AWS Machine Learning
-

AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
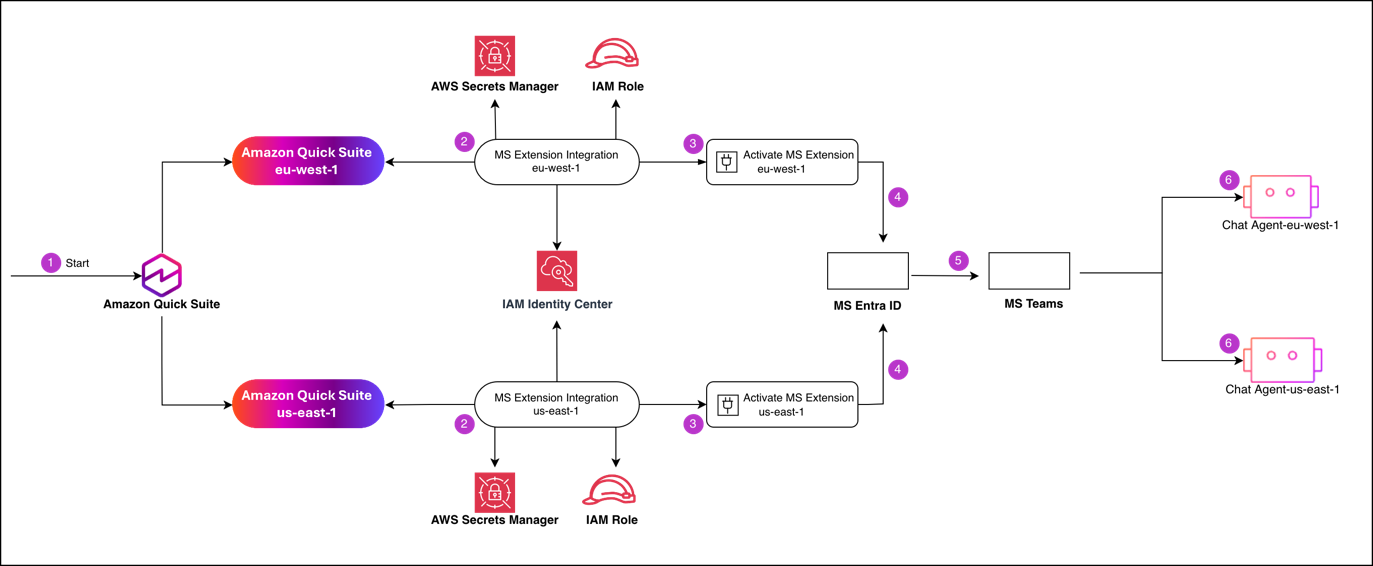
Enforce data residency with Amazon Quick extensions for Microsoft Teams
Organizations with users in multiple geographies face data residency […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
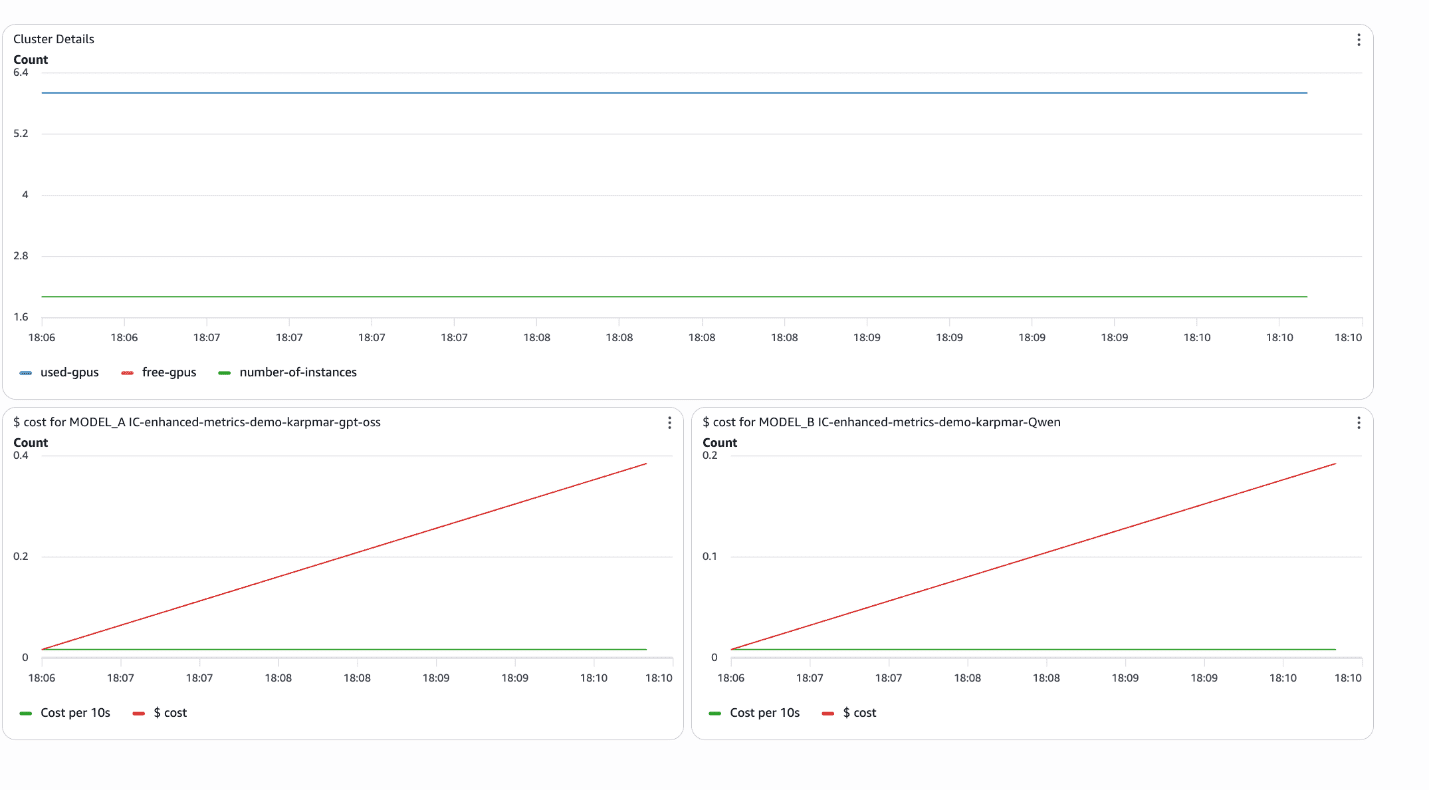
Enhanced metrics for Amazon SageMaker AI endpoints: deeper visibility for better performance
Running machine learning (ML) models in production […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
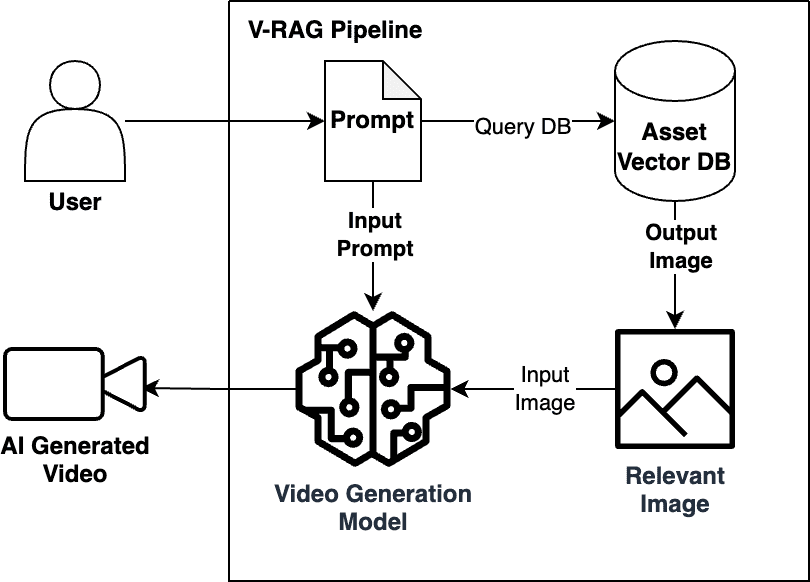
