
Evaluation of generative AI techniques for clinical report summarization
In part 1 of this blog series, we discussed how a large language model (LLM) available on Amazon SageMaker JumpStart can be fine-tuned for the task of radiology report impression generation. Since then, Amazon Web Services (AWS) has introduced new services such as Amazon Bedrock. This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API.
Amazon Bedrock also comes with a broad set of capabilities required to build generative AI applications with security, privacy, and responsible AI. It’s serverless, so you don’t have to manage any infrastructure. You can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. In this part of the blog series, we review techniques of prompt engineering and Retrieval Augmented Generation (RAG) that can be employed to accomplish the task of clinical report summarization by using Amazon Bedrock.
When summarizing healthcare texts, pre-trained LLMs do not always achieve optimal performance. LLMs can handle complex tasks like math problems and commonsense reasoning, but they are not inherently capable of performing domain-specific complex tasks. They require guidance and optimization to extend their capabilities and broaden the range of domain-specific tasks they can perform effectively. It can be achieved through the use of proper guided prompts. Prompt engineering helps to effectively design and improve prompts to get better results on different tasks with LLMs. There are many prompt engineering techniques.
In this post, we provide a comparison of results obtained by two such techniques: zero-shot and few-shot prompting. We also explore the utility of the RAG prompt engineering technique as it applies to the task of summarization. Evaluating LLMs is an undervalued part of the machine learning (ML) pipeline. It is time-consuming but, at the same time, critical. We benchmark the results with a metric used for evaluating summarization tasks in the field of natural language processing (NLP) called Recall-Oriented Understudy for Gisting Evaluation (ROUGE). These metrics will assess how well a machine-generated summary compares to one or more reference summaries.
Solution overview
In this post, we start with exploring a few of the prompt engineering techniques that will help assess the capabilities and limitations of LLMs for healthcare-specific summarization tasks. For more complex, clinical knowledge-intensive tasks, it’s possible to build a language model–based system that accesses external knowledge sources to complete the tasks. This enables more factual consistency, improves the reliability of the generated responses, and helps to mitigate the propensity that LLMs have to be confidently wrong, called hallucination.
Pre-trained language models
In this post, we experimented with Anthropic’s Claude 3 Sonnet model, which is available on Amazon Bedrock. This model is used for the clinical summarization tasks where we evaluate the few-shot and zero-shot prompting techniques. This post then seeks to assess whether prompt engineering is more performant for clinical NLP tasks compared to the RAG pattern and fine-tuning.
Dataset
The MIMIC Chest X-ray (MIMIC-CXR) Database v2.0.0 is a large publicly available dataset of chest radiographs in DICOM format with free-text radiology reports. We used the MIMIC CXR dataset, which can be accessed through a data use agreement. This requires user registration and the completion of a credentialing process.
During routine clinical care clinicians trained in interpreting imaging studies (radiologists) will summarize their findings for a particular study in a free-text note. Radiology reports for the images were identified and extracted from the hospital’s electronic health records (EHR) system. The reports were de-identified using a rule-based approach to remove any protected health information.
Because we used only the radiology report text data, we downloaded just one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR website. For evaluation, the 2,000 reports (referred to as the ‘dev1’ dataset) from a subset of this dataset and the 2,000 radiology reports (referred to as ‘dev2’) from the chest X-ray collection from the Indiana University hospital network were used.
Techniques and experimentation
Prompt design is the technique of creating the most effective prompt for an LLM with a clear objective. Crafting a successful prompt requires a deeper understanding of the context, it’s the subtle art of asking the right questions to elicit the desired answers. Different LLMs may interpret the same prompt differently, and some may have specific keywords with particular meanings. Also, depending on the task, domain-specific knowledge is crucial in prompt creation. Finding the perfect prompt often involves a trial-and-error process.
Prompt structure
Prompts can specify the desired output format, provide prior knowledge, or guide the LLM through a complex task. A prompt has three main types of content: input, context, and examples. The first of these specifies the information for which the model needs to generate a response. Inputs can take various forms, such as questions, tasks, or entities. The latter two are optional parts of a prompt. Context is providing relevant background to ensure the model understands the task or query, such as the schema of a database in the example of natural language querying. Examples can be something like adding an excerpt of a JSON file in the prompt to coerce the LLM to output the response in that specific format. Combined, these components of a prompt customize the response format and behavior of the model.
Prompt templates are predefined recipes for generating prompts for language models. Different templates can be used to express the same concept. Hence, it is essential to carefully design the templates to maximize the capability of a language model. A prompt task is defined by prompt engineering. Once the prompt template is defined, the model generates multiple tokens that can fill a prompt template. For instance, “Generate radiology report impressions based on the following findings and output it within <impression> with tokens.
