
The Weather Company enhances MLOps with Amazon SageMaker, AWS CloudFormation, and Amazon CloudWatch
This blog post is co-written with Qaish Kanchwala from The Weather Company.
As industries begin adopting processes dependent on machine learning (ML) technologies, it is critical to establish machine learning operations (MLOps) that scale to support growth and utilization of this technology. MLOps practitioners have many options to establish an MLOps platform; one among them is cloud-based integrated platforms that scale with data science teams. AWS provides a full-stack of services to establish an MLOps platform in the cloud that is customizable to your needs while reaping all the benefits of doing ML in the cloud.
In this post, we share the story of how The Weather Company (TWCo) enhanced its MLOps platform using services such as Amazon SageMaker, AWS CloudFormation, and Amazon CloudWatch. TWCo data scientists and ML engineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. TWCo reduced infrastructure management time by 90% while also reducing model deployment time by 20%.
The need for MLOps at TWCo
TWCo strives to help consumers and businesses make informed, more confident decisions based on weather. Although the organization has used ML in its weather forecasting process for decades to help translate billions of weather data points into actionable forecasts and insights, it continuously strives to innovate and incorporate leading-edge technology in other ways as well. TWCo’s data science team was looking to create predictive, privacy-friendly ML models that show how weather conditions affect certain health symptoms and create user segments for improved user experience.
TWCo was looking to scale its ML operations with more transparency and less complexity to allow for more manageable ML workflows as their data science team grew. There were noticeable challenges when running ML workflows in the cloud. TWCo’s existing Cloud environment lacked transparency for ML jobs, monitoring, and a feature store, which made it hard for users to collaborate. Managers lacked the visibility needed for ongoing monitoring of ML workflows. To address these pain points, TWCo worked with the AWS Machine Learning Solutions Lab (MLSL) to migrate these ML workflows to Amazon SageMaker and the AWS Cloud. The MLSL team collaborated with TWCo to design an MLOps platform to meet the needs of its data science team, factoring present and future growth.
Examples of business objectives set by TWCo for this collaboration are:
- Achieve quicker reaction to the market and faster ML development cycles
- Accelerate TWCo migration of their ML workloads to SageMaker
- Improve end user experience through adoption of manage services
- Reduce time spent by engineers in maintenance and upkeep of the underlying ML infrastructure
Functional objectives were set to measure the impact of MLOps platform users, including:
- Improve the data science team’s efficiency in model training tasks
- Decrease the number of steps required to deploy new models
- Reduce the end-to-end model pipeline runtime
Solution overview
The solution uses the following AWS services:
- AWS CloudFormation – Infrastructure as code (IaC) service to provision most templates and assets.
- AWS CloudTrail – Monitors and records account activity across AWS infrastructure.
- Amazon CloudWatch – Collects and visualizes real-time logs that provide the basis for automation.
- AWS CodeBuild – Fully managed continuous integration service to compile source code, runs tests, and produces ready-to-deploy software. Used to deploy training and inference code.
- AWS CodeCommit – Managed sourced control repository that stores MLOps infrastructure code and IaC code.
- AWS CodePipeline – Fully managed continuous delivery service that helps automate the release of pipelines.
- Amazon SageMaker – Fully managed ML platform to perform ML workflows from exploring data, training, and deploying models.
- AWS Service Catalog – Centrally manages cloud resources such as IaC templates used for MLOps projects.
- Amazon Simple Storage Service (Amazon S3) – Cloud object storage to store data for training and testing.
The following diagram illustrates the solution architecture.
