
Efficiently train models with large sequence lengths using Amazon SageMaker model parallel
Large language models (LLMs) have witnessed an unprecedented surge in popularity, with customers increasingly using publicly available models such as Llama, Stable Diffusion, and Mistral. Across diverse industries—including healthcare, finance, and marketing—organizations are now engaged in pre-training and fine-tuning these increasingly larger LLMs, which often boast billions of parameters and larger input sequence length. Although these advancements offer remarkable capabilities, they also present significant challenges. Longer sequence lengths and the sheer number of trainable parameters demand innovative approaches to model development and deployment. To maximize performance and optimize training, organizations frequently need to employ advanced distributed training strategies.
In this post, we demonstrate how the Amazon SageMaker model parallel library (SMP) addresses this need through support for new features such as 8-bit floating point (FP8) mixed-precision training for accelerated training performance and context parallelism for processing large input sequence lengths, expanding the list of its existing features.
We guide you through a step-by-step implementation, demonstrating how to accelerate workloads with FP8 and work with longer sequence lengths using context parallelism, with minimal code changes to your existing training workflow.
The implementation of these new SMP features promises several advantages for customers working with LLMs. First, it can lead to lower costs to convergence, allowing for more efficient use of resources during the training process. This results in reduced time to market, allowing organizations to deploy their optimized models more quickly and gain a competitive edge. Second, it enables training with larger dataset records, expanding the scope and complexity of tasks that can be tackled.
The following sections take a deeper look into this.
Business challenge
Businesses today face a significant challenge when training LLMs efficiently and cost-effectively. As models grow larger and more complex, organizations are using fine-tuning and continuous pre-training strategies to train these models with domain-specific data, using larger sequence lengths that can range from 8K to 128K tokens. These longer sequence lengths allow models to better understand long-range dependencies in text, generate more globally coherent outputs, and handle tasks requiring analysis of lengthy documents.
Although there exist various strategies such as Fully Shared Data Parallelism (FSDP), tensor parallelism (TP), and pipeline parallelism to effectively train models with billions of parameters, these methods are primarily designed to distribute model parameters, gradients, and optimizer states across GPUs, and they don’t focus on input data–related optimizations. This approach reduces memory pressure and enables efficient training of large models. However, none of these techniques effectively address partitioning along the sequence dimension. As a result, training with longer sequence lengths can still lead to out-of-memory (OOM) errors, despite using FSDP.
As a result, working with larger sequence length might result in memory pressure, and it often requires innovative approaches such as FP8 and context parallelism.
How does SMP context parallelism and FP8 help accelerate model training?
SMP addresses the challenges of memory pressure by providing an implementation of context parallelism, which is a parallelization technique that partitions on the dimension of sequence length. Furthermore, it can work together with other parallelism techniques such as FSDP and TP. SMP also implements FP8 for supported models such as Llama. FP8 is a reduced-precision floating-point format that boosts efficiency by enabling faster matrix multiplications without significant accuracy loss. You can use these techniques together to train complex models that are orders of magnitude faster and rapidly iterate and deploy innovative AI solutions that drive business value.
The following sections dive deep into the implementation details for each of these features in SMP.
Context parallelism
Context parallelism is a model parallelism technique to allow the model to train with long sequences. It’s a parallelization scheme that partitions a model’s activations along the sequence dimension. During training with SMP context parallel strategy, the inputs are partitioned along the sequence dimension before being fed to the model. With activations being partitioned along the sequence dimension, we need to consider how our model’s computations are affected. For layers that don’t have inter-token dependency during computation, we don’t require special considerations. In a transformer architecture, such layers are the embedding layers and the multilayer perceptron (MLP) layers. The layers that have inter-token dependency are the attention layers. For the attention layer, as we see from the attention computation, Query projections (Q) need to interact with the tokens of key (K) and value (V) projections.
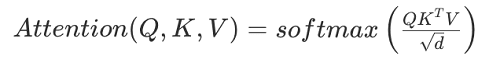
Because we only have a partition of K and V, we require an AllGather operation to collect the keys and queries from other ranks. As detailed in the following figure, we consider a context parallel scheme with context parallel degree 2 for a causal language model. Thus GPU 0 has the first half of the input sequence and GPU 1 has the other half. During forward, the non-attention layers compute their activations as normal. For attention computation, an AllGather operation is performed for K and V across the context parallel ranks belonging to GPU 0 and GPU 1. To conserve memory, the K and V tensors obtained from the AllGather operation are discarded after the attention computation is completed. Consequently, during the backward pass, we require the same AllGather operation for K and V. Additionally, after the attention backward pass, a ReduceScatter operation is performed to scatter the gradients to corresponding context parallel ranks.

