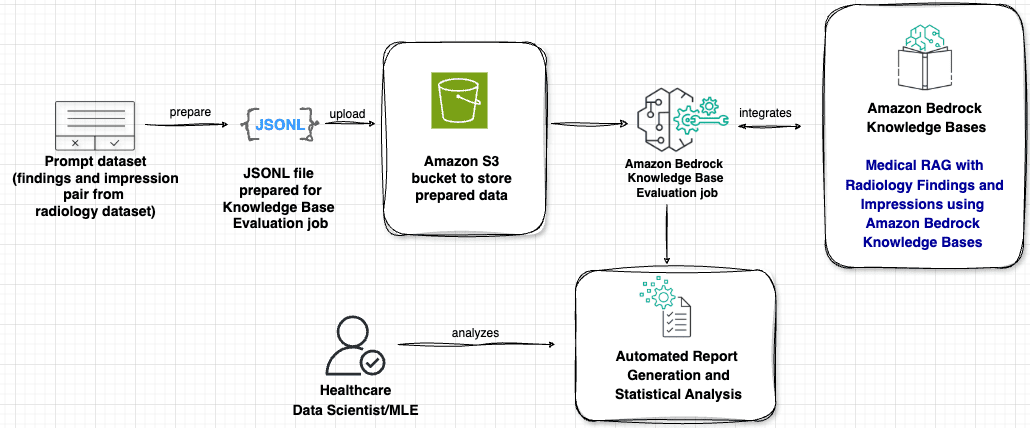
Favorite In our previous blog posts, we explored various techniques such as fine-tuning large language models (LLMs), prompt engineering, and Retrieval Augmented Generation (RAG) using Amazon Bedrock to generate impressions from the findings section in radiology reports using generative AI. Part 1 focused on model fine-tuning. Part 2 introduced RAG,
Read More
 Shared by AWS Machine Learning February 27, 2025
Shared by AWS Machine Learning February 27, 2025
Favorite This is a guest post authored by the team at ByteDance. ByteDance is a technology company that operates a range of content platforms to inform, educate, entertain, and inspire people across languages, cultures, and geographies. Users trust and enjoy our content platforms because of the rich, intuitive, and safe
Read More
Shared by AWS Machine Learning February 26, 2025
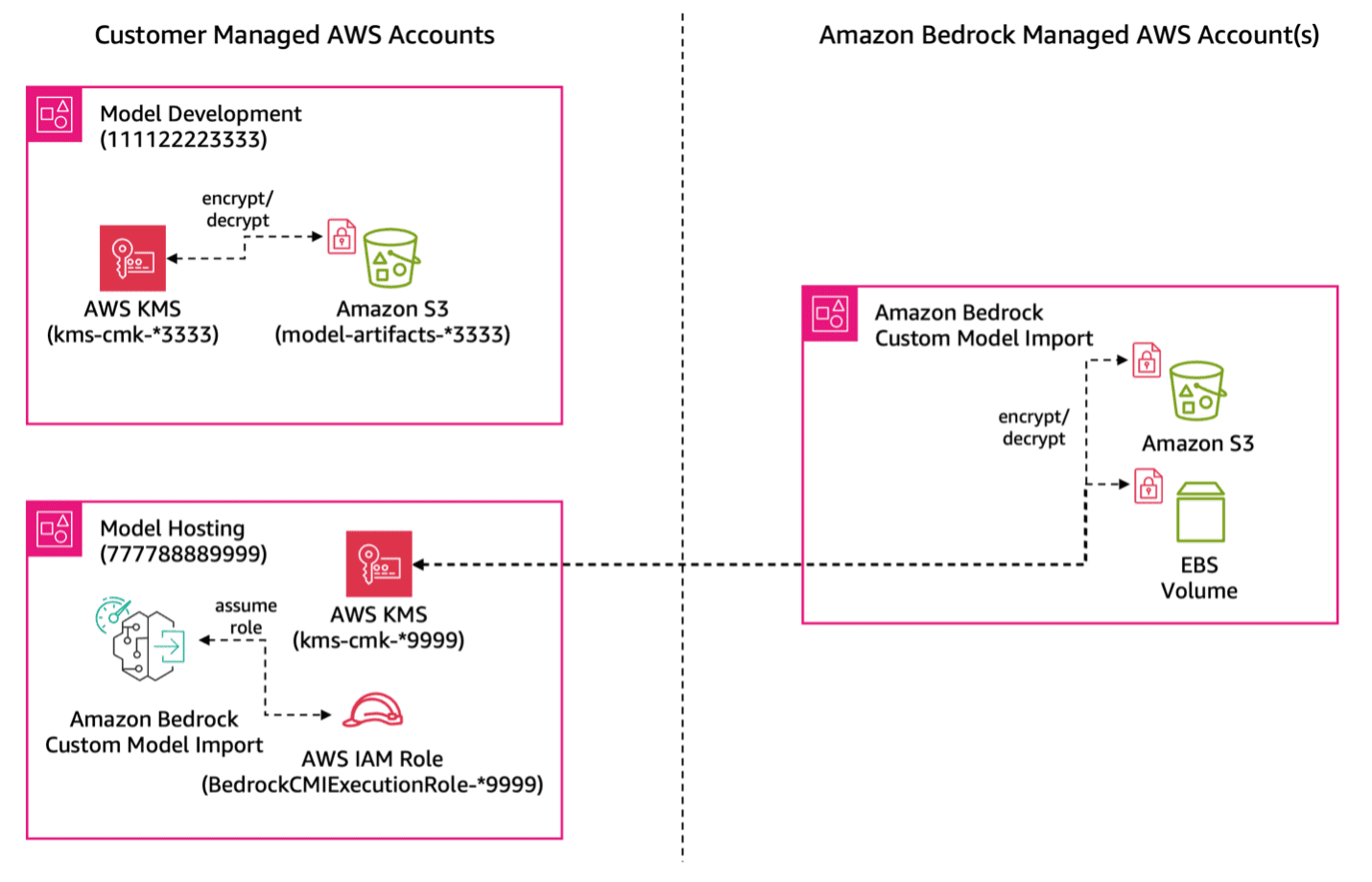