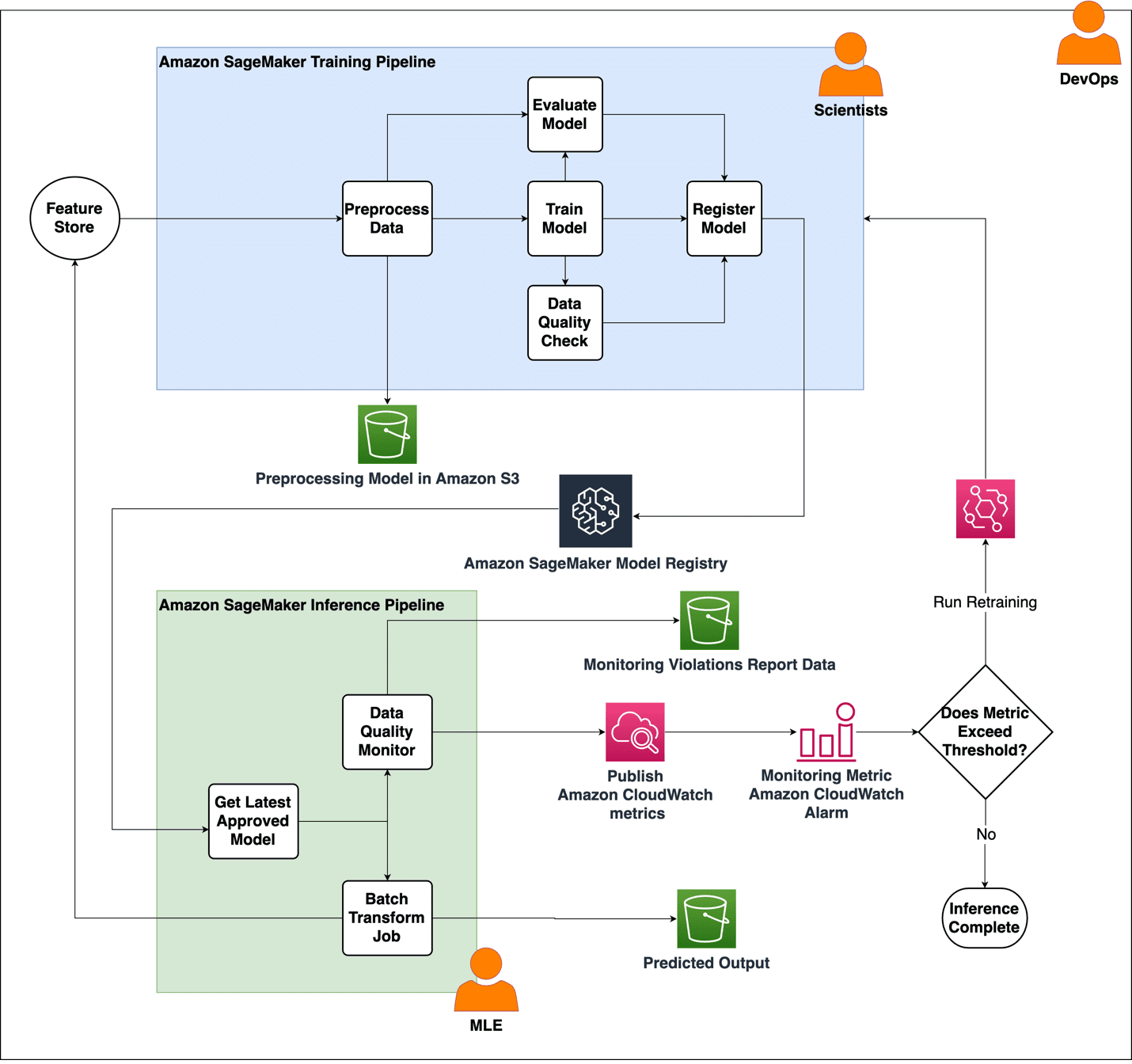
This architecture consists of two primary pipelines:
- Training pipeline – The training pipeline is designed to work with features and labels stored as a CSV-formatted file on Amazon S3. It involves several components, including Preprocess, Train, and Evaluate. After training the model, its associated artifacts are registered with the Amazon SageMaker Model Registry through the Register Model component. The Data Quality Check part of the pipeline creates baseline statistics for the monitoring task in the inference pipeline.
- Inference pipeline – The inference pipeline handles on-demand batch inference and monitoring tasks. Within this pipeline, SageMaker on-demand Data Quality Monitor steps are incorporated to detect any drift when compared to the input data. The monitoring results are stored in Amazon S3 and published as a CloudWatch metric, and can be used to set up an alarm. The alarm is used later to invoke training, send automatic emails, or any other desired action.
The proposed MLOps architecture includes flexibility to support different use cases, as well as collaboration between various team personas like data scientists and ML engineers. The architecture reduces the friction between cross-functional teams moving models to production.