Zero-shot prompting
Zero-shot prompting means providing a prompt to a LLM without any (zero) examples. With a single prompt and no examples, the model should still generate the desired result. This technique makes LLMs useful for many tasks. We have applied zero-shot technique to generate impressions from the findings section of a radiology report.
In clinical use cases, numerous medical concepts need to be extracted from clinical notes. Meanwhile, very few annotated datasets are available. It’s important to experiment with different prompt templates to get better results. An example zero-shot prompt used in this work is shown in Figure 1.

Figure 1 – Zero-shot prompting
Few-shot prompting
The few-shot prompting technique is used to increase performance compared to the zero-shot technique. Large, pre-trained models have demonstrated remarkable capabilities in solving an abundance of tasks by being provided only a few examples as context. This is known as in-context learning, through which a model learns a task from a few provided examples, specifically during prompting and without tuning the model parameters. In the healthcare domain, this bears great potential to vastly expand the capabilities of existing AI models.

Figure 2 – Few-shot prompting
Few-shot prompting uses a small set of input-output examples to train the model for specific tasks. The benefit of this technique is that it doesn’t require large amounts of labeled data (examples) and performs reasonably well by providing guidance to large language models.
In this work, five examples of findings and impressions were provided to the model for few-shot learning as shown in Figure 2.
Retrieval Augmented Generation pattern
The RAG pattern builds on prompt engineering. Instead of a user providing relevant data, an application intercepts the user’s input. The application searches across a data repository to retrieve content relevant to the question or input. The application feeds this relevant data to the LLM to generate the content. A modern healthcare data strategy enables the curation and indexing of enterprise data. The data can then be searched and used as context for prompts or questions, assisting an LLM in generating responses.
To implement our RAG system, we utilized a dataset of 95,000 radiology report findings-impressions pairs as the knowledge source. This dataset was uploaded to Amazon Simple Service (Amazon S3) data source and then ingested using Knowledge Bases for Amazon Bedrock. We used the Amazon Titan Text Embeddings model on Amazon Bedrock to generate vector embeddings.
Embeddings are numerical representations of real-world objects that ML systems use to understand complex knowledge domains like humans do. The output vector representations were stored in a newly created vector store for efficient retrieval from the Amazon OpenSearch Serverless vector search collection. This leads to a public vector search collection and vector index setup with the required fields and necessary configurations. With the infrastructure in place, we set up a prompt template and use RetrieveandGenerate API for vector similarity search. Then, we use the Anthropic Claude 3 Sonnet model for impressions generation. Together, these components enabled both precise document retrieval and high-quality conditional text generation from the findings-to-impressions dataset.