Favorite In enterprise environments, organizations often divide their AI operations into two specialized teams: an AI research team and a model hosting team. The research team is dedicated to developing and enhancing AI models using model training and fine-tuning techniques. Meanwhile, a separate hosting team is responsible for deploying these
Read More
Shared by AWS Machine Learning February 26, 2025
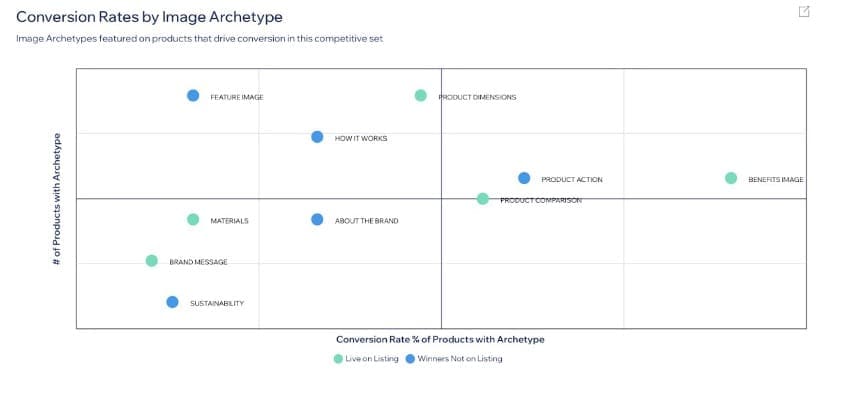
Favorite Brands today are juggling a million things, and keeping product content up-to-date is at the top of the list. Between decoding the endless requirements of different marketplaces, wrangling inventory across channels, adjusting product listings to catch a customer’s eye, and trying to outpace shifting trends and fierce competition, it’s
Read More
Shared by AWS Machine Learning February 26, 2025
Favorite Today, we’re excited to announce that Mistral-Small-24B-Instruct-2501—a twenty-four billion parameter large language model (LLM) from Mistral AI that’s optimized for low latency text generation tasks—is available for customers