ML model experimentation is one of the sub-components of the MLOps architecture. It improves data scientists’ productivity and model development processes. Examples of model experimentation on MLOps-related SageMaker services require features like Amazon SageMaker Pipelines, Amazon SageMaker Feature Store, and SageMaker Model Registry using the SageMaker SDK and AWS Boto3 libraries.
When setting up pipelines, resources are created that are required throughout the lifecycle of the pipeline. Additionally, each pipeline may generate its own resources.
The pipeline setup resources are:
- Training pipeline:
- SageMaker pipeline
- SageMaker Model Registry model group
- CloudWatch namespace
- Inference pipeline:
- SageMaker pipeline
The pipeline run resources are:
- Training pipeline:
- SageMaker model
You should delete these resources when the pipelines expire or are no longer needed.
SageMaker project template
In this section, we discuss the manual provisioning of pipelines through an example notebook and automatic provisioning of SageMaker pipelines through the use of a Service Catalog product and SageMaker project.
By using Amazon SageMaker Projects and its powerful template-based approach, organizations establish a standardized and scalable infrastructure for ML development, allowing teams to focus on building and iterating ML models, reducing time wasted on complex setup and management.
The following diagram shows the required components of a SageMaker project template. Use Service Catalog to register a SageMaker project CloudFormation template in your organization’s Service Catalog portfolio.
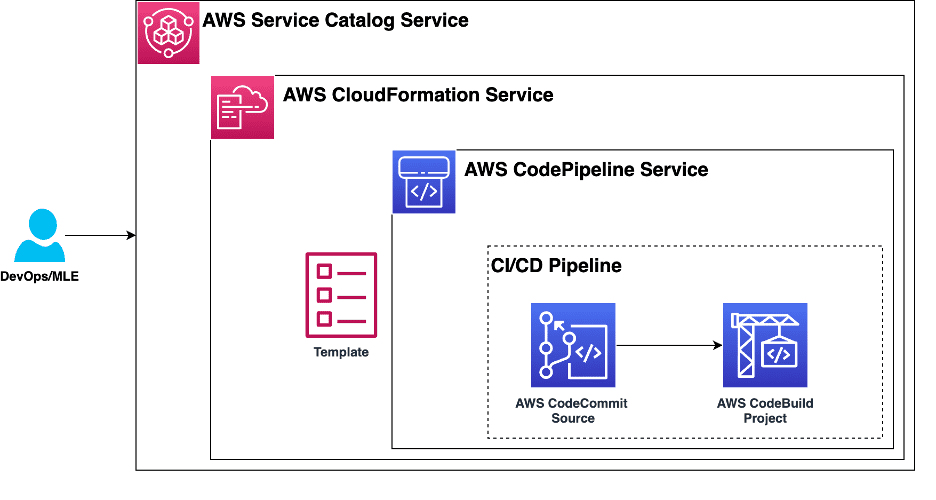
To start the ML workflow, the project template serves as the foundation by defining a continuous integration and delivery (CI/CD) pipeline. It begins by retrieving the ML seed code from a CodeCommit repository. Then the BuildProject component takes over and orchestrates the provisioning of SageMaker training and inference pipelines. This automation delivers a seamless and efficient run of the ML pipeline, reducing manual intervention and speeding up the deployment process.
Dependencies
The solution has the following dependencies:
- Amazon SageMaker SDK – The Amazon SageMaker Python SDK is an open source library for training and deploying ML models on SageMaker. For this proof of concept, pipelines were set up using this SDK.
- Boto3 SDK – The AWS SDK for Python (Boto3) provides a Python API for AWS infrastructure services. We use the SDK for Python to create roles and provision SageMaker SDK resources.
- SageMaker Projects – SageMaker Projects delivers standardized infrastructure and templates for MLOps for rapid iteration over multiple ML use cases.
- Service Catalog – Service Catalog simplifies and speeds up the process of provisioning resources at scale. It offers a self-service portal, standardized service catalog, versioning and lifecycle management, and access control.
Conclusion
In this post, we showed how TWCo uses SageMaker, CloudWatch, CodePipeline, and CodeBuild for their MLOps platform. With these services, TWCo extended the capabilities of its data science team while also improving how data scientists manage ML workflows. These ML models ultimately helped TWCo create predictive, privacy-friendly experiences that improved user experience and explains how weather conditions impact consumers’ daily planning or business operations. We also reviewed the architecture design that helps maintain responsibilities between different users modularized. Typically data scientists are only concerned with the science aspect of ML workflows, whereas DevOps and ML engineers focus on the production environments. TWCo reduced infrastructure management time by 90% while also reducing model deployment time by 20%.
