
How Fastweb fine-tuned the Mistral model using Amazon SageMaker HyperPod as a first step to build an Italian large language model
This post is co-written with Marta Cavalleri and Giovanni Germani from Fastweb, and Claudia Sacco and Andrea Policarpi from BIP xTech.
AI’s transformative impact extends throughout the modern business landscape, with telecommunications emerging as a key area of innovation. Fastweb, one of Italy’s leading telecommunications operators, recognized the immense potential of AI technologies early on and began investing in this area in 2019. With a vision to build a large language model (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod.
SageMaker HyperPod can provision and maintain large-scale compute resilient clusters powered by thousands of accelerators such as AWS Trainium and NVIDIA H200 and H100 Graphical Processing Units (GPUs), but its flexibility allowed Fastweb to deploy a small, agile and on-demand cluster enabling efficient resource utilization and cost management, aligning well with the project’s requirements.
In this post, we explore how Fastweb used cutting-edge AI and ML services to embark on their LLM journey, overcoming challenges and unlocking new opportunities along the way.
Fine-tuning Mistral 7B on AWS
Fastweb recognized the importance of developing language models tailored to the Italian language and culture. To achieve this, the team built an extensive Italian language dataset by combining public sources and acquiring licensed data from publishers and media companies. Using this data, Fastweb, in their first experiment with LLM training, fine-tuned the Mistral 7B model, a state-of-the-art LLM, successfully adapting it to handle tasks such as summarization, question answering, and creative writing in the Italian language, applying a nuanced understanding of Italian culture to the LLM’s responses and providing contextually appropriate and culturally sensitive output.
The team opted for fine-tuning on AWS. This strategic decision was driven by several factors:
- Efficient data preparation – Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. Because the final, comprehensive pre-training dataset was still under construction, it was essential to begin with an approach that could adapt existing models to Italian.
- Early results and insights – Fine-tuning allowed the team to achieve early results in training models on the Italian language, providing valuable insights and preliminary Italian language models. This enabled the engineers to iteratively improve the approach based on initial outcomes.
- Computational efficiency – Fine-tuning requires significantly less computational power and less time to complete compared to a complete model pre-training. This approach streamlined the development process and allowed for a higher volume of experiments within a shorter time frame on AWS.
To facilitate the process, the team created a comprehensive dataset encompassing a wide range of tasks, constructed by translating existing English datasets and generating synthetic elements. The dataset was stored in an Amazon Simple Storage Service (Amazon S3) bucket, which served as a centralized data repository. During the training process, our SageMaker HyperPod cluster was connected to this S3 bucket, enabling effortless retrieval of the dataset elements as needed.
The integration of Amazon S3 and the SageMaker HyperPod cluster exemplifies the power of the AWS ecosystem, where various services work together seamlessly to support complex workflows.
Overcoming data scarcity with translation and synthetic data generation
When fine-tuning a custom version of the Mistral 7B LLM for the Italian language, Fastweb faced a major obstacle: high-quality Italian datasets were extremely limited or unavailable. To tackle this data scarcity challenge, Fastweb had to build a comprehensive training dataset from scratch to enable effective model fine-tuning.
While establishing strategic agreements to acquire licensed data from publishers and media companies, Fastweb employed two main strategies to create a diverse and well-rounded dataset: translating open source English training data into Italian and generating synthetic Italian data using AI models.
