
Accelerating ML experimentation with enhanced security: AWS PrivateLink support for Amazon SageMaker with MLflow
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker, users want a seamless and secure way to experiment with and select the models that deliver the most value for their business. In the initial stages of an ML project, data scientists collaborate closely, sharing experimental results to address business challenges. However, keeping track of numerous experiments, their parameters, metrics, and results can be difficult, especially when working on complex projects simultaneously. MLflow, a popular open-source tool, helps data scientists organize, track, and analyze ML and generative AI experiments, making it easier to reproduce and compare results.
SageMaker is a comprehensive, fully managed ML service designed to provide data scientists and ML engineers with the tools they need to handle the entire ML workflow. Amazon SageMaker with MLflow is a capability in SageMaker that enables users to create, manage, analyze, and compare their ML experiments seamlessly. It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. See Fully managed MLFlow on Amazon SageMaker for more details.
Enhanced security: AWS VPC and AWS PrivateLink
When working with SageMaker, you can decide the level of internet access to provide to your users. For example, you can give users access permission to download popular packages and customize the development environment. However, this can also introduce potential risks of unauthorized access to your data. To mitigate these risks, you can further restrict which traffic can access the internet by launching your ML environment in an Amazon Virtual Private Cloud (Amazon VPC). With an Amazon VPC, you can control the network access and internet connectivity of your SageMaker environment, or even remove direct internet access to add another layer of security. See Connect to SageMaker through a VPC interface endpoint to understand the implications of running SageMaker within a VPC and the differences when using network isolation.
SageMaker with MLflow now supports AWS PrivateLink, which enables you to transfer critical data from your VPC to MLflow Tracking Servers through a VPC endpoint. This capability enhances the protection of sensitive information by making sure that data sent to the MLflow Tracking Servers is transferred within the AWS network, avoiding exposure to the public internet. This capability is available in all AWS Regions where SageMaker is currently available, excluding China Regions and GovCloud (US) Regions. To learn more, see Connect to an MLflow tracking server through an Interface VPC Endpoint.
In this blogpost, we demonstrate a use case to set up a SageMaker environment in a private VPC (without internet access), while using MLflow capabilities to accelerate ML experimentation.
Solution overview
You can find the reference code for this sample in GitHub. The high-level steps are as follows:
- Deploy infrastructure with the AWS Cloud Development Kit (AWS CDK) including:
- A SageMaker environment in a private VPC without internet access.
- AWS CodeArtifact, which provides a private PyPI repository so that SageMaker can use it to download necessary packages.
- VPC endpoints, which enable the SageMaker environment to connect to other AWS services (Amazon Simple Storage Service (Amazon S3), AWS CodeArtifact, Amazon Elastic Container Registry (Amazon ECR), Amazon CloudWatch, SageMaker Managed MLflow, and so on) through AWS PrivateLink without exposing the environment to the public internet.
- Run ML experimentation with MLflow using the @remote decorator from the open-source SageMaker Python SDK.
The overall solution architecture is shown in the following figure.
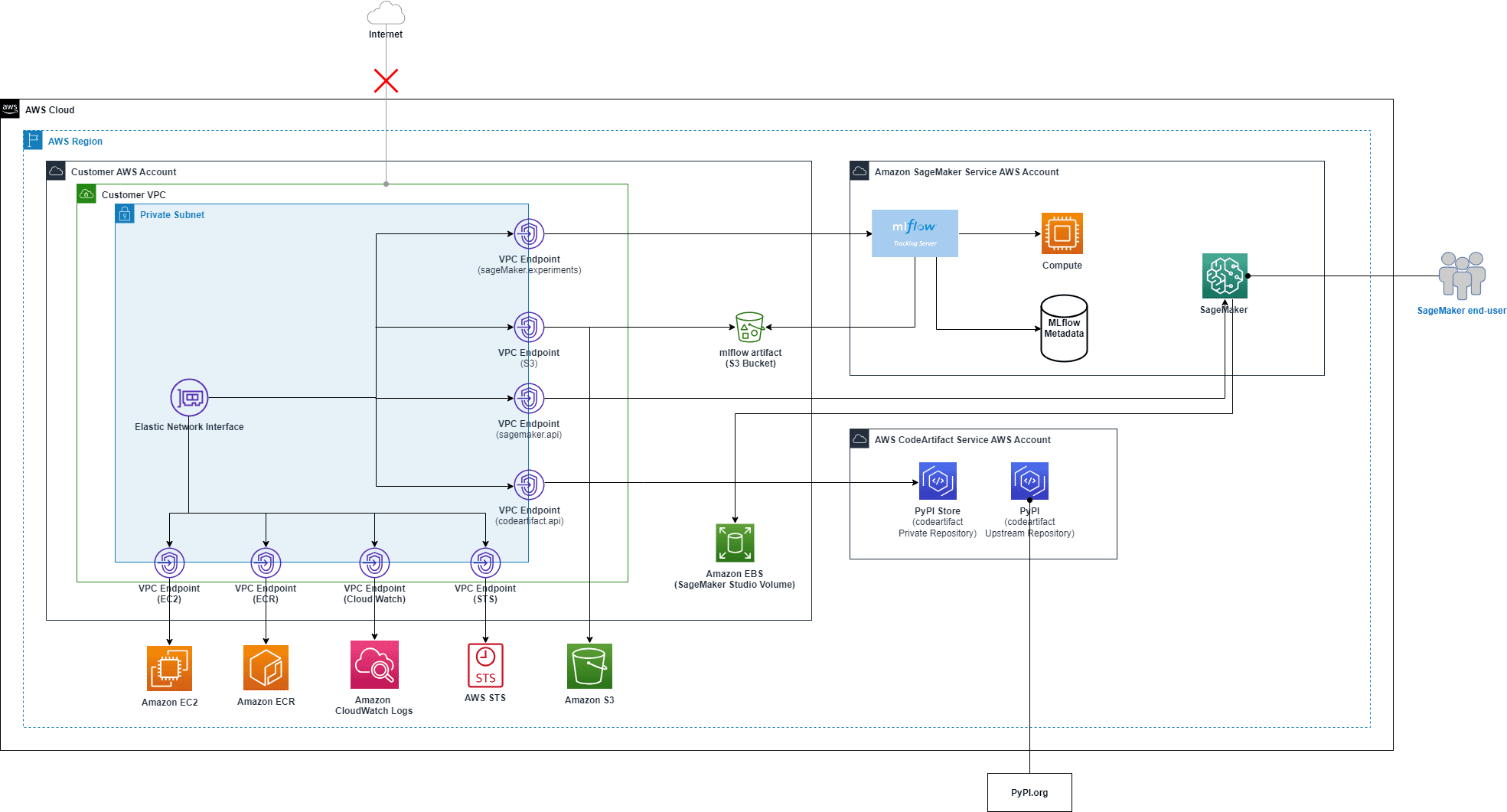
For your reference, this blog post demonstrates a solution to create a VPC with no internet connection using an AWS CloudFormation template.