This is just one of many ways AWS enables builders to deliver great solutions. We encourage to you to get started with Amazon SageMaker today.
About the Authors
 Qaish Kanchwala is a ML Engineering Manager and ML Architect at The Weather Company. He has worked on every step of the machine learning lifecycle and designs systems to enable AI use cases. In his spare time, Qaish likes to cook new food and watch movies.
Qaish Kanchwala is a ML Engineering Manager and ML Architect at The Weather Company. He has worked on every step of the machine learning lifecycle and designs systems to enable AI use cases. In his spare time, Qaish likes to cook new food and watch movies.
 Chezsal Kamaray is a Senior Solutions Architect within the High-Tech Vertical at Amazon Web Services. She works with enterprise customers, helping to accelerate and optimize their workload migration to the AWS Cloud. She is passionate about management and governance in the cloud and helping customers set up a landing zone that is aimed at long-term success. In her spare time, she does woodworking and tries out new recipes while listening to music.
Chezsal Kamaray is a Senior Solutions Architect within the High-Tech Vertical at Amazon Web Services. She works with enterprise customers, helping to accelerate and optimize their workload migration to the AWS Cloud. She is passionate about management and governance in the cloud and helping customers set up a landing zone that is aimed at long-term success. In her spare time, she does woodworking and tries out new recipes while listening to music.
 Anila Joshi has more than a decade of experience building AI solutions. As an Applied Science Manager at the AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and guides customers to strategically chart a course into the future of AI.
Anila Joshi has more than a decade of experience building AI solutions. As an Applied Science Manager at the AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and guides customers to strategically chart a course into the future of AI.
 Kamran Razi is a Machine Learning Engineer at the Amazon Generative AI Innovation Center. With a passion for creating use case-driven solutions, Kamran helps customers harness the full potential of AWS AI/ML services to address real-world business challenges. With a decade of experience as a software developer, he has honed his expertise in diverse areas like embedded systems, cybersecurity solutions, and industrial control systems. Kamran holds a PhD in Electrical Engineering from Queen’s University.
Kamran Razi is a Machine Learning Engineer at the Amazon Generative AI Innovation Center. With a passion for creating use case-driven solutions, Kamran helps customers harness the full potential of AWS AI/ML services to address real-world business challenges. With a decade of experience as a software developer, he has honed his expertise in diverse areas like embedded systems, cybersecurity solutions, and industrial control systems. Kamran holds a PhD in Electrical Engineering from Queen’s University.
 Shuja Sohrawardy is a Senior Manager at AWS’s Generative AI Innovation Center. For over 20 years, Shuja has utilized his technology and financial services acumen to transform financial services enterprises to meet the challenges of a highly competitive and regulated industry. Over the past 4 years at AWS, Shuja has used his deep knowledge in machine learning, resiliency, and cloud adoption strategies, which has resulted in numerous customer success journeys. Shuja holds a BS in Computer Science and Economics from New York University and an MS in Executive Technology Management from Columbia University.
Shuja Sohrawardy is a Senior Manager at AWS’s Generative AI Innovation Center. For over 20 years, Shuja has utilized his technology and financial services acumen to transform financial services enterprises to meet the challenges of a highly competitive and regulated industry. Over the past 4 years at AWS, Shuja has used his deep knowledge in machine learning, resiliency, and cloud adoption strategies, which has resulted in numerous customer success journeys. Shuja holds a BS in Computer Science and Economics from New York University and an MS in Executive Technology Management from Columbia University.
 Francisco Calderon is a Data Scientist at the Generative AI Innovation Center (GAIIC). As a member of the GAIIC, he helps discover the art of the possible with AWS customers using generative AI technologies. In his spare time, Francisco likes playing music and guitar, playing soccer with his daughters, and enjoying time with his family.
Francisco Calderon is a Data Scientist at the Generative AI Innovation Center (GAIIC). As a member of the GAIIC, he helps discover the art of the possible with AWS customers using generative AI technologies. In his spare time, Francisco likes playing music and guitar, playing soccer with his daughters, and enjoying time with his family.
Leave a Reply