
Automate mortgage document fraud detection using an ML model and business-defined rules with Amazon Fraud Detector: Part 3
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case.
In the second post, we discussed an approach to develop a deep learning-based computer vision model to detect and highlight forged images in mortgage underwriting.
In this post, we present a solution to automate mortgage document fraud detection using an ML model and business-defined rules with Amazon Fraud Detector.
Solution overview
We use Amazon Fraud Detector, a fully managed fraud detection service, to automate the detection of fraudulent activities. With an objective to improve fraud prediction accuracies by proactively identifying document fraud, while improving underwriting accuracies, Amazon Fraud Detector helps you build customized fraud detection models using a historical dataset, configure customized decision logic using the built-in rules engine, and orchestrate risk decision workflows with the click of a button.
The following diagram represents each stage in a mortgage document fraud detection pipeline.
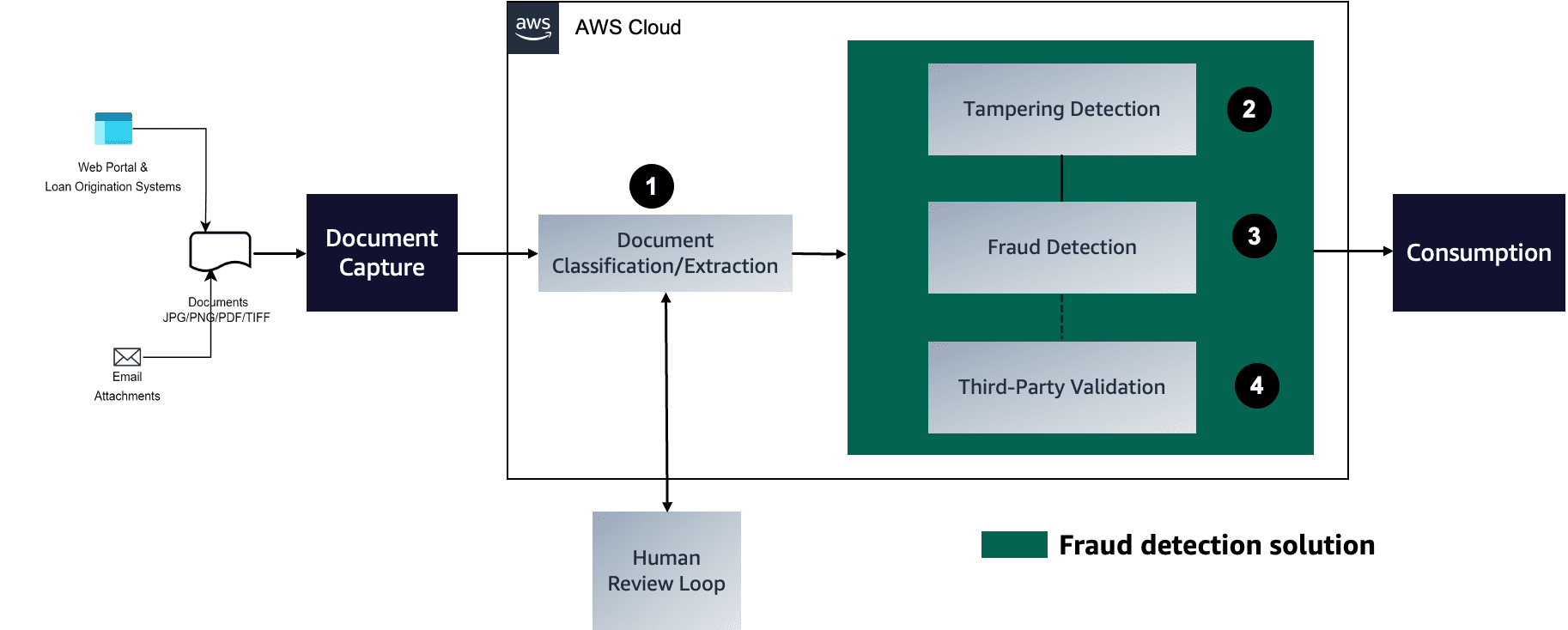
We will now be covering the third component of the mortgage document fraud detection pipeline. The steps to deploy this component are as follows:
- Upload historical data to Amazon Simple Storage Service (Amazon S3).
- Select your options and train the model.
- Create the model.