The following reference architecture diagram in Figure 3 illustrates the fully managed RAG pattern with Knowledge Bases for Amazon Bedrock on AWS. The fully managed RAG provided by Knowledge Bases for Amazon Bedrock converts user queries into embeddings, searches the knowledge base, obtains relevant results, augments the prompt, and then invokes an LLM (Claude 3 Sonnet) to generate the response.
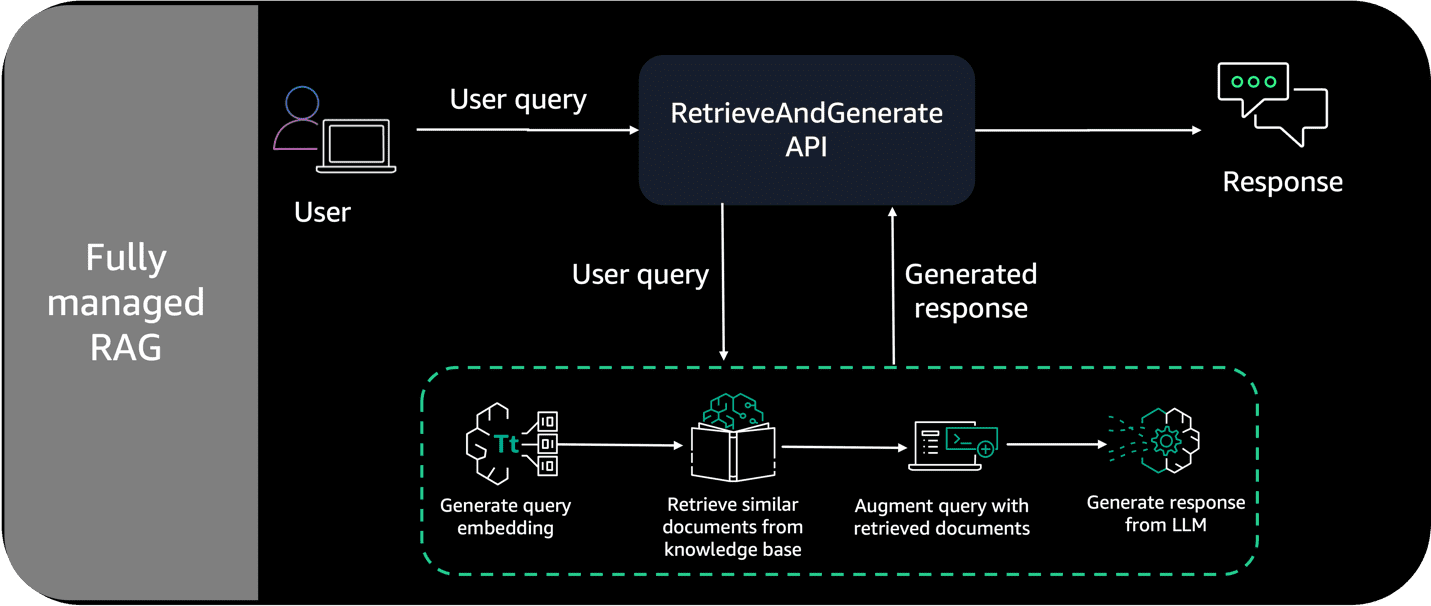
Figure 3 – Retrieval Augmented Generation pattern
Prerequisites
You need to have the following to run this demo application:
- An AWS account
- Basic understanding of how to navigate Amazon SageMaker Studio
- Basic understanding of how to download a repo from GitHub
- Basic knowledge of running a command on a terminal
Key steps in implementation
Following are key details of each technique
Zero-shot prompting
- Load the reports into the Amazon Bedrock knowledge base by connecting to the S3 bucket (data source).
- The knowledge base will split them into smaller chunks (based on the strategy selected), generate embeddings, and store them in the associated vector store. For detailed steps, refer to the Amazon Bedrock User Guide. We used Amazon Titan Embeddings G1 – Text embedding model for converting the reports data to embeddings.
- Once the knowledge base is up and running, locate the knowledge base id and generate model Amazon Resource Number (ARN) for Claude 3 Sonnet model using the following code:
- Set up the Amazon Bedrock runtime client using the latest version of AWS SDK for Python (Boto3).
- Use the RetrieveAndGenerate API to retrieve the most relevant report from the knowledge base and generate an impression.
- Use the following prompt template along with query (findings) and retrieval results to generate impressions with the Claude 3 Sonnet LLM.
Evaluation
Performance analysis
The performance of zero-shot, few-shot, and RAG techniques is evaluated using the ROUGE score. For more details on the definition of various forms of this score, please refer to part 1 of this blog.
The following table depicts the evaluation results for the dev1 and dev2 datasets. The evaluation result on dev1 (2,000 findings from the MIMIC CXR Radiology Report) shows that the zero-shot prompting performance was the poorest, whereas the RAG approach for report summarization performed the best. The use of the RAG technique led to substantial gains in performance, improving the aggregated average ROUGE1 and ROUGE2 scores by approximately 18 and 16 percentage points, respectively, compared to the zero-shot prompting method. An approximately 8 percentage point improvement is observed in aggregated ROUGE1 and ROUGE2 scores over the few-shot prompting technique.
| Model | Technique | Dataset: dev1 | Dataset: dev2 | ||||||
| . | . | ROUGE1 | ROUGE2 | ROUGEL | ROUGELSum | ROUGE1 | ROUGE2 | ROUGEL | ROUGELSum |
| Claude 3 | Zero-shot | 0.242 | 0.118 | 0.202 | 0.218 | 0.210 | 0.095 | 0.185 | 0.194 |
| Claude 3 | Few-shot | 0.349 | 0.204 | 0.309 | 0.312 | 0.439 | 0.273 | 0.351 | 0.355 |
| Claude 3 | RAG | 0.427 | 0.275 | 0.387 | 0.387 | 0.438 | 0.309 | 0.43 | 0.43 |
For dev2, an improvement of approximately 23 and 21 percentage points is observed in ROUGE1 and ROUGE2 scores of the RAG-based technique over zero-shot prompting. Overall, RAG led to an improvement of approximately 17 percentage points and 24 percentage points in ROUGELsum scores for the dev1 and dev2 datasets, respectively. The distribution of ROUGE scores attained by RAG technique for dev1 and dev2 datasets is shown in the following graphs.
