AWS Machine Learning
-

AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 7 hours, 51 minutes ago
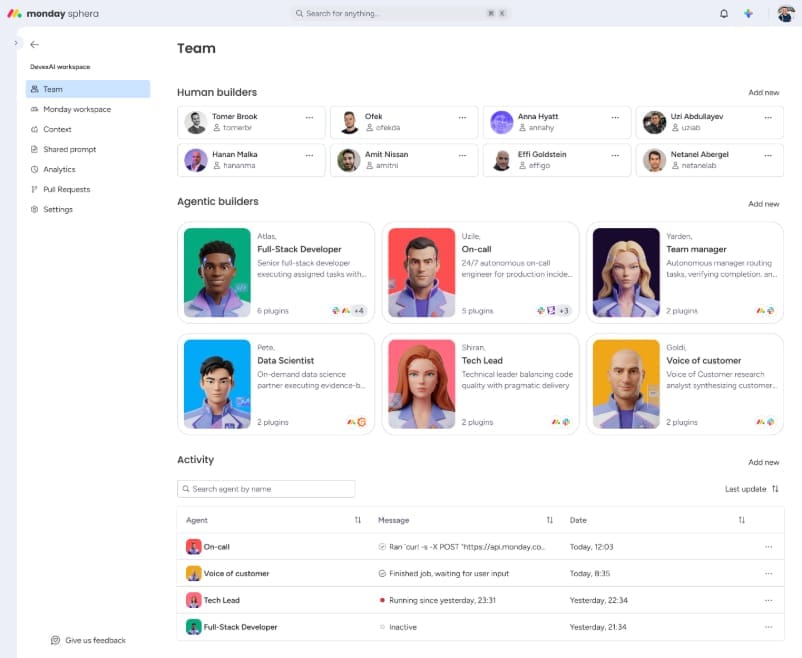
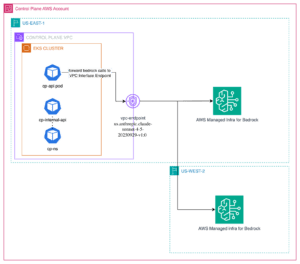
AI Teammates: how monday.com runs production AI agents on Amazon Bedrock
AI Teammates are agentic AI on Amazon Bedrock, and few engineering […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 day, 8 hours ago
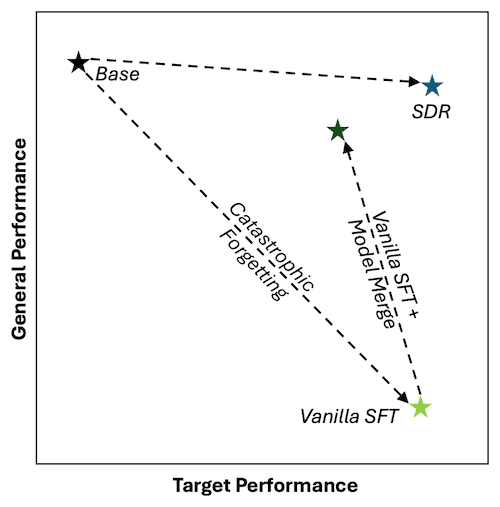
Exploring self-distilled reasoning for supervised fine-tuning with Amazon Nova
When you fine-tune a model using Supervised Fine-Tuning (SFT), […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 days, 8 hours ago