- Review model performance.
- Deploy the model.
- Create a detector.
- Add rules to interpret model scores.
- Deploy the API to make predictions.
Prerequisites
The following are prerequisite steps for this solution:
- Sign up for an AWS account.
- Set up permissions that allows your AWS account to access Amazon Fraud Detector.
- Collect the historical fraud data to be used to train the fraud detector model, with the following requirements:
- Data must be in CSV format and have headers.
- Two headers are required:
EVENT_TIMESTAMPandEVENT_LABEL. - Data must reside in Amazon S3 in an AWS Region supported by the service.
- It’s highly recommended to run a data profile before you train (use an automated data profiler for Amazon Fraud Detector).
- It’s recommended to use at least 3–6 months of data.
- It takes time for fraud to mature; data that is 1–3 months old is recommended (not too recent).
- Some NULLs and missing values are acceptable (but too many and the variable is ignored, as discussed in Missing or incorrect variable type).
Upload historical data to Amazon S3
After you have the custom historical data files to train a fraud detector model, create an S3 bucket and upload the data to the bucket.
Select options and train the model
The next step towards building and training a fraud detector model is to define the business activity (event) to evaluate for the fraud. Defining an event involves setting the variables in your dataset, an entity initiating the event, and the labels that classify the event.
Complete the following steps to define a docfraud event to detect document fraud, which is initiated by the entity applicant mortgage, referring to a new mortgage application:
- On the Amazon Fraud Detector console, choose Events in the navigation pane.
- Choose Create.
- Under Event type details, enter
docfraudas the event type name and, optionally, enter a description of the event. - Choose Create entity.
- On the Create entity page, enter
applicant_mortgageas the entity type name and, optionally, enter a description of the entity type. - Choose Create entity.
- Under Event variables, for Choose how to define this event’s variables, choose Select variables from a training dataset.
- For IAM role, choose Create IAM role.
- On the Create IAM role page, enter the name of the S3 bucket with your example data and choose Create role.
- For Data location, enter the path to your historical data. This is the S3 URI path that you saved after uploading the historical data. The path is similar to
S3://your-bucket-name/example dataset filename.csv. - Choose Upload.
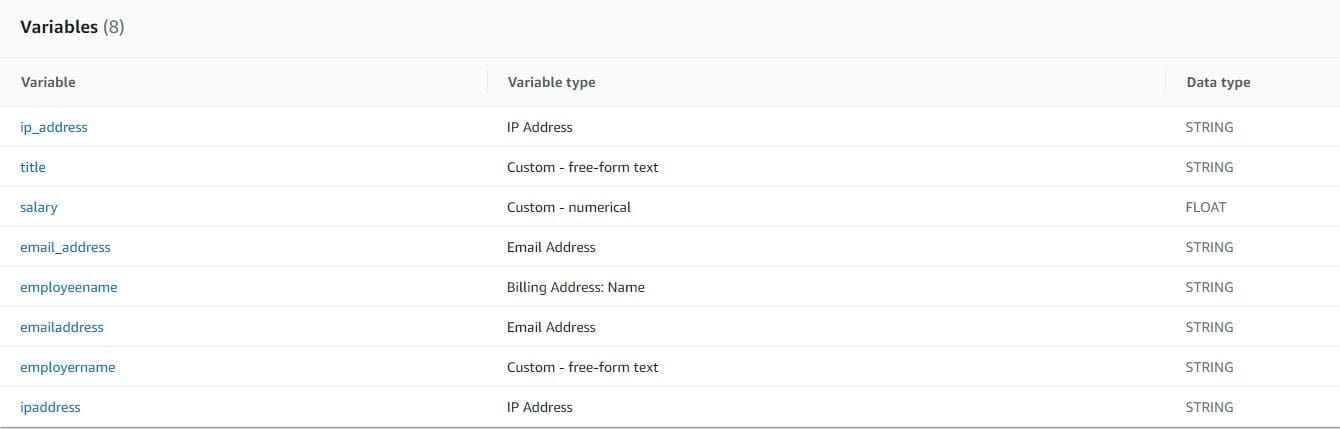
Variables represent data elements that you want to use in a fraud prediction. These variables can be taken from the event dataset that you prepared for training your model, from your Amazon Fraud Detector model’s risk score outputs, or from Amazon SageMaker models. For more information about variables taken from the event dataset, see Get event dataset requirements using the Data models explorer.