Unlike other model parallel schemes such as tensor parallelism, context parallelism keeps the model parameters intact. Thus, there are no additional communication collectives for parameters required for context parallelism.
Supported models
SMP supports context parallelism using NVIDIA Transformer Engine, and it seamlessly integrates with other model parallelism techniques Fully Sharded Data Parallel and Tensor Parallelism. SMP v2.6 supports the Llama 3.1 (and prior Llama models) and Mistral model architectures for context parallelism.
Mixed Precision Training with FP8
As shown in figure below, FP8 is a datatype supported by NVIDIA’s H100 and H200 GPUs, enables efficient deep learning workloads. The FP8 format occupies only 8 bits of memory, half that of its BF16 or FP16 counterparts, significantly reducing computational costs for operations such as matrix multiplication. The compute throughput for running matrix operations such as multipliers and convolutions is significantly higher on 8-bit float tensors compared to 32-bit float tensors. FP8 precision reduces the data footprint and computational requirements, making it ideal for large-scale models where memory and speed are critical.

Delving deeper into FP8’s architecture, we discover two distinct subtypes: E4M3 and E5M2. The E4M3 configuration, with its 1 sign bit, 4 exponent bits, and 3 mantissa bits, offers superior precision but a limited dynamic range. This makes it ideal for the forward pass in model training. Conversely, E5M2, featuring 1 sign bit, 5 exponent bits, and 2 mantissa bits, boasts a broader dynamic range at the expense of reduced precision. This configuration excels in the backward pass, where precision is less critical, but a wider range proves advantageous.
The transition to mixed precision training with FP16 or BF16 has historically necessitated static or dynamic loss-scaling to address convergence issues that stemmed from reduced precision in gradient flow. This challenge is further amplified in FP8 due to its narrower range. To combat this, the Transformer Engine introduced an innovative solution called DelayedScaling. This technique selects scaling factors based on the maximum observed value for each tensor from previous iterations. Although DelayedScaling maximizes the performance benefits of FP8 computation, it does come with a memory overhead for storing the tensors’ maximum value history. However, despite the additional overhead, the improved throughput observed with 8-bit tensor computations make this approach valuable.
Supported models
SMP supports FP8 mixed precision training using NVIDIA Transformer Engine and keeps compatibility with PyTorch MixedPrecision. This means that you can use FP8 training for supported layers and half-precision using PyTorch Automatic Mixed Precision for others. SMP v2.6 supports the following model architectures for FP8 training: Llama 3.1 (and prior Llama models), Mixtral, and Mistral.
More details about FP8 can be found at FP8 Formats For Deep Learning.
Solution overview
We can use SMP with both Amazon SageMaker Model training jobs and Amazon SageMaker HyperPod.
For this post, we demonstrate SMP implementation on SageMaker trainings jobs.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. After they’re initiated, SageMaker training jobs spin up the cluster, provisioning the specified number and type of compute instances.
In our example, we use a single ml.p5.48xlarge instance, though we’re illustrating the use of four GPUs for demonstration purposes. The training data, securely stored in Amazon Simple Storage Service (Amazon S3), is copied to the cluster. Each record sequence (Seq0) is strategically split into multiple subsequences and assigned to each GPU in our cluster.
Our implementation uses the FP8 capabilities of SMP to execute model training on Nvidia H100 GPUs and showcases context parallelism capabilities. Because of the flexibility of SageMaker, you can scale your compute resources as needed, accommodating workloads across of a range of sizes. SageMaker creates a resilient training cluster, handles orchestration, closely monitors the infrastructure, and recovers from faults, providing a smooth and uninterrupted training experience. Furthermore, the SageMaker training jobs cost-effective design automatically terminates the cluster upon completion of the training job, with billing calculated down to the second of actual training time used. This combination of power, flexibility, and cost-efficiency makes SageMaker an ideal service for ML practitioners of all levels.
The following diagram shows the solution architecture.

The following walkthrough shows you how you can train a Llama 3.1 8B Instruct model using the PubMed tokenized dataset with a sequence length of approximately 16K tokens. We use SMP context parallelism implementation to enable training for this large sequence length. We compare two approaches: one without context parallelism and another one with it. This comparison highlights the importance of context parallelism when working with LLMs and datasets containing long sequences.
Additionally, we conduct a comparative run on p5.48xlarge instances with context parallelism enabled, both with FP8 enabled and disabled. This demonstration will showcase the incremental throughput benefits we can achieve by enabling FP8-based training alongside context parallelism.
In summary, the implementation follows these four steps:
- Set up libraries and process data
- Run training without context parallelism
- Run training with context parallelism enabled to track memory optimizations
- Run training with FP8 enabled to gain further performance
The following flow diagram shows these four steps.