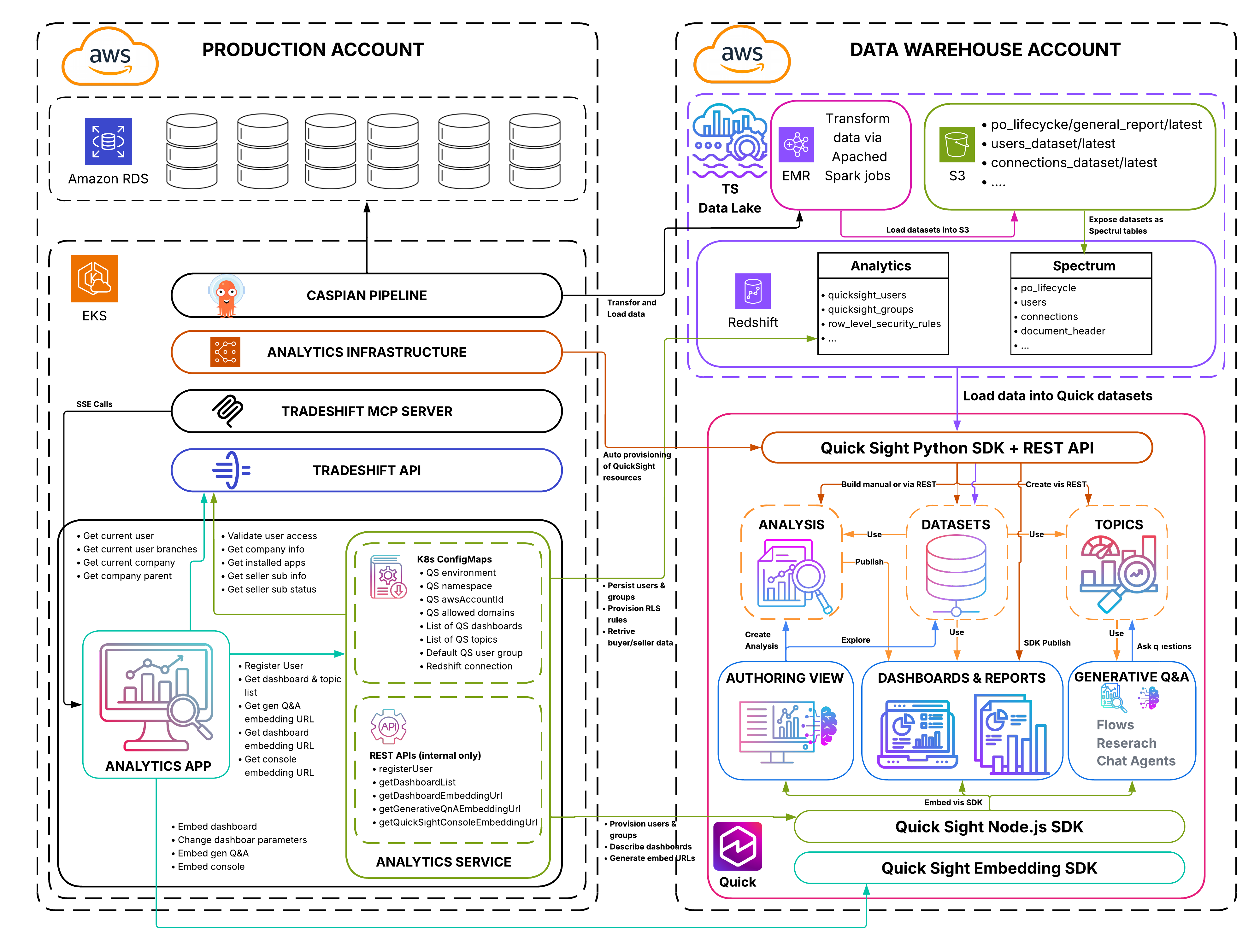
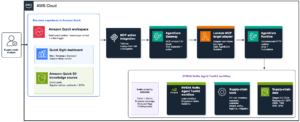
Evolving from legacy BI to agentic AI at Tradeshift with Amazon Quick
This guest post is co-written by Raphael Bres, Robert Iordache, Anca Andone, […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 days, 8 hours ago
How Couchbase built a multi-model AI architecture for Capella iQ with Amazon Bedrock
This post is co-written with Tushar Madaan from Couchbase. […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 days, 8 hours ago
Build specialized agent workflows for your business with Amazon Quick and NVIDIA NeMo Agent Toolkit