Prerequisites
You need an AWS account with an AWS Identity and Access Management (IAM) role with permissions to manage resources created as part of the solution. For details, see Creating an AWS account.
Deploy infrastructure with AWS CDK
The first step is to create the infrastructure using this CDK stack. You can follow the deployment instructions from the README.
Let’s first have a closer look at the CDK stack itself.
It defines multiple VPC endpoints, including the MLflow endpoint as shown in the following sample:
vpc.add_interface_endpoint(
"mlflow-experiments",
service=ec2.InterfaceVpcEndpointAwsService.SAGEMAKER_EXPERIMENTS,
private_dns_enabled=True,
subnets=ec2.SubnetSelection(subnets=subnets),
security_groups=[studio_security_group]
)We also try to restrict the SageMaker execution IAM role so that you can use SageMaker MLflow only when you’re in the right VPC.
You can further restrict the VPC endpoint for MLflow by attaching a VPC endpoint policy.
Users outside the VPC can potentially connect to Sagemaker MLflow through the VPC endpoint to MLflow. You can add restrictions so that user access to SageMaker MLflow is only allowed from your VPC.
studio_execution_role.attach_inline_policy(
iam.Policy(self, "mlflow-policy",
statements=[
iam.PolicyStatement(
effect=iam.Effect.ALLOW,
actions=["sagemaker-mlflow:*"],
resources=["*"],
conditions={"StringEquals": {"aws:SourceVpc": vpc.vpc_id } }
)
]
)
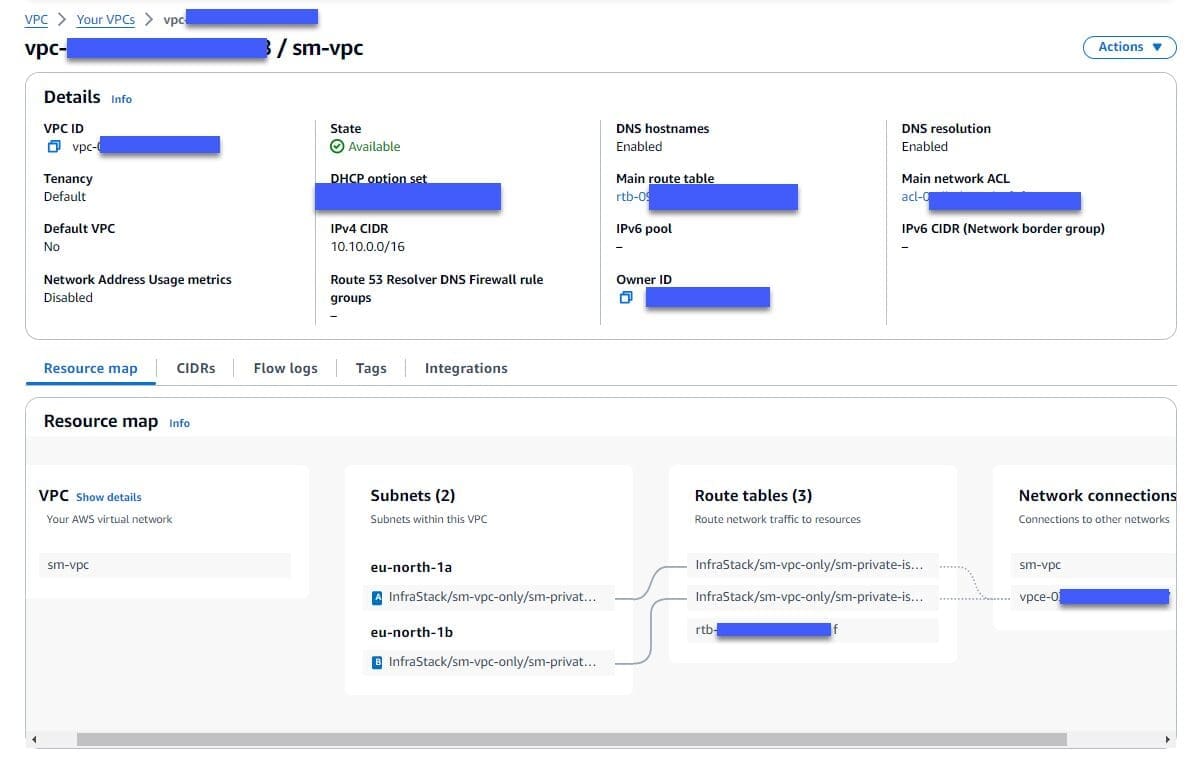
)After successful deployment, you should be able to see the new VPC in the AWS Management Console for Amazon VPC without internet access, as shown in the following screenshot.
