Deploy a Slack gateway for Amazon Bedrock
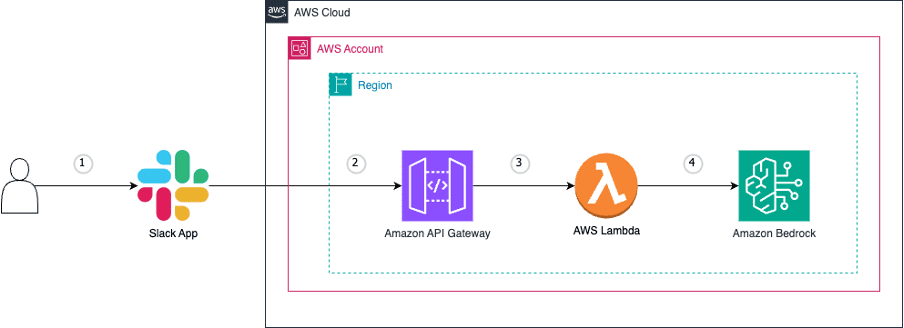
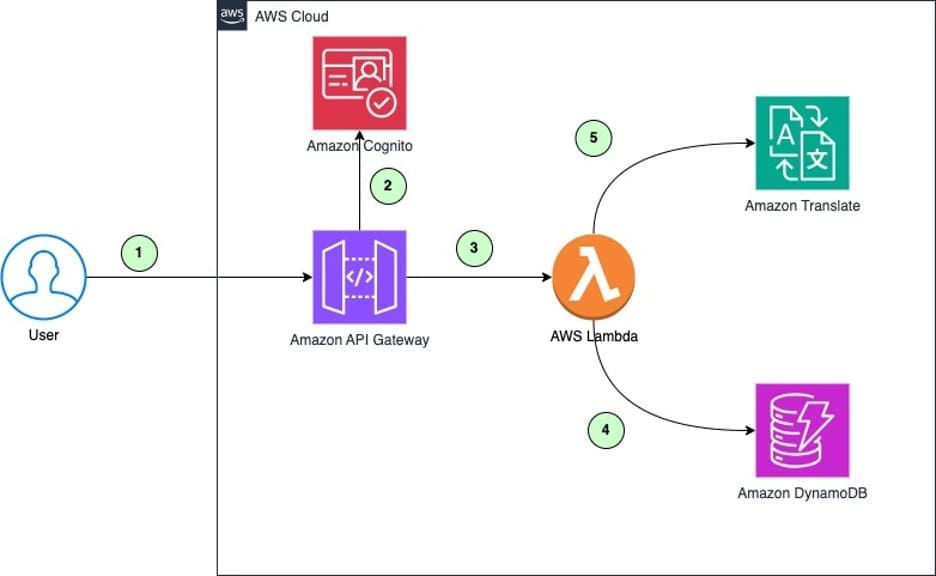
Favorite In today’s fast-paced digital world, streamlining workflows and boosting productivity are paramount. That’s why we’re thrilled to share an exciting integration that will take your team’s collaboration to new heights. Get ready to unlock the power of generative artificial intelligence (AI) and bring it directly into your Slack workspace.
Read More![]() Shared by AWS Machine Learning June 19, 2024
Shared by AWS Machine Learning June 19, 2024