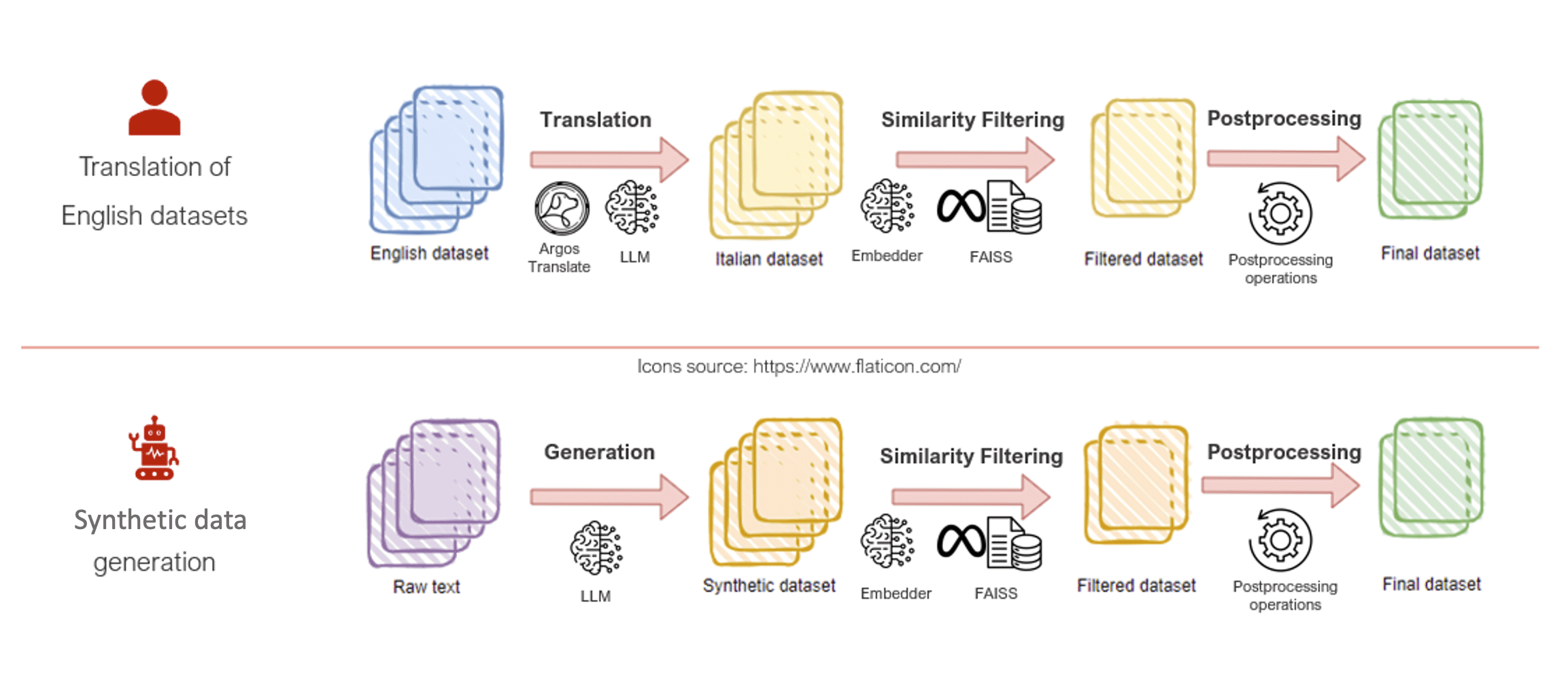
To use the wealth of information available in English, Fastweb translated open source English training datasets into Italian. This approach made valuable data accessible and relevant for Italian language training. Both LLMs and open source translation tools were used for this process.
The open source Argos Translate tool was used for bulk translation of datasets with simpler content. Although LLMs offer superior translation quality, Argos Translate is free, extremely fast, and well-suited for efficiently handling large volumes of straightforward data. For complex datasets where accuracy was critical, LLMs were employed to provide high-quality translations.
To further enrich the dataset, Fastweb generated synthetic Italian data using LLMs. This involved creating a variety of text samples covering a wide range of topics and tasks relevant to the Italian language. High-quality Italian web articles, books, and other texts served as the basis for training the LLMs to generate authentic-sounding synthetic content that captured the nuances of the language.
The resulting sub-datasets spanned diverse subjects, including medical information, question-answer pairs, conversations, web articles, science topics, and more. The tasks covered were also highly varied, encompassing question answering, summarization, creative writing, and others.