Prerequisites
To perform the solution, you need to have the following prerequisites in place:
- Create a Hugging Face User Access Token and get access to the gated repository meta-llama/Llama-3.1-8B on Hugging Face.
- Request a Service Quota for 1x
p4d.24xlargeand 1xml.p5.48xlargeon Amazon SageMaker. To request a service quota increase, on the AWS Service Quotas console, choose AWS services, Amazon SageMaker, and then choose one ml.p4d.24xlarge and one ml.p5.48xlarge training job usage. - Create an AWS Identity and Access Management (IAM) role with managed policies
AmazonSageMakerFullAccess, AmazonEC2FullAccess to give required access to SageMaker to run the examples.
This walkthrough is for demonstration purposes only. You should adjust this to your specific security requirements for production. Adhere to the principle of least privilege while defining IAM policies in production.
- Create an Amazon SageMaker Studio domain (refer to Quick setup to Amazon SageMaker) to access Jupyter notebooks.
Solution walkthrough
To perform the solution, use the instructions in the following steps.
Set up libraries and process data
To set up libraries and process data, follow these instructions. The following flow diagram shows step 1 highlighted.

- Enter the following command to install the relevant HuggingFace and SageMaker libraries:
- Load the PubMed dataset and tokenize it
In this example, we use the PubMed Scientific Papers dataset, containing 133,215 biomedical research articles. For our experiment, we select 1,000 papers split 80/20 for training and validation. Using the Meta-LlaMA-3 tokenizer, we process each paper into sequences of 16,384 tokens.
The dataset undergoes two main processing steps: tokenization with Llama’s tokenizer and grouping into fixed-length chunks of 16,384 tokens using utility function group_texts. This uniform sequence length enables even distribution across GPUs while maintaining the natural structure of the scientific papers.
- Prepare data for the training job
In this section, we prepare the PubMed dataset for SageMaker training by managing data transfers to Amazon S3. Both training and validation splits are converted to JSON format and uploaded to designated S3 buckets, with separate paths for input data and output artifacts.
- Set up training hyper parameters
In this configuration, we define hyperparameters for training Llama on PubMed, covering memory optimizations, training parameters, model architecture settings, and performance tuning. Starting with conservative settings (batch size=1, BF16 precision), we establish a baseline configuration that will be modified to test different optimization strategies, particularly for context parallelism experiments.
Run training without context parallelism

To run training without context parallelism, follow these instructions. The following flow diagram shows step 2 highlighted.
In this setup, we configure a baseline training job by disabling context parallelism and FP8 features, while maximizing memory usage through FP32 precision and larger batch sizes. Each GPU processes the full 16,384 token sequence without splitting, and memory-saving features are disabled to demonstrate the limitations and potential memory constraints when running without advanced optimizations such as context parallelism and FP8.
The result of not using context parallelism with a large context width (16,384) means that we will get a CUDA out-of-memory error:
AlgorithmError: ExecuteUserScriptError: ExitCode 1 ErrorMessage “[rank3]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 7.83 GiB. GPU 3 has a total capacity of 39.38 GiB of which 5.53 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use.
Run training with context parallelism enabled to track memory optimizations

To run training with context parallelism enabled to track memory optimizations, follow these instructions. The following flow diagram shows step 3 highlighted.
In this configuration, we enable context parallelism while keeping FP8 disabled. By setting context parallel degree to 8, we distribute the 16,384 token sequence across all available GPUs for efficient processing. The setup includes essential context parallelism parameters and launches the training job in a background thread, allowing for unblocked notebook execution while maintaining clear job identification for comparison with other configurations.
The result of using context parallelism with such a large context width is that the job successfully completes, as shown in the following screenshot.

We also enabled delayed parameter initialization and hybrid sharding capabilities from SMP for both preceding configurations. Delayed parameter initialization allows initializing large models on a meta device without attaching data. This can resolve limited GPU memory issues when you first load the model. This approach is particularly useful for training LLMs with tens of billions of parameters, where even CPU memory might not be sufficient for initialization. Hybrid sharding is a memory saving technique that shards parameters within the hybrid shard degree (HSD) group and replicates parameters across groups. The HSD controls sharding across GPUs and can be set to an integer from 0 to world_size. This results in reduced communication volume because expensive AllGathers and ReduceScatters are only done within a node, which perform better for medium-sized models.
Run training with FP8 enabled to gain further performance

To run training with FP8 enabled to gain further memory performance, follow these instructions. The following flow diagram shows step 4 highlighted.
In this fully optimized configuration, we enable both context parallelism and FP8 training using a NVIDIA P5 instance (ml.p5.48xlarge). This setup combines sequence splitting across GPUs with FP8 precision training, creating a highly efficient training environment. Using P5 instances provides the necessary hardware support for FP8 computation, with the result that we can maximize the benefits of both memory-saving techniques.
Start training with context parallelism, without FP8 (on a P5 instance)
To do a fair comparison with and without FP8, we will do another run without FP8 but with context parallelism on a P5.48xlarge instance and compare the throughputs for both runs.
If we compare both runs, we can tell that the speed of the same context parallelism enabled job with FP8 is almost 10 times faster
With FP8, speed is around 14.6 samples/second, as shown in the following screenshot.

