AWS Machine Learning
-

AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 4 days ago
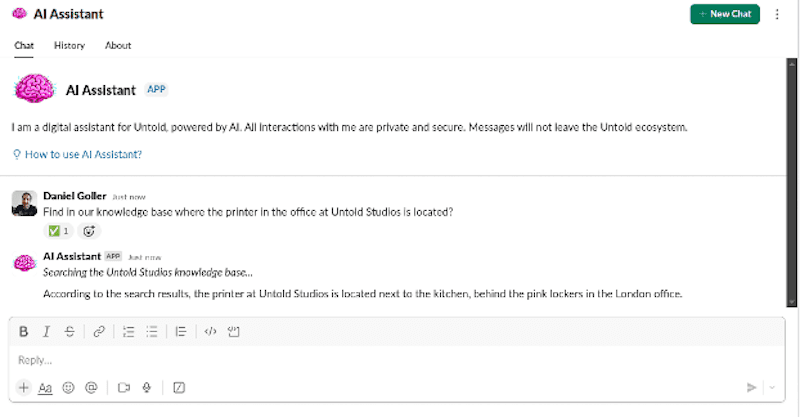
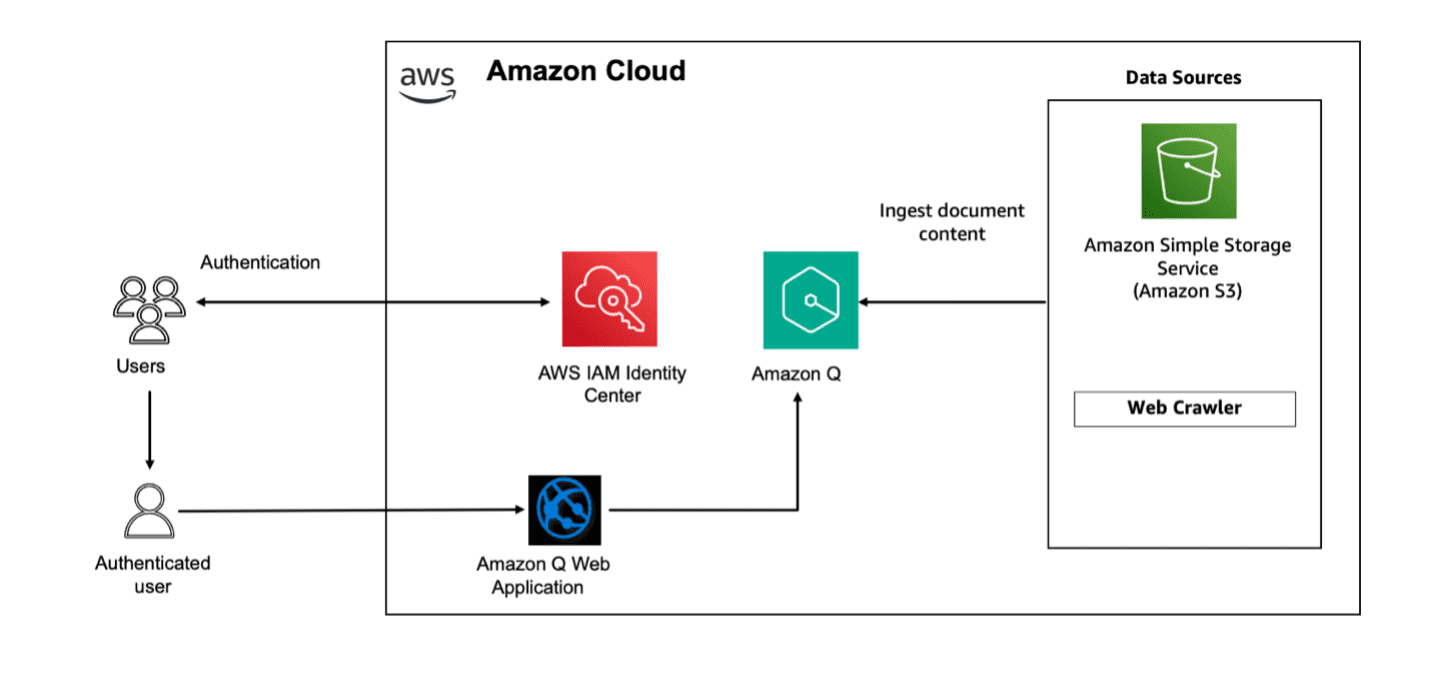
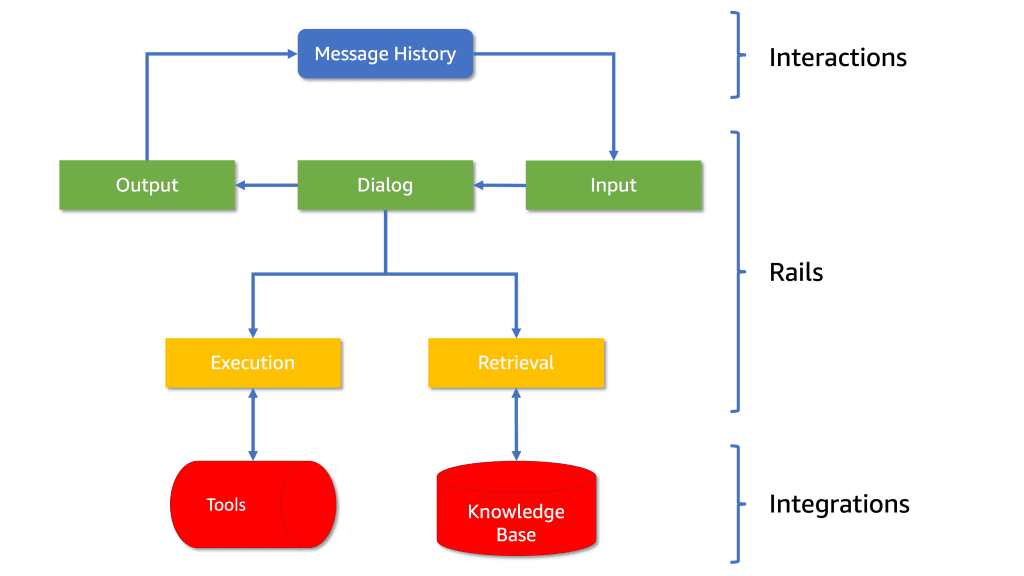
How Untold Studios empowers artists with an AI assistant built on Amazon Bedrock
Untold Studios is a tech-driven, leading creative studio […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 4 days ago
Building the future of construction analytics: CONXAI’s AI inference on Amazon EKS
This is a guest post co-written with Tim Krause, Lead MLOps […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 4 days ago
Accelerate your Amazon Q implementation: starter kits for SMBs
