
Faster LLMs with speculative decoding and AWS Inferentia2
In recent years, we have seen a big increase in the size of large language models (LLMs) used to solve natural language processing (NLP) tasks such as question answering and text summarization. Larger models with more parameters, which are in the order of hundreds of billions at the time of writing, tend to produce better results. For example, Llama-3-70B, scores better than its smaller 8B parameters version on metrics like reading comprehension (SQuAD 85.6 compared to 76.4). Thus, customers often experiment with larger and newer models to build ML-based products that bring value.
However, the larger the model, the more computationally demanding it is, and the higher the cost to deploy. For example, on AWS Trainium, Llama-3-70B has a median per-token latency of 21.4 ms, while Llama-3-8B takes 4.7 ms. Similarly, Llama-2-70B has a median per-token latency of 20.6 ms, while Llama-2-7B takes 3.7 ms. Customers have to consider performance to ensure they meet their users’ needs. In this blog post, we will explore how speculative sampling can help make large language model inference more compute efficient and cost-effective on AWS Inferentia and Trainium. This technique improves LLM inference throughput and output token latency (TPOT).
Introduction
Modern language models are based on the transformer architecture. The input prompts are processed first using a technique called context encoding, which runs fast because it is parallelizable. Next, we perform auto-regressive token generation where the output tokens are generated sequentially. Note that we cannot generate the next token until we know the previous one, as depicted in Figure 1. Therefore, to generate N output tokens we need N serial runs through the decoder. A run takes longer through a larger model, like Llama-3-70B, than through a smaller model, like Llama-3-8B.

Figure 1: Sequential token generation in LLMs
From a computational perspective, token generation in LLMs is a memory bandwidth-bound process. The larger the model, the more likely it is that we will wait on memory transfers. This results in underutilizing the compute units and not fully benefiting from the floating-point operations (FLOPS) available.
Speculative sampling
Speculative sampling is a technique that improves the computational efficiency for running inference with LLMs, while maintaining accuracy. It works by using a smaller, faster draft model to generate multiple tokens, which are then verified by a larger, slower target model. This verification step processes multiple tokens in a single pass rather than sequentially and is more compute efficient than processing tokens sequentially. Increasing the number of tokens processed in parallel increases the compute intensity because a larger number of tokens can be multiplied with the same weight tensor. This provides better performance compared with the non-speculative run, which is usually memory bandwidth-bound, and thus leads to better hardware resource utilization.
The speculative process involves an adjustable window k, where the target model provides one guaranteed correct token, and the draft model speculates on the next k-1 tokens. If the draft model’s tokens are accepted, the process speeds up. If not, the target model takes over, ensuring accuracy.
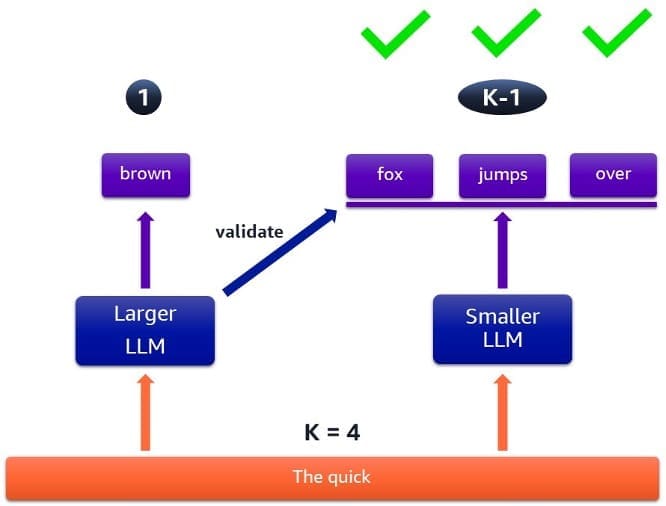
Figure 2: Case when all speculated tokens are accepted
Figure 2 illustrates a case where all speculated tokens are accepted, resulting in faster processing. The target model provides a guaranteed output token, and the draft model runs multiple times to produce a sequence of possible output tokens. These are verified by the target model and subsequently accepted by a probabilistic method.