Fast-growing companies and enterprise […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 days, 8 hours ago
Custom OS installation now available on AWS DeepRacer devices
With the stock firmware and software, developers couldn’t modify their AWS DeepRacer d […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 5 days, 8 hours ago
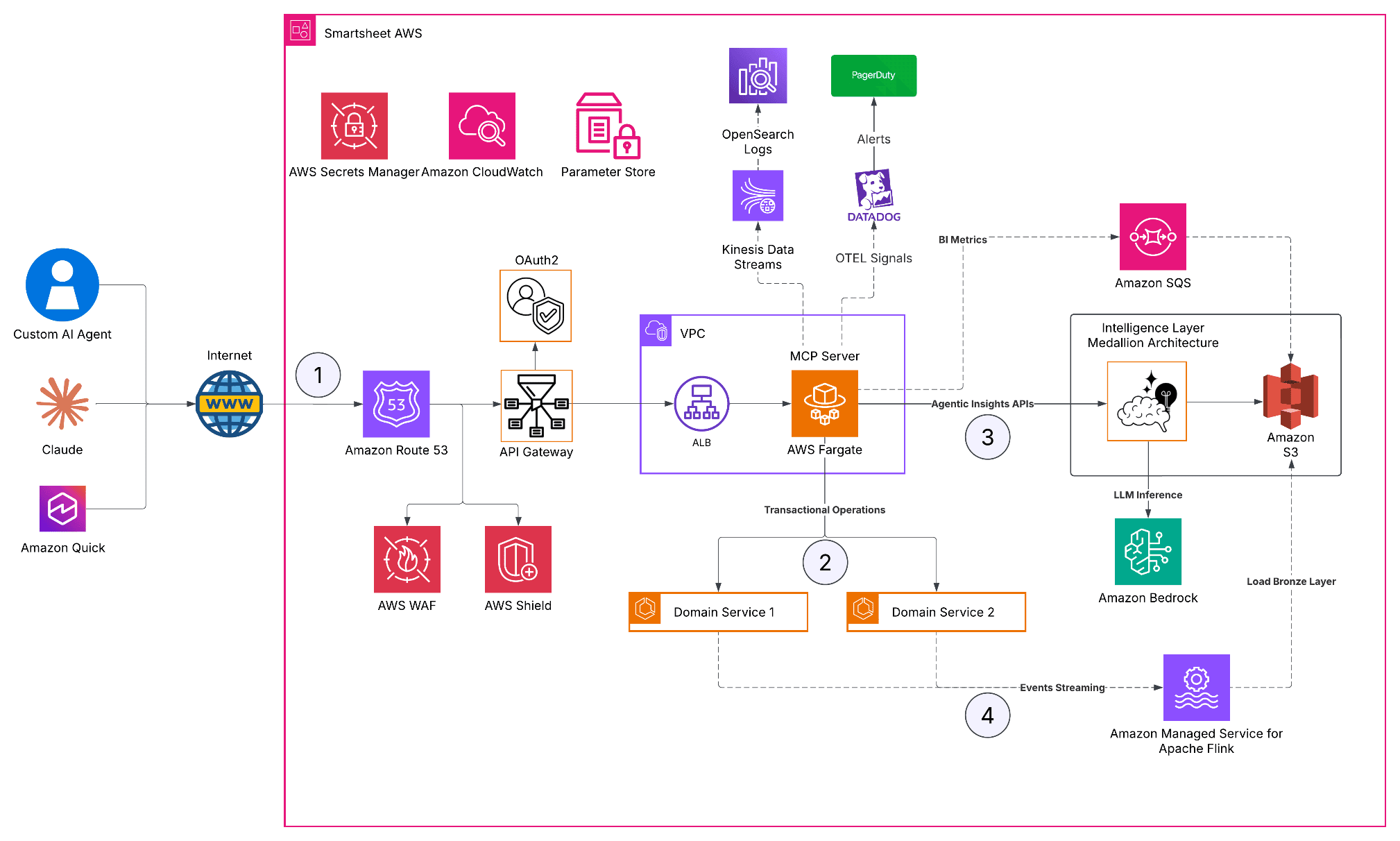
How Smartsheet built a remote MCP server on AWS
Smartsheet is an enterprise work management platform that hundreds of thousands of organizations […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 5 days, 8 hours ago