Whether you’re a small or medium-sized business (SMB) or a managed service provider a […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 5 days ago
Enhancing LLM Capabilities with NeMo Guardrails on Amazon SageMaker JumpStart
As large language models (LLMs) become increasingly integrated into […] -
-
-
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 1 week, 6 days ago
Orchestrate seamless business systems integrations using Amazon Bedrock Agents
Generative AI has revolutionized technology through generating […] -
-
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks ago
Accelerate video Q&A workflows using Amazon Bedrock Knowledge Bases, Amazon Transcribe, and thoughtful UX design
Organizations are often inundated with […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 1 day ago
Boost team innovation, productivity, and knowledge sharing with Amazon Q Apps
As enterprises rapidly expand their applications, platforms, and […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 3 days ago
Accelerate digital pathology slide annotation workflows on AWS using H-optimus-0
Digital pathology is essential for the diagnosis and treatment of […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 3 days ago
How Travelers Insurance classified emails with Amazon Bedrock and prompt engineering
This is a guest blog post co-written with Jordan Knight, Sara […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 3 days ago
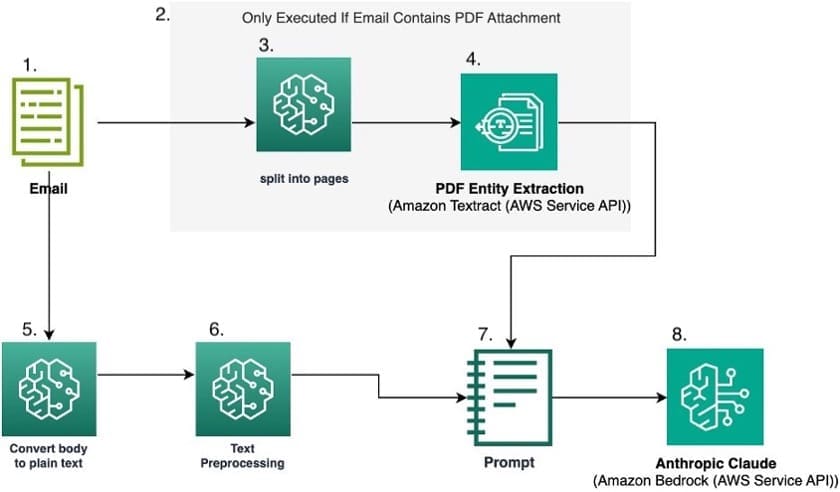
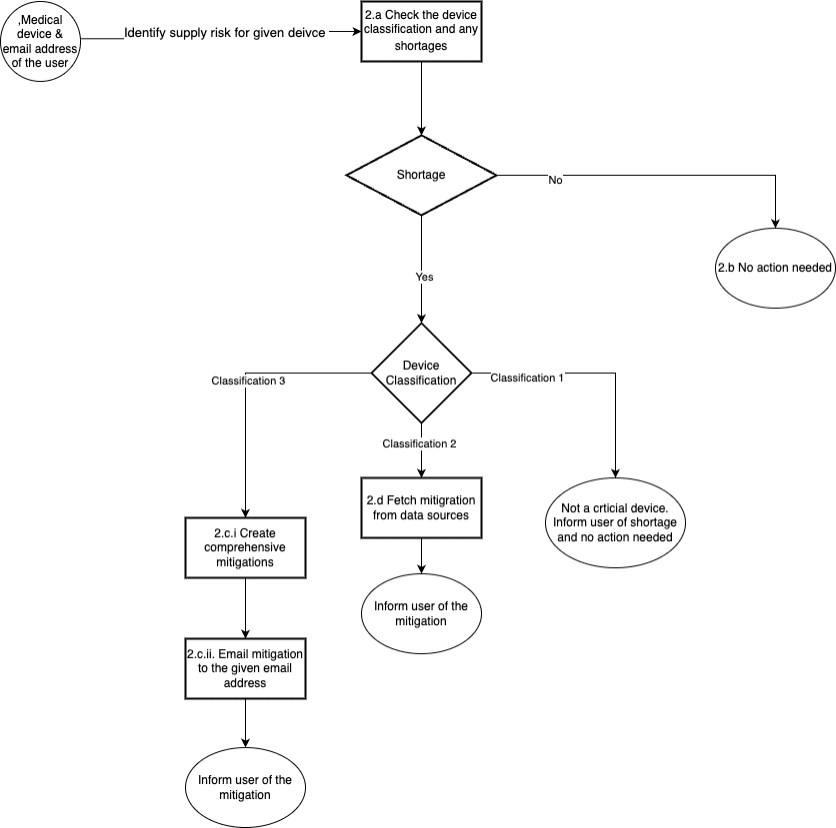
Harnessing Amazon Bedrock generative AI for resilient supply chain
From pandemic shutdowns to geopolitical tensions, recent years have thrown our […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 4 days ago
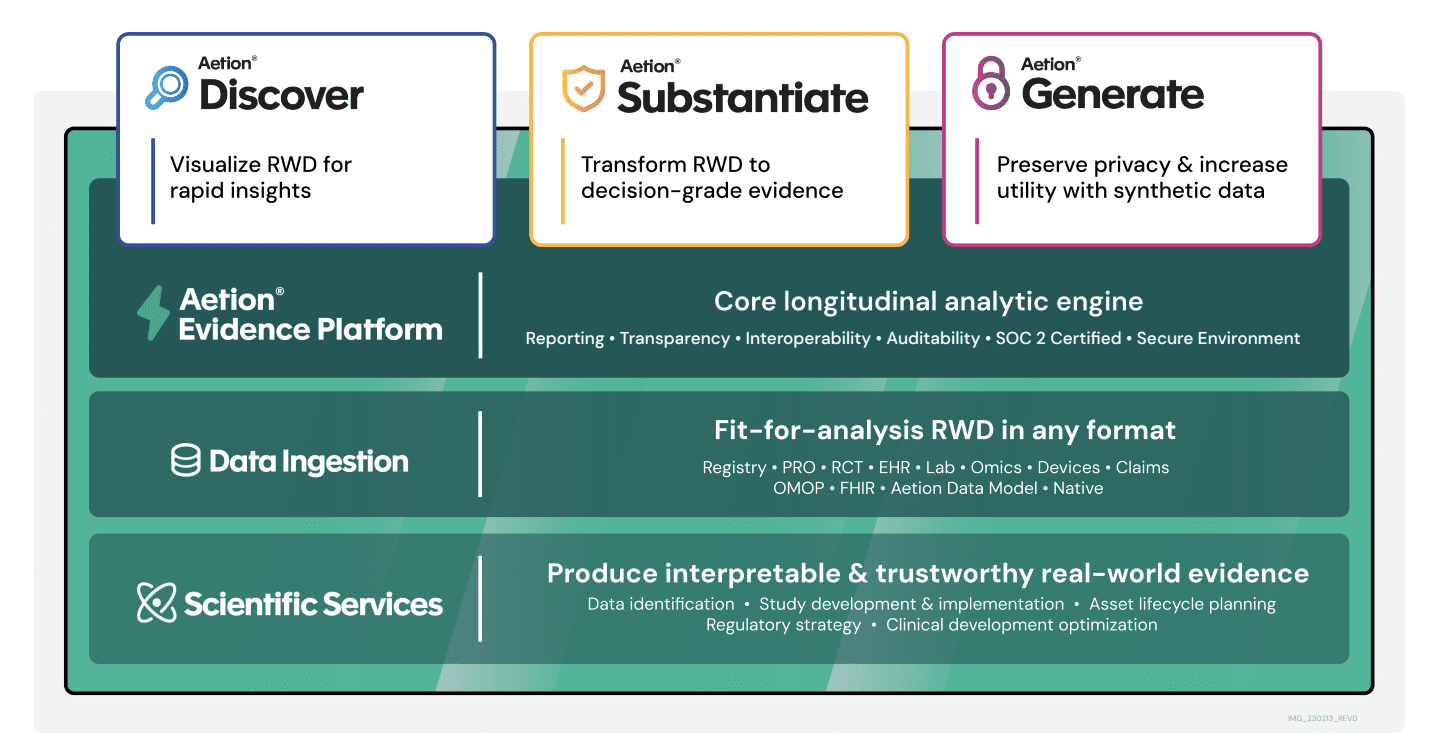
How Aetion is using generative AI and Amazon Bedrock to unlock hidden insights about patient populations
The real-world data collected and derived […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 4 days ago
Streamline grant proposal reviews using Amazon Bedrock
