpStart has simplified the process of building and deploying generative AI applications, offering pre-trained models, user-friendly interfaces, and seamless scalability within the AWS ecosystem. We also saw how using FAISS as a vector index can enable quick retrieval from a large corpus of information, while keeping costs and operational overhead low.
To learn more about RAG on SageMaker, see Retrieval Augmented Generation, or contact your AWS account team to discuss your use cases.
About the Authors
 Raghu Ramesha is an ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is an ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Ram Vegiraju is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on SageMaker. In his spare time, he loves traveling and writing.
 Vivek Gangasani is a Senior GenAI Specialist Solutions Architect at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
Vivek Gangasani is a Senior GenAI Specialist Solutions Architect at AWS. He helps emerging generative AI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of large language models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
 Harish Rao is a Senior Solutions Architect at AWS, specializing in large-scale distributed AI training and inference. He empowers customers to harness the power of AI to drive innovation and solve complex challenges. Outside of work, Harish embraces an active lifestyle, enjoying the tranquility of hiking, the intensity of racquetball, and the mental clarity of mindfulness practices.
Harish Rao is a Senior Solutions Architect at AWS, specializing in large-scale distributed AI training and inference. He empowers customers to harness the power of AI to drive innovation and solve complex challenges. Outside of work, Harish embraces an active lifestyle, enjoying the tranquility of hiking, the intensity of racquetball, and the mental clarity of mindfulness practices.
 Ankith Ede is a Solutions Architect at Amazon Web Services based in New York City. He specializes in helping customers build cutting-edge generative AI, machine learning, and data analytics-based solutions for AWS startups. He is passionate about helping customers build scalable and secure cloud-based solutions.
Ankith Ede is a Solutions Architect at Amazon Web Services based in New York City. He specializes in helping customers build cutting-edge generative AI, machine learning, and data analytics-based solutions for AWS startups. He is passionate about helping customers build scalable and secure cloud-based solutions.
 Sid Rampally is a Customer Solutions Manager at AWS, driving generative AI acceleration for life sciences customers. He writes about topics relevant to his customers, focusing on data engineering and machine learning. In his spare time, Sid enjoys walking his dog in Central Park and playing hockey.
Sid Rampally is a Customer Solutions Manager at AWS, driving generative AI acceleration for life sciences customers. He writes about topics relevant to his customers, focusing on data engineering and machine learning. In his spare time, Sid enjoys walking his dog in Central Park and playing hockey.
Leave a Reply