Each subset generated through translation or synthetic data creation underwent meticulous filtering to maintain quality and diversity. A similarity check was performed to deduplicate the data; if two elements were found to be too similar, one was removed. This step was crucial in maintaining variability and preventing bias from repetitive or overly similar content.
The deduplication process involved embedding dataset elements using a text embedder, then computing cosine similarity between the embeddings to identify similar elements. Meta’s FAISS library, renowned for its efficiency in similarity search and clustering of dense vectors, was used as the underlying vector database due to its ability to handle large-scale datasets effectively.
After filtering and deduplication, the remaining subsets were postprocessed and combined to form the final fine-tuning dataset, comprising 300,000 training elements. This comprehensive dataset enabled Fastweb to effectively fine-tune their custom version of the Mistral 7B model, achieving high performance and diversity across a wide range of tasks and topics.
All data generation and processing steps were run in parallel directly on the SageMaker HyperPod cluster nodes, using a unique working environment and highlighting the cluster’s versatility for various tasks beyond just training models.
The following diagram illustrates two distinct data pipelines for creating the final dataset: the upper pipeline uses translations of existing English datasets into Italian, and the lower pipeline employs custom generated synthetic data.
The computational cost of training an LLM
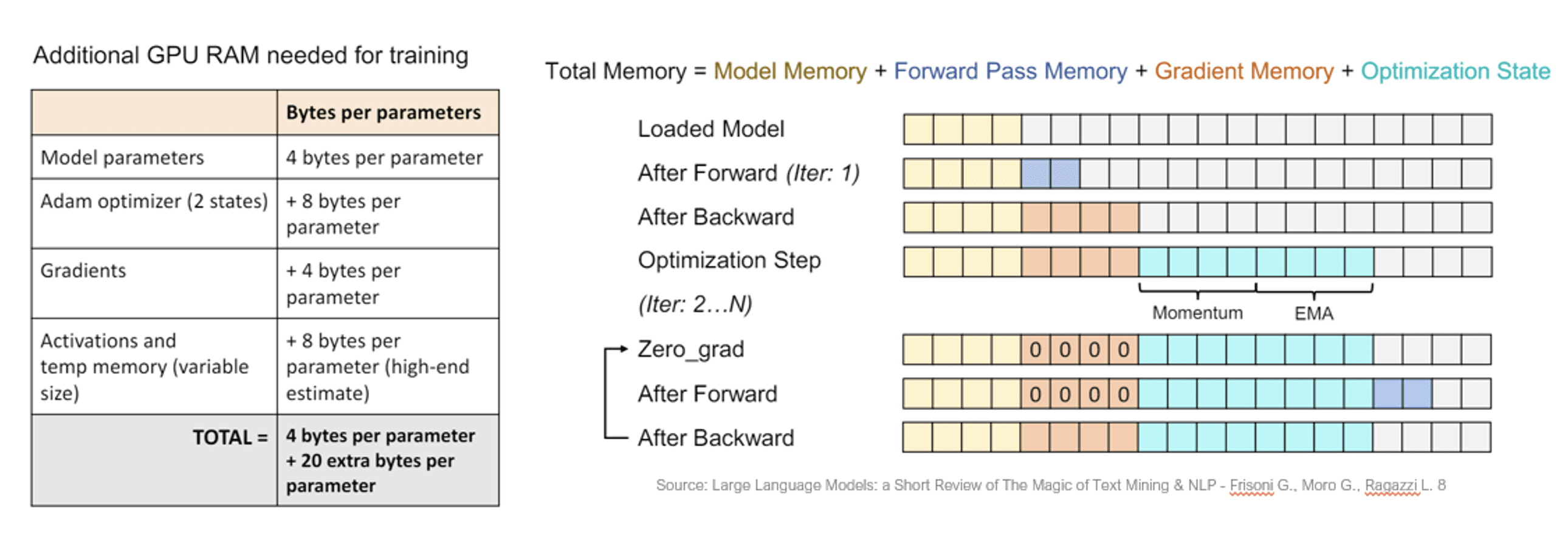
The computational cost of training LLMs scales approximately with the number of parameters and the amount of training data. As a general rule, for each model parameter being trained, approximately 24 bytes of memory are required. This means that to fully fine-tune a 7 billion parameter model like Mistral 7B, at least 156 GB of hardware memory is necessary, not including the additional overhead of loading training data.