Government and non-profit organizations evaluating grant proposals face a significant […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 4 days ago
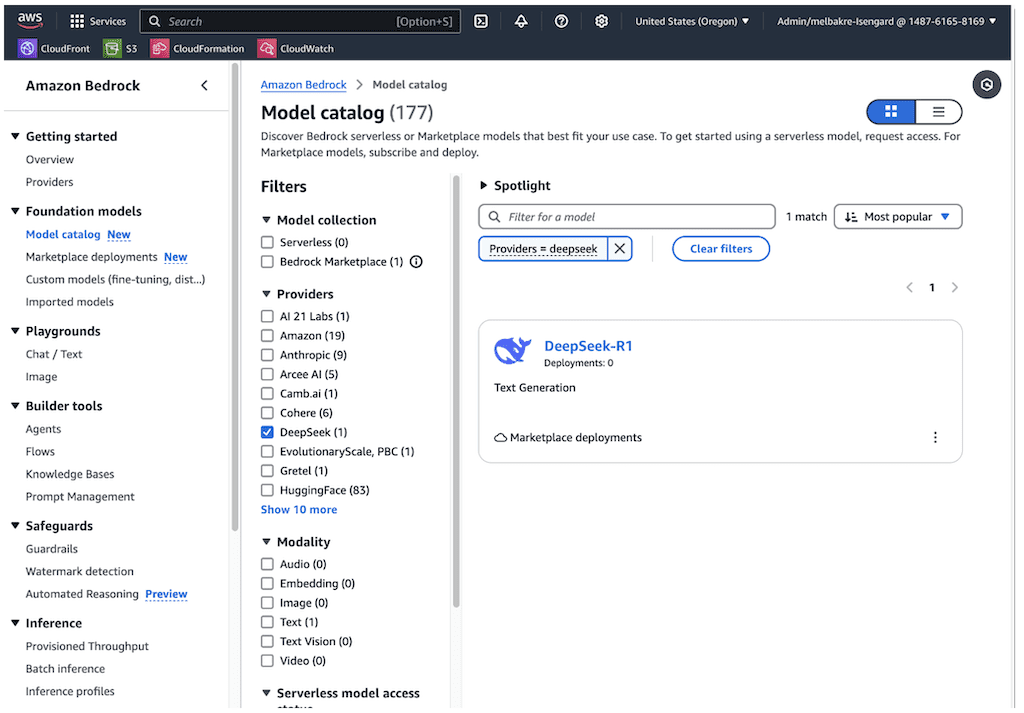
DeepSeek-R1 model now available in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart
Today, we are announcing that DeepSeek AI’s f […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 5 days ago
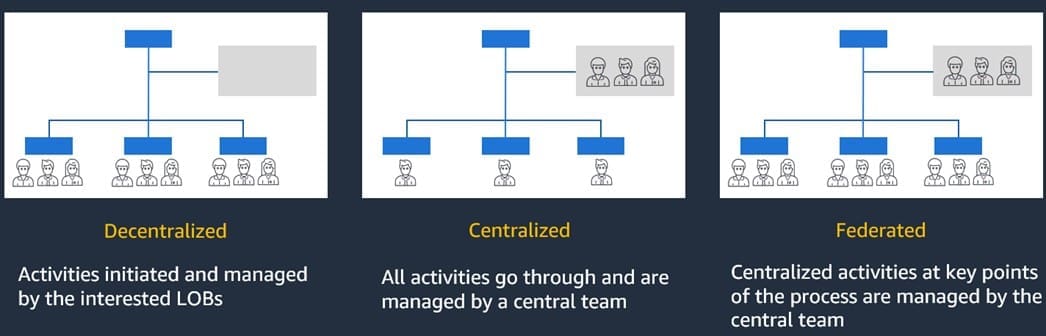
Generative AI operating models in enterprise organizations with Amazon Bedrock
Generative AI can revolutionize organizations by enabling the […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 5 days ago
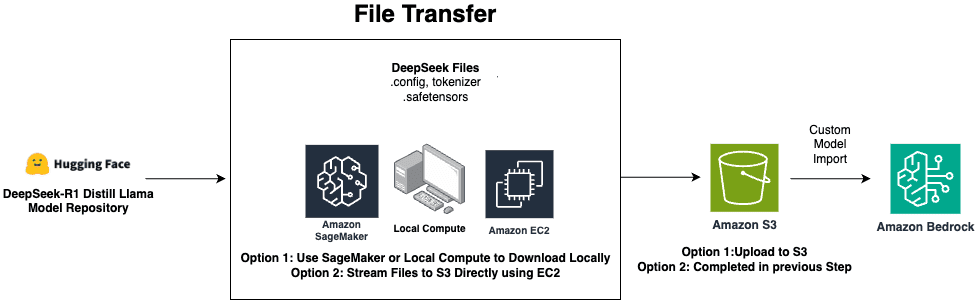