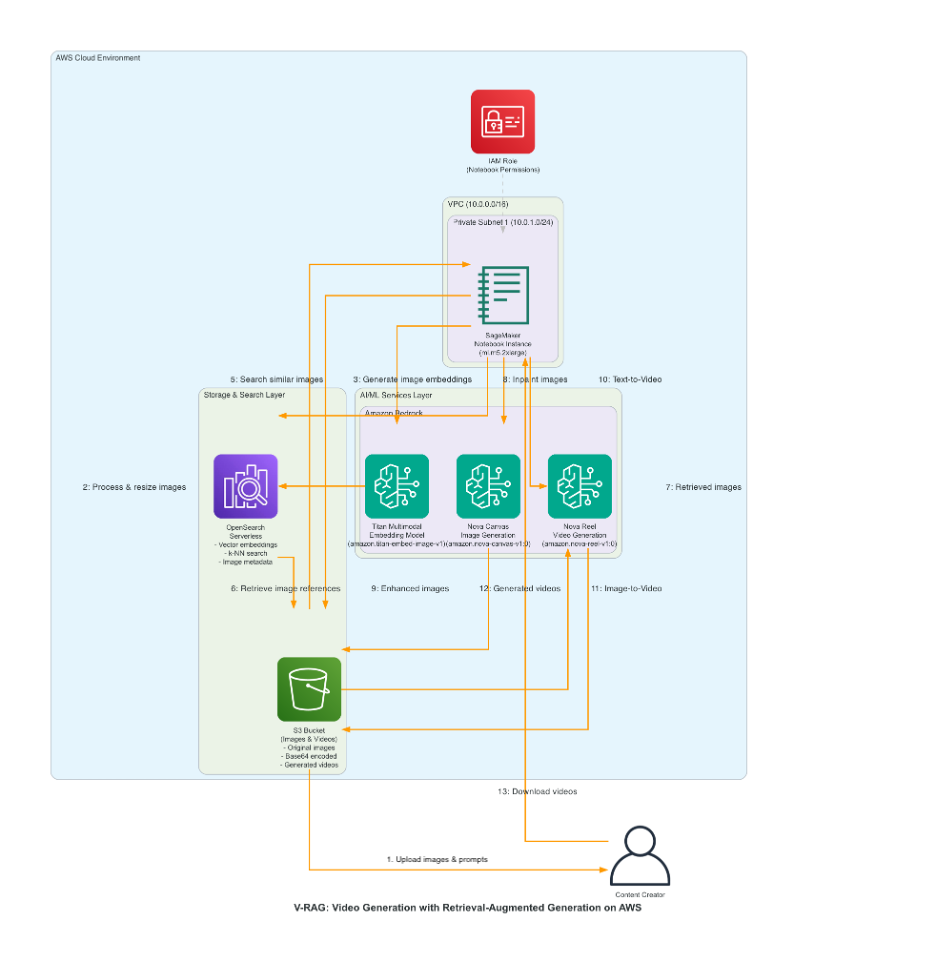
Introducing V-RAG: revolutionizing AI-powered video production with Retrieval Augmented Generation
A key development in generative AI is AI-powered […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
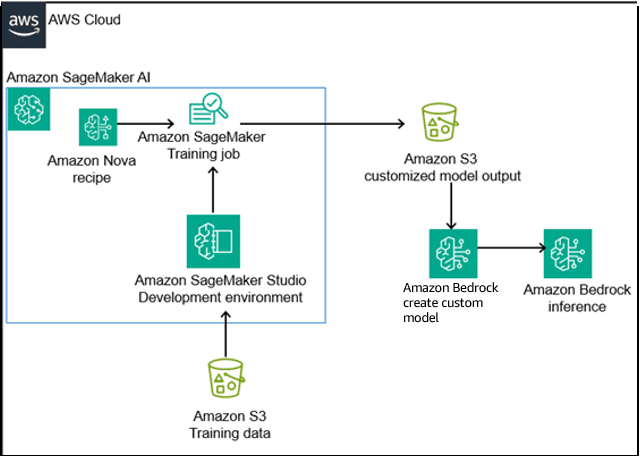
Overcoming LLM hallucinations in regulated industries: Artificial Genius’s deterministic models on Amazon Nova
This post is cowritten by Paul Burchard […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
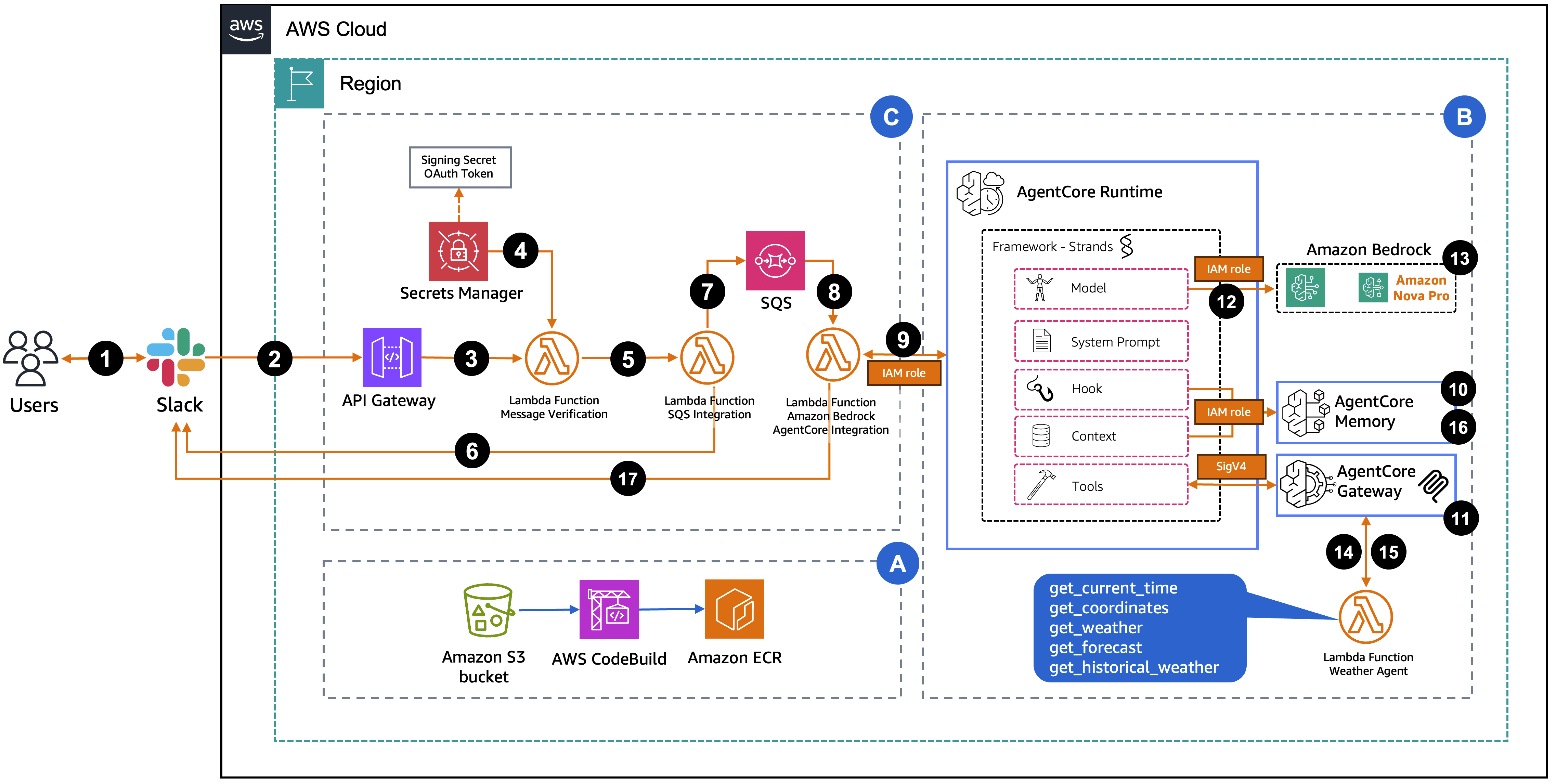
Integrating Amazon Bedrock AgentCore with Slack