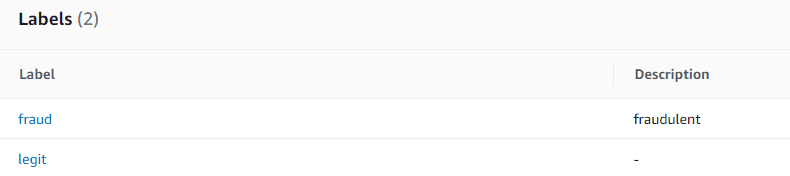
- Under Labels – optional, for Labels, choose Create new labels.
- On the Create label page, enter
fraudas the name. This label corresponds to the value that represents the fraudulent mortgage application in the example dataset. - Choose Create label.
- Create a second label called
legit. This label corresponds to the value that represents the legitimate mortgage application in the example dataset. - Choose Create event type.
The following screenshot shows our event type details.

The following screenshot shows our variables.
The following screenshot shows our labels.
Create the model
After you have loaded the historical data and selected the required options to train a model, complete the following steps to create a model:
- On the Amazon Fraud Detector console, choose Models in the navigation pane.
- Choose Add model, and then choose Create model.
- On the Define model details page, enter
mortgage_fraud_detection_modelas the model’s name and an optional description of the model. - For Model type, choose the Online Fraud Insights model.
- For Event type, choose
docfraud. This is the event type that you created earlier. - In the Historical event data section, provide the following information:
- For Event data source, choose Event data stored uploaded to S3 (or AFD).
- For IAM role, choose the role that you created earlier.
- For Training data location, enter the S3 URI path to your example data file.
- Choose Next.
- In the Model inputs section, leave all checkboxes checked. By default, Amazon Fraud Detector uses all variables from your historical event dataset as model inputs.
- In the Label classification section, for Fraud labels, choose
fraud, which corresponds to the value that represents fraudulent events in the example dataset. - For Legitimate labels, choose
legit, which corresponds to the value that represents legitimate events in the example dataset. - For Unlabeled events, keep the default selection Ignore unlabeled events for this example dataset.
- Choose Next.
- Review your settings, then choose Create and train model.
Amazon Fraud Detector creates a model and begins to train a new version of the model.
On the Model versions page, the Status column indicates the status of model training. Model training that uses the example dataset takes approximately 45 minutes to complete. The status changes to Ready to deploy after model training is complete.
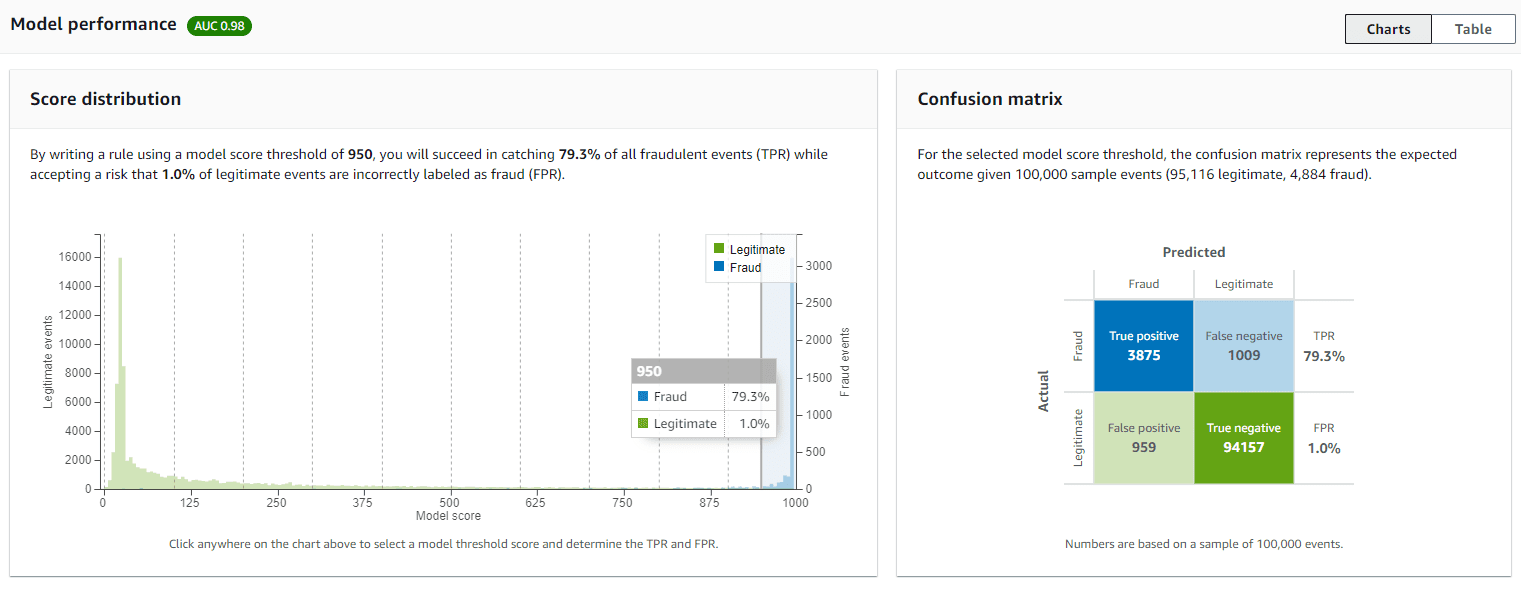