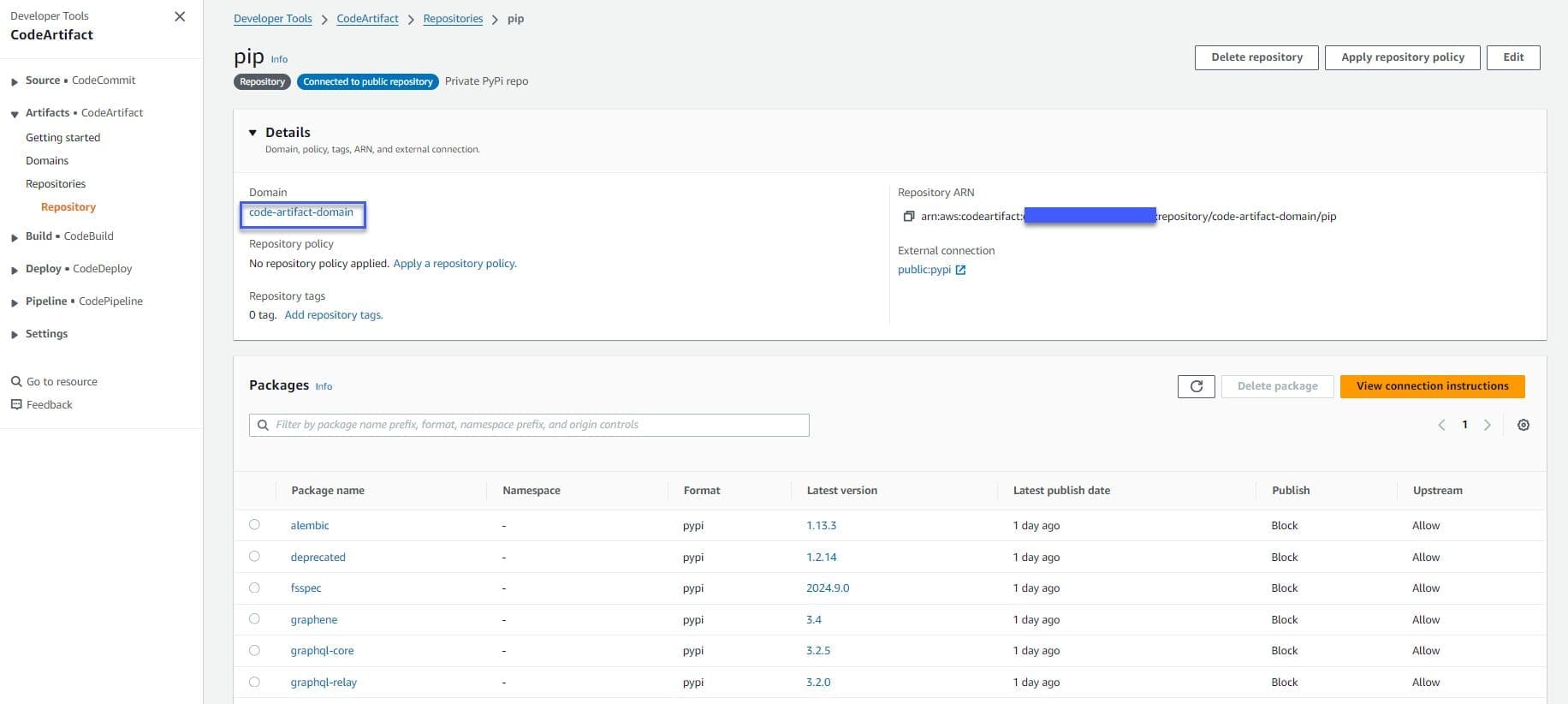
A CodeArtifact domain and a CodeArtifact repository with external connection to PyPI should also be created, as shown in the following figure, so that SageMaker can use it to download necessary packages without internet access. You can verify the creation of the domain and the repository by going to the CodeArtifact console. Choose “Repositories” under “Artifacts” from the navigation pane and you will see the repository “pip”.
ML experimentation with MLflow
Setup
After the CDK stack creation, a new SageMaker domain with a user profile should also be created. Launch Amazon SageMaker Studio and create a JupyterLab Space. In the JupyterLab Space, choose an instance type of ml.t3.medium, and select an image with SageMaker Distribution 2.1.0.
To check that the SageMaker environment has no internet connection, open the JupyterLab space and check the internet connection by running the curl command in a terminal.

SageMaker with MLflow now supports MLflow version 2.16.2 to accelerate generative AI and ML workflows from experimentation to production. An MLflow 2.16.2 tracking server is created along with the CDK stack.
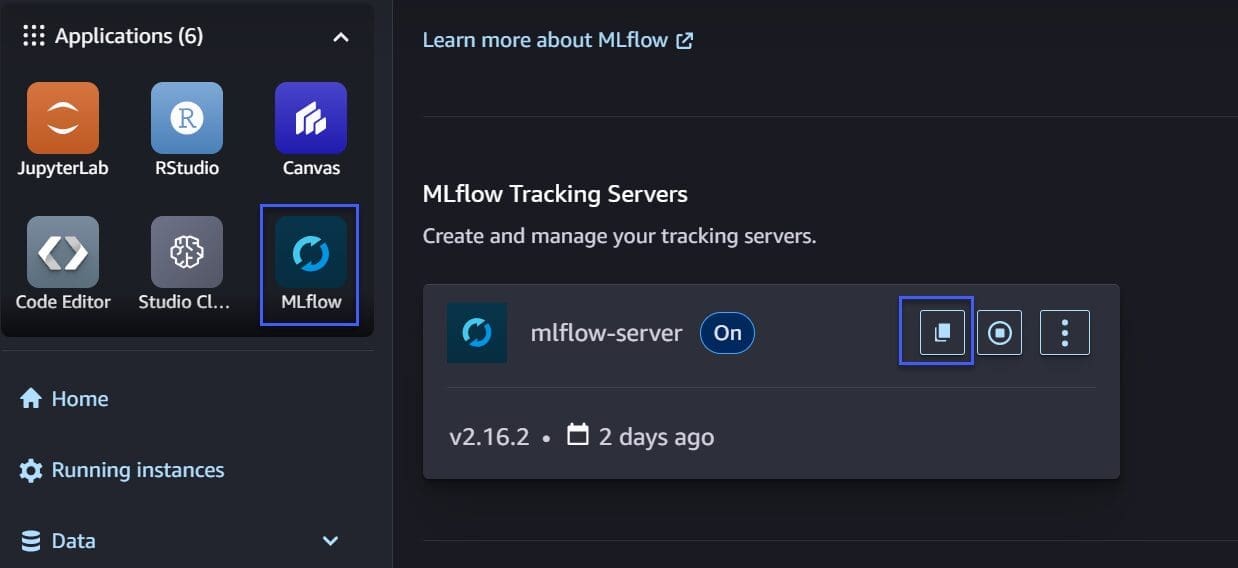
You can find the MLflow tracking server Amazon Resource Name (ARN) either from the CDK output or from the SageMaker Studio UI by clicking “MLFlow” icon, as shown in the following figure. You can click the “copy” button next to the “mlflow-server” to copy the MLflow tracking server ARN.