Integrating Amazon Bedrock AgentCore with Slack brings AI agents directly into your workspace. Your […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
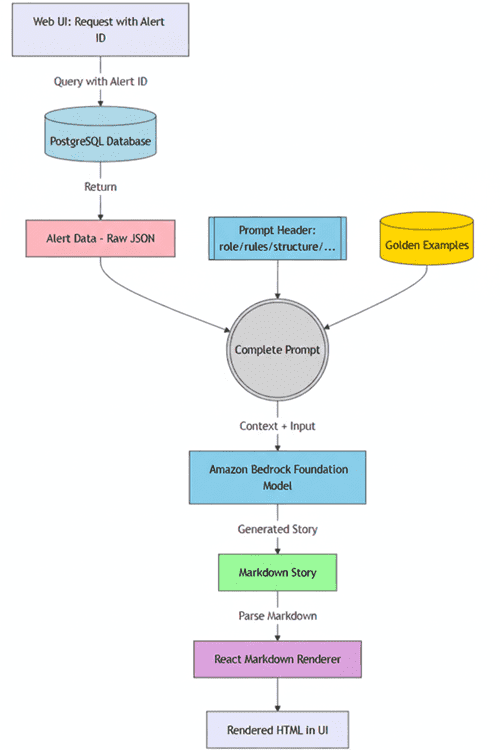
How Reco transforms security alerts using Amazon Bedrock
This post is cowritten by Tal Shapira and Tamir Friedman from Reco. Reco helps […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
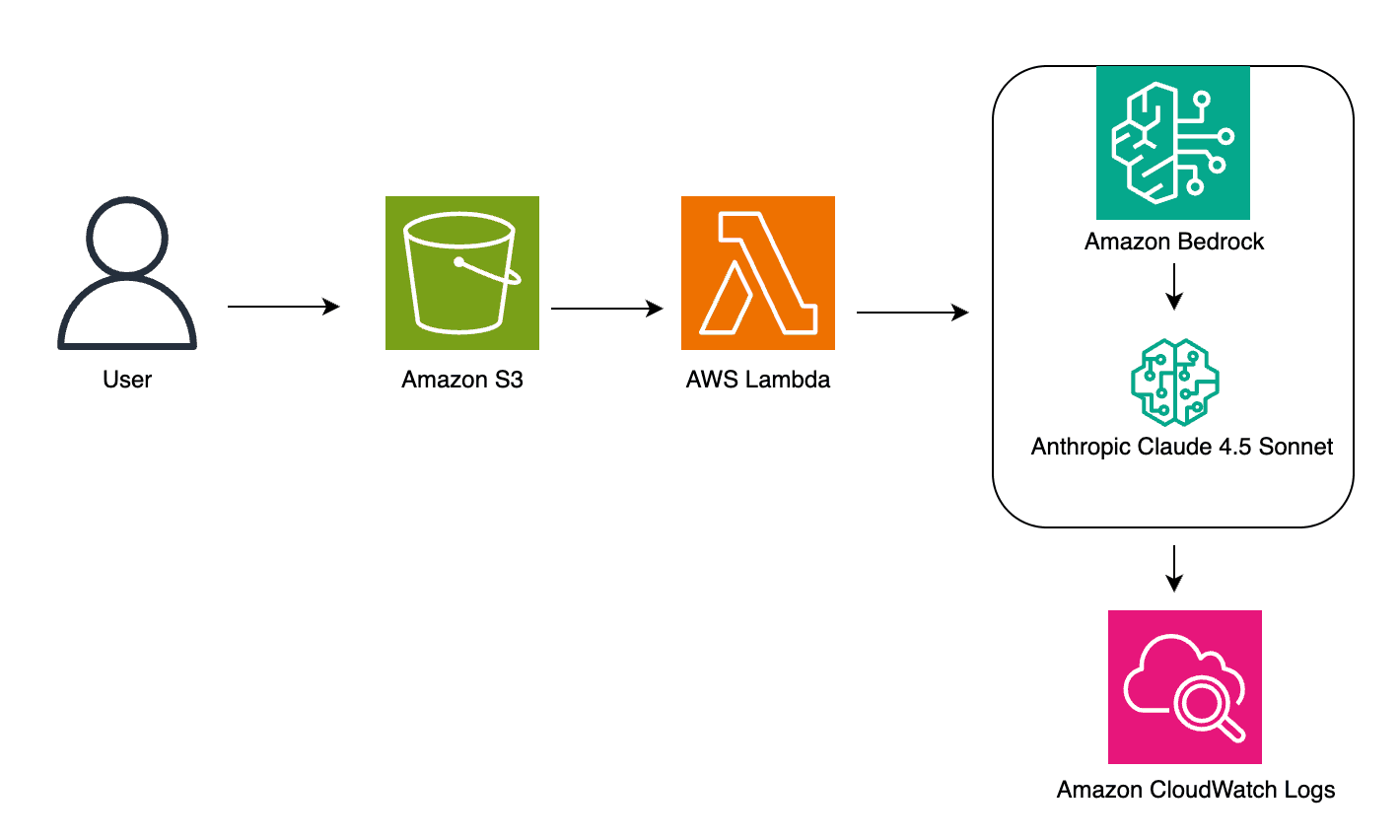
Accelerating custom entity recognition with Claude tool use in Amazon Bedrock
Businesses across industries face a common challenge: how to […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