The following table provides additional examples.
| LLM Model Size vs. Training Memory | |
| Number of Parameters | Memory Requirement |
| 500 million | 12 GB |
| 1 billion | 23 GB |
| 2 billion | 45 GB |
| 3 billion | 67 GB |
| 5 billion | 112 GB |
| 7 billion | 156 GB |
| 10 billion | 224 GB |
Parameter-efficient fine-tuning (PEFT) methods minimize the number of trainable parameters, whereas quantization reduces the number of bits per parameter, often with minimal negative impact on the final training results.
Despite these memory-saving techniques, fine-tuning large models still demands substantial GPU memory and extended training times. This makes distributed training essential, allowing the workload to be shared across multiple GPUs, thereby enabling the efficient handling of such large-scale computational tasks.
The following table and figure illustrate the allocation of GPU memory during each phase of LLM training.
Solution overview
Training LLMs often requires significant computational resources that can exceed the capabilities of a single GPU. Distributed training is a powerful technique that addresses this challenge by distributing the workload across multiple GPUs and nodes, enabling parallel processing and reducing training time. SageMaker HyperPod simplifies the process of setting up and running distributed training jobs, providing preconfigured environments and libraries specifically designed for this purpose.
There are two main techniques for distributed training: data parallelization and model parallelization. Data parallelization involves distributing the training data across multiple GPUs, whereas model parallelization splits the model itself across different GPUs.
To take advantage of distributed training, a cluster of interconnected GPUs, often spread across multiple physical nodes, is required. SageMaker HyperPod allows for both data and model parallelization techniques to be employed simultaneously, maximizing the available computational resources. Also, SageMaker HyperPod provides resilience through features like automatic fault detection and recovery, which are crucial for long-running training jobs. SageMaker HyperPod allows for the creation of personalized Conda environments, enabling the installation of necessary libraries and tools for distributed training.
One popular library for implementing distributed training is DeepSpeed, a Python optimization library that handles distributed training and makes it memory-efficient and fast by enabling both data and model parallelization. The choice to use DeepSpeed was driven by the availability of an extensive, already-developed code base, ready to be employed for training experiments. The high flexibility and environment customization capabilities of SageMaker HyperPod made it possible to create a personalized Conda environment with all the necessary libraries installed, including DeepSpeed.
The following diagram illustrates the two key parallelization strategies offered by DeepSpeed: data parallelism and model parallelism. Data parallelism involves replicating the entire model across multiple devices, with each device processing a distinct batch of training data. In contrast, model parallelism distributes different parts of a single model across multiple devices, enabling the training of large models that exceed the memory capacity of a single device.

To help meet the demanding computational requirements of training LLMs, we used the power and flexibility of SageMaker HyperPod clusters, orchestrated with Slurm. While HyperPod also supports orchestration with Amazon EKS, our research team had prior expertise with Slurm. The cluster configuration was tailored to our specific training needs, providing optimal resource utilization and cost-effectiveness.
The SageMaker HyperPod cluster architecture consisted of a controller machine to orchestrate the training job’s coordination and resource allocation. The training tasks were run by two compute nodes, which were g5.12xlarge instances equipped with high-performance GPUs. These compute nodes handled the bulk of the computational workload, using their GPUs to accelerate the training process.
The AWS managed high-performance Lustre file system (Amazon FSx for Lustre) mounted on the nodes provided high-speed data access and transfer rates, which are essential for efficient training operations.