As an example dataset to train the model, download the reference dataset from the public UC Irvine ML repository to your local PC, and name it predictive_maintenance_raw_data_header.csv.
Upload the reference dataset from your local PC to your JupyterLab Space as shown in the following figure.
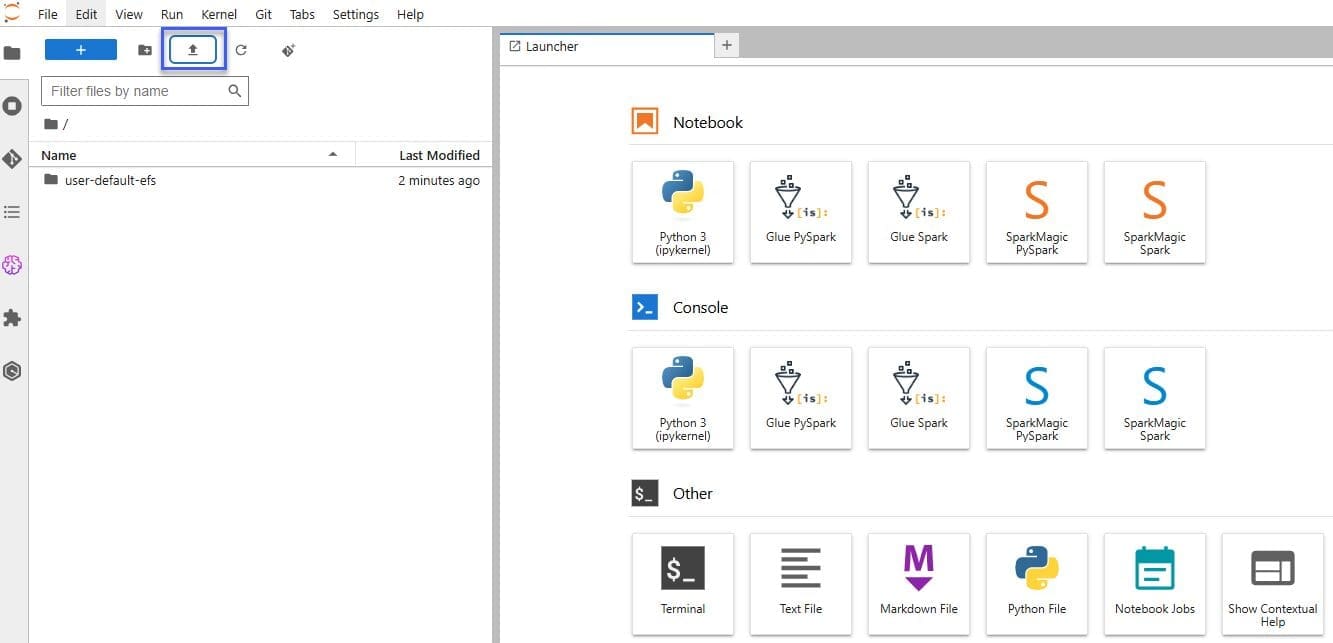
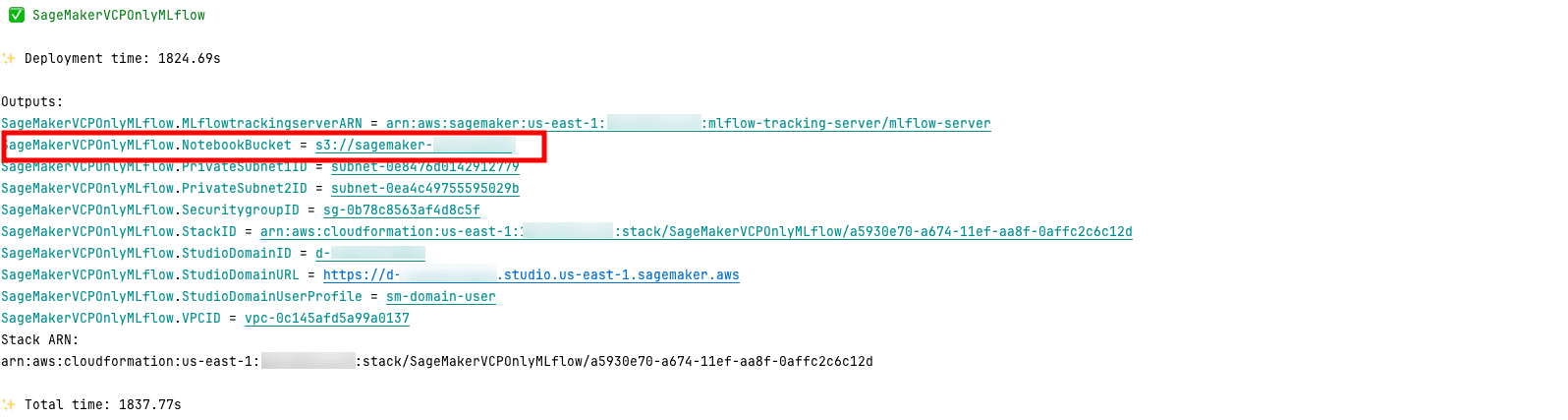
To test your private connectivity to the MLflow tracking server, you can download the sample notebook that has been uploaded automatically during the creation of the stack in a bucket within your AWS account. You can find the an S3 bucket name in the CDK output, as shown in the following figure.