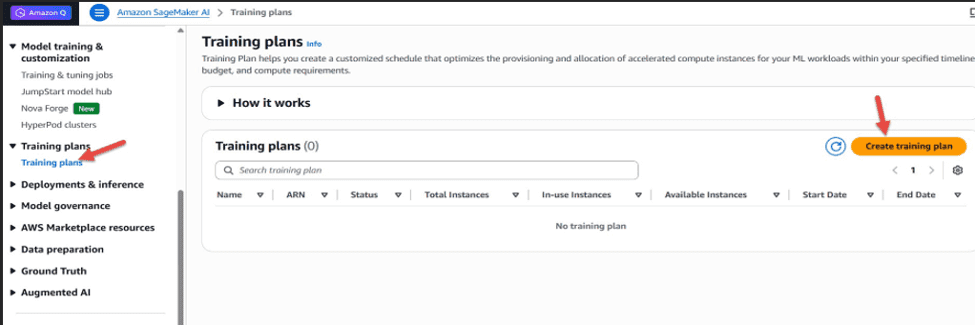
Deploy SageMaker AI inference endpoints with set GPU capacity using training plans
Deploying large language models (LLMs) for inference requires […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
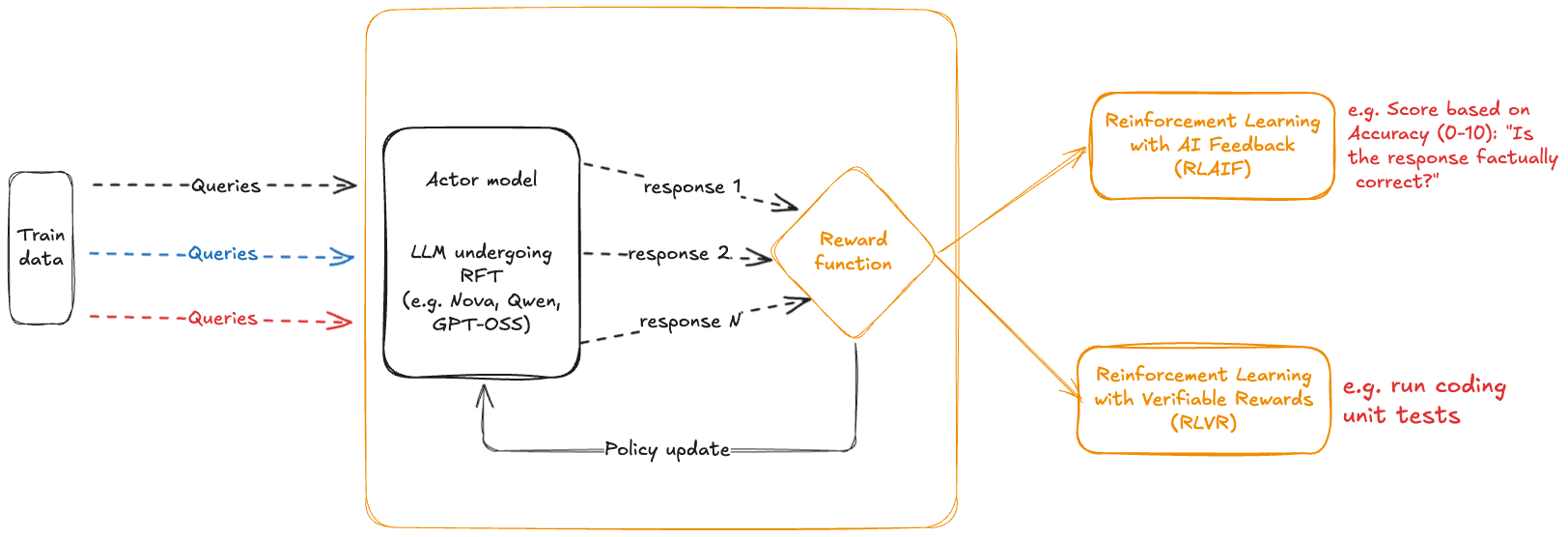
Reinforcement fine-tuning on Amazon Bedrock with OpenAI-Compatible APIs: a technical walkthrough
In December 2025, we announced the availability of […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
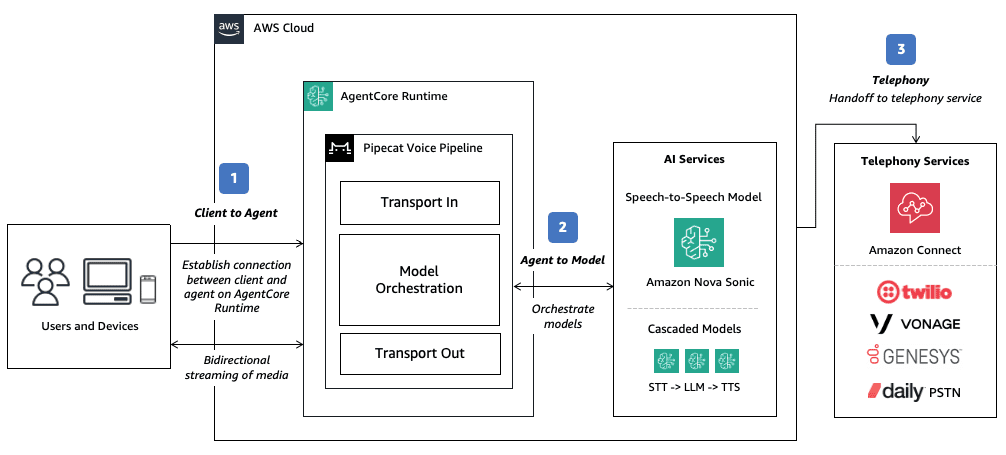
Deploy voice agents with Pipecat and Amazon Bedrock AgentCore Runtime – Part 1