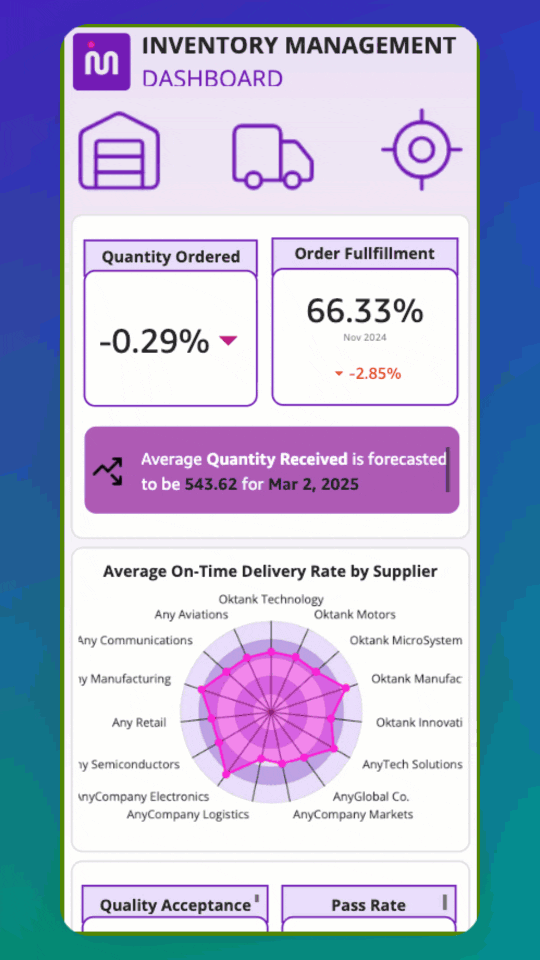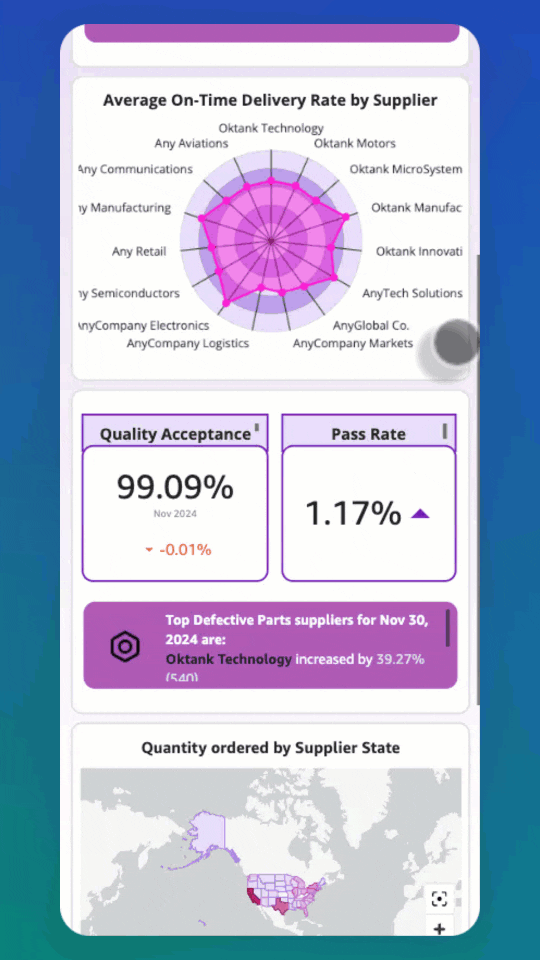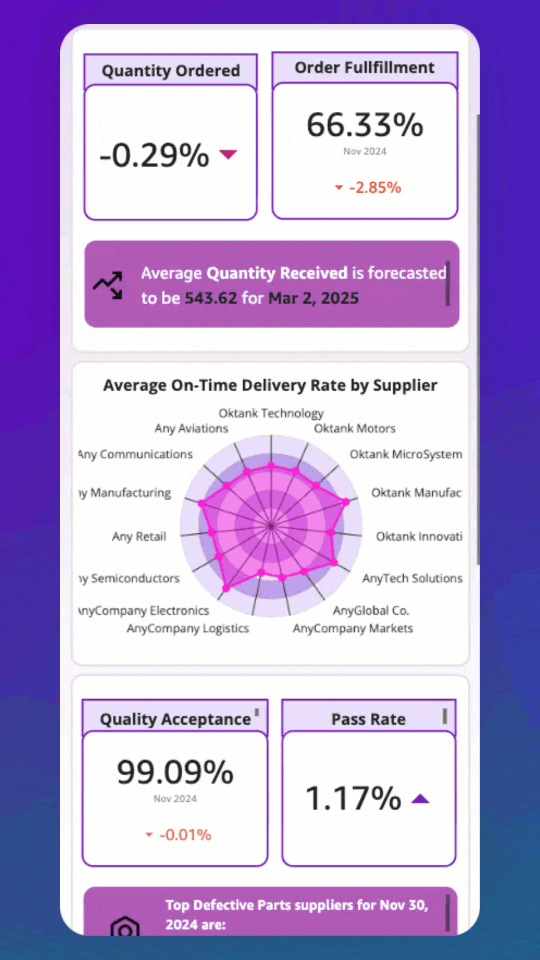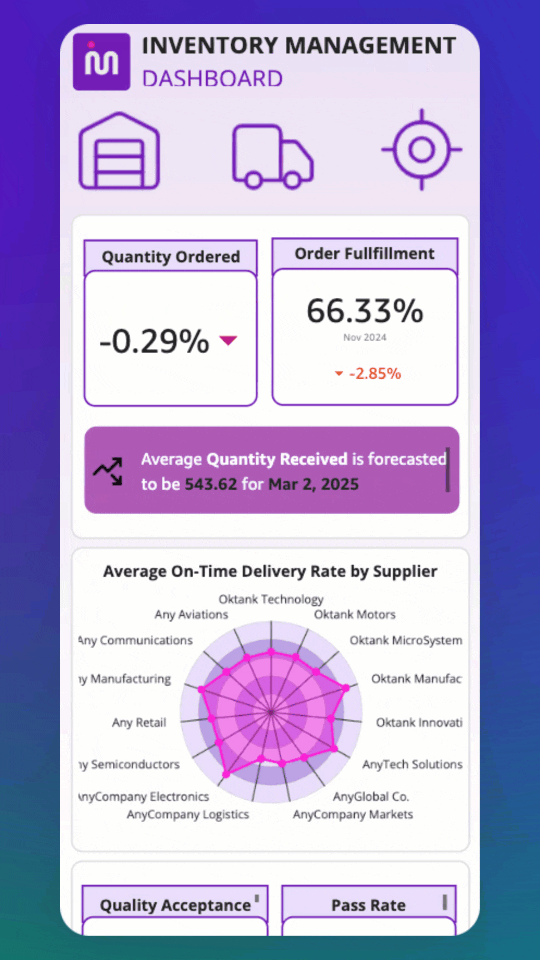
Introducing Mobile Layout for Amazon Quick dashboards
Teams that rely on dashboards for daily decisions often must pinch and zoom to interact with […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 5 days, 8 hours ago
Transform your sales organization with Amazon Quick: your new agentic AI teammate
The average sales rep spends only 40% of their time actually […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 6 days, 8 hours ago
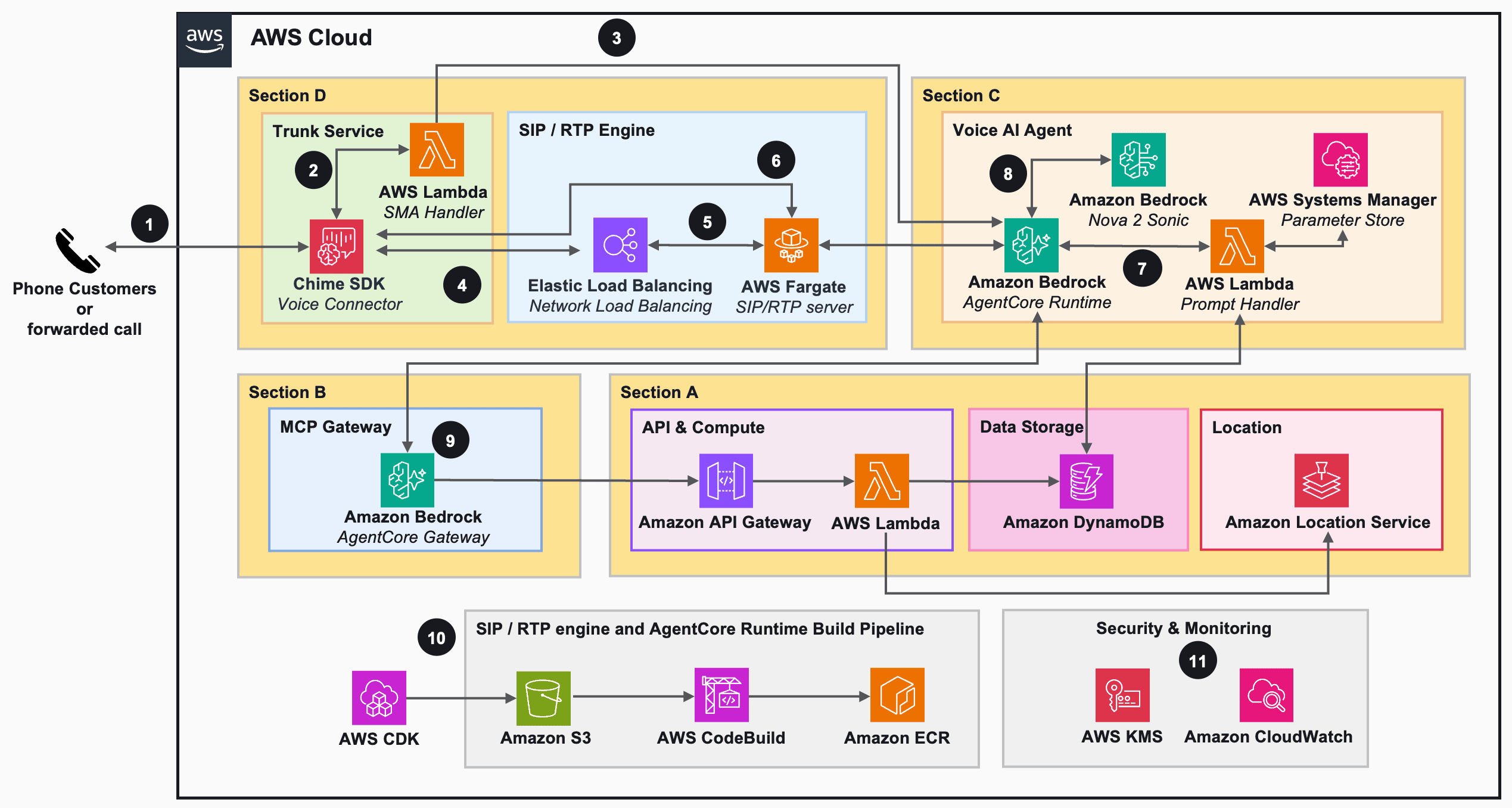