From the JupyterLab app terminal, run the following command:
aws s3 cp --recursive ./ You can now open the private-mlflow.ipynb notebook.
In the first cell, fetch credentials for the CodeArtifact PyPI repository so that SageMaker can use pip from the private AWS CodeArtifact repository. The credentials will expire in 12 hours. Make sure to log on again when they expire.
%%bash
AWS_ACCOUNT=$(aws sts get-caller-identity --output text --query 'Account')
aws codeartifact login --tool pip --repository pip --domain code-artifact-domain --domain-owner ${AWS_ACCOUNT} --region ${AWS_DEFAULT_REGION}Experimentation
After setup, start the experimentation. The scenario is using the XGBoost algorithm to train a binary classification model. Both the data processing job and model training job use @remote decorator so that the jobs are running in the SageMaker-associated private subnets and security group from your private VPC.
In this case, the @remote decorator looks up the parameter values from the SageMaker configuration file (config.yaml). These parameters are used for data processing and training jobs. We define the SageMaker-associated private subnets and security group in the configuration file. For the full list of supported configurations for the @remote decorator, see Configuration file in the SageMaker Developer Guide.
Note that we specify in PreExecutionCommands the aws codeartifact login command to point SageMaker to the private CodeAritifact repository. This is needed to make sure that the dependencies can be installed at runtime. Alternatively, you can pass a reference to a container in your Amazon ECR through ImageUri, which contains all installed dependencies.
We specify the security group and subnets information in VpcConfig.
config_yaml = f"""
SchemaVersion: '1.0'
SageMaker:
PythonSDK:
Modules:
TelemetryOptOut: true
RemoteFunction:
# role arn is not required if in SageMaker Notebook instance or SageMaker Studio
# Uncomment the following line and replace with the right execution role if in a local IDE
# RoleArn:
# ImageUri:
S3RootUri: s3://{bucket_prefix}
InstanceType: ml.m5.xlarge
Dependencies: ./requirements.txt
IncludeLocalWorkDir: true
PreExecutionCommands:
- "aws codeartifact login --tool pip --repository pip --domain code-artifact-domain --domain-owner {account_id} --region {region}"
CustomFileFilter:
IgnoreNamePatterns:
- "data/*"
- "models/*"
- "*.ipynb"
- "__pycache__"
VpcConfig:
SecurityGroupIds:
- {security_group_id}
Subnets:
- {private_subnet_id_1}
- {private_subnet_id_2}
""" Here’s how you can setup an MLflow experiment similar to this.
from time import gmtime, strftime
# Mlflow (replace these values with your own, if needed)
project_prefix = project_prefix
tracking_server_arn = mlflow_arn
experiment_name = f"{project_prefix}-sm-private-experiment"
run_name=f"run-{strftime('%d-%H-%M-%S', gmtime())}"Data preprocessing
During the data processing, we use the @remote decorator to link parameters in config.yaml to your preprocess function.
Note that MLflow tracking starts from the mlflow.start_run() API.
The mlflow.autolog() API can automatically log information such as metrics, parameters, and artifacts.
You can use log_input() method to log a dataset to the MLflow artifact store.
@remote(keep_alive_period_in_seconds=3600, job_name_prefix=f"{project_prefix}-sm-private-preprocess")
def preprocess(df, df_source: str, experiment_name: str):
mlflow.set_tracking_uri(tracking_server_arn)
mlflow.set_experiment(experiment_name)
with mlflow.start_run(run_name=f"Preprocessing") as run:
mlflow.autolog()
columns = ['Type', 'Air temperature [K]', 'Process temperature [K]', 'Rotational speed [rpm]', 'Torque [Nm]', 'Tool wear [min]', 'Machine failure']
cat_columns = ['Type']
num_columns = ['Air temperature [K]', 'Process temperature [K]', 'Rotational speed [rpm]', 'Torque [Nm]', 'Tool wear [min]']
target_column = 'Machine failure'
df = df[columns]
mlflow.log_input(
mlflow.data.from_pandas(df, df_source, targets=target_column),
context="DataPreprocessing",
)
...
model_file_path="/opt/ml/model/sklearn_model.joblib"
os.makedirs(os.path.dirname(model_file_path), exist_ok=True)
joblib.dump(featurizer_model, model_file_path)
return X_train, y_train, X_val, y_val, X_test, y_test, featurizer_modelRun the preprocessing job, then go to the MLflow UI (shown in the following figure) to see the tracked preprocessing job with the input dataset.