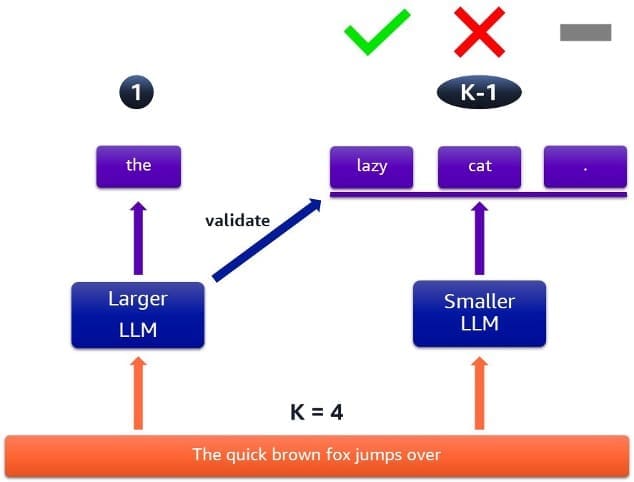
Figure 3: Case when some speculated tokens are rejected
On the other hand, Figure 3 shows a case where some of the tokens are rejected. The time it takes to run this speculative sampling loop is the same as in Figure 2, but we obtain fewer output tokens. This means we will be repeating this process more times to complete the response, resulting in slower overall processing.
By adjusting the window size k and understanding when the draft and target models are likely to produce similar results, we can maximize the benefits of speculative sampling.
A Llama-2-70B/7B demonstration
We will show how speculative sampling works on Inferentia2-powered Amazon EC2 Inf2 instances and Trainium-powered EC2 Trn1 instances. We will be using a sample where we generate text faster with Llama-2-70B by using a Llama-2-7B model as a draft model. The example walk-through is based on Llama-2 models, but you can follow a similar process for Llama-3 models as well.
Loading models
You can load the Llama-2 models using data type bfloat16. The draft model needs to be loaded in a standard way like in the example below. The parameter n_positions is adjustable and represents the maximum sequence length you want to allow for generation. The only batch_size we support for speculative sampling at the time of writing is 1. We will explain tp_degree later in this section.
The target model should be loaded in a similar way, but with speculative sampling functionality enabled. The value k was described previously.
Combined, the two models need almost 200 GB of device memory for the weights with additional memory in the order of GBs needed for key-value (KV) caches. If you prefer to use the models with float32 parameters, they will need around 360 GB of device memory. Note that the KV caches grow linearly with sequence length (input tokens + tokens yet to be generated). Use neuron-top to see the memory utilization live. To accommodate for these memory requirements, we’ll need either the largest Inf2 instance (inf2.48xlarge) or largest Trn1 instance (trn1.32xlarge).
Because of the size of the models, their weights need to be distributed amongst the NeuronCores using a technique called tensor parallelism. Notice that in the sample provided, tp_degree is used per model to specify how many NeuronCores that model should use. This, in turn, affects the memory bandwidth utilization, which is critical for token generation performance. A higher tp_degree can lead to better bandwidth utilization and improved throughput. The topology for Trn1 requires that tp_degree is set to 1, 2, 8, 16 or a multiple of 32. For Inf2, it needs to be 1 or multiples of 2.
The order in which you load the models also matters. After a set of NeuronCores has been initialized and allocated for one model, you cannot use the same NeuronCores for another model unless it’s the exact same set. If you try to use only some of the NeuronCores that were previously initialized, you will get an nrt_load_collectives - global nec_comm is already init'd error.
Let’s go through two examples on trn1.32xlarge (32 NeuronCores) to understand this better. We will calculate how many NeuronCores we need per model. The formula used is the observed model size in memory, using neuron-top, divided by 16GB which is the device memory per NeuronCore.