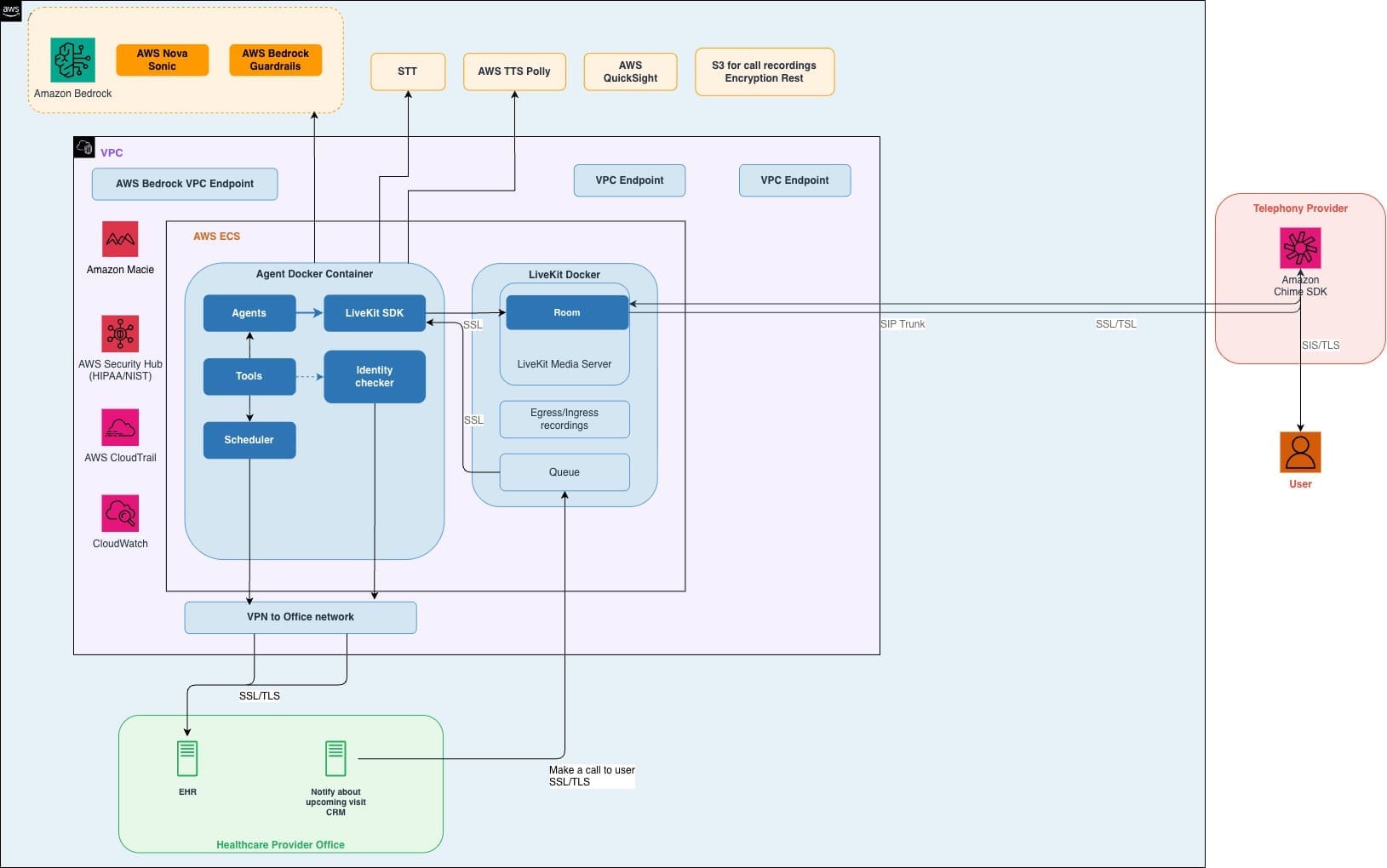
Building a restaurant telephony AI host with Amazon Bedrock AgentCore and Amazon Nova 2 Sonic
Restaurants miss an average of 150 phone calls per […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 6 days, 8 hours ago
Introducing Grok on Amazon Bedrock
This post is co-written with Eric Jiang from xAI (SpaceXAI). xAI’s Grok 4.3 is now generally available on A […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 6 days, 8 hours ago
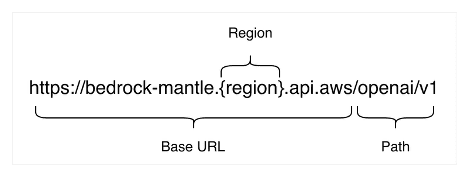
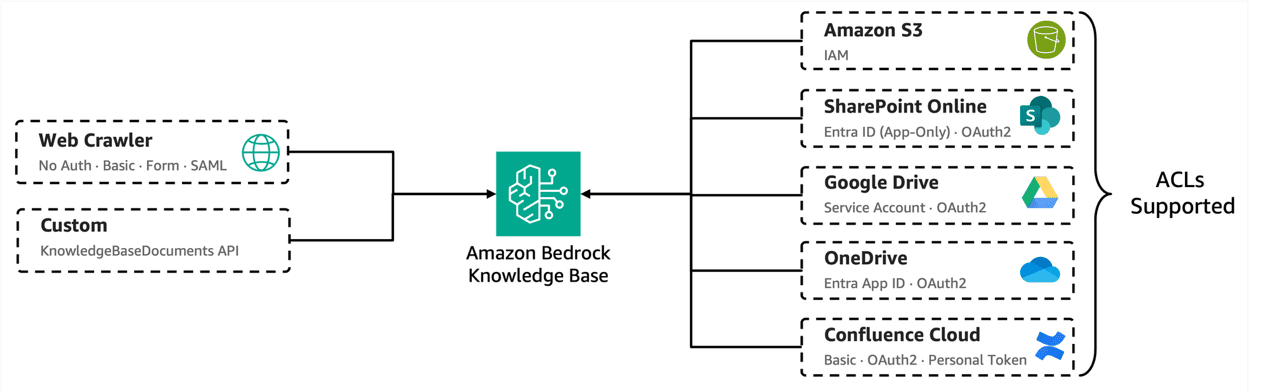
Build enterprise search for agents with Amazon Bedrock Managed Knowledge Base