This post is a collaboration between AWS and Pipecat. Deploying […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
Unlocking video insights at scale with Amazon Bedrock multimodal models
Video content is now everywhere, from security surveillance and media […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
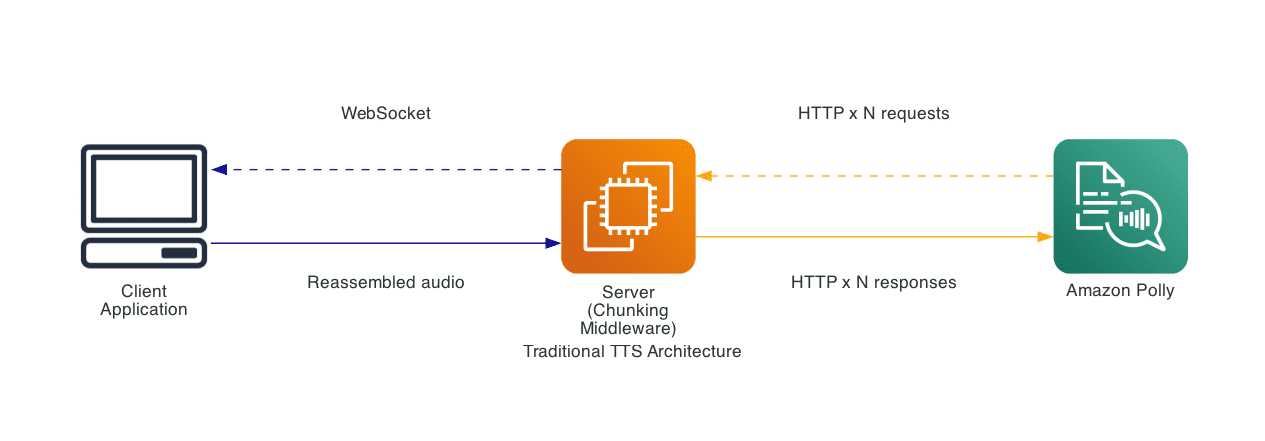
Introducing Amazon Polly Bidirectional Streaming: Real-time speech synthesis for conversational AI
Building natural conversational experiences […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