SageMaker HyperPod is used to launch large clusters for pre-training Large Language Models (LLMs) with thousands of GPUs, but one of its key advantages is its flexibility, indeed it also allows for the creation of small, agile, and on-demand clusters. The versatility of SageMaker HyperPod made it possible to use resources only when needed, avoiding unnecessary costs.
For the DeepSpeed configuration, we followed the standard recommended setup, enabling data and model parallelism across the two g5.12xlarge nodes of the cluster, for a total of 8 GPUs.
Although more advanced techniques were available, such as offloading some computation to the CPU during training, our cluster was sized with a sufficiently high GPU margin. With 192 GiB (206 GB) of available overall GPU memory, even accounting for the additional GPU needed to keep dataset batches in memory during training, we had ample resources to train a 7B parameter model without the need for these advanced techniques. The following figure describes the infrastructure setup of our training solution.

Training results and output examples
After completing the training process, Fastweb’s fine-tuned language model demonstrated a significant performance improvement on Italian language tasks compared to the base model. Evaluated on an internal benchmark dataset, the fine-tuned model achieved an average accuracy increase of 20% across a range of tasks designed to assess its general understanding of the Italian language.
The benchmark tasks focused on three key areas: question answering, common sense reasoning, and next word prediction. Question answering tasks tested the model’s ability to comprehend and provide accurate responses to queries in Italian. Common sense reasoning evaluated the model’s grasp of common sense knowledge and its capacity to make logical inferences based on real-world scenarios. Next word prediction assessed the model’s understanding of language patterns and its ability to predict the most likely word to follow in a given context.
To evaluate the fine-tuned model’s performance, we initiated our interaction by inquiring about its capabilities. The model responded by enumerating its primary functions, emphasizing its ability to address Fastweb-specific topics. The response was formulated in correct Italian with a very natural syntax, as illustrated in the following example.

Afterwards, we asked the model to generate five titles for a presentation on the topic of AI.

Just for fun, we asked what the most famous sandwich is. The model responded with a combination of typical Italian ingredients and added that there is a wide variety of choices.

Lastly, we asked the model to provide us with a useful link to understand the recent EU AI Act. The model provided a working link, along with a helpful description.

Conclusion
Using SageMaker HyperPod, Fastweb successfully fine-tuned the Mistral 7B model as a first step in their generative AI journey, significantly improving its performance on tasks involving the Italian language.
Looking ahead, Fastweb plans to deploy their next models also on Amazon Bedrock using the Custom Model Import feature. This strategic move will enable Fastweb to quickly build and scale new generative AI solutions for their customers, using the broad set of capabilities available on Amazon Bedrock.
By harnessing Amazon Bedrock, Fastweb can further enhance their offerings and drive digital transformation for their customers. This initiative aligns with Fastweb’s commitment to staying at the forefront of AI technology and fostering innovation across various industries.
With their fine-tuned language model running on Amazon Bedrock, Fastweb will be well-positioned to deliver cutting-edge generative AI solutions tailored to the unique needs of their customers. This will empower businesses to unlock new opportunities, streamline processes, and gain valuable insights, ultimately driving growth and competitiveness in the digital age.
Fastweb’s decision to use the Custom Model Import feature in Amazon Bedrock underscores the company’s forward-thinking approach and their dedication to providing their customers with the latest and most advanced AI technologies. This collaboration with AWS further solidifies Fastweb’s position as a leader in digital transformation and a driving force behind the adoption of innovative AI solutions across industries.
To learn more about SageMaker HyperPod, refer to Amazon SageMaker HyperPod and the Amazon SageMaker HyperPod workshop.
About the authors
 Marta Cavalleri is the Manager of the Artificial Intelligence Center of Excellence (CoE) at Fastweb, where she leads teams of data scientists and engineers in implementing enterprise AI solutions. She specializes in AI operations, data governance, and cloud architecture on AWS.