Review model performance
After the model training is complete, Amazon Fraud Detector validates the model performance using 15% of your data that was not used to train the model and provides various tools, including a score distribution chart and confusion matrix, to assess model performance.
To view the model’s performance, complete the following steps:
- On the Amazon Fraud Detector console, choose Models in the navigation pane.
- Choose the model that you just trained (
sample_fraud_detection_model), then choose 1.0. This is the version Amazon Fraud Detector created of your model. - Review the Model performance overall score and all other metrics that Amazon Fraud Detector generated for this model.
Deploy the model
After you have reviewed the performance metrics of your trained model and are ready to use it generate fraud predictions, you can deploy the model:
- On the Amazon Fraud Detector console, choose Models in the navigation pane.
- Choose the model
sample_fraud_detection_model, and then choose the specific model version that you want to deploy. For this post, choose 1.0. - On the Model version page, on the Actions menu, choose Deploy model version.
On the Model versions page, the Status shows the status of the deployment. The status changes to Active when the deployment is complete. This indicates that the model version is activated and available to generate fraud predictions.
Create a detector
After you have deployed the model, you build a detector for the docfraud event type and add the deployed model. Complete the following steps:
- On the Amazon Fraud Detector console, choose Detectors in the navigation pane.
- Choose Create detector.
- On the Define detector details page, enter
fraud_detectorfor the detector name and, optionally, enter a description for the detector, such as my sample fraud detector. - For Event Type, choose
docfraud. This is the event that you created in earlier. - Choose Next.
Add rules to interpret
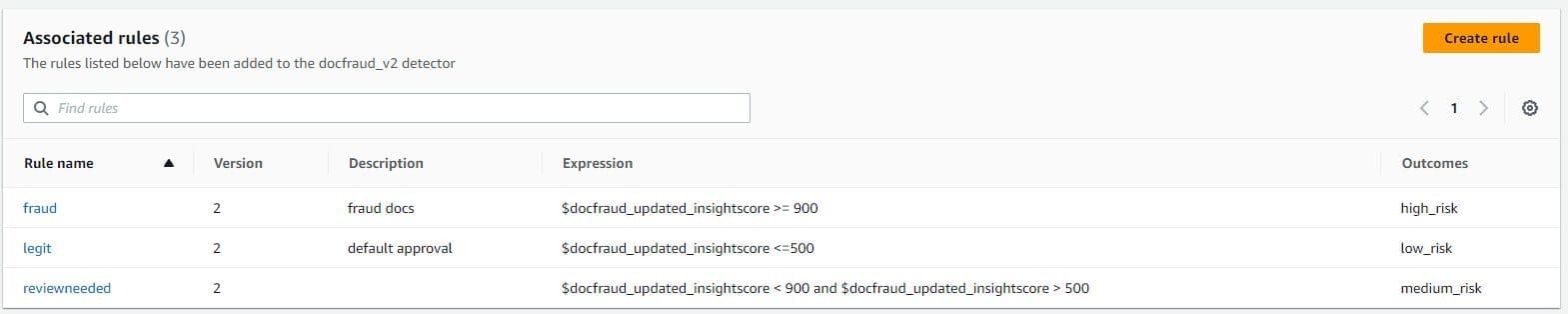
After you have created the Amazon Fraud Detector model, you can use the Amazon Fraud Detector console or application programming interface (API) to define business-driven rules (conditions that tell Amazon Fraud Detector how to interpret model performance score when evaluating for fraud prediction). To align with the mortgage underwriting process, you may create rules to flag mortgage applications according to the risk levels associated and mapped as fraud, legitimate, or if a review is needed.