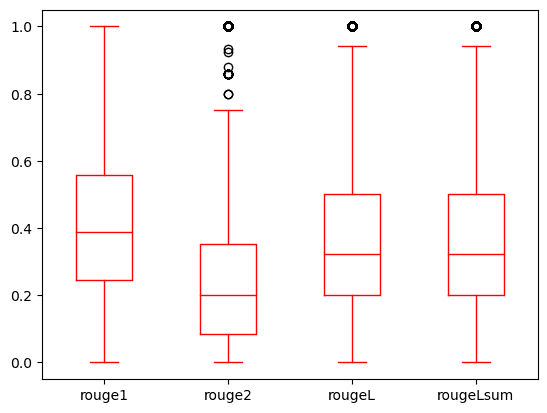 |
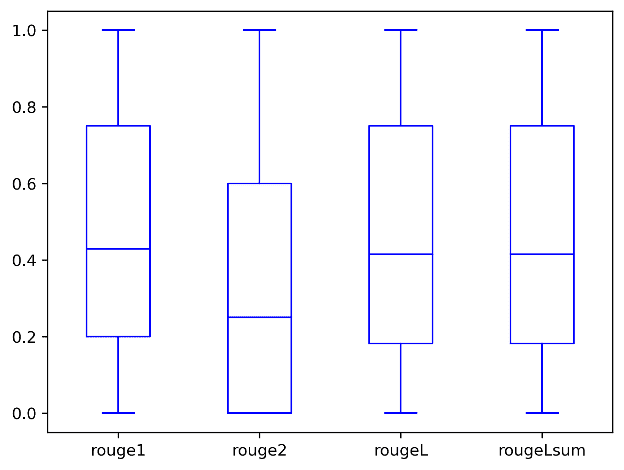 |
| Dataset: dev1 | Dataset: dev2 |
It is worth noting that RAG attains consistent average ROUGELSum for both test datasets (dev1=.387 and dev2=.43). This is in contrast to the average ROUGELSum for these two test datasets (dev1=.5708 and dev2=.4525) attained with the fine-tuned FLAN-T5 XL model presented in part 1 of this blog series. Dev1 is a subset of the MIMIC dataset, samples from which have been used as context. With the RAG approach, the median ROUGELsum is observed to be almost similar for both datasets dev2 and dev1.
Overall, RAG is observed to attain good ROUGE scores but falls short of the impressive performance of the fine-tuned FLAN-T5 XL model presented in part 1 of this blog series.
Cleanup
To avoid incurring future charges, delete all the resources you deployed as part of the tutorial.
Conclusion
In this post, we presented how various generative AI techniques can be applied for healthcare-specific tasks. We saw incremental improvement in results for domain-specific tasks as we evaluated and compared prompting techniques and the RAG pattern. We also see how fine-tuning the model to healthcare-specific data is comparatively better, as demonstrated in part 1 of the blog series. We expect to see significant improvements with increased data at scale, more thoroughly cleaned data, and alignment to human preference through instruction tuning or explicit optimization for preferences.
Limitations: This work demonstrates a proof of concept. As we analyzed deeper, hallucinations were observed occasionally.
About the authors
 Ekta Walia Bhullar, PhD, is a senior AI/ML consultant with AWS Healthcare and Life Sciences (HCLS) professional services business unit. She has extensive experience in the application of AI/ML within the healthcare domain, especially in radiology. Outside of work, when not discussing AI in radiology, she likes to run and hike.
Ekta Walia Bhullar, PhD, is a senior AI/ML consultant with AWS Healthcare and Life Sciences (HCLS) professional services business unit. She has extensive experience in the application of AI/ML within the healthcare domain, especially in radiology. Outside of work, when not discussing AI in radiology, she likes to run and hike.
 Priya Padate is a Senior Partner Solutions Architect with extensive expertise in Healthcare and Life Sciences at AWS. Priya drives go-to-market strategies with partners and drives solution development to accelerate AI/ML-based development. She is passionate about using technology to transform the healthcare industry to drive better patient care outcomes.
Priya Padate is a Senior Partner Solutions Architect with extensive expertise in Healthcare and Life Sciences at AWS. Priya drives go-to-market strategies with partners and drives solution development to accelerate AI/ML-based development. She is passionate about using technology to transform the healthcare industry to drive better patient care outcomes.
 Dr. Adewale Akinfaderin is a senior data scientist in healthcare and life sciences at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global healthcare customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
Dr. Adewale Akinfaderin is a senior data scientist in healthcare and life sciences at AWS. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global healthcare customers formulate and develop scalable solutions to interdisciplinary problems. He has two graduate degrees in physics and a doctorate in engineering.
 Srushti Kotak is an Associate Data and ML Engineer at AWS Professional Services. She has a strong data science and deep learning background with experience in developing machine learning solutions, including generative AI solutions, to help customers solve their business challenges. In her spare time, Srushti loves to dance, travel, and spend time with friends and family.
Srushti Kotak is an Associate Data and ML Engineer at AWS Professional Services. She has a strong data science and deep learning background with experience in developing machine learning solutions, including generative AI solutions, to help customers solve their business challenges. In her spare time, Srushti loves to dance, travel, and spend time with friends and family.
Leave a Reply