Knowledge bases that ground agents and generative AI applications over […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week ago
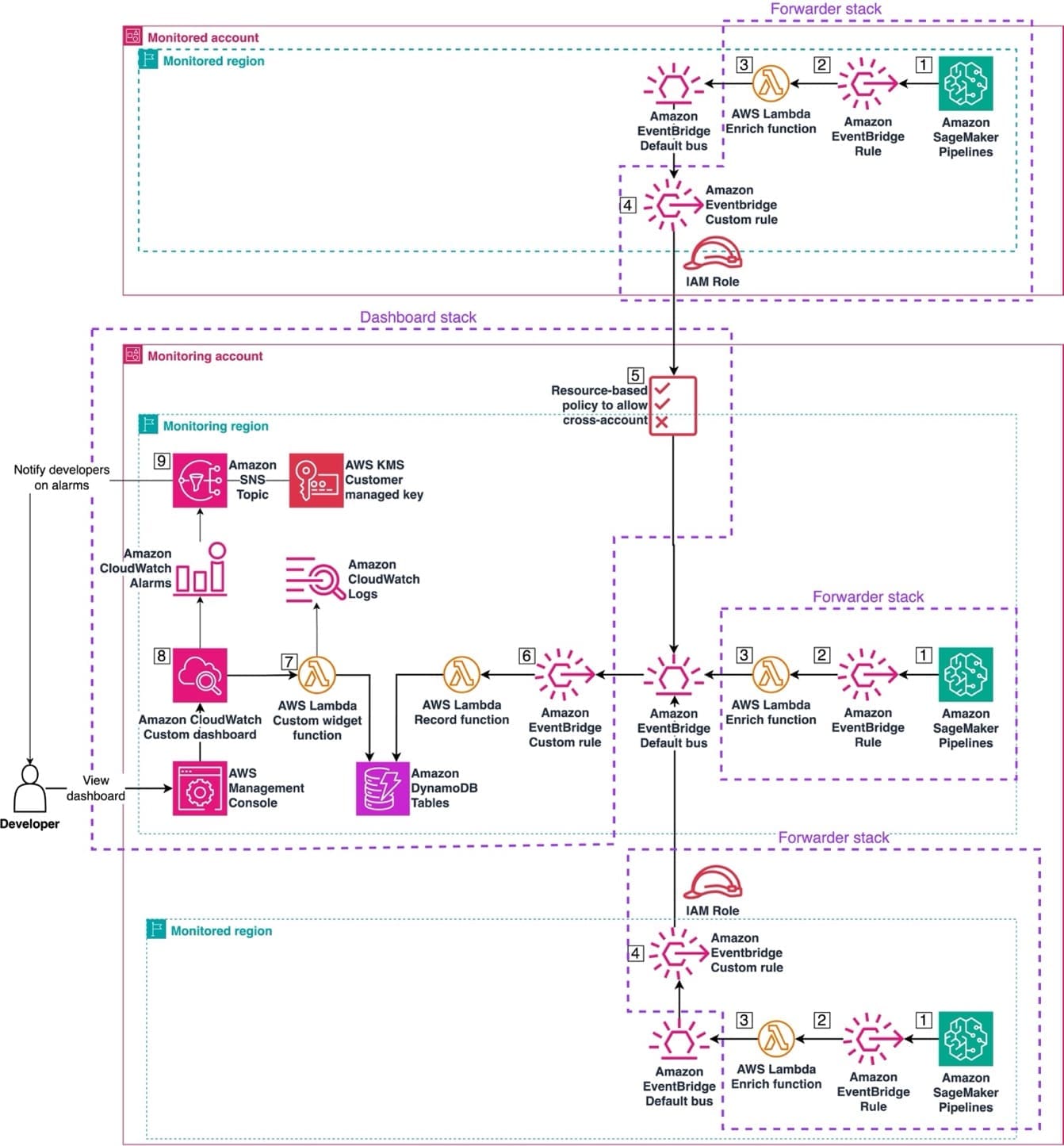
Monitor Amazon SageMaker Pipelines cross-account with custom Amazon CloudWatch dashboards
Using Amazon SageMaker Pipelines, organizations can […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week ago
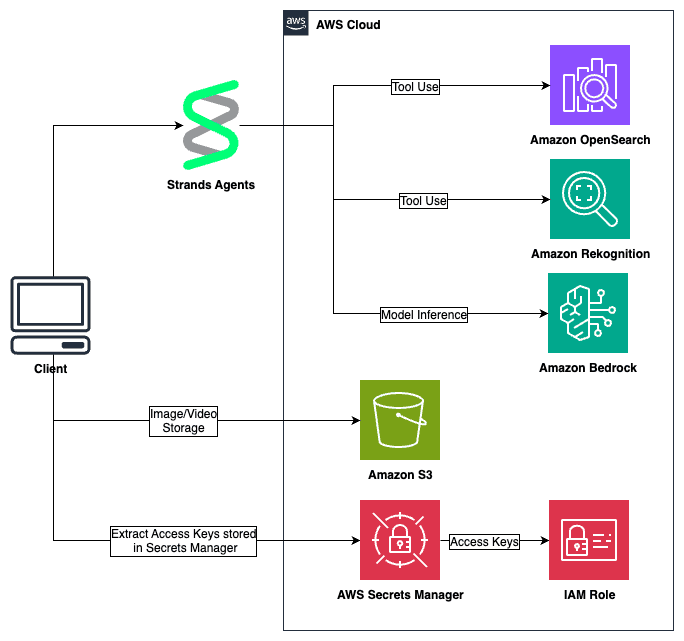
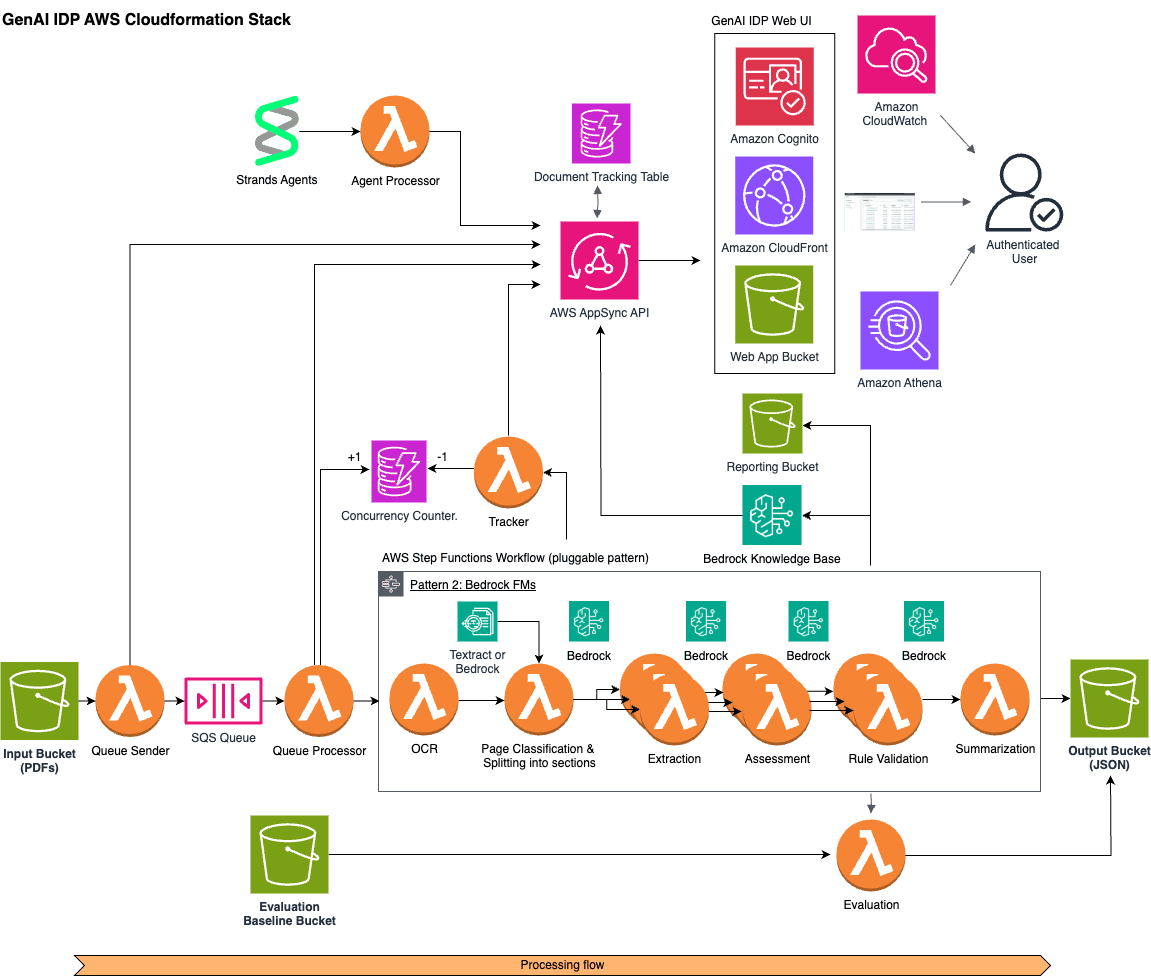
Agentic vision: Building visual intelligence with Amazon Bedrock and MCP servers
The integration of AI into real-world applications has long been […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week ago
