
Differential Privacy Accounting by Connecting the Dots

Differential privacy (DP) is an approach that enables data analytics and machine learning (ML) with a mathematical guarantee on the privacy of user data. DP quantifies the “privacy cost” of an algorithm, i.e., the level of guarantee that the algorithm’s output distribution for a given dataset will not change significantly if a single user’s data is added to or removed from it. The algorithm is characterized by two parameters, ε and δ, where smaller values of both indicate “more private”. There is a natural tension between the privacy budget (ε, δ) and the utility of the algorithm: a smaller privacy budget requires the output to be more “noisy”, often leading to less utility. Thus, a fundamental goal of DP is to attain as much utility as possible for a desired privacy budget.
A key property of DP that often plays a central role in understanding privacy costs is that of composition, which reflects the net privacy cost of a combination of DP algorithms, viewed together as a single algorithm. A notable example is the differentially-private stochastic gradient descent (DP-SGD) algorithm. This algorithm trains ML models over multiple iterations — each of which is differentially private — and therefore requires an application of the composition property of DP. A basic composition theorem in DP says that the privacy cost of a collection of algorithms is, at most, the sum of the privacy cost of each. However, in many cases, this can be a gross overestimate, and several improved composition theorems provide better estimates of the privacy cost of composition.
In 2019, we released an open-source library (on GitHub) to enable developers to use analytic techniques based on DP. Today, we announce the addition to this library of Connect-the-Dots, a new privacy accounting algorithm based on a novel approach for discretizing privacy loss distributions that is a useful tool for understanding the privacy cost of composition. This algorithm is based on the paper “Connect the Dots: Tighter Discrete Approximations of Privacy Loss Distributions”, presented at PETS 2022. The main novelty of this accounting algorithm is that it uses an indirect approach to construct more accurate discretizations of privacy loss distributions. We find that Connect-the-Dots provides significant gains over other privacy accounting methods in literature in terms of accuracy and running time. This algorithm was also recently applied for the privacy accounting of DP-SGD in training Ads prediction models.
Differential Privacy and Privacy Loss Distributions
A randomized algorithm is said to satisfy DP guarantees if its output “does not depend significantly” on any one entry in its training dataset, quantified mathematically with parameters (ε, δ). For example, consider the motivating example of DP-SGD. When trained with (non-private) SGD, a neural network could, in principle, be encoding the entire training dataset within its weights, thereby allowing one to reconstruct some training examples from a trained model. On the other hand, when trained with DP-SGD, we have a formal guarantee that if one were able to reconstruct a training example with non-trivial probability then one would also be able to reconstruct the same example even if it was not included in the training dataset.
The hockey stick divergence, parameterized by ε, is a measure of distance between two probability distributions, as illustrated in the figure below. The privacy cost of most DP algorithms is dictated by the hockey stick divergence between two associated probability distributions P and Q. The algorithm satisfies DP with parameters (ε, δ), if the value of the hockey stick divergence for ε between P and Q is at most δ. The hockey stick divergence between (P, Q), denoted δP||Q(ε) is in turn completely characterized by it associated privacy loss distribution, denoted by PLDP||Q.
 |
| Illustration of hockey stick divergence δP||Q(ε) between distributions P and Q (left), which corresponds to the probability mass of P that is above eεQ, where eεQ is an eε scaling of the probability mass of Q (right). |
The main advantage of dealing with PLDs is that compositions of algorithms correspond to the convolution of the corresponding PLDs. Exploiting this fact, prior work has designed efficient algorithms to compute the PLD corresponding to the composition of individual algorithms by simply performing convolution of the individual PLDs using the fast Fourier transform algorithm.
However, one challenge when dealing with many PLDs is that they often are continuous distributions, which make the convolution operations intractable in practice. Thus, researchers often apply various discretization approaches to approximate the PLDs using equally spaced points. For example, the basic version of the Privacy Buckets algorithm assigns the probability mass of the interval between two discretization points entirely to the higher end of the interval.
 |
| Illustration of discretization by rounding up probability masses. Here a continuous PLD (in blue) is discretized to a discrete PLD (in red), by rounding up the probability mass between consecutive points. |
Connect-the-Dots : A New Algorithm
Our new Connect-the-Dots algorithm provides a better way to discretize PLDs towards the goal of estimating hockey stick divergences. This approach works indirectly by first discretizing the hockey stick divergence function and then mapping it back to a discrete PLD supported on equally spaced points.
 |
| Illustration of high-level steps in the Connect-the-Dots algorithm. |
This approach relies on the notion of a “dominating PLD”, namely, PLDP’||Q’ dominates over PLDP||Q if the hockey stick divergence of the former is greater or equal to the hockey stick divergence of the latter for all values of ε. The key property of dominating PLDs is that they remain dominating after compositions. Thus for purposes of privacy accounting, it suffices to work with a dominating PLD, which gives us an upper bound on the exact privacy cost.
Our main insight behind the Connect-the-Dots algorithm is a characterization of discrete PLD, namely that a PLD is supported on a given finite set of ε values if and only if the corresponding hockey stick divergence as a function of eε is linear between consecutive eε values. This allows us to discretize the hockey stick divergence by simply connecting the dots to get a piecewise linear function that precisely equals the hockey stick divergence function at the given eε values. See a more detailed explanation of the algorithm.
