
Beyond Tabula Rasa: Reincarnating Reinforcement Learning

Reinforcement learning (RL) is an area of machine learning that focuses on training intelligent agents using related experiences so they can learn to solve decision making tasks, such as playing video games, flying stratospheric balloons, and designing hardware chips. Due to the generality of RL, the prevalent trend in RL research is to develop agents that can efficiently learn tabula rasa, that is, from scratch without using previously learned knowledge about the problem. However, in practice, tabula rasa RL systems are typically the exception rather than the norm for solving large-scale RL problems. Large-scale RL systems, such as OpenAI Five, which achieves human-level performance on Dota 2, undergo multiple design changes (e.g., algorithmic or architectural changes) during their developmental cycle. This modification process can last months and necessitates incorporating such changes without re-training from scratch, which would be prohibitively expensive.
Furthermore, the inefficiency of tabula rasa RL research can exclude many researchers from tackling computationally-demanding problems. For example, the quintessential benchmark of training a deep RL agent on 50+ Atari 2600 games in ALE for 200M frames (the standard protocol) requires 1,000+ GPU days. As deep RL moves towards more complex and challenging problems, the computational barrier to entry in RL research will likely become even higher.
To address the inefficiencies of tabula rasa RL, we present “Reincarnating Reinforcement Learning: Reusing Prior Computation To Accelerate Progress” at NeurIPS 2022. Here, we propose an alternative approach to RL research, where prior computational work, such as learned models, policies, logged data, etc., is reused or transferred between design iterations of an RL agent or from one agent to another. While some sub-areas of RL leverage prior computation, most RL agents are still largely trained from scratch. Until now, there has been no broader effort to leverage prior computational work for the training workflow in RL research. We have also released our code and trained agents to enable researchers to build on this work.
 |
| Tabula rasa RL vs. Reincarnating RL (RRL). While tabula rasa RL focuses on learning from scratch, RRL is based on the premise of reusing prior computational work (e.g., prior learned agents) when training new agents or improving existing agents, even in the same environment. In RRL, new agents need not be trained from scratch, except for initial forays into new problems. |
Why Reincarnating RL?
Reincarnating RL (RRL) is a more compute and sample-efficient workflow than training from scratch. RRL can democratize research by allowing the broader community to tackle complex RL problems without requiring excessive computational resources. Furthermore, RRL can enable a benchmarking paradigm where researchers continually improve and update existing trained agents, especially on problems where improving performance has real-world impact, such as balloon navigation or chip design. Finally, real-world RL use cases will likely be in scenarios where prior computational work is available (e.g., existing deployed RL policies).
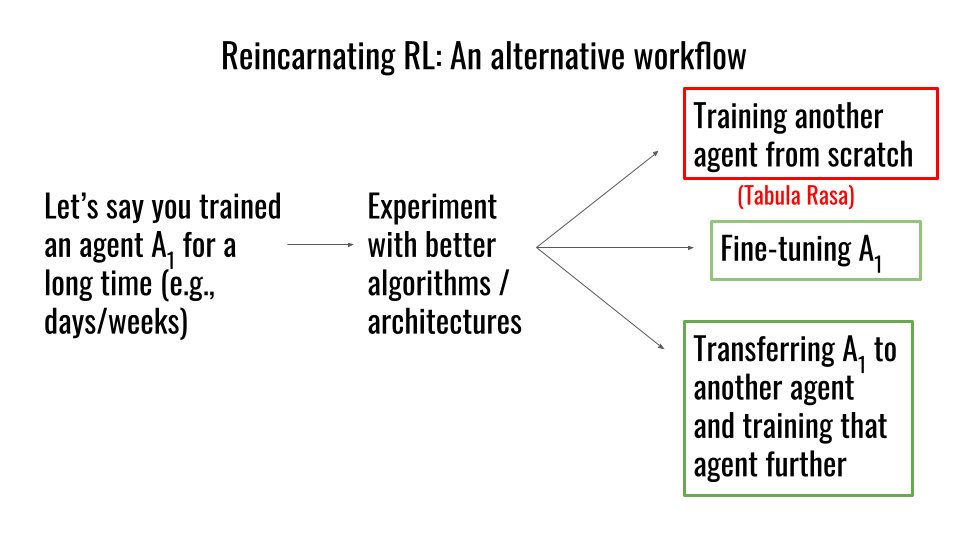 |
| RRL as an alternative research workflow. Imagine a researcher who has trained an agent A1 for some time, but now wants to experiment with better architectures or algorithms. While the tabula rasa workflow requires retraining another agent from scratch, RRL provides the more viable option of transferring the existing agent A1 to another agent and training this agent further, or simply fine-tuning A1. |
While there have been some ad hoc large-scale reincarnation efforts with limited applicability, e.g., model surgery in Dota2, policy distillation in Rubik’s cube, PBT in AlphaStar, RL fine-tuning a behavior-cloned policy in AlphaGo / Minecraft, RRL has not been studied as a research problem in its own right. To this end, we argue for developing general-purpose RRL approaches as opposed to prior ad-hoc solutions.
Case Study: Policy to Value Reincarnating RL
Different RRL problems can be instantiated depending on the kind of prior computational work provided. As a step towards developing broadly applicable RRL approaches, we present a case study on the setting of Policy to Value reincarnating RL (PVRL) for efficiently transferring an existing sub-optimal policy (teacher) to a standalone value-based RL agent (student). While a policy directly maps a given environment state (e.g., a game screen in Atari) to an action, value-based agents estimate the effectiveness of an action at a given state in terms of achievable future rewards, which allows them to learn from previously collected data.