-
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 1 day ago
ScienceSoft’s HIPAA-compliant AI voice scheduler built on AWS
Healthcare organizations need efficient scheduling solutions, and ScienceSoft’s AI v […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 1 day ago
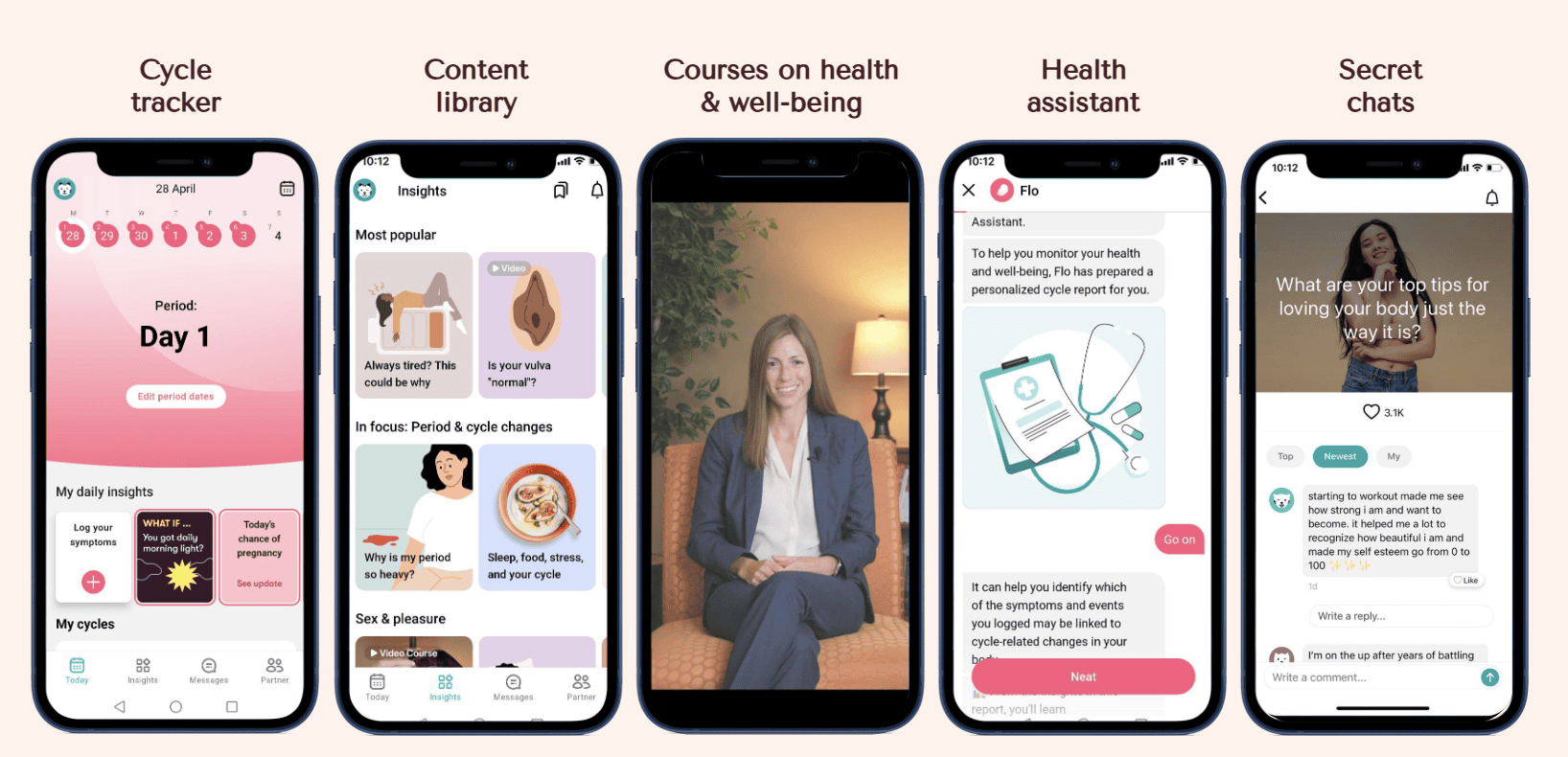
Scaling medical content review at Flo Health with Amazon Bedrock – Part 2
This post was written by Konstantin Lekh, Sasha Zinchuk, and Eugene Sergueev […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 1 day ago
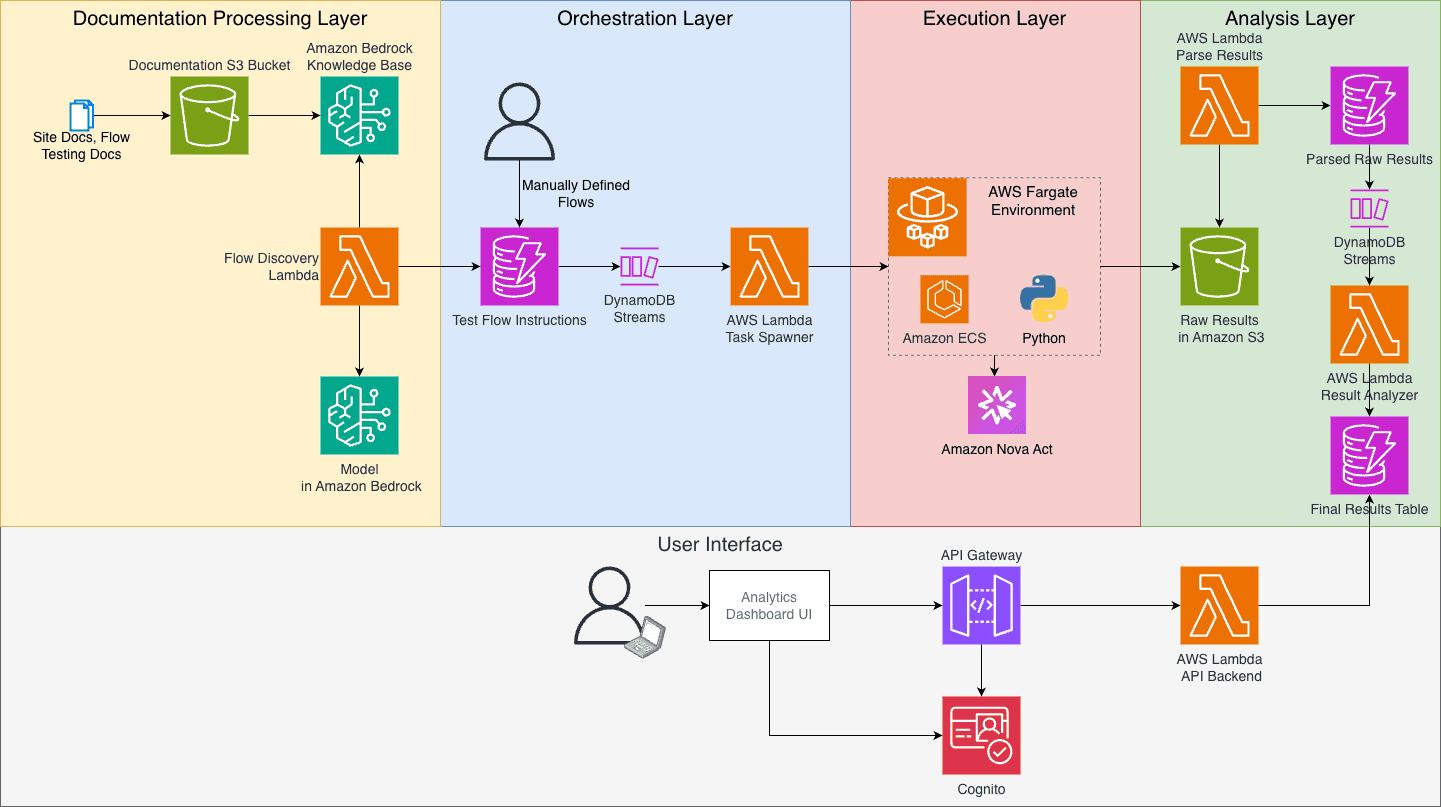
