Favorite Yesterday I blogged about the challenge to revolutionise the productivity of the knowledge worker, and how the first step was the division of knowledge. The second step is the automation of knowledge work. Image from wikipedia commons Automation was one of the factors that helped revolutionise the productivity of
Read More
 Shared by Nick Milton November 17, 2020
Shared by Nick Milton November 17, 2020
Favorite IDEO based their KM platform around 5 design principles. Here they are. Image from wikimedia commons Here is a fascinating article by Doug Solomon, entitled “The Tube: IDEO Builds a Collaboration System That Inspires through Passion.” It describes how IDEO, the famous design and innovation agency, built themselves a
Read More
Shared by Nick Milton March 6, 2020
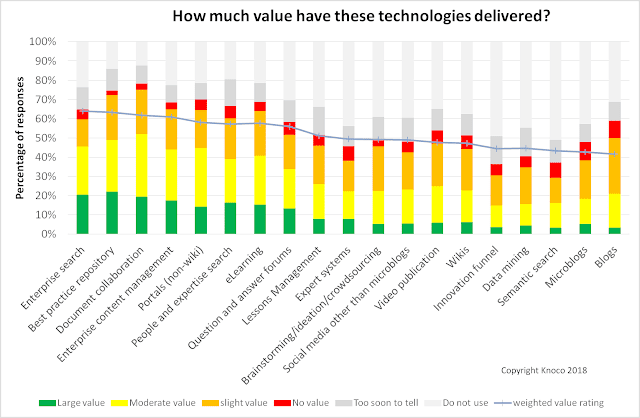
Favorite Here are some more results from our 2014 and 2017 Global Survey of Knowledge management; a plot of KM Technology usage and value. We asked the survey participants to rate a range of different types of technology by the value they have added to their KM program, giving them
Read More
Shared by Nick Milton January 8, 2020
Favorite Does KM need a single technology platform? More likely it needs several technologies. This blog post was prompted by a thread in Stan Garfield’s SIKM community asking what technology platform people use for KM. My immediate thought was that a single platform probably is not sufficient. However let’s look
Read More
Shared by Nick Milton November 22, 2019
Favorite Public organisations can learn from the coastguard when it comes to getting wide scale input to lesson learning US coastguard units train on Lake Ponchartrain by Coast Guard on Flickr Any public organisation, especially one with an element of high priority service, needs a lesson-learning process to improve that service.
Read More
Shared by Nick Milton February 7, 2019
Favorite In this blog post I want to contrast two software systems, the Lessons Database, and the Lessons Management System. Lessons Leaned. Sure, by Mike Licht on Flickr There are two types of Lessons Learned approaches, which you could differentiate as “Lessons for Information” and “Lessons for Action”. These represent
Read More
Shared by Nick Milton February 6, 2019
Favorite All the time we hear managers saying “we want a search engine as good as Google”. Here are 5 reasons why you can never even get close. Image from wikimedia commons Google is the yardstick for search, and managers seem to want internal enterprise search that works as well
Read More
Shared by Nick Milton December 14, 2018
Favorite An interesting Forrester blog highlights some of the risks of process automation image from wikimedia commons We live in a world where automation is beginning to impact knowledge work, in the same way that it impacted manual work in the last century. On the one hand this is great
Read More
Shared by Nick Milton December 12, 2018
Favorite Here is a very interesting article from HBR entitled “What managers need to know about social tools” – thanks to Anshuman Rath for bringing it to my attention. It’s well worth a complete read. Image by Codynguyen1116on wikimedia commons The article by Paul Leonardi and Tsedal Neeley, from the Nov/Dec
Read More
Shared by Nick Milton November 20, 2018
Favorite An example from Schlumberger shows us how selecting KM technology should be done. image from wikimedia commons At the KMUK conference a few years ago, Alan Boulter introduced us to the Schlumberger approach to selecting Knowledge Management technology. This is a very straightforward contracts to the common “gadget-store pick
Read More
Shared by Nick Milton August 29, 2018