X_train, y_train, X_val, y_val, X_test, y_test, featurizer_model = preprocess(df=df,
df_source=input_data_path,
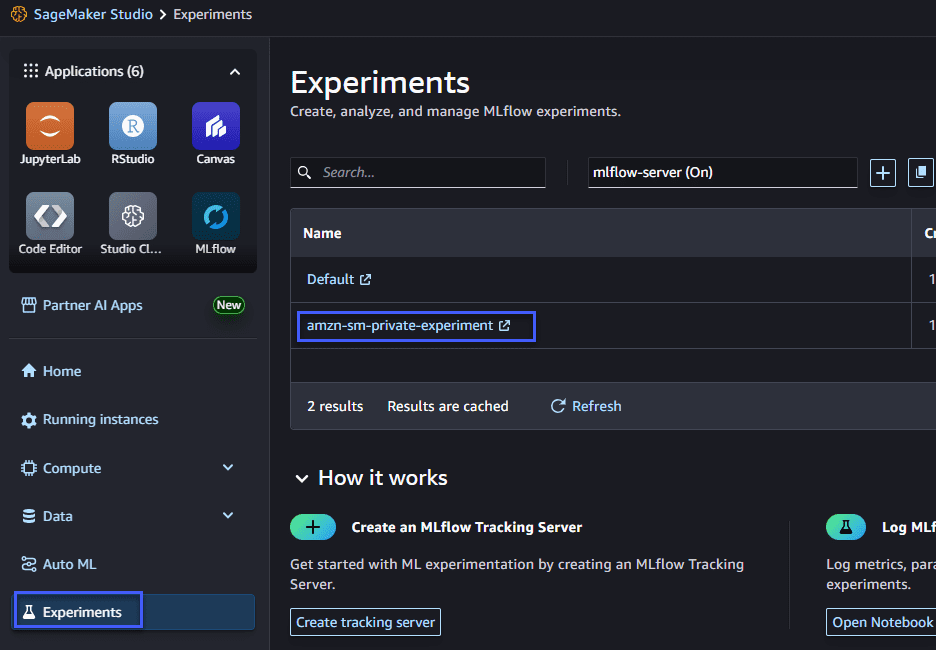
experiment_name=experiment_name)You can open an MLflow UI from SageMaker Studio as the following figure. Click “Experiments” from the navigation pane and select your experiment.
From the MLflow UI, you can see the processing job that just run.

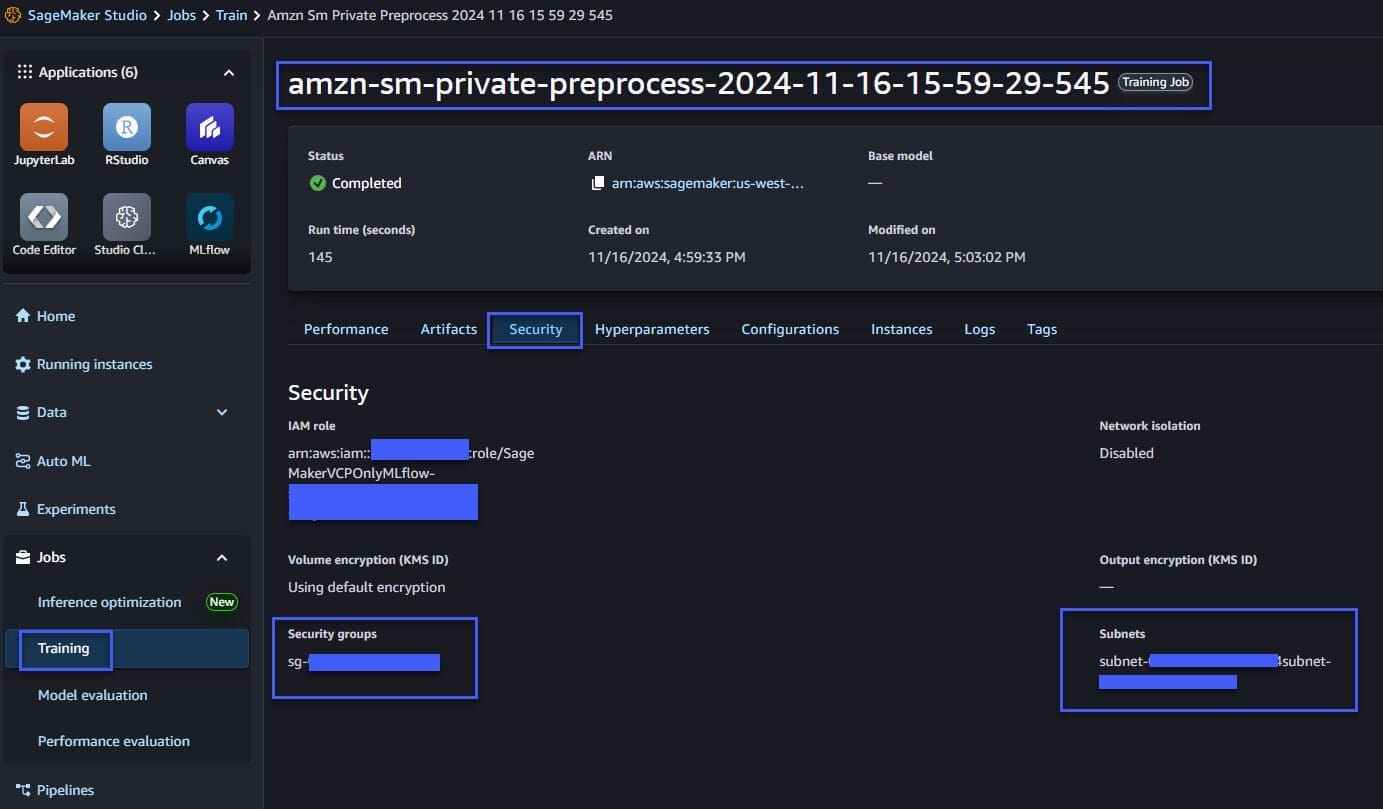
You can also see security details in the SageMaker Studio console in the corresponding training job as shown in the following figure.
Model training
Similar to the data processing job, you can also use @remote decorator with the training job.
Note that the log_metrics() method sends your defined metrics to the MLflow tracking server.