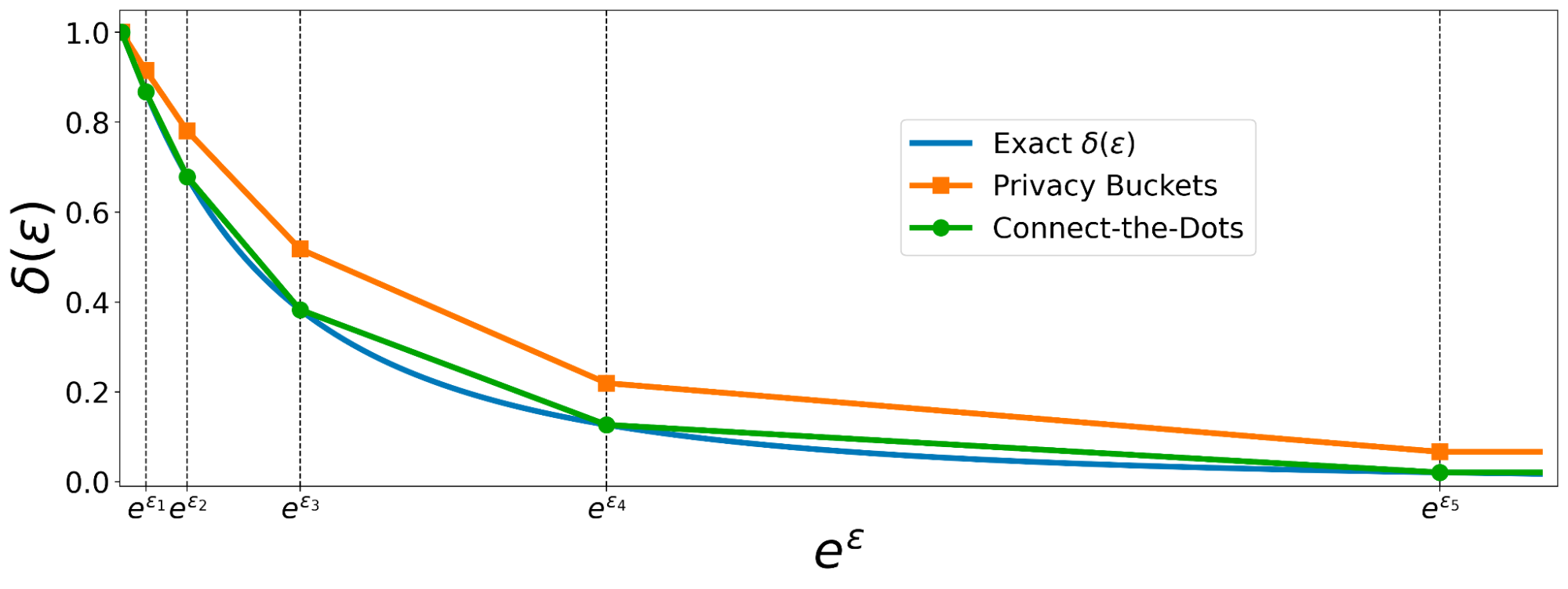 |
| Comparison of the discretizations of hockey stick divergence by Connect-the-Dots vs Privacy Buckets. |
Experimental Evaluation
The DP-SGD algorithm involves a noise multiplier parameter, which controls the magnitude of noise added in each gradient step, and a sampling probability, which controls how many examples are included in each mini-batch. We compare Connect-the-Dots against the algorithms listed below on the task of privacy accounting DP-SGD with a noise multiplier = 0.5, sampling probability = 0.2 x 10-4 and δ = 10-8.
- Renyi DP : The original approach used for the privacy accounting of DP-SGD. This accounting method is also supported in the Google-DP library.
- Privacy Buckets : The previous PLD-based approach used in Google-DP library, which rounds up probability masses between discretization points.
- Microsoft PRV Accountant : This approach improves upon the Privacy Buckets approach using a discretization that preserves the mean of the PLD.
We plot the value of the ε computed by each of the algorithms against the number of composition steps, and additionally, we plot the running time of the implementations. As shown in the plots below, privacy accounting using Renyi DP provides a loose estimate of the privacy loss. However, when comparing the approaches using PLD, we find that in this example, the implementation of Connect-the-Dots achieves a tighter estimate of the privacy loss, with a running time that is 5x faster than the Microsoft PRV Accountant and >200x faster than the previous approach of Privacy Buckets in the Google-DP library.
 |
| Left: Upper bounds on the privacy parameter ε for varying number of steps of DP-SGD, as returned by different algorithms (for fixed δ = 10-8). Right: Running time of the different algorithms. |
Conclusion & Future Directions
This work proposes Connect-the-Dots, a new algorithm for computing optimal privacy parameters for compositions of differentially private algorithms. When evaluated on the DP-SGD task, we find that this algorithm gives tighter estimates on the privacy loss with a significantly faster running time.
So far, the library only supports the pessimistic estimate version of Connect-the-Dots algorithm, which provides an upper bound on the privacy loss of DP-algorithms. However, the paper also introduces a variant of the algorithm that provides an “optimistic” estimate of the PLD, which can be used to derive lower bounds on the privacy cost of DP-algorithms (provided those admit a “worst case” PLD). Currently, the library does support optimistic estimates as given by the Privacy Buckets algorithm, and we hope to incorporate the Connect-the-Dots version as well.
Acknowledgements
This work was carried out in collaboration with Vadym Doroshenko, Badih Ghazi, Ravi Kumar. We thank Galen Andrew, Stan Bashtavenko, Steve Chien, Christoph Dibak, Miguel Guevara, Peter Kairouz, Sasha Kulankhina, Stefan Mellem, Jodi Spacek, Yurii Sushko and Andreas Terzis for their help.
Leave a Reply