Scaling UX testing with Amazon Nova Act: A new approach to user flow analysis
User experience (UX) testing faces multiple challenges that limit an […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 1 day ago
Accelerating software delivery with agentic QA automation using Amazon Nova Act – Part 2
Production quality assurance (QA) workflows require more than […] -
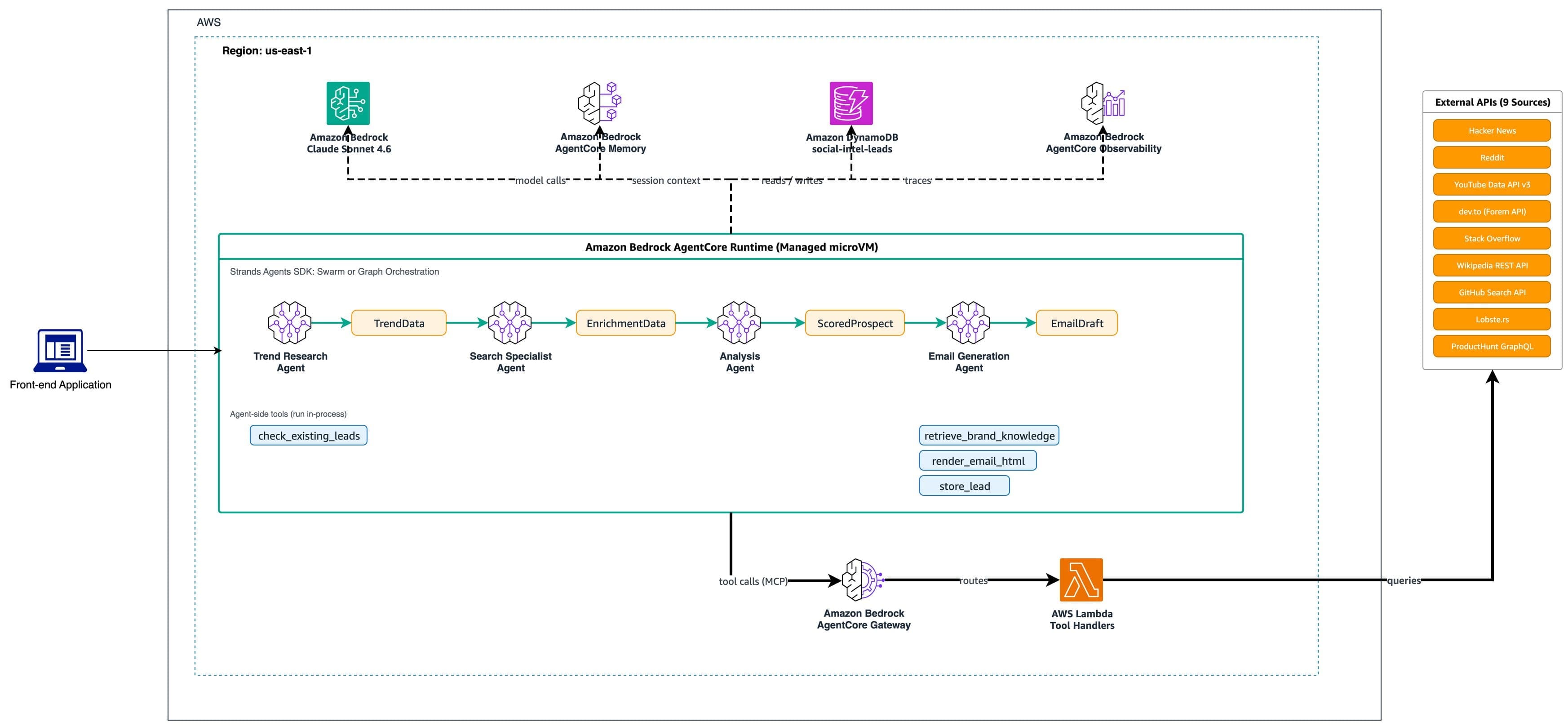
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 1 day ago
Multi-agent social intelligence with Strands Agents and Amazon Bedrock
Your prospects leave trails across multiple sources: a founder asks “What s […] - Load More