@remote(keep_alive_period_in_seconds=3600, job_name_prefix=f"{project_prefix}-sm-private-train")
def train(X_train, y_train, X_val, y_val,
eta=0.1,
max_depth=2,
gamma=0.0,
min_child_weight=1,
verbosity=0,
objective='binary:logistic',
eval_metric='auc',
num_boost_round=5):
mlflow.set_tracking_uri(tracking_server_arn)
mlflow.set_experiment(experiment_name)
with mlflow.start_run(run_name=f"Training") as run:
mlflow.autolog()
# Creating DMatrix(es)
dtrain = xgboost.DMatrix(X_train, label=y_train)
dval = xgboost.DMatrix(X_val, label=y_val)
watchlist = [(dtrain, "train"), (dval, "validation")]
print('')
print (f'===Starting training with max_depth {max_depth}===')
param_dist = {
"max_depth": max_depth,
"eta": eta,
"gamma": gamma,
"min_child_weight": min_child_weight,
"verbosity": verbosity,
"objective": objective,
"eval_metric": eval_metric
}
xgb = xgboost.train(
params=param_dist,
dtrain=dtrain,
evals=watchlist,
num_boost_round=num_boost_round)
predictions = xgb.predict(dval)
print ("Metrics for validation set")
print('')
print (pd.crosstab(index=y_val, columns=np.round(predictions),
rownames=['Actuals'], colnames=['Predictions'], margins=True))
rounded_predict = np.round(predictions)
val_accuracy = accuracy_score(y_val, rounded_predict)
val_precision = precision_score(y_val, rounded_predict)
val_recall = recall_score(y_val, rounded_predict)
# Log additional metrics, next to the default ones logged automatically
mlflow.log_metric("Accuracy Model A", val_accuracy * 100.0)
mlflow.log_metric("Precision Model A", val_precision)
mlflow.log_metric("Recall Model A", val_recall)
from sklearn.metrics import roc_auc_score
val_auc = roc_auc_score(y_val, predictions)
mlflow.log_metric("Validation AUC A", val_auc)
model_file_path="/opt/ml/model/xgboost_model.bin"
os.makedirs(os.path.dirname(model_file_path), exist_ok=True)
xgb.save_model(model_file_path)
return xgbDefine hyperparameters and run the training job.
eta=0.3
max_depth=10
booster = train(X_train, y_train, X_val, y_val,
eta=eta,
max_depth=max_depth)In the MLflow UI you can see the tracking metrics as shown in the figure below. Under “Experiments” tab, go to “Training” job of your experiment task. It is under “Overview” tab.
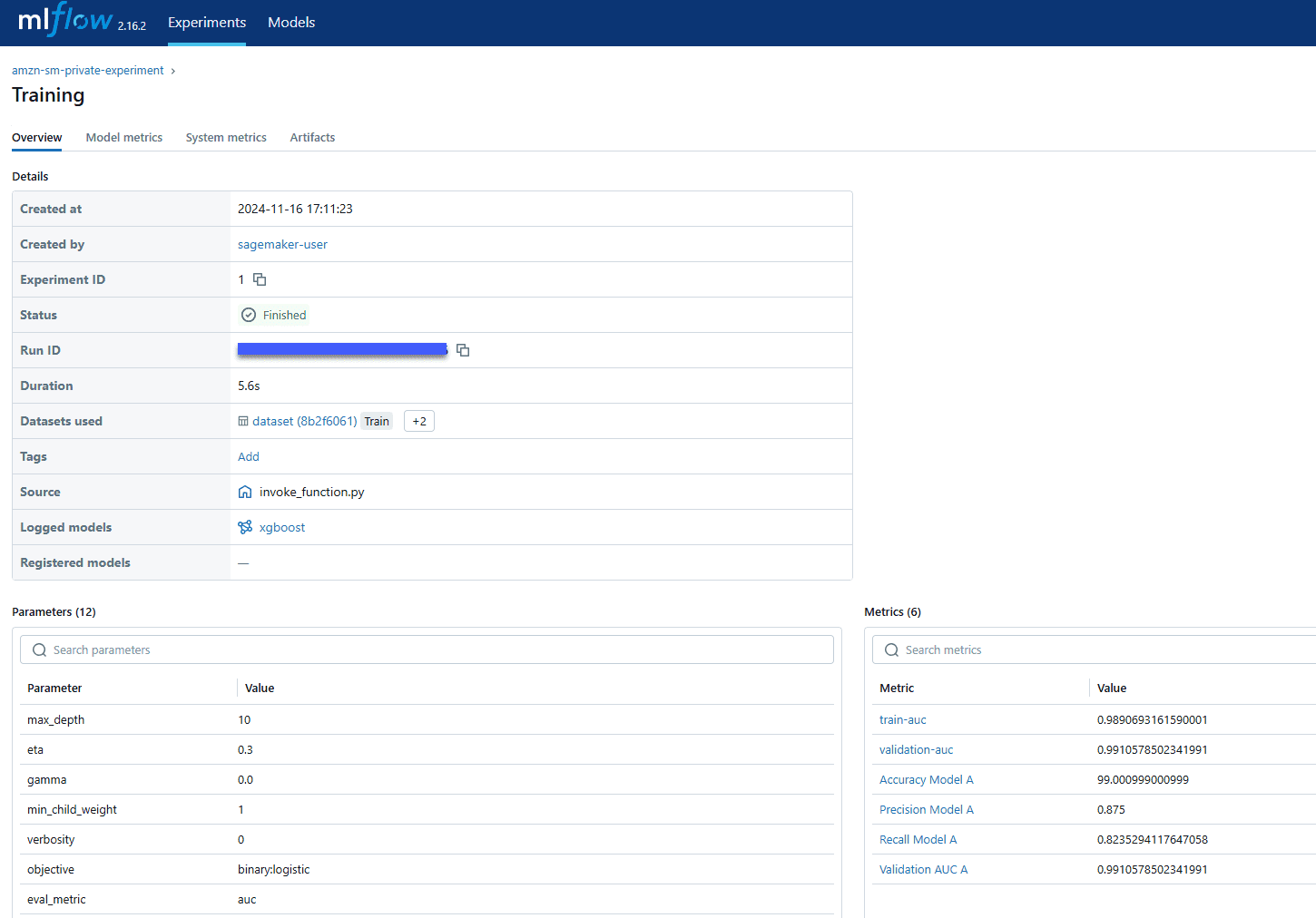
You can also view the metrics as graphs. Under “Model metrics” tab, you can see the model performance metrics that configured as part of the training job log.
