Favorite As AI adoption accelerates and reshapes our future, organizations are adapting to evolving regulatory frameworks. In our report commissioned to Strand Partners, Unlocking Europe’s AI Potential in the Digital Decade 2025, 68% of European businesses surveyed underlined that they struggle to understand their responsibilities under the EU AI Act.
Read More
 Shared by AWS Machine Learning June 20, 2025
Shared by AWS Machine Learning June 20, 2025
Favorite In recent years, the rapid advancement of artificial intelligence and machine learning (AI/ML) technologies has revolutionized various aspects of digital content creation. One particularly exciting development is the emergence of video generation capabilities, which offer unprecedented opportunities for companies across diverse industries. This technology allows for the creation of
Read More
Shared by AWS Machine Learning June 20, 2025
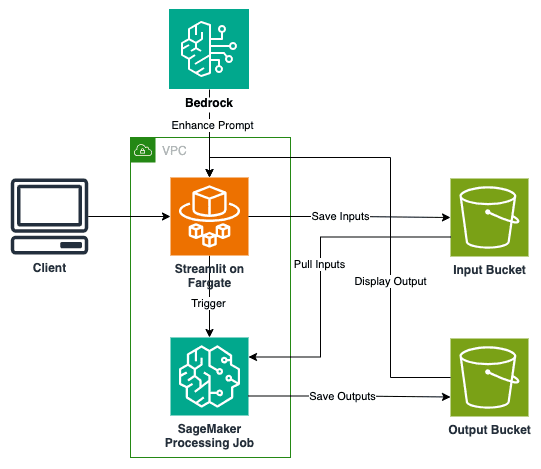
Favorite Developing robust text-to-SQL capabilities is a critical challenge in the field of natural language processing (NLP) and database management. The complexity of NLP and database management increases in this field, particularly while dealing with complex queries and database structures. In this post, we introduce a straightforward but powerful solution
Read More
Shared by AWS Machine Learning June 19, 2025
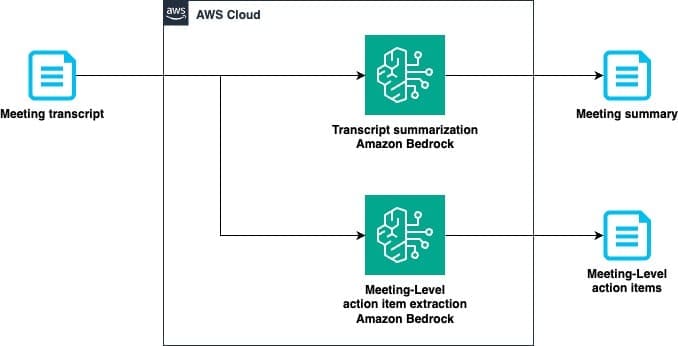
Favorite Meetings play a crucial role in decision-making, project coordination, and collaboration, and remote meetings are common across many organizations. However, capturing and structuring key takeaways from these conversations is often inefficient and inconsistent. Manually summarizing meetings or extracting action items requires significant effort and is prone to omissions or
Read More
Shared by AWS Machine Learning June 19, 2025