Deploy DeepSeek-R1 distilled Llama models with Amazon Bedrock Custom Model Import
Open foundation models (FMs) have become a cornerstone of […] -
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 6 days ago
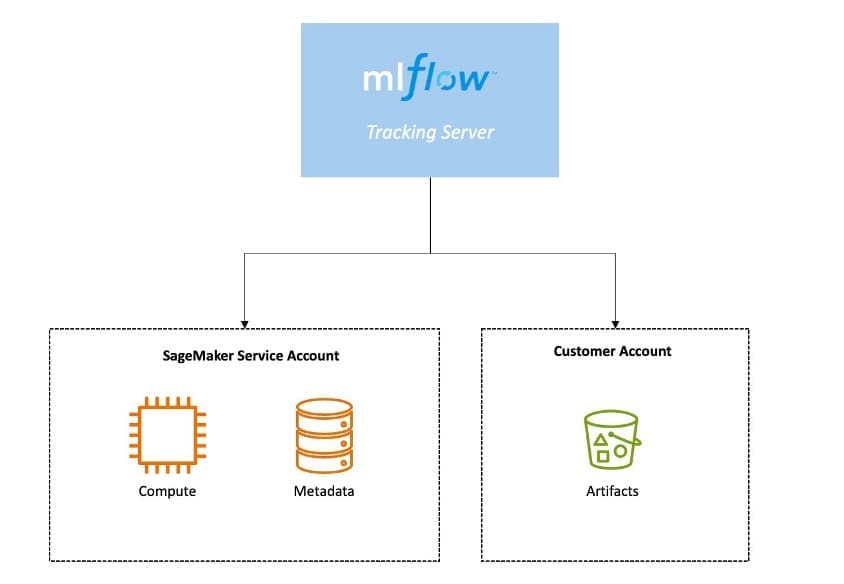
Track LLM model evaluation using Amazon SageMaker managed MLflow and FMEval
Evaluating large language models (LLMs) is crucial as LLM-based systems […] -
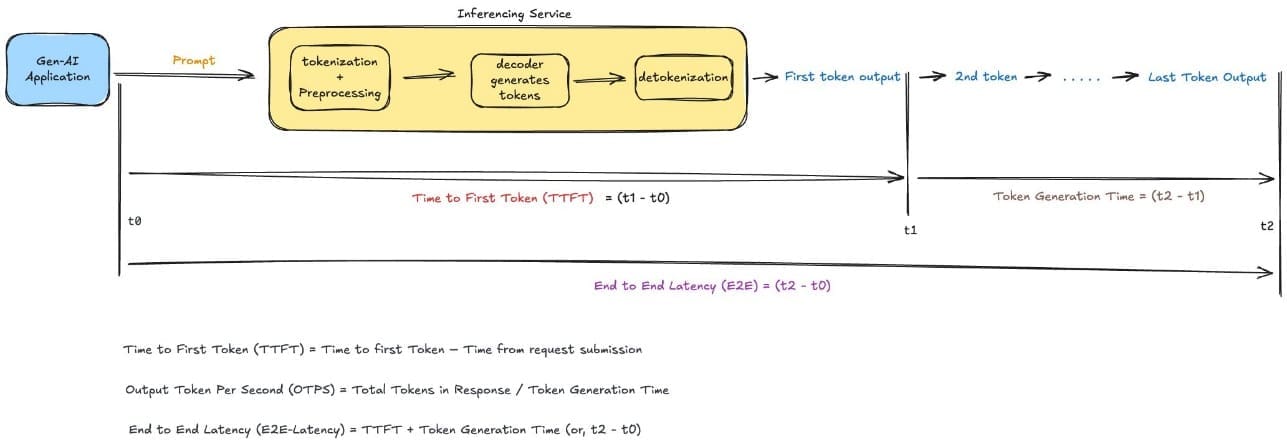
AWS Machine Learning wrote a new post on the site CYBERCASEMANAGER ENTERPRISES 2 weeks, 6 days ago
Optimizing AI responsiveness: A practical guide to Amazon Bedrock latency-optimized inference
In production generative AI applications, […] - Load More