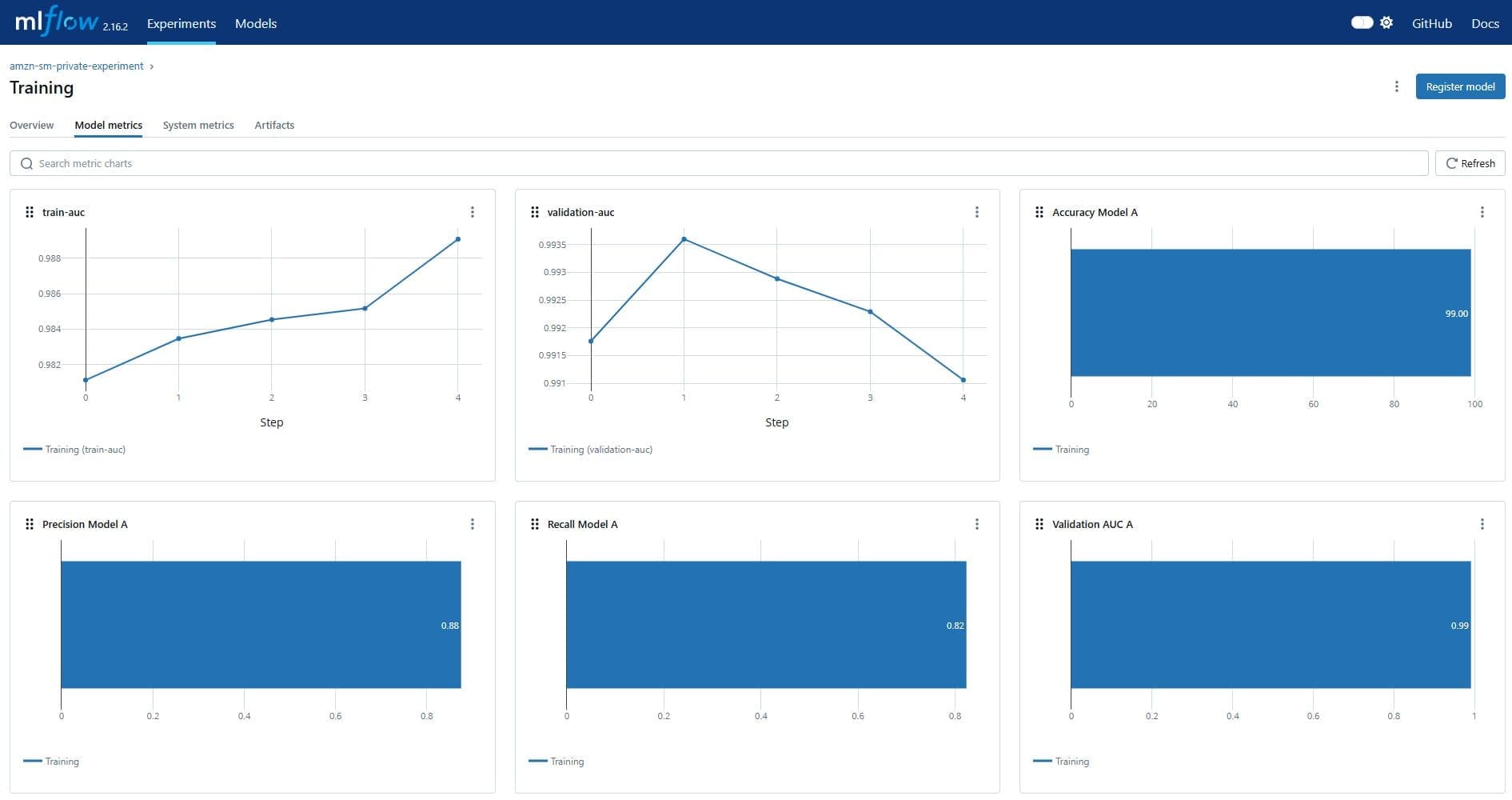
With MLflow, you can log your dataset information alongside other key metrics, such as hyperparameters and model evaluation. Find more details in the blogpost LLM experimentation with MLFlow.
Clean up
To clean up, first delete all spaces and applications created within the SageMaker Studio domain. Then destroy the infrastructure created by running the following code.
cdk destroyConclusion
SageMaker with MLflow allows ML practitioners to create, manage, analyze, and compare ML experiments on AWS. To enhance security, SageMaker with MLflow now supports AWS PrivateLink. All MLflow Tracking Server versions including 2.16.2 integrate seamlessly with this feature, enabling secure communication between your ML environments and AWS services without exposing data to the public internet.
For an extra layer of security, you can set up SageMaker Studio within your private VPC without Internet access and execute your ML experiments in this environment.
SageMaker with MLflow now supports MLflow 2.16.2. Setting up a fresh installation provides the best experience and full compatibility with the latest features.
About the Authors
 Xiaoyu Xing is a Solutions Architect at AWS. She is driven by a profound passion for Artificial Intelligence (AI) and Machine Learning (ML). She strives to bridge the gap between these cutting-edge technologies and a broader audience, empowering individuals from diverse backgrounds to learn and leverage AI and ML with ease. She is helping customers to adopt AI and ML solutions on AWS in a secure and responsible way.
Xiaoyu Xing is a Solutions Architect at AWS. She is driven by a profound passion for Artificial Intelligence (AI) and Machine Learning (ML). She strives to bridge the gap between these cutting-edge technologies and a broader audience, empowering individuals from diverse backgrounds to learn and leverage AI and ML with ease. She is helping customers to adopt AI and ML solutions on AWS in a secure and responsible way.
 Paolo Di Francesco is a Senior Solutions Architect at Amazon Web Services (AWS). He holds a PhD in Telecommunications Engineering and has experience in software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
Paolo Di Francesco is a Senior Solutions Architect at Amazon Web Services (AWS). He holds a PhD in Telecommunications Engineering and has experience in software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.
 Tomer Shenhar is a Product Manager at AWS. He specializes in responsible AI, driven by a passion to develop ethically sound and transparent AI solutions.
Tomer Shenhar is a Product Manager at AWS. He specializes in responsible AI, driven by a passion to develop ethically sound and transparent AI solutions.
Leave a Reply