- If we run the models using bfloat16, we need more than 10 NeuronCores for Llama-2-70B and more than 2 NeuronCores for Llama-2-7B. Because of topology constraints, it means we need at least
tp_degree=16for Llama-2-70B. We can use the remaining 16 NeuronCores for Llama-2-7B. However, because both models fit in memory across 32 NeuronCores, we should settp_degree=32for both, to speed-up the model inference for each. - If we run the models using float32, we need more than 18 NeuronCores for Llama-2-70B and more than 3 NeuronCores for Llama-2-7B. Because of topology constraints, we have to set
tp_degree=32for Llama-2-70B. That means Llama-2-7B needs to re-use the same set of NeuronCores, so you need to settp_degree=32for Llama-2-7B too.
Walkthrough
The decoder we’ll use from transformers-neuronx is LlamaForSampling, which is suitable for loading and running Llama models. You can also use NeuronAutoModelForCausalLM which will attempt to auto-detect which decoder to use. To perform speculative sampling, we need to create a speculative generator first which takes two models and the value k described previously.
We invoke the inferencing process by calling the following function:
During sampling, there are several hyper-parameters (for example: temperature, top_p, and top_k) that affect if the output is deterministic across multiple runs. At the time of writing, the speculative sampling implementation sets default values for these hyper-parameters. With these values, expect randomness in results when you run a model multiple times, even if it’s with the same prompt. This is normal intended behavior for LLMs because it improves their qualitative responses.
When you run the sample, you will use the default token acceptor, based on the DeepMind paper which introduced speculative sampling, which uses a probabilistic method to accept tokens. However, you can also implement a custom token acceptor, which you can pass as part of the acceptor parameter when you initialize the SpeculativeGenerator. You would do this if you wanted more deterministic responses, for example. See the implementation of the DefaultTokenAcceptor class in transformers-neuronx to understand how to write your own.
Conclusion
As more developers look to incorporate LLMs into their applications, they’re faced with a choice of using larger, more costly, and slower models that will deliver higher quality results. Or they can use smaller, less expensive and faster models that might reduce quality of answers. Now, with AWS artificial intelligence (AI) chips and speculative sampling, developers don’t have to make that choice. They can take advantage of the high-quality outputs of larger models and the speed and responsiveness of smaller models.
In this blog post, we have shown that we can accelerate the inference of large models, such as Llama-2-70B, by using a new feature called speculative sampling.
To try it yourself, check out the speculative sampling example, and tweak the input prompt and k parameter to see the results you get. For more advanced use cases, you can develop your own token acceptor implementation. To learn more about running your models on Inferentia and Trainium instances, see the AWS Neuron documentation. You can also visit repost.aws AWS Neuron channel to discuss your experimentations with the AWS Neuron community and share ideas.
About the Authors
 Syl Taylor is a Specialist Solutions Architect for Efficient Compute. She advises customers across EMEA on Amazon EC2 cost optimization and improving application performance using AWS-designed chips. Syl previously worked in software development and AI/ML for AWS Professional Services, designing and implementing cloud native solutions. She’s based in the UK and loves spending time in nature.
Syl Taylor is a Specialist Solutions Architect for Efficient Compute. She advises customers across EMEA on Amazon EC2 cost optimization and improving application performance using AWS-designed chips. Syl previously worked in software development and AI/ML for AWS Professional Services, designing and implementing cloud native solutions. She’s based in the UK and loves spending time in nature.
 Emir Ayar is a Senior Tech Lead Solutions Architect with the AWS Prototyping team. He specializes in assisting customers with building ML and generative AI solutions, and implementing architectural best practices. He supports customers in experimenting with solution architectures to achieve their business objectives, emphasizing agile innovation and prototyping. He lives in Luxembourg and enjoys playing synthesizers.
Emir Ayar is a Senior Tech Lead Solutions Architect with the AWS Prototyping team. He specializes in assisting customers with building ML and generative AI solutions, and implementing architectural best practices. He supports customers in experimenting with solution architectures to achieve their business objectives, emphasizing agile innovation and prototyping. He lives in Luxembourg and enjoys playing synthesizers.
Tags: Machine learning
Leave a Reply