Without FP8, speed is around 1.4 samples/second, as shown in the following screenshot.

The following table depicts the throughput increment you get in each of the listed cases. All these cases are run on a P5.48xLarge.
The throughput may vary based on factors such as the context width or batch size. The following numbers are what we have observed in our testing.
| Configuration (ml.P5.48xlarge; CP on 8 GPUs, Train Batch Size 4) | Observed samples speed | Observed throughput |
| No context parallelism & No FP8 | torch.OutOfMemoryError: CUDA out of memory | torch.OutOfMemoryError: CUDA out of memory |
| Only Context Parallelism | 2.03 samples/sec | 247 TFLOPS/GPU |
| Context parallelism + FP8 | 3.05 samples/sec | 372 TFLOPS/GPU |
Cleanup
To clean up your resources to avoid incurring more charges, follow these steps:
- Delete any unused SageMaker Studio resources.
- Optionally, delete the SageMaker Studio domain.
- Delete any S3 buckets created
- Verify that your training job isn’t running anymore! To do so, on your SageMaker console, choose Training and check Training jobs.

To learn more about cleaning up your resources provisioned, check out Clean up.
Conclusion
In this post, we demonstrated the process of setting up and running training jobs for the PubMed dataset using the Llama 3.1 8B Instruct model, both with and without context parallelism. We also showcased how to enable FP8 based training for even faster throughputs.
Key takeaways:
- For datasets that have long sequence lengths, we observe that using context parallelism helps avoid OOM errors.
- For faster training, we can enable FP8 based training and combine it with context parallelism to get increased throughput times. In this notebook, we observed that the throughput goes up tenfold if we enable FP8 with context parallelism.
As next steps, try out the above example by following the notebook steps at sagemaker-distributed-training-workshop.
Special thanks to Roy Allela, Senior AI/ML Specialist Solutions Architect for his support on the launch of this post.
About the Authors
 Kanwaljit Khurmi is a Principal Worldwide Generative AI Solutions Architect at AWS. He collaborates with AWS product teams, engineering departments, and customers to provide guidance and technical assistance, helping them enhance the value of their hybrid machine learning solutions on AWS. Kanwaljit specializes in assisting customers with containerized applications and high-performance computing solutions.
Kanwaljit Khurmi is a Principal Worldwide Generative AI Solutions Architect at AWS. He collaborates with AWS product teams, engineering departments, and customers to provide guidance and technical assistance, helping them enhance the value of their hybrid machine learning solutions on AWS. Kanwaljit specializes in assisting customers with containerized applications and high-performance computing solutions.
 Surya Kari is a Senior Generative AI Data Scientist at AWS. With a background in computer vision and AI devices, his current specializations include LLM training, multi-modal RAG, vision-language models, and edge computing.
Surya Kari is a Senior Generative AI Data Scientist at AWS. With a background in computer vision and AI devices, his current specializations include LLM training, multi-modal RAG, vision-language models, and edge computing.
 Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker team. He specializes in LLM training workloads, helping customers build LLM workloads using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, he enjoys running, hiking, and cooking.
Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker team. He specializes in LLM training workloads, helping customers build LLM workloads using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, he enjoys running, hiking, and cooking.
 Suhit Kodgule is a Software Development Engineer with the AWS Artificial Intelligence group working on deep learning frameworks. In his spare time, he enjoys hiking, traveling, and cooking.
Suhit Kodgule is a Software Development Engineer with the AWS Artificial Intelligence group working on deep learning frameworks. In his spare time, he enjoys hiking, traveling, and cooking.
 Anirudh Viswanathan is a Sr Product Manager, Technical – External Services with the SageMaker Training team. He holds a Masters in Robotics from Carnegie Mellon University, an MBA from the Wharton School of Business, and is named inventor on over 40 patents. He enjoys long-distance running, visiting art galleries, and Broadway shows.
Anirudh Viswanathan is a Sr Product Manager, Technical – External Services with the SageMaker Training team. He holds a Masters in Robotics from Carnegie Mellon University, an MBA from the Wharton School of Business, and is named inventor on over 40 patents. He enjoys long-distance running, visiting art galleries, and Broadway shows.
Tags: Machine learning
Leave a Reply