through Amazon SageMaker JumpStart and Amazon Bedrock Marketplace. Amazon Bedrock Marketplace is a new capability in Amazon Bedrock that developers can use to
Read More
Shared by AWS Machine Learning February 25, 2025
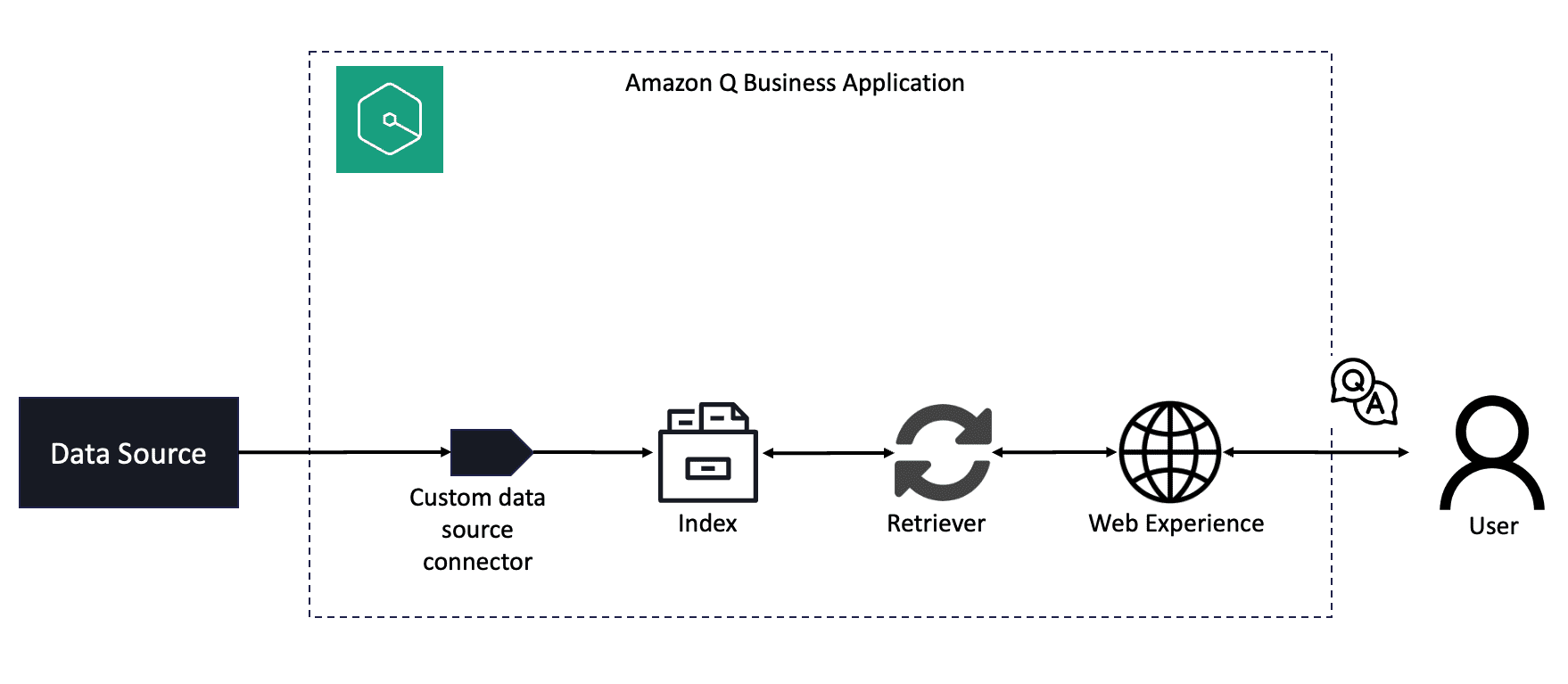
Favorite This blog post is co-written with Gene Arnold from Alation. To build a generative AI-based conversational application integrated with relevant data sources, an enterprise needs to invest time, money, and people. First, you would need build connectors to the data sources. Next you need to index this data to
Read More
Shared by AWS Machine Learning February 25, 2025
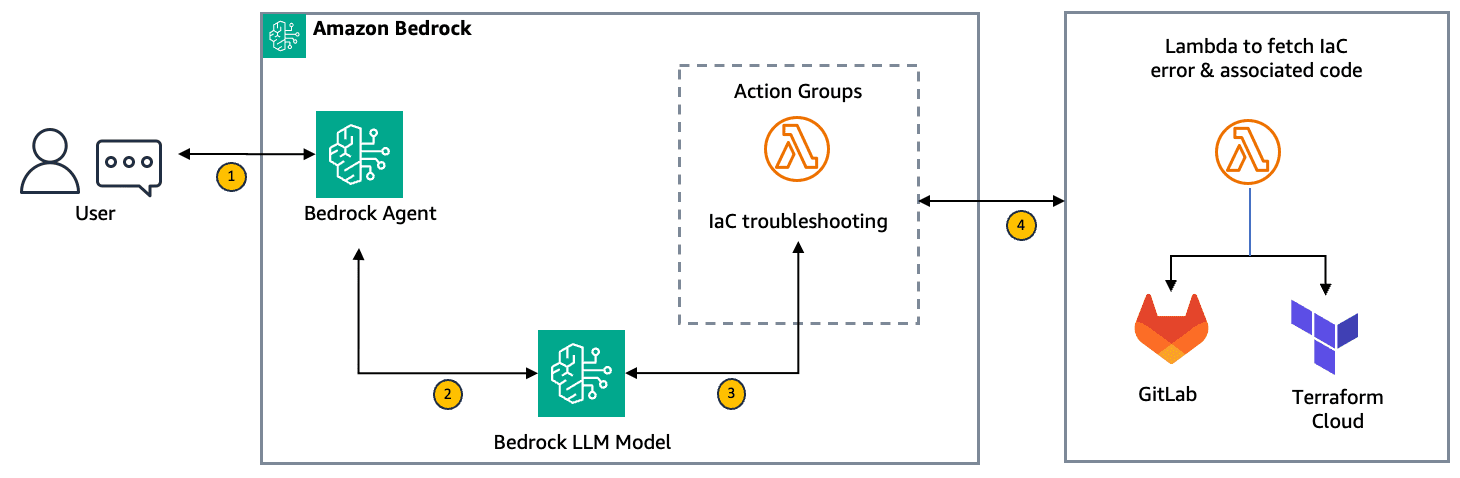
Favorite Troubleshooting infrastructure as code (IaC) errors often consumes valuable time and resources. Developers can spend multiple cycles searching for solutions across forums, troubleshooting repetitive issues, or trying to identify the root cause. These delays can lead to missed security errors or compliance violations, especially in complex, multi-account environments. This
Read More
Shared by AWS Machine Learning February 25, 2025
Favorite This post is co-written with Xavier Vizcaino, Diego Martín Montoro, and Jordi Sánchez Ferrer from Applus+ Idiada. In 2021, Applus+ IDIADA, a global partner to the automotive industry with over 30 years of experience supporting customers in product development activities through design, engineering, testing, and homologation services, established the
Read More
Shared by AWS Machine Learning February 25, 2025
Favorite Technology like AI is changing the ways we prevent, diagnose and treat diseases to make healthcare more accessible and human, putting people at the heart of innovation.T… View Original Source (blog.google/technology/ai/) Here.
Favorite In 2024, more than 140,000 people participated in Google and Kaggle’s Gen AI Intensive live course. Our course is returning this year, with updated content, new speakers… View Original Source (blog.google/technology/ai/) Here.