Accelerating LLM fine-tuning with unstructured data using SageMaker Unified Studio and S3
Last year, AWS announced an integration between Amazon […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
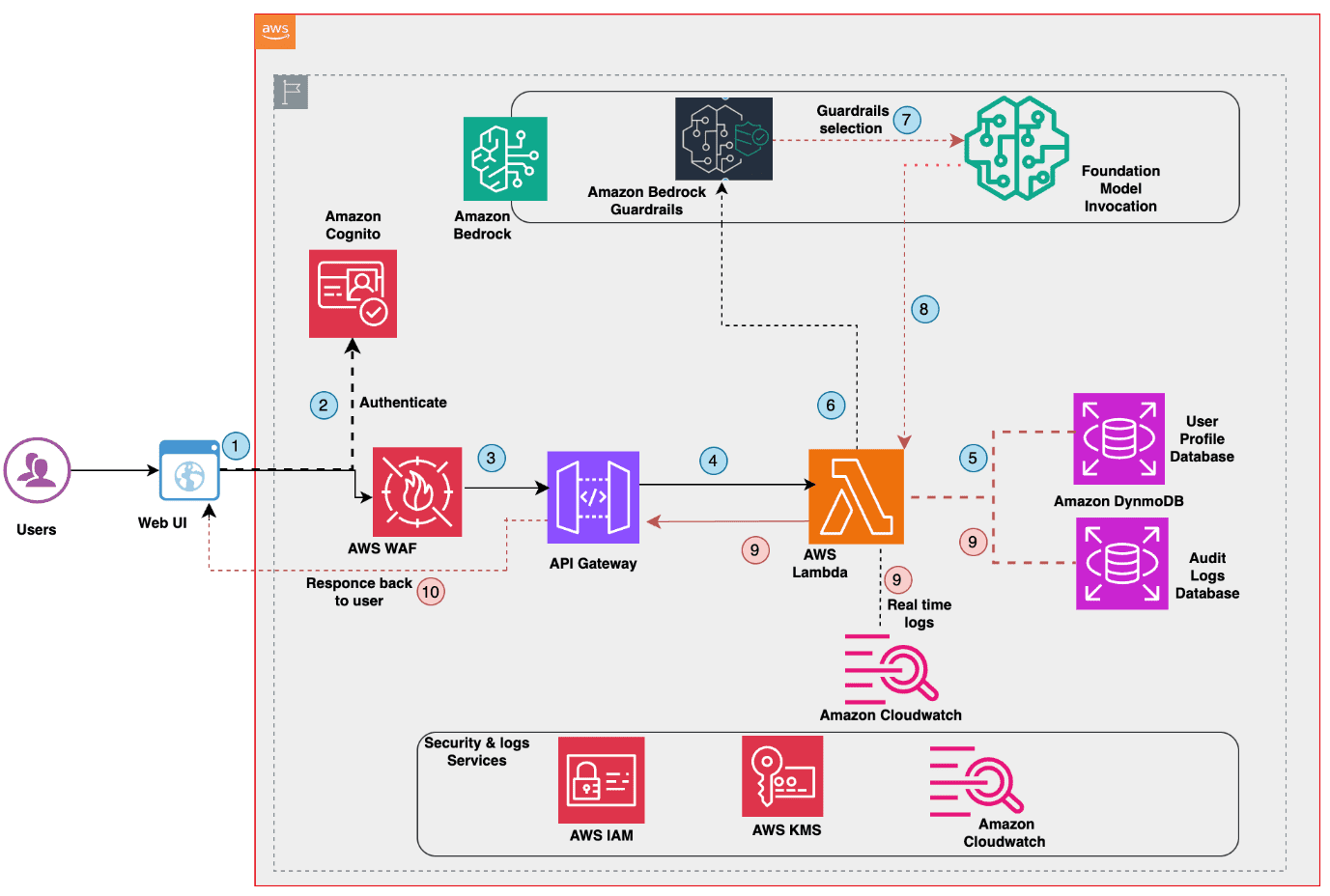
Building age-responsive, context-aware AI with Amazon Bedrock Guardrails
As you deploy generative AI applications to diverse user groups, you might […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 1 hour ago
Run Generative AI inference with Amazon Bedrock in Asia Pacific (New Zealand)
Kia ora! Customers in New Zealand have been asking for access to […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 1 day ago