Marta Cavalleri is the Manager of the Artificial Intelligence Center of Excellence (CoE) at Fastweb, where she leads teams of data scientists and engineers in implementing enterprise AI solutions. She specializes in AI operations, data governance, and cloud architecture on AWS.
 Giovanni Germani is the Manager of Architecture & Artificial Intelligence CoE at Fastweb, where he leverages his extensive experience in Enterprise Architecture and digital transformation. With over 12 years in Management Consulting, Giovanni specializes in technology-driven projects across telecommunications, media, and insurance industries. He brings deep expertise in IT strategy, cybersecurity, and artificial intelligence to drive complex transformation programs.
Giovanni Germani is the Manager of Architecture & Artificial Intelligence CoE at Fastweb, where he leverages his extensive experience in Enterprise Architecture and digital transformation. With over 12 years in Management Consulting, Giovanni specializes in technology-driven projects across telecommunications, media, and insurance industries. He brings deep expertise in IT strategy, cybersecurity, and artificial intelligence to drive complex transformation programs.
 Claudia Sacco is an AWS Professional Solutions Architect at BIP xTech, collaborating with Fastweb’s AI CoE and specialized in architecting advanced cloud and data platforms that drive innovation and operational excellence. With a sharp focus on delivering scalable, secure, and future-ready solutions, she collaborates with organizations to unlock the full potential of cloud technologies. Beyond her professional expertise, Claudia finds inspiration in the outdoors, embracing challenges through climbing and trekking adventures with her family.
Claudia Sacco is an AWS Professional Solutions Architect at BIP xTech, collaborating with Fastweb’s AI CoE and specialized in architecting advanced cloud and data platforms that drive innovation and operational excellence. With a sharp focus on delivering scalable, secure, and future-ready solutions, she collaborates with organizations to unlock the full potential of cloud technologies. Beyond her professional expertise, Claudia finds inspiration in the outdoors, embracing challenges through climbing and trekking adventures with her family.
 Andrea Policarpi is a Data Scientist at BIP xTech, collaborating with Fastweb’s AI CoE. With a strong foundation in computer vision and natural language processing, he is currently exploring the world of Generative AI and leveraging its powerful tools to craft innovative solutions for emerging challenges. In his free time, Andrea is an avid reader and enjoys playing the piano to relax.
Andrea Policarpi is a Data Scientist at BIP xTech, collaborating with Fastweb’s AI CoE. With a strong foundation in computer vision and natural language processing, he is currently exploring the world of Generative AI and leveraging its powerful tools to craft innovative solutions for emerging challenges. In his free time, Andrea is an avid reader and enjoys playing the piano to relax.
 Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
 Adolfo Pica has a strong background in cloud computing, with over 20 years of experience in designing, implementing, and optimizing complex IT systems and architectures and with a keen interest and hands-on experience in the rapidly evolving field of generative AI and foundation models. He has expertise in AWS cloud services, DevOps practices, security, data analytics and generative AI. In his free time, Adolfo enjoys following his two sons in their sporting adventures in taekwondo and football.
Adolfo Pica has a strong background in cloud computing, with over 20 years of experience in designing, implementing, and optimizing complex IT systems and architectures and with a keen interest and hands-on experience in the rapidly evolving field of generative AI and foundation models. He has expertise in AWS cloud services, DevOps practices, security, data analytics and generative AI. In his free time, Adolfo enjoys following his two sons in their sporting adventures in taekwondo and football.
 Maurizio Pinto is a Senior Solutions Architect at AWS, specialized in cloud solutions for telecommunications. With extensive experience in software architecture and AWS services, he helps organizations navigate their cloud journey while pursuing his passion for AI’s transformative impact on technology and society.
Maurizio Pinto is a Senior Solutions Architect at AWS, specialized in cloud solutions for telecommunications. With extensive experience in software architecture and AWS services, he helps organizations navigate their cloud journey while pursuing his passion for AI’s transformative impact on technology and society.
Leave a Reply