For example, you may want to automatically decline mortgage applications with a high fraud risk, considering parameters like tampered images of the required documents, missing documents like paystubs or income requirements, and so on. On the other hand, certain applications may need a human in the loop for making effective decisions.
Amazon Fraud Detector uses the aggregated value (calculated by combining a set of raw variables) and raw value (the value provided for the variable) to generate the model scores. The model scores can be between 0–1000, where 0 indicates low fraud risk and 1000 indicates high fraud risk.
To add the respective business-driven rules, complete the following steps:
- On the Amazon Fraud Detector console, choose Rules in the navigation pane.
- Choose Add rule.
- In the Define a rule section, enter fraud for the rule name and, optionally, enter a description.
- For Expression, enter the rule expression using the Amazon Fraud Detector simplified rule expression language
$docdraud_insightscore >= 900 - For Outcomes, choose Create a new outcome (An outcome is the result from a fraud prediction and is returned if the rule matches during an evaluation.)
- In the Create a new outcome section, enter decline as the outcome name and an optional description.
- Choose Save outcome
- Choose Add rule to run the rule validation checker and save the rule.
- After it’s created, Amazon Fraud Detector makes the following
high_riskrule available for use in your detector.- Rule name:
fraud - Outcome:
decline - Expression:
$docdraud_insightscore >= 900
- Rule name:
- Choose Add another rule, and then choose the Create rule tab to add additional 2 rules as below:
- Create a
low_riskrule with the following details:- Rule name:
legit - Outcome:
approve - Expression:
$docdraud_insightscore <= 500
- Rule name:
- Create a
medium_riskrule with the following details:- Rule name:
review needed - Outcome:
review - Expression:
$docdraud_insightscore <= 900 and docdraud_insightscore >=500
- Rule name:
These values are examples used for this post. When you create rules for your own detector, use values that are appropriate for your model and use case.
- After you have created all three rules, choose Next.
Deploy the API to make predictions
After the rules-based actions have been triggered, you can deploy an Amazon Fraud Detector API to evaluate the lending applications and predict potential fraud. The predictions can be performed in a batch or real time.

Integrate your SageMaker model (Optional)
If you already have a fraud detection model in SageMaker, you can integrate it with Amazon Fraud Detector for your preferred results.
This implies that you can use both SageMaker and Amazon Fraud Detector models in your application to detect different types of fraud. For example, your application can use the Amazon Fraud Detector model to assess the fraud risk of customer accounts, and simultaneously use your PageMaker model to check for account compromise risk.
Clean up
To avoid incurring any future charges, delete the resources created for the solution, including the following:
- S3 bucket
- Amazon Fraud Detector endpoint
Conclusion
This post walked you through an automated and customized solution to detect fraud in the mortgage underwriting process. This solution allows you to detect fraudulent attempts closer to the time of fraud occurrence and helps underwriters with an effective decision-making process. Additionally, the flexibility of the implementation allows you to define business-driven rules to classify and capture the fraudulent attempts customized to specific business needs.
For more information about building an end-to-end mortgage document fraud detection solution, refer to Part 1 and Part 2 in this series.
About the authors
 Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada working with Financial Services organizations. He helps customers to transform their businesses and innovate on cloud.
Anup Ravindranath is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada working with Financial Services organizations. He helps customers to transform their businesses and innovate on cloud.
 Vinnie Saini is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. She has been helping Financial Services customers transform on cloud, with AI and ML driven solutions laid on strong foundational pillars of Architectural Excellence.
Vinnie Saini is a Senior Solutions Architect at Amazon Web Services (AWS) based in Toronto, Canada. She has been helping Financial Services customers transform on cloud, with AI and ML driven solutions laid on strong foundational pillars of Architectural Excellence.
Leave a Reply