Use RAG for video generation using Amazon Bedrock and Amazon Nova Reel
Generating high-quality custom videos remains a significant challenge, […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 1 day ago
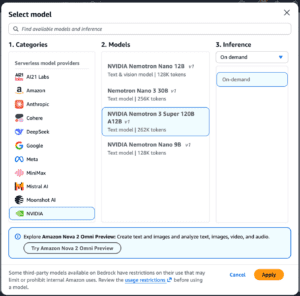
Run NVIDIA Nemotron 3 Super on Amazon Bedrock
Nemotron 3 Super is now available as a fully managed and serverless model on Amazon Bedrock, joining […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 3 days ago
Migrate from Amazon Nova 1 to Amazon Nova 2 on Amazon Bedrock
If you’re running Amazon Nova 1 models on Amazon Bedrock, you might be looking to e […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 3 days ago
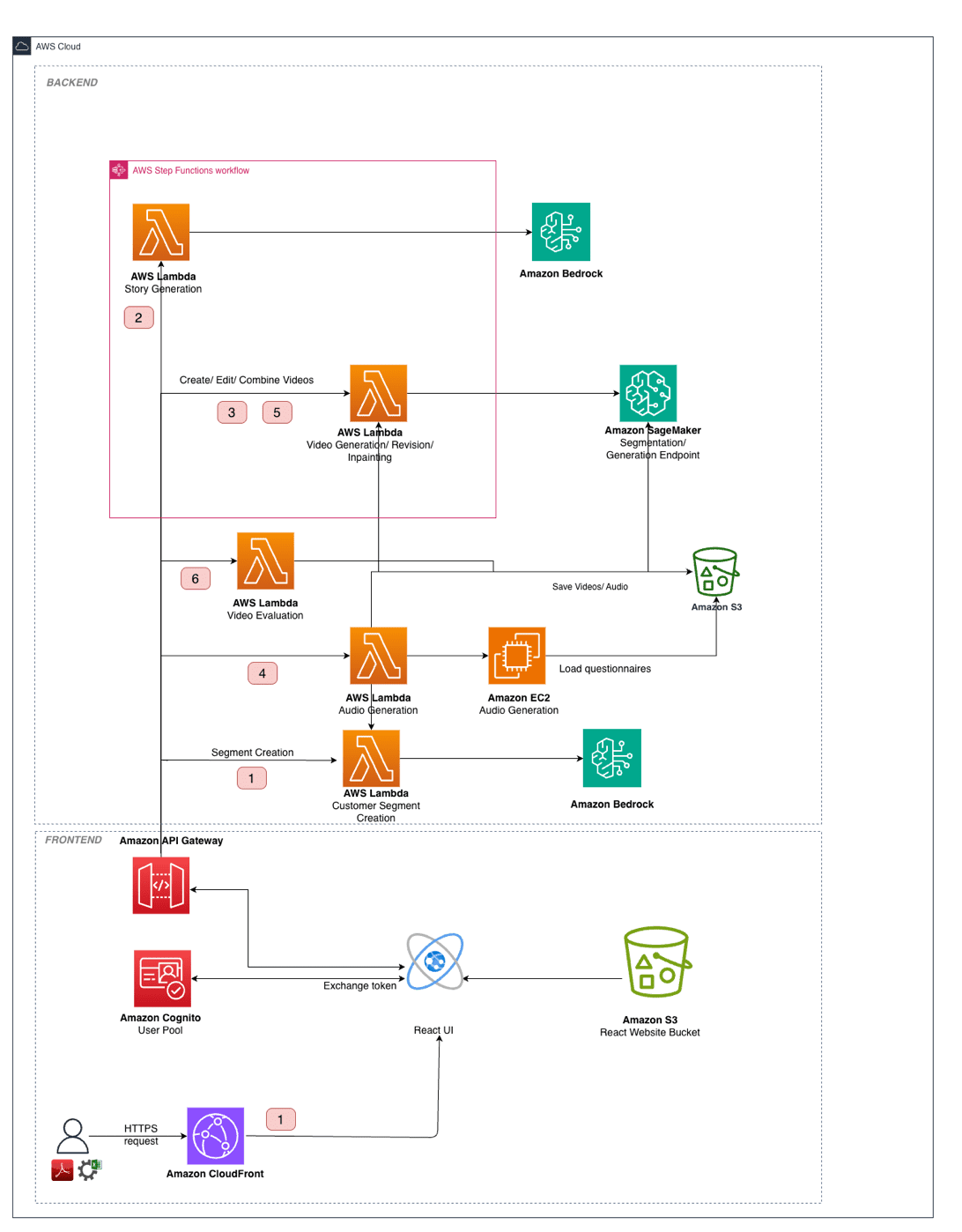
How Bark.com and AWS collaborated to build a scalable video generation solution
This post is cowritten with Hammad Mian and Joonas Kukkonen from […] -
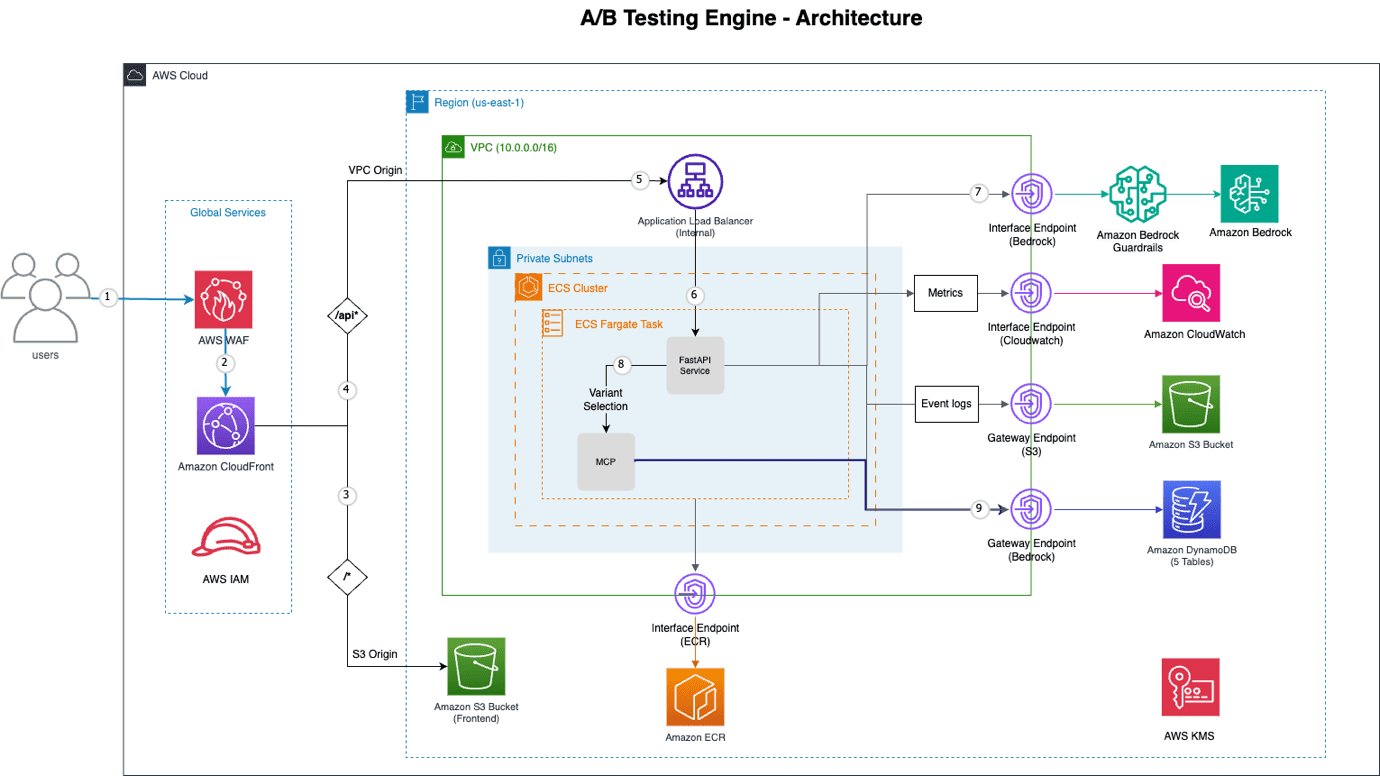
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 3 days ago
Build an AI-Powered A/B testing engine using Amazon Bedrock
Organizations commonly rely on A/B testing to optimize user experience, messaging, and […] - Load More