For a PVRL algorithm to be broadly useful, it should satisfy the following requirements:
- Teacher Agnostic: The student shouldn’t be constrained by the existing teacher policy’s architecture or training algorithm.
- Weaning off the teacher: It is undesirable to maintain dependency on past suboptimal teachers for successive reincarnations.
- Compute / Sample Efficient: Reincarnation is only useful if it is cheaper than training from scratch.
Given the PVRL algorithm requirements, we evaluate whether existing approaches, designed with closely related goals, will suffice. We find that such approaches either result in small improvements over tabula rasa RL or degrade in performance when weaning off the teacher.
To address these limitations, we introduce a simple method, QDagger, in which the agent distills knowledge from the suboptimal teacher via an imitation algorithm while simultaneously using its environment interactions for RL. We start with a deep Q-network (DQN) agent trained for 400M environment frames (a week of single-GPU training) and use it as the teacher for reincarnating student agents trained on only 10M frames (a few hours of training), where the teacher is weaned off over the first 6M frames. For benchmark evaluation, we report the interquartile mean (IQM) metric from the RLiable library. As shown below for the PVRL setting on Atari games, we find that the QDagger RRL method outperforms prior approaches.
 |
| Benchmarking PVRL algorithms on Atari, with teacher-normalized scores aggregated across 10 games. Tabula rasa DQN (–·–) obtains a normalized score of 0.4. Standard baseline approaches include kickstarting, JSRL, rehearsal, offline RL pre-training and DQfD. Among all methods, only QDagger surpasses teacher performance within 10 million frames and outperforms the teacher in 75% of the games. |
Reincarnating RL in Practice
We further examine the RRL approach on the Arcade Learning Environment, a widely used deep RL benchmark. First, we take a Nature DQN agent that uses the RMSProp optimizer and fine-tune it with the Adam optimizer to create a DQN (Adam) agent. While it is possible to train a DQN (Adam) agent from scratch, we demonstrate that fine-tuning Nature DQN with the Adam optimizer matches the from-scratch performance using 40x less data and compute.
 |
| Reincarnating DQN (Adam) via Fine-Tuning. The vertical separator corresponds to loading network weights and replay data for fine-tuning. Left: Tabula rasa Nature DQN nearly converges in performance after 200M environment frames. Right: Fine-tuning this Nature DQN agent using a reduced learning rate with the Adam optimizer for 20 million frames obtains similar results to DQN (Adam) trained from scratch for 400M frames. |
Given the DQN (Adam) agent as a starting point, fine-tuning is restricted to the 3-layer convolutional architecture. So, we consider a more general reincarnation approach that leverages recent architectural and algorithmic advances without training from scratch. Specifically, we use QDagger to reincarnate another RL agent that uses a more advanced RL algorithm (Rainbow) and a better neural network architecture (Impala-CNN ResNet) from the fine-tuned DQN (Adam) agent.
 |
| Reincarnating a different architecture / algorithm via QDagger. The vertical separator is the point at which we apply offline pre-training using QDagger for reincarnation. Left: Fine-tuning DQN with Adam. Right: Comparison of a tabula rasa Impala-CNN Rainbow agent (sky blue) to an Impala-CNN Rainbow agent (pink) trained using QDagger RRL from the fine-tuned DQN (Adam). The reincarnated Impala-CNN Rainbow agent consistently outperforms its scratch counterpart. Note that further fine-tuning DQN (Adam) results in diminishing returns (yellow). |
Overall, these results indicate that past research could have been accelerated by incorporating a RRL approach to designing agents, instead of re-training agents from scratch. Our paper also contains results on the Balloon Learning Environment, where we demonstrate that RRL allows us to make progress on the problem of navigating stratospheric balloons using only a few hours of TPU-compute by reusing a distributed RL agent trained on TPUs for more than a month.
Discussion
Fairly comparing reincarnation approaches involves using the exact same computational work and workflow. Furthermore, the research findings in RRL that broadly generalize would be about how effective an algorithm is given access to existing computational work, e.g., we successfully applied QDagger developed using Atari for reincarnation on Balloon Learning Environment. As such, we speculate that research in reincarnating RL can branch out in two directions:
- Standardized benchmarks with open-sourced computational work: Akin to NLP and vision, where typically a small set of pre-trained models are common, research in RRL may also converge to a small set of open-sourced computational work (e.g., pre-trained teacher policies) on a given benchmark.
- Real-world domains: Since obtaining higher performance has real-world impact in some domains, it incentivizes the community to reuse state-of-the-art agents and try to improve their performance.
See our paper for a broader discussion on scientific comparisons, generalizability and reproducibility in RRL. Overall, we hope that this work motivates researchers to release computational work (e.g., model checkpoints) on which others could directly build. In this regard, we have open-sourced our code and trained agents with their final replay buffers. We believe that reincarnating RL can substantially accelerate research progress by building on prior computational work, as opposed to always starting from scratch.
Acknowledgements
This work was done in collaboration with Pablo Samuel Castro, Aaron Courville and Marc Bellemare. We’d like to thank Tom Small for the animated figure used in this post. We are also grateful for feedback by the anonymous NeurIPS reviewers and several members of the Google Research team, DeepMind and Mila.
Leave a Reply