Favorite The Open Source Initiative (OSI) is excited to announce the availability of a new API service providing access to the canonical list of OSI Approved Licenses®. This launch is part of our broader effort to modernize how we manage and share Open Source license data, making it easier for
Read More
Shared by voicesofopensource June 19, 2025
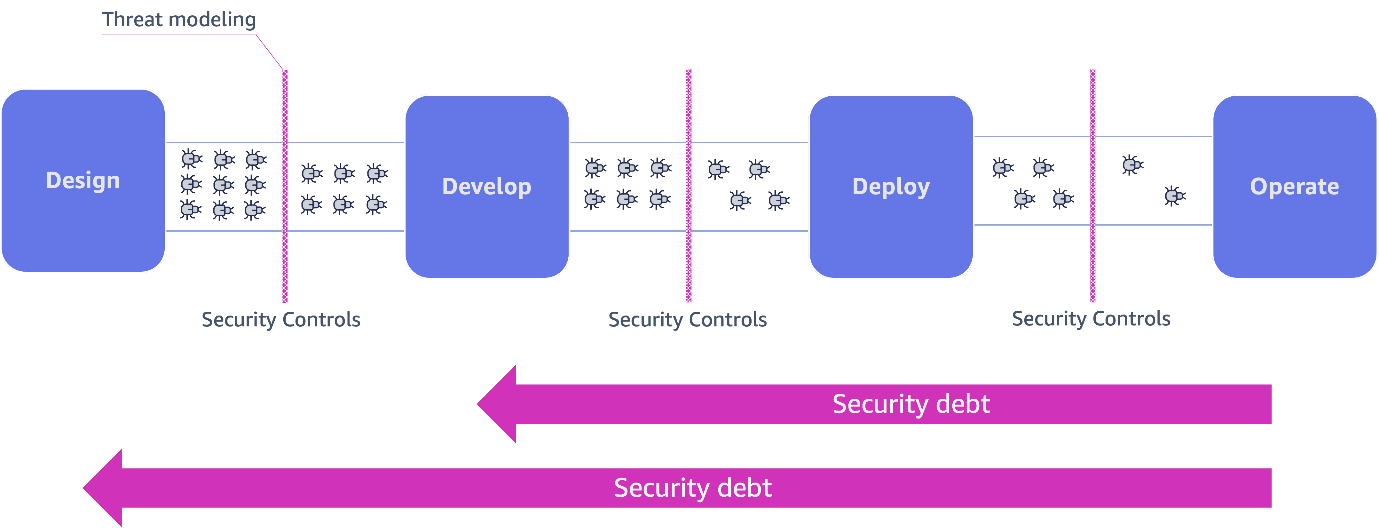
Favorite In this post, we explore how generative AI can revolutionize threat modeling practices by automating vulnerability identification, generating comprehensive attack scenarios, and providing contextual mitigation strategies. Unlike previous automation attempts that struggled with the creative and contextual aspects of threat analysis, generative AI overcomes these limitations through its ability
Read More
Shared by AWS Machine Learning June 18, 2025
Favorite Search Live with voice facilitates back-and-forth conversations in AI Mode. View Original Source (blog.google/technology/ai/) Here.
Favorite French President Emmanuel Macron alongside NVIDIA CEO Jensen Huang and Mistral AI’s Arthur Mensch celebrated a landmark partnership at Vivatech 2025 last week aimed at propelling Europe to the forefront of the global AI race with a strategic move toward European technological sovereignty. But what could truly support achieving
Read More
Shared by voicesofopensource June 18, 2025
Favorite The latest episode of the Google AI: Release Notes podcast focuses on how the Gemini team built one of the world’s leading AI coding models.Host Logan Kilpatrick chats w… View Original Source (blog.google/technology/ai/) Here.
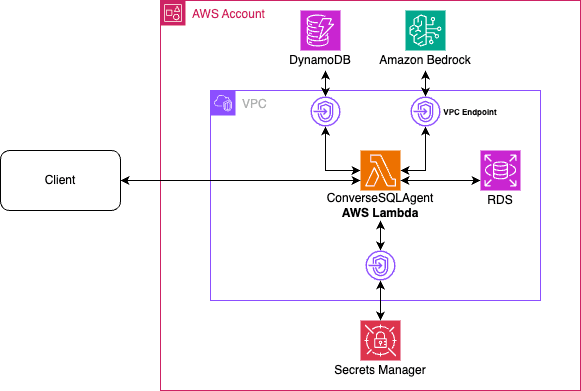
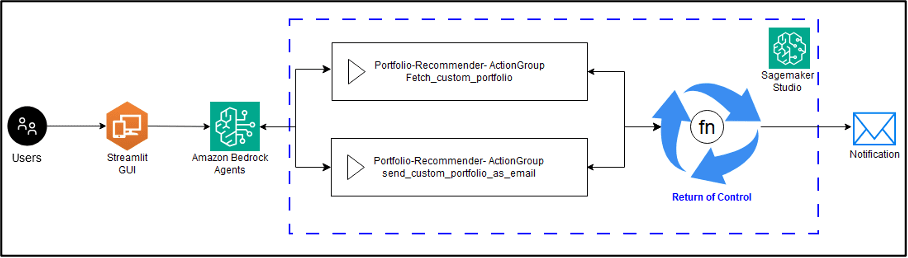
Favorite In the context of distributed systems and microservices architecture, orchestrating communication between diverse components presents significant challenges. However, with the launch of Amazon Bedrock Agents, the landscape is evolving, offering a simplified approach to agent creation and seamless integration of the return of control capability. In this post, we
Read More
Shared by AWS Machine Learning June 17, 2025